CCNet:Criss-Cross Attention for semantic Segmentation
原文链接:https://arxiv.org/abs/1811.11721
Github:https://github.com/speedinghzl/CCNet
本文也是Self-Attention机制的文章,该论文在捕获long-range上下文信息的同时提高了计算性能并减少了GPU内存,在Cityscapes、ADE20K和MSCOCO数据集上取得了先进性能。
文中1*1卷积的理解:https://blog.csdn.net/renhaofan/article/details/82721868
Abstract
Long-range依赖能够捕获有用的上写完信息从而解决视觉理解问题。本文提出一种十字交叉的网络CCNet更有效地获得重要的信息。具体来说,CCNet能够通过一个新的交叉注意模块获取其周围像素在十字交叉路径上的上下文信息。通过这样反复的操作,每个像素最终能够从所有的像素中捕获long-range依赖。总体上CCNet有以下贡献:(1)节省GPU内存。与非局部模块non-local相比,循环十字交叉注意模块能够节省11倍的GPU内存占用;(2)更高的计算性能。循环交叉注意力模块在计算Long-range依赖时能够减少85% non-local FLOPs;(3)在语义分割数据集Cityscapes和ADE20K和实例分割数据集COCO上取得了先进性能。
Introduction
为了捕获long-range依赖,Chen等人提出多尺度ASPP模块集成上下文信息;Zhao等人提出带有金字塔池化模块的PSPNet。然而空洞卷积只能从周围像素收集信息不能形成密集上下文信息,池化以非自适应方式集合上下文信息,对图像中的所有像素采用相同的方式,不能满足不同像素需要不同上下文依赖的条件。
为了生成密集的基于像素的上下文信息,PSANet通过各位置的预测注意力图集成上下问信息;Non-local网络采用self-attention机制。然而这些基于attention的方法需要耗费大量时间和空间,有着较高的计算复杂度和占用太大GPU内存。
本文有以下贡献:
- 提出一种新的十字交叉注意力模块,能够以一种更高效的方式从long-range依赖中获取上下文信息;
- 提出两层递归CCNet,在公开数据集上取得了先进性能。

Approach
Overall
网络结构图如下图所示,输入图片经过DCNN得到特征图X。为了保留更多的细节和更有效的生成密集特征图,移除DCNN中最后两个down-sampling操作,并将卷积层替换为空洞卷积,这样得到的特征图是输入图片的1/8大小。本文中采用的是ResNet-101作为主体网络。
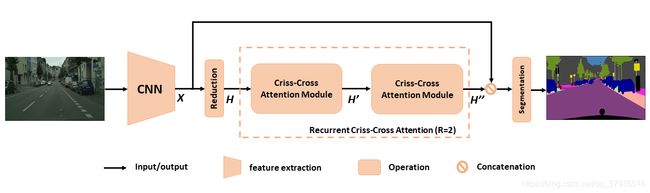
获得特征图X之后,应用卷积得到一个降维的特征图H并将其喂入十字交叉注意模块CCA得到新的特征图H'。H'仅仅继承了水平和竖直方向的上下文信息还不足以进行语义分割。为了获得更丰富更密集的上下文信息,将特征图H'再次喂入注意模块中并得到特征图H''。这时H''的每个位置都继承了所有像素的信息。称递归结构为递归十字交叉注意模块RCCA。
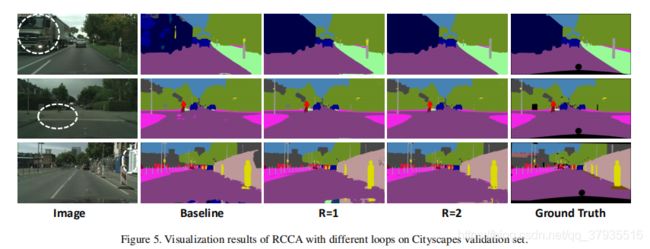
为什么递归两次就能从所有像素中捕获long-range依赖从而生成密集丰富的上下文特征呢?

上图展示了右上角蓝色点如何将信息传递到左下角绿色点的过程,在loop1中,左下角点(ux,uy)只能得到左上角点(ux,oy)和右下角点(ox,uy)的信息,右上角点(ox,oy)蓝色点的信息只能传递到(ux,oy)和(ox,uy),还不能传播到左下角点(ux,uy);在loop2中,左下角点(ux,uy)能够从左上角点(ux,oy)和右下角点(ox,uy)中得到信息,这时已经包含了蓝色点的信息,所以右上角点信息传播到左下角点。同理,任何不能一次遍历的位于十字位置的点只需两次就能完全遍历。
Criss-Cross Attention

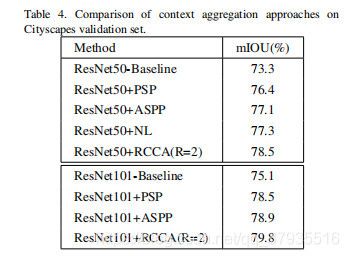
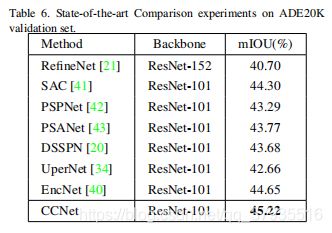
局部特征图H(C*W*H)采用1*1卷积降维得到特征图Q和K(C'*W*H),其中C' Ωi,u是第i个Ωu,Affine操作就是: 因此A的大小为(H+W-1)*W*H 从H经1*1卷积后得到另一卷积层V(C*W*H),在空间维特征V中每一位置u得到向量Vu(C)和φu((H+W-1)*C),然后将A与V中每一个u的特征向量做Aggregation操作: 从而得到输出的H'大小为C*W*H 从上图中可以看到白色圈内的容易被错分,当loops增加后效果改善的很明显。 在Cityscapes验证集上的mIoU。 在ADE20K上验证集上的mIoU。 上表中可以看到节省11倍的GPU memory和85%的计算性能。 参考资料: 
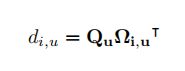

Results