Python编程从入门到实践.——项目二数据可视化
项目2 数据可视化
1 生成数据
1.1 安装matplotlib
1.1.5 matplotlib画廊
https://matplotlib.org/
1.2 绘制简单的折线图
mpl_squares.py
import matplotlib.pyplot as plt
squares = [1, 4,9, 16, 25]
plt.plot(squares)
plt.show()

1.2.1 修改标签文字和线条粗细
import matplotlib.pyplot as plt
squares = [1, 4,9, 16, 25]
plt.plot(squares, linewidth=5)
# 设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers", fontsize=24)
plt.xlabel("Value", fontsize=14)
plt.ylabel("Square of Value", fontsize=14)
# 设置刻度标记的大小
plt.tick_params(axis='both', labelsize=14)
plt.show()

1.2.2 校正图形
当你向plot() 提供一系列数字时,它假设第一个数据点对应的 x 坐标值为0
import matplotlib.pyplot as plt
input_values = [1, 2, 3, 4, 5]
squares = [1, 4,9, 16, 25]
plt.plot(input_values, squares, linewidth=5)
# 设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers", fontsize=24)
plt.xlabel("Value", fontsize=14)
plt.ylabel("Square of Value", fontsize=14)
# 设置刻度标记的大小
plt.tick_params(axis='both', labelsize=14)
plt.show()

1.2.3 使用scatter() 绘制散点图并设置其样式
绘制单个点 scatter()
scatter_squares.py
import matplotlib.pyplot as plt
plt.scatter(2, 4)
plt.show()

import matplotlib.pyplot as plt
plt.scatter(2, 4, s=200)
# 实参s设置了绘制图形时使用的点的尺寸
# 设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers", fontsize=24)
plt.xlabel("Value", fontsize=14)
plt.ylabel("Square of Value", fontsize=14)
# 设置刻度标记的大小
plt.tick_params(axis='both',which='major', labelsize=14)
plt.show()
1.2.4 使用scatter() 绘制一系列点
import matplotlib.pyplot as plt
x_values = [1, 2, 3, 4, 5]
y_values = [1, 4, 9, 16, 25]
plt.scatter(x_values, y_values, s=100)
# 设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers", fontsize=24)
plt.xlabel("Value", fontsize=14)
plt.ylabel("Square of Value", fontsize=14)
# 设置刻度标记的大小
plt.tick_params(axis='both',which='major', labelsize=14)
plt.show()

1.2.5 自动计算数据
import matplotlib.pyplot as plt
x_values = list(range(1, 1001))
y_values = [x**2 for x in x_values]
plt.scatter(x_values, y_values, s=40)
# 设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers", fontsize=24)
plt.xlabel("Value", fontsize=14)
plt.ylabel("Square of Value", fontsize=14)
# 设置每个坐标轴的取值范围
plt.axis([0, 1100, 0, 1100000])
plt.show()

1.2.6 删除数据点的轮廓
点的颜色默认为蓝色点和黑色轮廓
plt.scatter(x_values, y_values,edgecolor="none", s=40)

1.2.7 自定义颜色
plt.scatter(x_values, y_values,c="red", edgecolor="none", s=40)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qFYlQMUJ-1649081284027)(https://s2.loli.net/2022/04/04/iYqgOkBFTINds2E.png)]
plt.scatter(x_values, y_values,c=(0,0,0.6), edgecolor="none", s=40)
要指定自定义颜色,可传递参数c ,并将其设置为一个元组,其中包含三个0~1之间的小数值,它们分别表示红色、绿色和蓝色分量。

plt.scatter(x_values, y_values,c="#ac1f18", edgecolor="none", s=40)


1.2.8 使用颜色映射
颜色映射 (colormap)是一系列颜色,它们从起始颜色渐变到结束颜色。
import matplotlib.pyplot as plt
x_values = list(range(1, 1001))
y_values = [x**2 for x in x_values]
plt.scatter(x_values, y_values,c=y_values,cmap=plt.cm.Blues,
edgecolor="none", s=40)
# 设置图表标题,并给坐标轴加上标签
--snip--

