transform encoder详细解析
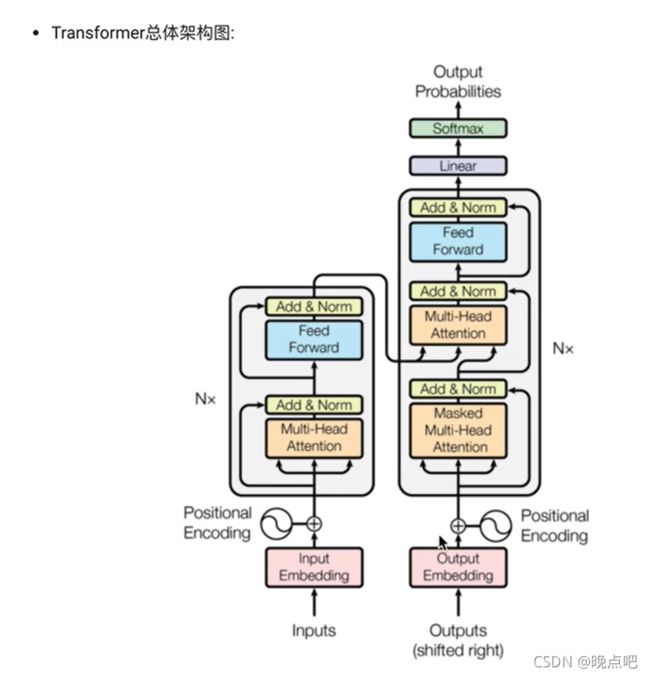
1、transformer 架构图
transformer encoder 和decoder 如下图左右两部分所示
下面主要介绍encoder层
1.1 encder 层包含的子层
- embedding 层
- 位置层
- 多头注意力层
- 全连接层
- 规范化层
- 子连接层
- EncoderLayer (encoder子层)
- Encoder
各层源码详见下面第二章
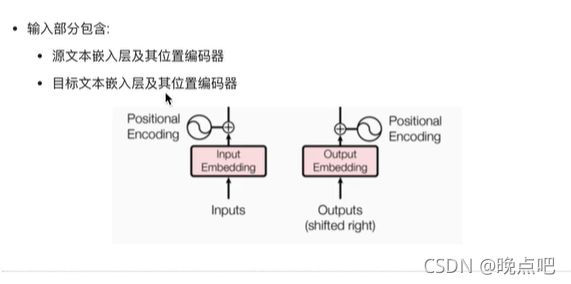
1、embedding 层和位置编码层
embedding layer
import torch
import torch.nn as nn
from torch.autograd import Variable
import math
import numpy as np
import copy
class Embeddings(nn.Module):
def __init__(self,vocab_size,embedding_dim):
super(Embeddings,self).__init__()
self.emb=nn.Embedding(vocab_size,embedding_dim=embedding_dim)
self.embedding_dim=embedding_dim
def forward(self,x):
return self.emb(x)*math.sqrt(self.embedding_dim)
position layer
class PositionalEncoding(nn.Module):
def __init__(self,embedding_dim,dropout,max_len=5000):
super(PositionalEncoding,self).__init__()
self.dropout=nn.Dropout(dropout)
pe=torch.zeros(max_len,embedding_dim)
position=torch.arange(0,max_len,dtype=torch.float32).unsqueeze(1)
div_term=torch.exp(torch.arange(0,embedding_dim,2,dtype=torch.float32)
* -(math.log(10000.0)/embedding_dim))
pe[:,::2]=torch.sin(position*div_term)
pe[:,1::2]=torch.cos(position*div_term)
pe=pe.unsqueeze(0)
self.register_buffer('pe',pe)
print(position.size())
print(div_term.size())
print((position*div_term).size())
def forward(self,x):
x=x+Variable(self.pe[:,:x.size(1)],requires_grad=False)
return self.dropout(x)
两层结果
vocab_size,embedding_dim=1000,512
dropout=0.1
max_len=60
x=Variable(torch.tensor([[100,4,21,4],[6,8,7,321]]))
embedding=Embeddings(vocab_size=vocab_size,embedding_dim=embedding_dim)
embed=embedding(x)
position=PositionalEncoding(embedding_dim,dropout,max_len)
position(embed)
##输出结果如下
torch.Size([60, 1])
torch.Size([256])
torch.Size([60, 256])
tensor([[[ 2.9604, 0.0000, 27.9346, ..., 10.6476, -26.1386, -38.5410],
[ 0.0000, -9.4506, 18.0266, ..., 36.0779, -19.8713, 30.7494],
[-18.7037, -22.6327, 21.2108, ..., 16.6003, -17.6253, -6.6058],
[ 14.0800, -0.1099, 13.9031, ..., 9.4709, 24.1501, 1.5589]],
[[-37.7638, -35.1709, 60.4838, ..., 15.7911, -14.4492, 25.6500],
[ 3.4908, -22.2088, 14.9238, ..., -19.7654, -9.2376, -2.2589],
[ -0.7863, -0.0000, 7.8943, ..., 23.4793, 0.0000, -11.9542],
[ -0.0000, -1.4276, -52.7363, ..., 36.3995, 3.3439, -6.9230]]],
grad_fn=)
2、encoding 编码器实现
2.1 attention
# 掩码示例
def subsequent_mask(size):
attn_shape=(1,size,size)
subsequent_mask=np.triu(np.ones(attn_shape),k=1).astype('uint8')
return torch.from_numpy(1-subsequent_mask)
size=5
subsequent_mask(size)
import torch.nn.functional as F
# attention 示例
def attention(query,key,value,mask=None,dropout=None):
dim=query.size(-1)
scores=torch.matmul(query,key.transpose(-2,-1))/math.sqrt(dim)
if mask is not None :
socres=scores.masked_fill(mask==0,-1e9)
print(scores.size())
p_attn=F.softmax(scores,dim=-1)
print(p_attn.size())
if dropout is not None :
dropout(p_attn)
return torch.matmul(p_attn,value)
mask=subsequent_mask(size)
attention 结果展示
query=key=value=embed_postion
mask=subsequent_mask(embed_postion.size(1))
