Alexnet实现Caltech101数据集图像分类(pytorch实现)
目录
-
-
- 主要任务
- 数据处理
- 网络结构
- 训练和测试
- 全部代码
- 训练结果
-
主要任务
- 基于PyTorch实现AlexNet结构
- 在Caltech101数据集上进行验证
- 数据集地址
数据处理
从101个文件中读取图像数据(进行resize和RGB的转化,原始图像数据大小不一,必须resize),并为其加上101类标签(0-100)
def data_processor(size=65):
"""
将文件中的图片读取出来并整理成data和labels 共101类
:return:
"""
data = []
labels = []
label_name = []
name2label = {}
for idx, image_path in enumerate(image_paths):
name = image_path.split(os.path.sep)[-2] #获取类别名
#读取图像并进行处理
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) #将BGR转化为RGB
image = cv2.resize(image, (size, size), interpolation=cv2.INTER_AREA)
data.append(image)
label_name.append(name)
data = np.array(data)
label_name = list(dict.fromkeys(label_name)) #利用字典进行去重
label_name = np.array(label_name)
# print(label_name)
# 生成0-100的类标签 对应label_name中的文件名
for idx, name in enumerate(label_name):
name2label[name] = idx #每个类别分配一个标签
for idx, image_path in enumerate(image_paths):
labels.append(name2label[image_path.split(os.path.sep)[-2]])
labels = np.array(labels)
return data, name2label, labels
进行图像变换,并分出训练集,验证集和测试集
#定义图像变换
# define transforms
train_transform = transforms.Compose(
[transforms.ToPILImage(),
# transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
val_transform = transforms.Compose(
[transforms.ToPILImage(),
# transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
# 将数据集分为训练集验证集以及测试集
# x_train examples: (5205, 200, 200, 3)
# x_test examples: (1736, 200, 200, 3)
# x_val examples: (1736, 200, 200, 3)
(X, x_val, Y, y_val) = train_test_split(data, labels,
test_size=0.2,
stratify=labels,
random_state=42)
(x_train, x_test, y_train, y_test) = train_test_split(X, Y,
test_size=0.25,
random_state=42)
print(f"x_train examples: {x_train.shape}\nx_test examples: {x_test.shape}\nx_val examples: {x_val.shape}")
自定义一个数据集类(继承自dataset)便于数据加载
class ImageDataset(Dataset):
def __init__(self, images, labels=None, transforms=None):
self.X = images
self.y = labels
self.transforms = transforms
def __len__(self):
return (len(self.X))
def __getitem__(self, i):
data = self.X[i][:]
if self.transforms:
data = self.transforms(data)
if self.y is not None:
return (data, self.y[i])
else:
return data
train_data = ImageDataset(x_train, y_train, train_transform)
val_data = ImageDataset(x_val, y_val, val_transform)
test_data = ImageDataset(x_test, y_test, val_transform)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
网络结构
Alexnet模型由5个卷积层和3个池化Pooling 层 ,其中还有3个全连接层构成。AlexNet 跟 LeNet 结构类似,但使⽤了更多的卷积层和更⼤的参数空间来拟合⼤规模数据集 ImageNet。它是浅层神经⽹络和深度神经⽹络的分界线。
Alexnet的网络结构如下所示:
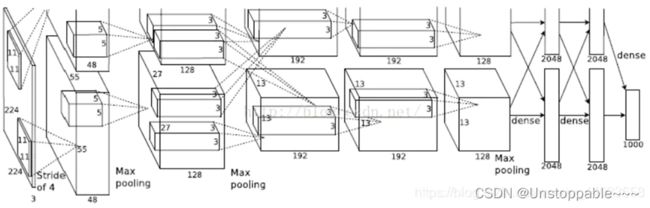
AlexNet的优点:
- 使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。
- 时使用Dropout随机忽略一部分神经元,以避免模型过拟合。在AlexNet中主要是最后几个全连接层使用了Dropout。
- NN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
- LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- 使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。
按照Alexnet结构设置了,五个卷积层和三个全连接层,卷积层间设置了Relu激活曾和BatchNorm2d层,全连接层间设置了Dropout层防止过拟合,并且设置了init_weights通过kaiming_normal进行初始化,效果更佳。
# 网络模型构建
class AlexNet(nn.Module):
def __init__(self, num_class=101, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11),
# nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55] 自动舍去小数点后
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.BatchNorm2d(48),
nn.Conv2d(48, 128, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.BatchNorm2d(128),
nn.Conv2d(128, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), #output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(6 * 6 * 128, 2048),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_class),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
# print("x.shape", x.shape) #torch.Size([32, 128, 22, 22])
x = torch.flatten(x, start_dim=1) #拉成一条
# print("x.flatten.shape", x.shape)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') #何教授方法
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) #正态分布赋值
nn.init.constant_(m.bias, 0)
训练和测试
#训练过程
def train(epoch):
model.train()
train_loss = 0.0
train_acc = 0
step = 1