注意 要了解pyplot 中所有的颜色映射,请访问http://matplotlib.org/ ,单击Examples,向下滚动到Color Examples,再单击colormaps_reference。
1.2.9 自动保存图表
plt.savefig('squares_plot.png', bbox_inches='tight')
第二个实参指定将图表多余的空白区域裁剪掉
1.3 随机漫步
1.3.1 创建RandomWalk() 类
from random import choice
class RandomWalk():
"""一个生成随机漫步数据的类"""
def __init__(self, num_points=5000):
"""初始化随机漫步的属性"""
self.num_points = num_points
# 所有随机漫步都始于(0,0)
self.x.values = [0]
self.y.values = [0]
1.3.2 选择方向
from random import choice
class RandomWalk():
"""一个生成随机漫步数据的类"""
def __init__(self, num_points=5000):
"""初始化随机漫步的属性"""
self.num_points = num_points
# 所有随机漫步都始于(0,0)
self.x_values = [0]
self.y_values = [0]
def fill_walk(self):
"""计算随机漫步包含的所有点"""
# 不断漫步,知道列表达到指点长度
while len(self.x_values) < self.num_points:
# 决定前进方向以及沿这个方向前进的距离
x_direction = choice(1, -1)
x_distance = choice([0, 1, 2, 3, 4])
x_step = x_direction * x_distance
y_direction = choice([1, -1])
y_distance = choice([0, 1, 2, 3, 4])
y_step = y_direction * y_distance
# 拒绝原地踏步
if x_step == 0 and y_step == 0:
continue
# 计算下一个点的x和y值
next_x = self.x_values[-1] + x_step
next_y = self.y_values[-1] + y_step
self.x_values.apped(next_x)
self.y_values.append(next_y)
1.3.3 绘制随机漫步图
rw_visual.py
import matplotlib.pyplot as plt
from random_walk import RandomWalk
# 创建一个RandomWalk的实例,并将其包含的点都绘制出来
rw = RandomWalk()
rw.fill_walk()
plt.scatter(rw.x_values, rw.y_values, s=15)
plt.show()

1.3.4 模拟多次随机漫步
import matplotlib.pyplot as plt
from random_walk import RandomWalk
# 只要程序处于活动状态,就不断地模拟随机漫步
while True:
# 创建一个RandomWalk的实例,并将其包含的点都绘制出来
rw = RandomWalk()
rw.fill_walk()
plt.scatter(rw.x_values, rw.y_values, s=15)
plt.show()
keep_running = input("Make anither walk?(y/n):")
if keep_running == "n":
break
1.3.5 设置随机漫步图的样式
1.3.6 给点着色
import matplotlib.pyplot as plt
from random_walk import RandomWalk
# 只要程序处于活动状态,就不断地模拟随机漫步
while True:
# 创建一个RandomWalk的实例,并将其包含的点都绘制出来
rw = RandomWalk()
rw.fill_walk()
point_number = list(range(rw.num_points))
plt.scatter(rw.x_values, rw.y_values,c=point_number,
cmap=plt.cm.Blues,edgecolors="none", s=1)
plt.show()
--snip--

1.3.7 重新绘制起点和终点
import matplotlib.pyplot as plt
from random_walk import RandomWalk
--snip--
# 突出起点和终点
plt.scatter(0, 0, c="green", edgecolors="none", s=50)
plt.scatter(rw.x_values[-1], rw.y_values[-1], c='red',
edgecolors='none',s=50)
plt.show()
--snip--
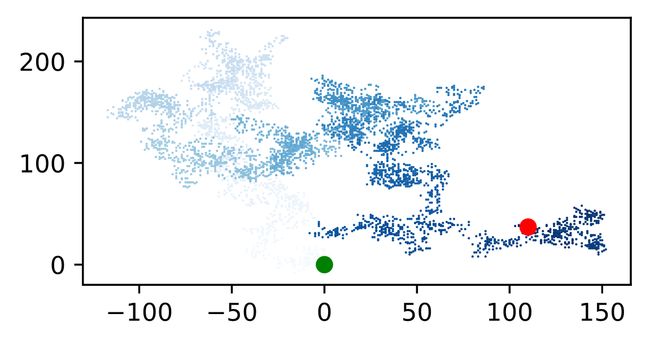
1.3.8 隐藏坐标轴
--snip--
plt.scatter(rw.x_values[-1], rw.y_values[-1], c='red',
edgecolors='none',s=50)
# 隐藏坐标轴
plt.axes().get_xaxis().set_visible(False)
plt.axes().get_yaxis().set_visible(False)
plt.show()
--snip--