atten_result=attention(query,key,value,mask=mask,dropout=nn.Dropout(0.1))
atten_result.size()
#torch.Size([2, 4, 512])
2.2 multihead layer
import copy
def copy_model(model,n):
return nn.ModuleList([ copy.deepcopy(model) for _ in range(n)])
class MultiHeadAttention(nn.Module):
def __init__(self,embedding_dim,head,dropout=0.1):
super(MultiHeadAttention,self).__init__()
self.k_dim=embedding_dim//head
self.head=head
self.liners=copy_model(nn.Linear(embedding_dim,embedding_dim),4)
self.dropout=nn.Dropout(dropout)
def forward(self,query,key,value,mask=None):
batch_size=query.size(0)
query,key,value= [ model(x).view(batch_size,-1,self.head,self.k_dim).transpose(2,1)
for model,x in zip(self.liners,(query,key,value))]
# query=query.view(batch_size,-1,self.head,self.k_dim).transpose(2,1)
# key=key.view(batch_size,-1,self.head,self.k_dim).transpose(2,1)
# value=value.view(batch_size,-1,self.head,self.k_dim).transpose(2,1)
if mask is not None:
mask=mask.unsqueeze(0)
attn=attention(query,key,value,mask=mask,dropout=self.dropout)
x =attn.transpose(1,2).contiguous().view(batch_size,-1,self.head*self.k_dim)
return self.liners[0](x)
att=MultiHeadAttention(embedding_dim,head=4)
mask=subsequent_mask(embed_postion.size(1))
muti_att=att(embed_postion,embed_postion,embed_postion,mask=mask)
muti_att.size()
# result 展示
# torch.Size([2, 4, 512])
2.3 ff layer
#全连接层
class PositionwiseFeedForwaed(nn.Module):
def __init__(self,embedding_dim,d_ff,dropout=0.1):
super(PositionwiseFeedForwaed,self).__init__()
self.w1=nn.Linear(embedding_dim,d_ff)
self.w2=nn.Linear(d_ff,embedding_dim)
self.dropout=nn.Dropout(dropout)
def forward(self,x):
return self.w2(self.dropout(torch.relu(self.w1(x))))
pf=PositionwiseFeedForwaed(embedding_dim,64)
ff_result=pf(muti_att)
ff_result.size()
# 结果展示
#torch.Size([2, 4, 512])
2.4 norm layer
# 规范化层
class LayerNorm(nn.Module):
def __init__(self,embedding_dim,eps=1e-6):
super(LayerNorm,self).__init__()
self.a2=nn.Parameter(torch.ones(embedding_dim))
self.b2=nn.Parameter(torch.zeros(embedding_dim))
self.eps=eps
def forward(self,x):
mean=x.mean(-1,keepdim=True)
std=x.std(-1,keepdim=True)
return self.a2*(x-mean)/(std+self.eps)+self.b2
ln=LayerNorm(embedding_dim)
ln_result=ln(ff_result)
ln_result.shape
#结果展示
#torch.Size([2, 4, 512])
2.5 子层连接结构
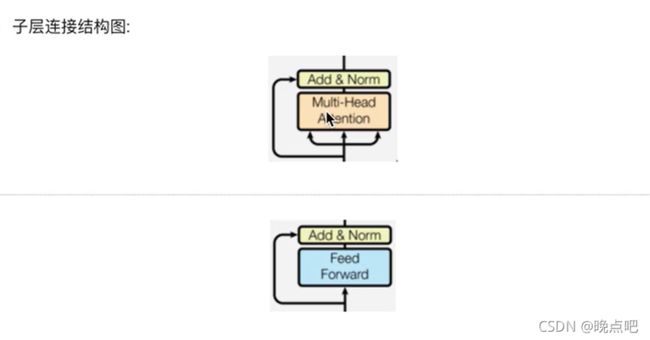
class SublayerConnection(nn.Module):
def __init__(self,embedding_dim,dropout=0.1):
super(SublayerConnection,self).__init__()
self.norm=LayerNorm(embedding_dim=embedding_dim)
self.dropout=nn.Dropout(dropout)
def forward(self,x,sublayer):
return self.norm(x+sublayer(x))
sublayerc=SublayerConnection(embedding_dim=embedding_dim)
# 使用位置层输出
sc_result=sublayerc(embed_postion,lambda embed_postion :att(embed_postion,embed_postion,embed_postion,mask=mask))
sc_result.size()
2.6 encoder layer
encoder layer 即一个下图层

# att=MultiHeadAttention(embedding_dim,head=4)
# feed_forward=PositionwiseFeedForwaed(embedding_dim,64)
class EncoderLayer(nn.Module):
def __init__(self,embedding_dim,att,feed_forward,dropout=0.1):
super(EncoderLayer,self).__init__()