for batch_idx, (data, label) in enumerate(train_loader):
data, label = data.to(device), label.to(device)
label = label.to(torch.int64) #类型转换
# print("data.shape", data.shape) #torch.Size([32, 3, 200, 200])
# print("label.shape", label.shape) #torch.Size([32]) 在这里不需要将label改成one-hot
optimizer.zero_grad()
outputs = model(data) #torch.Size([32, 101])
loss = F.cross_entropy(outputs, label)
#计算这一个batch的准确率
acc = (outputs.argmax(dim=1) == label).sum().cpu().item() / len(labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += acc
#平均数据
avg_train_acc = train_acc/step
avg_train_loss = train_loss/step
writer.add_scalars(
"Training Loss", {"Training Loss": avg_train_loss},
epoch
)
writer.flush()
return avg_train_acc, avg_train_loss
def val():
model.eval()
train_loss = 0.0
train_acc = 0
step = 1
with torch.no_grad():
for batch_idx, (data, label) in enumerate(train_loader):
data, label = data.to(device), label.to(device)
label = label.to(torch.int64) # 类型转换
optimizer.zero_grad()
outputs = model(data) # torch.Size([32, 101])
loss = F.cross_entropy(outputs, label)
# 计算这一个batch的准确率
acc = (outputs.argmax(dim=1) == label).sum().cpu().item() / len(labels)
train_loss += loss.item()
train_acc += acc
#平均数据
avg_train_acc = train_acc/step
avg_train_loss = train_loss/step
return avg_train_acc, avg_train_loss
全部代码
alexnet.py(将tensorboard部分注释解除在tensorboard中绘制出各类曲线)
from torch.nn import functional as F
from imutils import paths
import cv2
import os
import numpy as np
import torch
from torch import nn, optim
from torchvision.transforms import transforms
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split
from model import AlexNet
from torch.utils.tensorboard import SummaryWriter
#=======================使用tensorboard===================
writer = SummaryWriter('runs/alexnet-101-2')
#=============参数=======================
num_class = 101
epochs = 30
batch_size = 64
PATH = 'Xlnet.pth' #模型参数保存路径
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
path = 'caltech-101/101_ObjectCategories'
image_paths = list(paths.list_images(path)) #返回该目录下所有文件的列表
def data_processor(size=65):
"""
将文件中的图片读取出来并整理成data和labels 共101类
:return:
"""
data = []
labels = []
label_name = []
name2label = {}
for idx, image_path in enumerate(image_paths):
name = image_path.split(os.path.sep)[-2] #获取类别名
#读取图像并进行处理
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) #将BGR转化为RGB
image = cv2.resize(image, (size, size), interpolation=cv2.INTER_AREA)
data.append(image)
label_name.append(name)
data = np.array(data)
label_name = list(dict.fromkeys(label_name)) #利用字典进行去重
label_name = np.array(label_name)
# print(label_name)
# 生成0-100的类标签 对应label_name中的文件名
for idx, name in enumerate(label_name):
name2label[name] = idx #每个类别分配一个标签
for idx, image_path in enumerate(image_paths):
labels.append(name2label[image_path.split(os.path.sep)[-2]])
labels = np.array(labels)
return data, name2label, labels
#返回(8677, 200, 200, 3)的图像数据和0-100的标签序号
data, name2label, labels = data_processor()
# print(data.shape)
# print("===========================")
# print(name2label)
# print("===========================")
# print(labels)
#定义图像变换
# define transforms
train_transform = transforms.Compose(
[transforms.ToPILImage(),
# transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
val_transform = transforms.Compose(
[transforms.ToPILImage(),
# transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
# 将数据集分为训练集验证集以及测试集
# x_train examples: (5205, 200, 200, 3)
# x_test examples: (1736, 200, 200, 3)
# x_val examples: (1736, 200, 200, 3)
(X, x_val, Y, y_val) = train_test_split(data, labels,
test_size=0.2,
stratify=labels,
random_state=42)
(x_train, x_test, y_train, y_test) = train_test_split(X, Y,
test_size=0.25,
random_state=42)
print(f"x_train examples: {x_train.shape}\nx_test examples: {x_test.shape}\nx_val examples: {x_val.shape}")
#==============================数据加载===============================================
class ImageDataset(Dataset):
def __init__(self, images, labels=None, transforms=None):
self.X = images
