券商金股哪家强——利用信息比率评价主动风险回报
摘要
1:本文主要对投资组合的评价指标——信息比率(Information ratio)进行详细介绍,并利用组合评价指标对五十几家券商的荐股能力做出客观评价;
2:本文主要为理念的讲解,模型也是笔者自建,文中假设与观点是基于笔者对模型及数据的一孔之见,若有不同见解欢迎随时留言交流;
3:笔者希望搭建出一套交易体系,原则是只做干货的分享。后续将更新更多内容,但工作学习之余的闲暇时间有限,更新速度慢还请谅解;
4:本文主要数据通过Tushare(ID:444829)金融大数据平台接口获取,部分数据通过爬虫获取;
5:模型实现基于python3.8;
有人将券商金股比作金矿,也有人将之视为鸡肋。网上其实有很多文章分析券商推荐的股票,甚至还有券商自己写的券商金股策略研究。笔者认为一来很多文章都是以前写的,无法得知最新动向;二是网上很多水军,行话称为黑嘴,于是很难得知一些文章真实性;三是很少有文章会直接评论到某家具体的券商头上,很多都是根据券商的推荐选出某个行业或者个股进行分析,而笔者更希望得知每家券商的具体情况。于是笔者选择自建模型进行分析,本文属于入门级别,主要内容如下:
目录
1. 券商金股哪家强?
2. 主动收益
2.1 选股选券能力
2.2 资产配置能力
3. 主动风险
4. 信息比率及其性质
5. 券商比拼
5.1 代码实现
5.2 风险警示
6. 往期速览
7. 免责声明
1. 券商金股哪家强?
本文通过近三年券商每月公布的金股名单构建投资组合,笔者主要利用几个简单指标对历史数据进行回测。先直接放结论,后面有详细的分析及代码实现。
表一展示了不同指标下排名前十的券商。总回报用于衡量2020年3月初到2022年11月底的总收益率;平均回报是近三年平均日回报进行年化后的收益率;历史最高回报是三年历史上产生的最高收益率;最后笔者选取了上证指数作为基准计算信息比率,用于衡量组合的超额回报。
| 券商 | 总回报 | 券商 | 平均 回报 |
券商 | 历史最 高回报 |
券商 | 信息 比率 |
| 兴业证券 | 0.78 | 兴业证券 | 0.62 | 太平洋证券 | 1.09 | 新时代证券 | 3.36 |
| 太平洋证券 | 0.73 | 新时代证券 | 0.58 | 兴业证券 | 0.93 | 太平洋证券 | 1.68 |
| 新时代证券 | 0.37 | 华泰证券 | 0.47 | 开源证券 | 0.91 | 华泰证券 | 1.52 |
| 财通证券 | 0.26 | 太平洋证券 | 0.43 | 光大证券 | 0.54 | 西南证券 | 1.48 |
| 光大证券 | 0.23 | 东亚前海证券 | 0.34 | 国信证券 | 0.53 | 兴业证券 | 1.46 |
| 川财证券 | 0.20 | 财通证券 | 0.34 | 中原证券 | 0.53 | 中泰证券 | 1.17 |
| 中银证券 | 0.19 | 民生证券 | 0.23 | 新时代证券 | 0.39 | 中原证券 | 1.13 |
| 中原证券 | 0.18 | 中银证券 | 0.22 | 川财证券 | 0.37 | 财通证券 | 1.07 |
| 东亚前海证券 | 0.17 | 中原证券 | 0.19 | 长城证券 | 0.36 | 东亚前海证券 | 0.99 |
| 国元证券 | 0.17 | 川财证券 | 0.19 | 东亚前海证券 | 0.35 | 国盛证券 | 0.90 |
表一:主要金股组合数据指标
从近三年的结果来看,表一中各指标下多次出现的券商荐股能力还是不错的。不过真正在认真做荐股的并不多,剩下四十几家券商很多都是荐了个寂寞,按照它们的推荐一个不慎很有可能直接摩托变单车。不过鉴于杀伤面比较广,笔者就不公布这些表现不佳的券商名单了,笔者以后还得在圈子里混呢,姑且给留一块遮羞布。
不过说到这些评价指标则是五花八门,除了上面笔者使用的,还有最大回撤,VaR,夏普比率,索提诺比率(Sortino ratio),詹森指数(Jensen alpha)等等。当然,不同的指标具有不同的侧重点,大多数情况下要综合利用多个指标进行判断。不过如果只让笔者选择一个指标进行衡量,笔者的建议是直接采用信息比率进行衡量即可。信息比率有很多优良性质,用来衡量投资组合通过承担主动风险获得主动回报的能力,其计算公式为[1],下面笔者将进行详细解读:
![]()
2. 主动收益
仅仅看绝对的收益率和涨跌幅是可能被误导的,因此衍生出许多相对评价指标。例如一个公司一年上涨50%,听上去很多,但如果告诉大盘上涨了100%,那么这支股票相对大盘其实是偏弱势的。如果简单的直接用该公司收益减去大盘,收益就从原本的正50%变成了负50%。因此这个负50%才更为真实的表现出该公司有没有获得超额收益(或者称为主动收益),但前提是选择了合适的比较基准。
如果引入多支股票构甚至多种资产大类构建出一个投资组合,那么情况就会变得复杂起来。总的来说可以将主动收益的来源按投资能力分为三类:1)选股选券能力带来的主动收益;2)资产配置能力带来的主动收益;以及3)择时能力带来的主动收益。其中,3)择时能力不是本期重点,暂不予讨论。
其实选股选券能力和资产配置能力可以用面积法非常生动形象的解释,笔者个人也非常喜欢这种表达方式。如图一的长方形所示,将长方形长边表示为资产配置的权重,宽表示为回报率;另记:
![]() :比较基准第
:比较基准第 个券的回报率
个券的回报率
![]() :组合第个券的回报率
:组合第个券的回报率
![]() :比较基准第个券的权重配置
:比较基准第个券的权重配置
![]() :投资组合第个券的权重配置
:投资组合第个券的权重配置