1.3.9 增加点数
--snip--
while True:
# 创建一个RandomWalk的实例,并将其包含的点都绘制出来
rw = RandomWalk(50000)
rw.fill_walk()
--snip--

1.3.10 调整尺寸以适合屏幕
rw = RandomWalk()
rw.fill_walk()
# 设置绘图窗口的尺寸
plt.figure(dpi=200, figsize=(10, 6))

plt.figure(dpi=128, figsize=(10, 6))
1.4 使用Pygal模拟掷骰子
可视化包Pygal来生成可缩放的矢量图形文件。
1.4.1 安装Pygal
1.4.2 Pygal画廊
要了解使用Pygal可创建什么样的图表,请查看图表类型画廊:访问http://www.pygal.org/ ,单击Documentation,再单击Chart types。每个示例都包含源代码,让你知道这些图表是如何生成的。
pygal说明书:http://www.pygal.org/en/stable/index.html
1.4.3 创建Die 类
die.py
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 30 17:28:15 2022
@author: zixiao
"""
from random import randint
class Die():
"""表示一个骰子的类"""
def __init__(self, num_sides = 6):
"""骰子默认为6个面"""
self.num_sides = num_sides
def roll(self):
"""返回一个位于1和骰子面数之间的随机值"""
return randint(1, self.num_sides)
1.4.4 掷骰子
from die import Die
# 创建一个D6
die = Die()
# 掷几次骰子,并将结果存储在一个列表中
results = []
for roll_num in range(100):
result = die.roll()
results.append(result)
print(results)
[2, 2, 2, 1, 4, 3, 5, 3, 5, 3, 2, 3, 4, 6, 2, 2, 5, 1, 2, 4, 5, 3, 3, 2, 6, 6, 5, 3, 4, 5, 5, 6, 6, 5, 5, 1, 1, 4, 2, 3, 2, 2, 4, 3, 3, 5, 4, 2, 6, 1, 2, 3, 3, 1, 3, 2, 4, 2, 4, 5, 3, 5, 2, 3, 1, 1, 3, 2, 6, 1, 2, 3, 2, 2, 2, 6, 4, 1, 1, 1, 6, 3, 6, 4, 6, 3, 3, 2, 1, 3, 3, 4, 5, 1, 6, 4, 1, 5, 4, 5]
1.4.5 分析结果
from die import Die
# 创建一个D6
die = Die()
# 掷几次骰子,并将结果存储在一个列表中
results = []
for roll_num in range(100):
result = die.roll()
results.append(result)
# 分析结果
frequencies = []
for value in range(1, die.num_sides+1):
frequency = results.count(value)
frequencies.append(frequency)
print(frequencies)
[16, 18, 15, 19, 19, 13]
1.4.6 绘制直方图
from die import Die
import pygal
# 创建一个D6
die = Die()
# 掷几次骰子,并将结果存储在一个列表中
results = []
for roll_num in range(1000):
result = die.roll()
results.append(result)
# 分析结果
frequencies = []
for value in range(1, die.num_sides+1):
frequency = results.count(value)
frequencies.append(frequency)
# 对结果进行可视化
hist = pygal.Bar()
hist.title = "Results of rolling one D6 1000 times."
hist.x_labels = ['1', '2', '3', '4', '5', '6']
hist.x_title = "Result"
hist.y_title = "Frequency of Result"
hist.add("D6", frequencies)
hist.render_to_file('die_visual.svg')

1.4.7 同时掷两个骰子
from die import Die
import pygal
# 创建一个D6
die1 = Die()
die2 = Die()
# 掷几次骰子,并将结果存储在一个列表中
results = []
for roll_num in range(1000):
result = die1.roll() + die2.roll()
results.append(result)
# 分析结果
frequencies = []
max_num_sides = die1.num_sides + die1.num_sides
for value in range(2, max_num_sides+1):
frequency = results.count(value)
frequencies.append(frequency)
# 对结果进行可视化
hist = pygal.Bar()
hist.title = "Results of rolling two D6 dice 1000 times."
hist.x_labels = ['2', '3', '4', '5','6','7','8',
'9','10','11','12']
hist.x_title = "Result"
hist.y_title = "Frequency of Result"
hist.add("D6 + D6", frequencies)
hist.render_to_file('die_visual.svg')