self.y = labels
self.transforms = transforms
def __len__(self):
return (len(self.X))
def __getitem__(self, i):
data = self.X[i][:]
if self.transforms:
data = self.transforms(data)
if self.y is not None:
return (data, self.y[i])
else:
return data
train_data = ImageDataset(x_train, y_train, train_transform)
val_data = ImageDataset(x_val, y_val, val_transform)
test_data = ImageDataset(x_test, y_test, val_transform)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
#=================构建模型==============================
model = AlexNet(init_weights=True).to(device) #送入GPU
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005) # 随机梯度下降
#训练过程
def train(epoch):
model.train()
train_loss = 0.0
train_acc = 0
step = 1
for batch_idx, (data, label) in enumerate(train_loader):
data, label = data.to(device), label.to(device)
label = label.to(torch.int64) #类型转换
# print("data.shape", data.shape) #torch.Size([32, 3, 200, 200])
# print("label.shape", label.shape) #torch.Size([32]) 在这里不需要将label改成one-hot
optimizer.zero_grad()
outputs = model(data) #torch.Size([32, 101])
loss = F.cross_entropy(outputs, label)
#计算这一个batch的准确率
acc = (outputs.argmax(dim=1) == label).sum().cpu().item() / len(labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += acc
#平均数据
avg_train_acc = train_acc/step
avg_train_loss = train_loss/step
writer.add_scalars(
"Training Loss", {"Training Loss": avg_train_loss},
epoch
)
writer.flush()
return avg_train_acc, avg_train_loss
def val():
model.eval()
train_loss = 0.0
train_acc = 0
step = 1
with torch.no_grad():
for batch_idx, (data, label) in enumerate(train_loader):
data, label = data.to(device), label.to(device)
label = label.to(torch.int64) # 类型转换
optimizer.zero_grad()
outputs = model(data) # torch.Size([32, 101])
loss = F.cross_entropy(outputs, label)
# 计算这一个batch的准确率
acc = (outputs.argmax(dim=1) == label).sum().cpu().item() / len(labels)
train_loss += loss.item()
train_acc += acc
#平均数据
avg_train_acc = train_acc/step
avg_train_loss = train_loss/step
return avg_train_acc, avg_train_loss
def tensorboard_draw():
#初始化一张全为0的图片
images = torch.zeros((1, 3, 65, 65))
# 绘制网络结构图
writer.add_graph(model.to("cpu"), images)
writer.flush()
def select_n_random(data, labels, n=100):
assert len(data) == len(labels)
perm = torch.randperm(len(data))
return data[perm][:n], labels[perm][:n]
def run():
print('start training')
for epoch in range(epochs):
train_acc, train_loss = train(epoch)
print("EPOCH [{}/{}] Train acc {:.4f} Train loss {:.4f} ".format(epoch + 1, epochs, train_acc, train_loss))
torch.save(model.state_dict(), PATH) #保存模型参数
val_acc, val_loss = val()
print("val(): val acc {:.4f} val loss {:.4f} ".format(val_acc, val_loss))
writer.close()
run()
# tensorboard_draw(train_loader)
# tensorboard_draw2()
model.py
import torch
import os
from torch import nn
from torch.nn import functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
from torchvision.datasets import ImageFolder
import torch.optim as optim
import torch.utils.data
# 网络模型构建
class AlexNet(nn.Module):
def __init__(self, num_class=101, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11),
# nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55] 自动舍去小数点后
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.BatchNorm2d(48),
nn.Conv2d(48, 128, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.BatchNorm2d(128),
nn.Conv2d(128, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), #output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(6 * 6 * 128, 2048),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_class),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
# print("x.shape", x.shape) #torch.Size([32, 128, 22, 22])
x = torch.flatten(x, start_dim=1) #拉成一条
# print("x.flatten.shape", x.shape)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') #何教授方法
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) #正态分布赋值
nn.init.constant_(m.bias, 0)
训练结果

由于硬件限制,本次采用了简化版的Alexnet模型(并未改变模型结构,仅仅降低了参数量,将图片大小由224224resize为6565)训练了30轮每轮batch为64(未达到收敛),相信有更强大的硬件支持,效果会更好