MapReduce大数据处理技术课程复习提纲
Mapreduce课程接近尾声,在此将之前课上的内容做一个简要的总结。
第一章 .并行计算与大数据处理技术简介
围绕着五大问题:为什么需要并行计算?并行计算技术的分类有哪些?并行计算存在的主要技术问题是什么?MPI并行程序设计模式的基本内容是什么?为什么我们现在需要打过么数据并行处理技术?展开。
为什么需要并行计算?
(1)不断提高计算机的性能是从计算机一开始被实际的制造出来enginner就已经开始追求的目标!
之前如我们在学习组原时所主要学习的体系结构上的哪些优化设计方法就是围绕着这一目标的:
1,提高处理器字长;2,提高芯片上的集成度(Moore‘s Law);3,多级流水线等微体系结构技术;4,提高处理器的频率(clock rate)。问题是正如摩尔定律已经接近失灵一样,这些单核的性能处理技术存在着物理上的upper bound或者说工程技术难度上的ceiling。(集成度墙、ILP墙、存储墙、功耗墙)
接着人们将关注点转向多核/众核技术。
(2) 人类对计算机技术的应用越来越广泛,对计算性能的需求也越来越大!超大实时数据处理量、超大计算量、计算复杂度任务。
而这一切问题,目前最好的solution就是使用并行计算技术!
对于programmer而言则是:
并行计算技术的分类有哪些?
按不同的标准有不同的分类方法:
(1)按数据和指令处理结构分类:弗林(Flynn)分类: SISD、SIMD、MISD、MIMD。
(2)按并行的类型(层次):位级并行、指令级并行、线程级并行(数据型并行、任务型并行)。
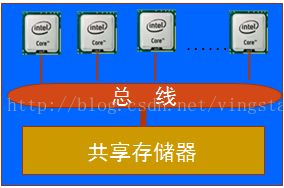
(3)按不同的存储访问结构分类:shared Memory、distributed and shared memory、distributed memory。
、
(4)按系统类型分类:Multicore/Manycore、SMP(SymmetricMultiprocessing、MPP(MassiveParallel Processing、Cluster、Grid(5)按计算特征分类:数据密集型、计算密集型、两者混合型
(6)按并行程序设计模式/方法分类:共享内存变量、消息传递(如MPI)、MapReduce方式)。
并行计算存在的主要技术问题是什么? 怎么存 以及怎么算的问题!

S是加速比,P是程序可并行比例 N是处理器数目 (可推出一个并行程序可加速程度是有限制的,并非可无限加速,并非处理器越多越好)
(具体的看,这些技术问题在上一问题,如何分类,中的各种不同角度上具有体现,所以解决这一问题是一个综合性问题。)
MPI并行程序设计技术
主要是介绍这一在MapReduce之前出现的较为流行的编程模型的基本内容,看看并行编程模式的一般需求以及之前解决方案的优缺点。
MPI主要功能
用常规语言编程方式,所有节点运行同一个程序,但处理不同的数据
提供点对点通信(Point-point communication)
提供节点集合通信(Collective communication)
MPI并行程序设计接口
基本编程接口
MPI提供了6个最基本的编程接口,理论上任何并行程序都可以通过这6个基本API实现
1. MPI_Init(argc,argv) : 初始化MPI,开始MPI并行计算程序体
2. MPI_Finalize(): 终止MPI并行计算
3. MPI_Comm_Size(comm, size): 确定指定范围内处理器/进程数目
4. MPI_Comm_Rank(comm, rank) : 确定一个处理器/进程的标识号
5. MPI_Send(buf, count,datatype,dest, tag, comm): 发送一个消息
6. MPI_Recv (buf, count,datatype, source, tag,comm, status): 接受消息
size:进程数,rank:指定进程的ID
comm:指定一个通信组(communicator)
Dest:目标进程号,source:源进程标识号,tag:消息标签
点对点通信
同步通信:阻塞式通信,等待通信操作完成后才返回
MPI_Send (buf, count,datatype,dest, tag, comm):发送一个消息(tag是为了指定某一次通信session?!)