1.4.8 同时掷两个面数不同的骰子
from die import Die
import pygal
# 创建一个D6
die1 = Die()
die2 = Die(10)
# 掷几次骰子,并将结果存储在一个列表中
results = []
for roll_num in range(50000):
result = die1.roll() + die2.roll()
results.append(result)
# 分析结果
frequencies = []
max_num_sides = die1.num_sides + die2.num_sides
for value in range(2, max_num_sides+1):
frequency = results.count(value)
frequencies.append(frequency)
# 对结果进行可视化
hist = pygal.Bar()
hist.title = "Results of rolling D6 D10 dice 50 000 times."
hist.x_labels = ['2', '3', '4', '5','6','7','8',
'9','10','11','12','13','14','15','16']
hist.x_title = "Result"
hist.y_title = "Frequency of Result"
hist.add("D6 + D10", frequencies)
hist.render_to_file('die_visual.svg')

2 下载数据
2.1 CSV文件格式
2.1.1 分析CSV文件头
highs_lows.py
import csv
filename = 'data/sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
print(header_row)
模块csv 包含函数next() ,调用它并将阅读器对象传递给它时,它将返回文件中的下一行。
[‘AKDT’, ‘Max TemperatureF’, ‘Mean TemperatureF’, ‘Min TemperatureF’, ‘Max Dew PointF’, ‘MeanDew PointF’, ‘Min DewpointF’, ‘Max Humidity’, ’ Mean Humidity’, ’ Min Humidity’, ’ Max Sea Level PressureIn’, ’ Mean Sea Level PressureIn’, ’ Min Sea Level PressureIn’, ’ Max VisibilityMiles’, ’ Mean VisibilityMiles’, ’ Min VisibilityMiles’, ’ Max Wind SpeedMPH’, ’ Mean Wind SpeedMPH’, ’ Max Gust SpeedMPH’, ‘PrecipitationIn’, ’ CloudCover’, ’ Events’, ’ WindDirDegrees’]
2.1.2 打印文件头及其位置
highs_lows.py
import csv
filename = 'data/sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
for index, column_header in enumerate(header_row):
print(index, column_header)
0 AKDT
1 Max TemperatureF
2 Mean TemperatureF
–snip–
21 Events
22 WindDirDegrees
2.1.3 提取并读取数据
首先读取每天的最高气温:
highs_lows.py
import csv
# 从文件中获取最高气温
filename = 'data/sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
hights = []
for row in reader:
hights.append(row[1])
print(hights)
遍历文件中的各行
下面使用int() 将这些字符串转换为数字,让matplotlib能够读取它们:
highs_lows.py
--snip--
hights = []
for row in reader:
hight = int(row[1])
hights.append(hight)
print(hights)
[64, 71, 64, 59, 69, 62, 61, 55, 57, 61, 57, 59, 57, 61, 64, 61, 59, 63, 60, 57, 69, 63, 62, 59, 57, 57, 61, 59, 61, 61, 66]
2.1.4 绘制气温图表
highs_lows.py
import csv
from matplotlib import pyplot as plt
--snip--
# 根据书籍绘制图形
fig = plt.figure(dpi=128, figsize = (10, 6))
plt.plot(highs, c="red")
# 设置图形的格式
plt.title("Daily high temperatures, July 2014", fontsize=24)
plt.xlabel("", fontsize=16)
plt.ylabel("Temperature(F)",fontsize=16)
plt.tick_params(axis="both", which='major', labelsize=16)
plt.show()

2.1.5 模块datetime
模块datetime中设置日期和时间格式的实参
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iQ8uLAmj-1649081284067)(https://s2.loli.net/2022/04/04/ewycGLoOEIrsNz1.png)]

2.1.6 在图表中添加日期
highs_lows.py
import csv
from datetime import datetime
from matplotlib import pyplot as plt
--snip--
dates, highs = [], []
for row in reader:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
dates.append(current_date)
high = int(row[1])
highs.append(high)
--snip--
# 设置图形的格式
plt.title("Daily high temperatures, July 2014", fontsize=24)
plt.xlabel("", fontsize=16)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)",fontsize=16)
plt.tick_params(axis="both", which='major', labelsize=16)
plt.show()