![]() :分别是比较基准和组合中的个券或资产数量
:分别是比较基准和组合中的个券或资产数量
那么大长方形可以被拆解为3块区域:

图一:回报的拆解
图中1区域面积为比较基准的收益率,2区域面积代表选股选券能力,3面积代表资产配置能力,而整个大长方形面积则代表投资组合的收益率。
2.1 选股选券能力
总的来说衡量选股选券能力还是很简单的,我们将![]() 定义为主动回报,如公式[2]:
定义为主动回报,如公式[2]:
![]()
在某个资产大类下选择某些个券进行买入,得到的收益与比较基准收益相减即是选股选券能力。在图一中简单表示为![]() ,即相同大类资产权重下由于选择不同个券带来的主动回报。如果完全按照某个指数配置个券,那么会得到与大盘一模一样的走势。将我们的收益与指数相减得到的都是0,也就是说没有获得任何主动收益,这就是典型的ETF指数被动跟踪方式。
,即相同大类资产权重下由于选择不同个券带来的主动回报。如果完全按照某个指数配置个券,那么会得到与大盘一模一样的走势。将我们的收益与指数相减得到的都是0,也就是说没有获得任何主动收益,这就是典型的ETF指数被动跟踪方式。
2.2 资产配置能力
资产配置则要复杂一些,因为涉及到不同的资产大类,很少会有基于不同资产大类的指数,因此这里的比较基准往往需要自建。我们将![]() 定义为主动风险,如公式[3]:
定义为主动风险,如公式[3]:
![]()
资产配置能力在图一中简单表示为![]() ,即在给定比较基准的资产下,通过超配或低配比较基准中不同资产的权重而获得的主动回报。
,即在给定比较基准的资产下,通过超配或低配比较基准中不同资产的权重而获得的主动回报。![]() 大于
大于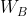 表示超配,
表示超配, ![]() 小于表示低配。
小于表示低配。
需要注意的是图一中面积都完全可以是负数,即![]() 也完全可以小于
也完全可以小于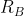 。
。![]() 小于一定是件坏事,即主动选了券不如被动跟投指数,干脆按照基准配置还要省心省力些。但主动权重是负数则并不一定是一件坏事,例如今年大环境不好,低配,甚至做空了很多风险资产,即
小于一定是件坏事,即主动选了券不如被动跟投指数,干脆按照基准配置还要省心省力些。但主动权重是负数则并不一定是一件坏事,例如今年大环境不好,低配,甚至做空了很多风险资产,即 ![]() 小于 ,虽然很多风险资产收益率为负,但配的权重非常低,最后对整个投资组合的影响就非常有限。
小于 ,虽然很多风险资产收益率为负,但配的权重非常低,最后对整个投资组合的影响就非常有限。
3. 主动风险
在金融领域应用最广泛的风险测度指标是标准差,用于衡量数据的波动和不确定性。对大多数资产来说波动和不确定性是越小越好的,大部分投资者都不喜欢波动。如果仅仅只依靠回报对组合表现进行评价仍旧是不完善的,因为我们还是无法得知这个回报下需要承担多大的风险。于是一个大名鼎鼎的比率——夏普比率就诞生了,在回报的基础上除以标准差,通过这个比率可以得知承担一单位风险能获得多少回报。举个例子,比如某支个股主动回报是50%,通过第2部分的分析我们已经知道这支个股有非常不错的超额回报。但这个指标并没有告诉投资者风险相关的信息,如果获得主动回报的前提是每年需要承担巨大的资产价格波动,我们依然认为50%的主动回报是不划算的,即风险与回报不成正比。
夏普比率是应用非常广泛的一个指标,夏普比率的分母是投资组合的标准差,因此衡量的是投资组合总的风险回报。既然上面介绍了信息比率分子为相对的回报,那么按照分母与分子匹配的原则,分母也是可以自然而然地转化为相对的风险,即主动风险,记为![]() ,如公式[4],这里的主动风险其实就是主动回报的标准差:
,如公式[4],这里的主动风险其实就是主动回报的标准差:
![]()
4. 信息比率及其性质
主动收益及主动风险都是个相对概念,因此信息比率也是个相对比率,相对的标的就是选择的基准。其实很多人没有意识到夏普比率也是有比较基准的,夏普比率的比较基准就是无风险收益。不妨看看正统的夏普比率公式[4]:
![]()
这个式子其实与信息比率的计算公式[1]是非常相似的,只要将信息比率公式分子简单的展开一下可得公式[5]:
![]()
如果将无风险收益看作是个稳定的常数,将公式[5]中的![]() 替换为无风险利率,信息比率就会直接退化成夏普比率。也就是说夏普比率其实也有一个基准,并且学过夏普比率的都知道夏普比率其中一个性质是用无风险利率借贷不会影响投资者的夏普比率,这点也可以说明夏普比率其实是有一个基准存在的。如图二,在资本市场线(CML,Capital market line)上,无论是在A点完全按照有效前沿配置,还是在B点以无风险利率贷钱出去,亦或是在C点以无风险利率借钱进来都不会改变CML线的斜率:
替换为无风险利率,信息比率就会直接退化成夏普比率。也就是说夏普比率其实也有一个基准,并且学过夏普比率的都知道夏普比率其中一个性质是用无风险利率借贷不会影响投资者的夏普比率,这点也可以说明夏普比率其实是有一个基准存在的。如图二,在资本市场线(CML,Capital market line)上,无论是在A点完全按照有效前沿配置,还是在B点以无风险利率贷钱出去,亦或是在C点以无风险利率借钱进来都不会改变CML线的斜率:

图二:最优资产配置下以无风险利率借贷不影响夏普比率
我们已经知道,夏普比率的基准其实是无风险利率,并且以无风险利率借贷不影响夏普比率,那么其实信息比率也是可以推出类似性质的。
性质一:对比较基准的成分券进行做多或做空不会影响信息比率大小