self.att=att
self.feed_forward=feed_forward
self.embedding_dim=embedding_dim
self.sublay_att=SublayerConnection(embedding_dim=embedding_dim)
self.sublay_ff=SublayerConnection(embedding_dim=embedding_dim)
def forward(self,x):
x=self.sublay_att(x,lambda x: self.att(x,x,x))
x=self.sublay_ff(x,lambda x :self.feed_forward(x))
return x
encoderLayer=EncoderLayer(embedding_dim,att,pf)
encoderLayer_result=encoderLayer(embed_postion)
encoderLayer_result.size()
2.7 encoder
所有encoder 部分,即n 个 encoder layer组成
class Encoder(nn.Module):
def __init__(self,n,encoder_layer):
super(Encoder,self).__init__()
self.model_list=copy_model(encoder_layer,n)
self.norm=LayerNorm(encoder_layer.embedding_dim)
def forward(self,x):
for model in self.model_list:
x=model(x)
return self.norm(x)
encoderLayer=EncoderLayer(embedding_dim,att,pf)
encoder=Encoder(8,encoderLayer)
encoder_result=encoder(embed_postion)
encoder_result.size()
3.0 encoder coder 汇总
import torch
import torch.nn as nn
from torch.autograd import Variable
import math
import numpy as np
import copy
import torch.nn.functional as F
# embedding 层
class Embeddings(nn.Module):
def __init__(self,vocab_size,embedding_dim):
super(Embeddings,self).__init__()
self.emb=nn.Embedding(vocab_size,embedding_dim=embedding_dim)
self.embedding_dim=embedding_dim
def forward(self,x):
return self.emb(x)*math.sqrt(self.embedding_dim)
# 位置层
class PositionalEncoding(nn.Module):
def __init__(self,embedding_dim,dropout,max_len=5000):
super(PositionalEncoding,self).__init__()
self.dropout=nn.Dropout(dropout)
pe=torch.zeros(max_len,embedding_dim)
position=torch.arange(0,max_len,dtype=torch.float32).unsqueeze(1)
div_term=torch.exp(torch.arange(0,embedding_dim,2,dtype=torch.float32)
* -(math.log(10000.0)/embedding_dim))
pe[:,::2]=torch.sin(position*div_term)
pe[:,1::2]=torch.cos(position*div_term)
pe=pe.unsqueeze(0)
self.register_buffer('pe',pe)
# print(position.size())
# print(div_term.size())
# print((position*div_term).size())
def forward(self,x):
print(self.pe[:,:x.size(1),:].size())
x=x+Variable(self.pe[:,:x.size(1)],requires_grad=False)
return self.dropout(x)
# encoding layer
def subsequent_mask(size):
attn_shape=(1,size,size)
subsequent_mask=np.triu(np.ones(attn_shape),k=1).astype('uint8')
return torch.from_numpy(1-subsequent_mask)
# attention 计算
def attention(query,key,value,mask=None,dropout=None):
dim=query.size(-1)
scores=torch.matmul(query,key.transpose(-2,-1))/math.sqrt(dim)
if mask is not None :
socres=scores.masked_fill(mask==0,-1e9)
# print(scores.size())
p_attn=F.softmax(scores,dim=-1)
if dropout is not None :
dropout(p_attn)
return torch.matmul(p_attn,value)
def copy_model(model,n):
return nn.ModuleList([ copy.deepcopy(model) for _ in range(n)])
# 多头注意力层
class MultiHeadAttention(nn.Module):
def __init__(self,embedding_dim,head,dropout=0.1):
super(MultiHeadAttention,self).__init__()
self.k_dim=embedding_dim//head
self.head=head
self.liners=copy_model(nn.Linear(embedding_dim,embedding_dim),4)
self.dropout=nn.Dropout(dropout)
def forward(self,query,key,value,mask=None):