我们调用了fig.autofmt_xdate() 来绘制斜的日期标签,以免它们彼此重叠
2.1.7 涵盖更长的时间
import csv
from datetime import datetime
from matplotlib import pyplot as plt
# 从文件中获取最高气温
filename = 'data/sitka_weather_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs = [], []
for row in reader:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
dates.append(current_date)
high = int(row[1])
highs.append(high)
# 根据书籍绘制图形
fig = plt.figure(dpi=128, figsize = (10, 6))
plt.plot(dates, highs, c="red")
# 设置图形的格式
plt.title("Daily high temperatures - 2014", fontsize=24)
plt.xlabel("", fontsize=16)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)",fontsize=16)
plt.tick_params(axis="both", which='major', labelsize=16)
plt.show()

2.1.8 再绘制一个数据系列
--snip--
dates, highs, lows = [], [], []
for row in reader:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
dates.append(current_date)
high = int(row[1])
highs.append(high)
low = int(row[3])
lows.append(low)
# 根据书籍绘制图形
fig = plt.figure(dpi=128, figsize = (10, 6))
plt.plot(dates, highs, c="red")
plt.plot(dates,lows, c="blue")
# 设置图形的格式
plt.title("Daily high and low temperatures - 2014", fontsize=24)
--snip--

2.1.9 给图表区域着色
--snip--# 根据书籍绘制图形
fig = plt.figure(dpi=128, figsize = (10, 6))
plt.plot(dates, highs, c="red")
plt.plot(dates,lows, c="blue")
--snip--

2.1.10 错误检查
--snip--
dates, highs, lows = [], [], []
for row in reader:
try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
high = int(row[1])
low = int(row[3])
except ValueError:
print(current_date, "missing data")
else:
dates.append(current_date)
highs.append(high)
lows.append(low)
# 根据书籍绘制图形
--snip--
# 设置图形的格式
plt.title("Daily high and low temperatures - 2014\nDeath value, CA", fontsize=24)
plt.xlabel("", fontsize=16)
--snip--
2014-02-16 00:00:00 missing data

2.2 制作世界人口地图:JSON格式
2.2.2 提取相关的数据
import json
# 将数据加载到一个列表中
filename = 'data/population_data.json'
with open(filename) as f:
pop_data = json.load(f)
# 打印每个国家2010年的人口数量
for pop_dict in pop_data:
if pop_dict["Year"] == "2010":
country_name = pop_dict["Country Name"]
population = pop_dict['Value']
print(country_name + ":" + population)
Arab World:357868000
Caribbean small states:6880000
East Asia & Pacific (all income levels):2201536674
–snip–
Zambia:12927000
Zimbabwe:12571000
2.2.3 将字符串转换为数字值
# 打印每个国家2010年的人口数量
for pop_dict in pop_data:
if pop_dict["Year"] == "2010":
country_name = pop_dict["Country Name"]
population = int(pop_dict['Value'])
print(country_name + ":" + str(population))