做多或做空本质上就是对主动权重产生影响,将信息比率计算公式展开:
![]()
[6]式分母带求和符号,可以直接把![]() 提到求和符号外面(乘法运算律),分母是个标准差,权重符号一样可以当作常数提出来,这样一来分子分母都约掉了个相同的权重,于是信息比率不变,如公式[7]。
提到求和符号外面(乘法运算律),分母是个标准差,权重符号一样可以当作常数提出来,这样一来分子分母都约掉了个相同的权重,于是信息比率不变,如公式[7]。
![]()
也就是说无论主动权重怎么变化,即对比较基准进行卖空或加杠杆,信息比率都是不变的。
性质二:组合所有资产的权重同时扩大相同的倍数c,信息比率不变
这点很简单,无非是在[7]式权重基础上多乘以个常数c,都是可以提出了约掉的,信息比率保持不变。
性质三:不合适的比较基准可能造成截然相反的结果
信息比率的计算一定是基于一个比较基准,它所相对的也是比较基准。如果选择了上证指数作为比较基准,我们可能得到较好的信息比率,但如果这个基准换成上证50,我们甚至有可能得到负的信息比率。因此选择合适的比较基准才能使得信息比率的计算真实反馈出相对的风险回报。一般来说基准选取有以下三个条件进行参考:
1):比较基准需要有代表性,能代表投资者将会选择的资产;
2):基准里的资产要与投资组合有一定可比性,例如投资组合里的资产很容易就能获取,那么基准里的资产就不能选择那些流动性非常差,有交易限制,或者手续费非常高昂的资产;
3):比较基准的权重是事前就确定的,而回报率是事后获得的;举个简单的例子,比如今天下午买了两只股票,各配50%权重,第二天发现一只股票暴跌于是割了,在第二天晚上计算回报率时还是要按照50%去配置权重,不能说割了以后按0%的权重计算回报率。
5. 券商比拼
俗话说得好,是骡子是马拉出来溜溜。既然我们已经得到信息比率的计算方式,不妨利用它对各家券商的金股表现做一个回测。数据方面笔者选择了Tushare金融大数据平台,正好Tushare有券商金股数据,通过Tushare的API请求数据将会省去大把去券商官网爬金股的时间,毕竟五十几家券商,一家家爬不知道得爬到什么时候。
笔者打算测试一下近三年的券商月度金股,给每家券商创一个投资组合,每月1号留出一天时间进行调仓,按市值加权买入所有推荐股票。笔者只对当月进行统计,没有进行推荐的月份数据就直接跳过,不考虑交易费用。
5.1 代码实现
先导入相关模块,实例化Tushare的接口,这里需要输入自己的token:
import pandas as pd
import tushare as ts
import numpy as np
key_id = "" # 输入自己的密钥
pro = ts.pro_api(key_id)用来请求金股数据的接口是这个,详见tushare技术文档:Tushare数据
df = pro.broker_recommend(month="202211")由于要放月份参数进去,先写个小模块自动生成一下月份参数:
def date_mod(start_y, start_m, period, end_month): # 开始年,开始月份,持续年数,结束月份
months = []
if period == 0:
for m in range(1, end_month+1):
if m < 10:
months.append(str(year)+"0"+str(m))
else:
months.append(str(year)+str(m))
return months
years=[]
for y in range(period):
years.append(start_y+y)
m = ["01","02","03","04","05","06",
"07","08","09","10","11","12"]
for year in years:
if year == start_y:
for index in range(start_m,len(m)):
months.append(str(year)+m[index-1])
else:
for index in range(len(m)):
months.append(str(year)+m[index])
year = years[-1] + 1
for index in range(1,end_month): # 添加至任意月份
months.append(str(year)+m[index])
return months例如笔者想生成2020年3月到2022年12月的参数列表,那么可以传入参数:
date_mod(start_y = 2020, start_m = 3, period = 3, end_month = 12)
['202003','202004','202005','202006','202007','202008','202009','202010','202011','202101','202102','202103','202104','202105','202106','202107','202108','202109','202110','202111','202112','202202','202203','202204','202205','202206','202207','202208','202209','202210','202211','202212']写个数据的请求模块,这样只要传入某券商某月的金股名单及月份数据就可以输出每支金股的详细数据了:
def companies_data(stocks, month):
companies = []