batch_size=query.size(0)
query,key,value= [ model(x).view(batch_size,-1,self.head,self.k_dim).transpose(2,1)
for model,x in zip(self.liners,(query,key,value))]
# query=query.view(batch_size,-1,self.head,self.k_dim).transpose(2,1)
# key=key.view(batch_size,-1,self.head,self.k_dim).transpose(2,1)
# value=value.view(batch_size,-1,self.head,self.k_dim).transpose(2,1)
if mask is not None:
mask=mask.unsqueeze(0)
attn=attention(query,key,value,mask=mask,dropout=self.dropout)
x =attn.transpose(1,2).contiguous().view(batch_size,-1,self.head*self.k_dim)
return self.liners[0](x)
#全连接层
class PositionwiseFeedForwaed(nn.Module):
def __init__(self,embedding_dim,d_ff,dropout=0.1):
super(PositionwiseFeedForwaed,self).__init__()
self.w1=nn.Linear(embedding_dim,d_ff)
self.w2=nn.Linear(d_ff,embedding_dim)
self.dropout=nn.Dropout(dropout)
def forward(self,x):
return self.w2(self.dropout(torch.relu(self.w1(x))))
pf=PositionwiseFeedForwaed(embedding_dim,64)
ff_result=pf(muti_att)
ff_result.size()
# 规范化层
class LayerNorm(nn.Module):
def __init__(self,embedding_dim,eps=1e-6):
super(LayerNorm,self).__init__()
self.a2=nn.Parameter(torch.ones(embedding_dim))
self.b2=nn.Parameter(torch.zeros(embedding_dim))
self.eps=eps
def forward(self,x):
mean=x.mean(-1,keepdim=True)
std=x.std(-1,keepdim=True)
return self.a2*(x-mean)/(std+self.eps)+self.b2
# 子连接层
class SublayerConnection(nn.Module):
def __init__(self,embedding_dim,dropout=0.1):
super(SublayerConnection,self).__init__()
self.norm=LayerNorm(embedding_dim=embedding_dim)
self.dropout=nn.Dropout(dropout)
def forward(self,x,sublayer):
return self.norm(x+sublayer(x))
# att=MultiHeadAttention(embedding_dim,head=4)
# feed_forward=PositionwiseFeedForwaed(embedding_dim,64)
class EncoderLayer(nn.Module):
def __init__(self,embedding_dim,att,feed_forward,dropout=0.1):
super(EncoderLayer,self).__init__()
self.att=att
self.feed_forward=feed_forward
self.embedding_dim=embedding_dim
self.sublay_att=SublayerConnection(embedding_dim=embedding_dim)
self.sublay_ff=SublayerConnection(embedding_dim=embedding_dim)
def forward(self,x):
x=self.sublay_att(x,lambda x: self.att(x,x,x))
x=self.sublay_ff(x,lambda x :self.feed_forward(x))
return x
class Encoder(nn.Module):
def __init__(self,n,encoder_layer):
super(Encoder,self).__init__()
self.model_list=copy_model(encoder_layer,n)
self.norm=LayerNorm(encoder_layer.embedding_dim)
def forward(self,x):
for model in self.model_list:
x=model(x)
return self.norm(x)
if __name__=='__main__':
vocab_size,embedding_dim=1000,512
dropout=0.1
max_len=60
x=Variable(torch.tensor([[100,4,21,4],[6,8,7,321]]))
embedding=Embeddings(vocab_size=vocab_size,embedding_dim=embedding_dim)
embed=embedding(x)
position=PositionalEncoding(embedding_dim,dropout,max_len)
embed_postion=position(embed)# 位置 embeding
att=MultiHeadAttention(embedding_dim,head=4) # 多头注意力
pf=PositionwiseFeedForwaed(embedding_dim,64) # 前馈神经网络
encoderLayer=EncoderLayer(embedding_dim,att,pf)
encoder=Encoder(8,encoderLayer)
encoder_result=encoder(embed_postion)
encoder_result.size()