Python不能直接将包含小数点的字符串’1127437398.85751’ 转换为整数
# 打印每个国家2010年的人口数量
for pop_dict in pop_data:
if pop_dict["Year"] == "2010":
country_name = pop_dict["Country Name"]
population = int(float(pop_dict['Value']))
print(country_name + ":" + str(population))
Arab World:357868000
Caribbean small states:6880000
East Asia & Pacific (all income levels):2201536674
–snip–
Zambia:12927000
Zimbabwe:12571000
2.2.4 获取两个字母的国别码
from pygal_maps_world.i18n import COUNTRIES
for country_code in sorted(COUNTRIES.keys()):
print(country_code, COUNTRIES[country_code])
ad Andorra
ae United Arab Emirates
af Afghanistan
–snip–
zm Zambia
zw Zimbabwe
country_codes.py
from pygal_maps_world.i18n import COUNTRIES
def get_country_code(country_name):
"""根据指定的公家,返回pygal使用的两个字母的国别码"""
for code, name in COUNTRIES.items():
if name == country_name:
return code
# 如果没有找到指定的国家,就返回None
return None
print(get_country_code('Andorra'))
print(get_country_code('United Arab Emirates'))
print(get_country_code('Afghanistan'))
ad
ae
af
world_population.py
import json
from country_codes import get_country_code
--snip--
# 打印每个国家2010年的人口数量
for pop_dict in pop_data:
if pop_dict["Year"] == "2010":
country_name = pop_dict["Country Name"]
population = int(float(pop_dict['Value']))
code = get_country_code(country_name)
if code:
print(code + ":" + str(population))
else:
print('ERROR - ' + country_name)
ERROR - Arab World
ERROR - Caribbean small states
ERROR - East Asia & Pacific (all income levels)
–snip–
af:34385000
al:3205000
dz:35468000
ERROR - American Samoa
ad:84864
–snip–
zm:12927000
zw:12571000
2.2.5 制作世界地图
import pygal_maps_world.maps
wm = pygal_maps_world.maps.World()
wm.title = 'North, Central, and South America'
wm.add('North America', ['ca','mx', 'us'])
wm.add('Central America', ['bz', 'cr', 'gt', 'hn', 'ni', 'pa', 'sv'])
wm.add('South America', ['ar','bo','br','cl','co','ec',
'gf', 'gy', 'pe','py','sr','uy','ve'])
wm.render_to_file("americas.svg")
如果图片打开错误,可试试使用谷歌浏览器打开

2.2.6 在世界地图上呈现数字数据
na_populations.py
import pygal_maps_world.maps
wm = pygal_maps_world.maps.World()
wm.title = 'Populations of Countries in North America'
wm.add('North America',{'ca':34126000,'us':309349000,'mx':113423000})
wm.render_to_file('na.populations.svg')

2.2.7 绘制完整的世界人口地图
world_population.py
import json
import pygal_maps_world.maps
from country_codes import get_country_code
# 将数据加载到一个列表中
filename = 'data/population_data.json'
with open(filename) as f:
pop_data = json.load(f)
# 打印每个国家2010年的人口数量
cc_populations = {} ## 构建一个空的字典
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country = pop_dict['Country Name']
population = int(float(pop_dict['Value']))
code = get_country_code(country)
if code:
cc_populations[code] = population
wm = pygal_maps_world.maps.World()
wm.title = "World Population in 2010, by Country"
wm.add('2010', cc_populations)
wm.render_to_file('world_population.svg')

2.2.8 根据人口数量将国家分组
根据人口数量分成三组
--snip--
# 将数据加载到一个列表中
--snip--
# 打印每个国家2010年的人口数量
--snip--
# 根据人口数量将所有的国家分成三组
cc_pops_1, cc_pops_2, cc_pops_3 = {},{},{}
for cc, pop in cc_populations.items():
if pop < 10000000:
cc_pops_1[cc] = pop
elif pop < 1000000000:
cc_pops_2[cc] = pop
else:
cc_pops_3[cc] = pop
# 看看每组分别包含多少国家
print(len(cc_pops_1), len(cc_pops_2), len(cc_pops_3))
wm = pygal_maps_world.maps.World()
wm.title = "World Population in 2010, by Country"
wm.add('2010', cc_pops_1)
wm.add('2010', cc_pops_2)
wm.add('2010', cc_pops_3)
wm.render_to_file('world_population.svg')
85 69 2

2.2.9 使用Pygal设置世界地图的样式
world_population.py
--snip--
from pygal.style import RotateStyle
--snip--
wm_style = RotateStyle('#336699')
wm = pygal_maps_world.maps.World(style=wm_style)
--snip--