for code in stocks:
company = pro.daily_basic(ts_code=code, start_date=month+'01', end_date=month+'31', fields='ts_code,trade_date,close,pe,pb,total_mv')
current_price = company["close"][:len(company)-1] # 前一天价格
previous_price = company["close"][1:]# 后一天价格
current_price.index = range(len(current_price)) # 表格索引要匹配后面才能相减
previous_price.index = range(len(previous_price))
pct_chg = (current_price-previous_price)/previous_price
company = company[:len(company)-1]
company.index = range(len(company)) # 索引匹配
company["pct_chg"] = pct_chg
companies.append(company)
return companies再写个模块用于计算某券商组合的收益率情况,下面只要传入比较基准的详细数据,companies_data模块所返回的详细股票数据及券商名字,就可以输出一张券商投资组合的数据表:
def broker_mod(index, companies, broker_name):
protfolio_r = []
dates = []
trade_date = index["trade_date"].values[::-1] # 去掉每月第一天,用来换股
for date in trade_date[1:]:# 分别计算每天的组合回报,转换成时间正序排列
## 计算总市值方便后面加权
total_mv = 0
for code in companies:
if date in code["trade_date"].values: # 停牌,没有交易数据的就跳过
total_mv += code[(code["trade_date"]==date)]["total_mv"].values[0]
else:
pass
r = 0
for code in companies:# 计算当日组合的市值加权回报
if date in code["trade_date"].values:
row = code[(code["trade_date"]==date)].index.to_list()
r += float(code["pct_chg"][row].values[0])*float(code["total_mv"][row].values[0])/float(total_mv)
protfolio_r.append(float(r))
dates.append(date)
table = pd.DataFrame({"date":dates, broker_name: protfolio_r})
return table
date 东莞证券
0 20221011 0.015730
1 20221012 0.016681
2 20221013 -0.021188
3 20221014 0.015801
4 20221017 -0.003195
5 20221018 -0.005783
...因为上面是按月获取了很多张数据表,还需要一个模块整合所有月份的数据。如果是新出现的券商,添加进brokers_return列表,如果是之前添加过了的券商则在那家券商的表格后面进行追加:
def data_integrate_mod(all_brokers_name, broker, broker_r, brokers_return):
if broker in all_brokers_name:
num = 0
for table in brokers_return:
if table.columns[1]==broker:
brokers_return[num] = brokers_return[num].append(broker_r)
num+=1
else:
brokers_return.append(broker_r)还需要一个投资组合表现评价模块,笔者设置了一些简单指标以及信息比率。所有年化操作口径均设置为250天,组合日标准差假设稳定不变,通过平方根公式进行年化:
def protfolio_performance_mod(data_set, broker):
total_r = (data_set["stock"].values[-1]-data_set["stock"].values[-0])/data_set["stock"].values[0]
mean_r = (1+np.mean(data_set["stock_r"].values))**250 - 1
max_r = max(data_set["stock"].values)-1
min_r = min(data_set["stock"].values)-1
active_return = (1+np.mean(data_set["stock_r"]-data_set["index_r"]))**250-1
active_risk = np.std(data_set["stock_r"]-data_set["index_r"])*250**(0.5)