2.2.10 加亮颜色主题
--snip--
from pygal.style import RotateStyle as RS, LightColorizedStyle as LCS
--snip--
wm_style = RS('#336699',base_style=LCS)
wm = pygal_maps_world.maps.World(style=wm_style)
wm.title = "World Population in 2010, by Country"
wm.add('2010', cc_pops_1)
wm.add('2010', cc_pops_2)
wm.add('2010', cc_pops_3)
wm.render_to_file('world_population.svg')
3 使用API
3.1 使用Web API
3.1.1 Git和GitHub
3.1.2 使用API调用请求数据
https://api.github.com/search/repositories?q=language:python&sort=stars
3.1.3 安装requests
$ pip install --user requests
3.1.4 处理API响应
import requests
# 执行API调用并存储响应
url = "https://api.github.com/search/repositories?q=language:python&sort=stars"
r = requests.get(url)
print("Status code:", r.status_code)
# 将API响应存储在一个变量中
response_dict = r.json()
# 处理结果
print(response_dict.keys())
Status code: 200
dict_keys([‘total_count’, ‘incomplete_results’, ‘items’])
状态码为200
3.1.5 处理响应字典
import requests
# 执行API调用并存储响应
url = "https://api.github.com/search/repositories?q=language:python&sort=stars"
r = requests.get(url)
print("Status code:", r.status_code)
# 将API响应存储在一个变量中
response_dict = r.json()
print("Total repositories:", response_dict['total_count'])
# 探索有关仓库的信息
repo_dicts = response_dict['items']
print('Repositories returned:', len(repo_dicts))
# 研究第一个仓库
repo_dict = repo_dicts[0]
print("\nKeys:", len(repo_dict))
for key in sorted(repo_dict.keys()):
print(key)
Status code: 200
Total repositories: 8599845
Repositories returned: 30
Keys: 78
allow_forking
archive_url
–snip–
watchers
watchers_count
python_repos.py
--snip--
# 探索有关仓库的信息
repo_dicts = response_dict['items']
print('Repositories returned:', len(repo_dicts))
# 研究第一个仓库
repo_dict = repo_dicts[0]
print('Name:', repo_dict['name'])
print('Owner:', repo_dict['owner']['login'])
print('Stars:', repo_dict['stargazers_count'])
print('Repository:',repo_dict['html_url'] )
print("Created:", repo_dict["created_at"])
print('Updated:',repo_dict['updated_at'])
print('Description:', repo_dict['description'])
Status code: 200
Total repositories: 8966328
Repositories returned: 30
Name: public-apis
Owner: public-apis
Stars: 187542
Repository: https://github.com/public-apis/public-apis
Created: 2016-03-20T23:49:42Z
Updated: 2022-04-04T06:01:17Z
Description: A collective list of free APIs
3.1.6 概述最受欢迎的仓库
import requests
# 执行API调用并存储响应
url = "https://api.github.com/search/repositories?q=language:python&sort=stars"
r = requests.get(url)
print("Status code:", r.status_code)
# 将API响应存储在一个变量中
response_dict = r.json()
print("Total repositories:", response_dict['total_count'])
# 探索有关仓库的信息
repo_dicts = response_dict['items']
print('Repositories returned:', len(repo_dicts))
print('\nSelected information about each repository:')
for repo_dict in repo_dicts:
print('\nName:', repo_dict['name'])
print('Owner:', repo_dict['owner']['login'])
print('Stars:', repo_dict['stargazers_count'])
print('Repository:',repo_dict['html_url'])
print('Description:', repo_dict['description'])
Status code: 200
Total repositories: 8799051
Repositories returned: 30
Selected information about each repository:
Name: public-apis
Owner: public-apis
Stars: 187544
Repository: https://github.com/public-apis/public-apis
Description: A collective list of free APIs
Name: system-design-primer
Owner: donnemartin
Stars: 170436
Repository: https://github.com/donnemartin/system-design-primer
Description: Learn how to design large-scale systems. Prep for the system design interview. Includes Anki flashcards.
3.1.7 监视API的速率限制
3.2 使用Pygal可视化仓库
import requests
import pygal
from pygal.style import LightColorizedStyle as LCS, LightenStyle as LS
# 执行API调用并存储响应
url = "https://api.github.com/search/repositories?q=language:python&sort=stars"
r = requests.get(url)
print("Status code:", r.status_code)
# 将API响应存储在一个变量中
response_dict = r.json()
print("Total repositories:", response_dict['total_count'])
# 探索有关仓库的信息
repo_dicts = response_dict['items']
names, stars = [], []
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
# 可视化
my_style = LS('#333366', base_style=LCS)
chart = pygal.Bar(style=my_style,x_label_rotation=45,
show_legend=False)
chart.title = 'Most-Starred Python Projects on GitHub'
chart.x_labels = names
chart.add(" ",stars)
chart.render_to_file('python_repos.svg')
x_label_rotation=45 让标签绕x轴旋转45度;chart.add(" ",stars)标签设为空字符

my_style = LS(‘#333366’, base_style=LCS) 可以更改颜色
例如将颜色改为**海棠红**my_style = LS(‘#f03752’, base_style=LCS)

3.2.1 改进Pygal图表
import requests
import pygal
from pygal.style import LightColorizedStyle as LCS, LightenStyle as LS
# 执行API调用并存储响应
url = "https://api.github.com/search/repositories?q=language:python&sort=stars"
r = requests.get(url)
print("Status code:", r.status_code)
# 将API响应存储在一个变量中
response_dict = r.json()
print("Total repositories:", response_dict['total_count'])
# 探索有关仓库的信息
repo_dicts = response_dict['items']
names, stars = [], []
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
# 可视化
my_style = LS('#333366', base_style=LCS)
my_config = pygal.Config()
my_config.x_label_rotation = 45
my_config.show_legend = False
my_config.title_font_size = 24
my_config.label_font_size = 14
my_config.major_label_font_size = 18 # 设置主标签大小
my_config.truncate_label = 15 # 将较长的项目名缩短为15个字符
my_config.show_y_guides = False # 以隐藏图表中的水平线
my_config.width = 1000 # 自定义宽度
chart = pygal.Bar(my_config, style=my_style)
chart.title = 'Most-Starred Python Projects on GitHub'
chart.x_labels = names
chart.add(" ",stars)
chart.render_to_file('python_repos.svg')
关于无法区分主副标签的问题参考https://blog.csdn.net/weixin_43091089/article/details/99792892

my_style = LS(‘#333366’, major_label_font_size= 18, base_style=LCS)
或者:my_style.major_label_font_size= 18

3.2.2 添加自定义工具提示
在Pygal中,将鼠标指向条形将显示它表示的信息,这通常称为工具提示 。
import pygal
from pygal.style import LightColorizedStyle as LCS, LightenStyle as LS
my_style = LS('#333366', base_style=LCS)
chart = pygal.Bar(style=my_style, x_label_rotation = 45,
show_legend = False)
chart.title = 'Python Projects'
chart.x_labels = ["httpie", 'django', 'flask']
plot_dicts = [
{'value':16101, 'label':'Description of httpie.'},
{'value':15028, 'label':'Description of django.'},
{'value':14798, 'label':'Description of flask.'},
]
chart.add('', plot_dicts)
chart.render_to_file('bar_descriptions.svg')

3.2.3 根据数据绘图
--snip--
# 探索有关仓库的信息
repo_dicts = response_dict['items']
names, plot_dicts = [], []
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
plot_dict = {'value': repo_dict['stargazers_count'],
'label': repo_dict['description'],
}
plot_dicts.append(plot_dict)
# 可视化
--snip--
chart.add(" ",plot_dicts)
chart.render_to_file('python_repos.svg')

3.2.4 在图表中添加可单击的链接
--snip--
# 探索有关仓库的信息
repo_dicts = response_dict['items']
names, plot_dicts = [], []
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
plot_dict = {'value': repo_dict['stargazers_count'],
'label': repo_dict['description'],
'xlink': repo_dict['html_url'],
}
plot_dicts.append(plot_dict)
# 可视化
--snip--

3.3 Hacker News API
Hacker News
https://hacker-news.firebaseio.com/v0/item/9884165.json
import requests
from operator import itemgetter
# 执行API调用并存储响应
url = 'https://hacker-news.firebaseio.com/v0/topstories.json'
r = requests.get(url)
print("Status code:", r.status_code)
# 处理有关没骗文章的信息
submission_ids = r.json()
submission_dicts = []
for submission_id in submission_ids[:30]:
# 对于每篇文章,都执行一个API调用
url = ('https://hacker-news.firebaseio.com/v0/item/' +
str(submission_id) + '.json')
submission_r = requests.get(url)
print(submission_r.status_code)
response_dict = submission_r.json()
submission_dict = {
'title':response_dict['title'],
'link': 'http://news.ycombinator.com/item?id=' +
str(submission_id),
'comments':response_dict.get('descendants', 0)
}
submission_dicts.append(submission_dict)
submission_dicts = sorted(submission_dicts,
key=itemgetter('comments'),
reverse=True)
for submission_dict in submission_dicts:
print("\nTitle:",submission_dict['title'])
print("Discussion link:", submission_dict['link'])
print('Comments:', submission_dict['comments'])