IR = active_return/active_risk
performance = {"name": broker, "volum": len(data_set["stock"].values), "total return":total_r, "mean return":mean_r,
"max return": max_r, "min return": min_r, "active return": active_return,
"active risk": active_risk, "information ratio": IR}
return performance最后调用之前的模块,该传参的传参,该循环的循环:
months = date_mod(start_y = 2020, start_m = 3, period = 3, end_month = 11)
all_brokers_name = [] # 存下做出过所有预测的券商名,后面让收益率汇总到各家的名下
brokers_return = []
for month in months: # 循环所有时间 months
## 比较基准数据,这里选用中证500
index = pro.index_daily(ts_code='000001.SH', start_date=month+"01", end_date=month+"31")
df = pro.broker_recommend(month=month) # 某月所有券商金股
brokers = df.drop_duplicates("broker")["broker"].values
for broker in brokers: # 循环所有券商
print("正在处理{},{}月数据\r".format(broker,month),end="")
stocks = df[(df["broker"]==broker)]["ts_code"].values # 筛选出某券商的月金股
if len(stocks) > 0:
companies = companies_data(stocks, month)
broker_r = broker_mod(index, companies, broker)
data_integrate_mod(all_brokers_name, broker, broker_r, brokers_return)
else:
pass
print("\n完成{}月数据\n".format(month))
for name in brokers:
if name not in all_brokers_name:
all_brokers_name.append(name)
正在处理西南证券,202003月数据据
完成202003月数据
正在处理申万宏源,202004月数据
完成202004月数据
正在处理西南证券,202005月数据据
完成202005月数据
正在处理长城证券,202006月数据据
完成202006月数据
正在处理财通证券,202007月数据据
完成202007月数据
正在处理财通证券,202008月数据据
完成202008月数据
正在处理长江证券,202009月数据据
完成202009月数据
...brokers_return里就存储了所有券商的回报数据,可以将其输出到折线图上:
import matplotlib.pyplot as plt
plt.rcParams[ 'font.sans-serif' ] = [ 'SimHei' ] # 进行中文显示
plt.rcParams[ 'axes.unicode_minus' ] = False
plt.figure(figsize=(16,5))
index = pro.index_daily(ts_code='000001.SH', start_date="20200301", end_date="20221231")[::-1]
trade_date = index["trade_date"].values
index_value = []
value = 1
for i in index["pct_chg"].values:
value = value * (1+i/100)
index_value.append(value)
plt.plot(trade_date, index_value, label="SH index", color="r")
for table in brokers_return:
r = []
value = 1
broker = table.columns[1]
for date in trade_date:
if date in table["date"].values:
value = value * (1+float(table[(table["date"]==date)][broker].values))
r.append(value)
else:
r.append(None)
plt.plot(trade_date, r, label=broker)
plt.xticks(trade_date[::30], rotation=90)
plt.legend()
plt.show()运行得图三:

图三:各大券商金股数据集中展示
不过图三看起来很杂乱,毕竟50几家券商,旁边的图例笔者都截图删掉了很多,不然是一大串。并且很多券商不是每月都推金股,因此有很多空白及片段。笔者对上面的代码进行一些修改,将空白数据删去,每家券商单独输出到图上:
index = pro.index_daily(ts_code='000001.SH', start_date="20200301", end_date="20221231")[::-1]
trade_date = index["trade_date"].values
indicators = []
for table in brokers_return:
stock_r, index_r = [], []
stock_values, index_values = [], []
value_stock, index_value = 1, 1
broker = table.columns[1]
for date in trade_date:
if date in table["date"].values:
value_stock = value_stock * (1+float(table[(table["date"]==date)][broker].values))
stock_values.append(value_stock)
stock_r.append(float(table[(table["date"]==date)][broker].values))
index_value = index_value * (1+float(index[(index["trade_date"]==date)]["pct_chg"].values)/100)
index_values.append(index_value)
index_r.append(float(index[(index["trade_date"]==date)]["pct_chg"].values)/100)
else:
stock_r.append(None)
index_r.append(None)
stock_values.append(None)
index_values.append(None)
data_set = pd.DataFrame({"trade_date":trade_date, "index":index_values,
"index_r": index_r,"stock":stock_values, "stock_r":stock_r})
data_set.dropna(inplace=True)
indicators.append(protfolio_performance_mod(data_set, broker))
plt.figure(figsize=(16,5))
plt.plot(data_set["trade_date"], data_set["stock"], label=broker)
plt.plot(data_set["trade_date"], data_set["index"], label="000001.SH", color="r")
plt.xticks(data_set["trade_date"][::30], rotation=90)
plt.legend()
plt.show()运行后就会输出五十几家券商的图表,下面笔者随意展示两家排名靠前的券商:

图四:太平洋证券投资组合历史回报走势

图四:兴业证券投资组合历史回报走势
上面的indicators表格里存着的就是本文一开始笔者所展示的表格,可以直接导入csv或者Excel。由于需要显示中文,to_csv需要多加一个编码参数:
performance = pd.DataFrame(indicators)
performance.to_csv("C:/Users/SK248/Desktop/result.csv", encoding='utf_8_sig')5.2 风险警示
由于Tushare只有2020年3月之后的金股数据,因此统计期间仅为3年,一般来说统计时间更长所得到的结果才更为可靠。其次,本文通过历史数据计算的是事后信息比率(Ex-post information ratio),未来可能还会产生新的变动,该模型仅能以当前状况推测未来。最后,笔者选取上证指数为信息比率基准只是随意为之,如果选择其它比较基准结果可能产生差异。
6. 往期速览
| 往期速览 | |||
| 系列 | 子类别 | 文章传送门 | 实现方式 |
| 基本面分析 | 绝对估值 | 实现GGM的理想国 | Python |
| Fama-French及PSM | Python | ||
| 增速g的测算 | Python | ||
| 相对估值 | PE指标平滑 | Python | |
| PE Band | Python | ||
| 技术分析 | / | 分类树算法 | R |
| / | 蒙特卡洛模拟 | Python | |
| / | 全连接神经网络模型 | Python | |
| 财务分析 | 财务建模 | 利润表 | R |
| 金融数据获取 | / | 多线程爬取 | Python |
| / | 多进程爬取 | Python | |
| / | selenium模拟网页爬虫 |
Python | |
| 其它 | / | 市场风险分析 | Python |
| / | 金融危机模拟 | Python | |
7. 免责声明
本文分析师具有专业胜任能力,以勤勉的职业态度,独立客观地出具本文,本文所表述的所有观点均准确地反映了本人的研究观点,在独立客观的基础上合理判断得出结论。本文是为广大投资者提供的参考,但本文通过数据分析所得的结论不构成任何投资建议。本文力求报告内容的准确可靠, 但并不对报告内容及所引用资料的准确性和完整性作出任何承诺和保证。作者不会承担因使用本报告而产 生的法律责任。