MPI_Recv (buf, count,datatype, source, tag,comm, status):接受消息
同步通信时一定要等到通信操作完成,这会造成处理器空闲,
因而可能导致系统效率下降,为此MPI提供异步通信功能
异步通信:非阻塞式通信,不等待通信操作完成即返回
MPI_ISend (buf, count, datatype,dest, tag,comm, request):异步发送
MPI_IRecv (buf, count,datatype, source, tag, comm, status, request) 异步接受消息
MPI_Wait (request, status): 等待非阻塞数据传输完成
MPI_Test (request, flag,status): 检查是否异步数据传输确实完成
#include
#include
int main(int argc, char** argv)
{
int myid,numprocs, source;
MPI_Status status; char message[100];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
if (myid !=0) /* 其他进程,向0进程发送HelloWorld信息*/
{ strcpy(message, “Hello World!”);
MPI_Send(message,strlen(message)+1, MPI_CHAR,0,99,MPI_COMM_WORLD);
} else /* 0进程负责从其他进程接受信息并输出*/
{ for (source = 1; source < numprocs; source++)
{ MPI_Recv(message, 100, MPI_CHAR, source,99,MPI_COMM_WORLD, &status);
printf("I am process %d. I recv string '%s' from process%d.\n", myid,message,source);
}
}
MPI_Finalize();
}
节点集合通信接口
同步(Barrier)
MPI_Barrier:设置同步障使所有进程的执行同时完成
数据移动(Data movement)
MPI_BCAST: 一对多的广播式发送
MPI_GATHER:多个进程的消息以某种次序收集到一个进程
MPI_SCATTER:将一个信息划分为等长的段依次发送给其它进程
数据规约(Reduction)
MPI_Reduce:将一组进程的数据按照指定的操作方式规约到一起并传送给一个进程
数据规约操作
将一组进程的数据按照指定的操作方式规约到一起并传送给一个进程
MPI_Reduce(sendbuf,recvbuf, count,datatype, op, root,comm)【在这时我们的理解就要注意,这时一个整体软件框架上的操作,不能仅仅的看做是某一个process上的一条命令!】
其中规约操作op可设为下表定义的操作之一:
MPI_MAX 求最大值 MPI_MIN 求最小值
MPI_SUM 求和 MPI_PROD 求积
MPI_LAND 逻辑与 MPI_BAND 按位与
MPI_LOR 逻辑或 MPI_BOR 按位或
MPI_LXOR 逻辑异或 MPI_BXOR 按位异或
MPI_MAXLOC 最大值和位置 MPI_MINLOC 最小值和位置
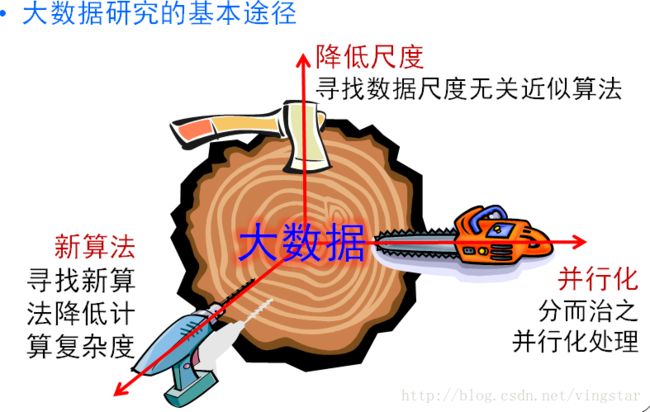
for(i=myid;i { /* 根据节点数目将N个矩形分为图示的多个颜色组*/ local +=x*x*dx; /*矩形面积=高度x宽度=y*dx */ } 为什么需要大数据并行处理? 现实应用的需要! 图灵奖获得者Jim Gray:2007年最后一次演讲中提出“数据密集型科学发现(Data-Intensive Scientific Discovery)” 将成为科学研究的第四范式 数据处理能力大幅落后于数据增长速度
大数据隐含着更准确的事实 大数据的特点 (4个V+1个C): Volume: 大容量,TB-ZB Variety: 多样性 Velocity: 时效性 Veracity: 准确性 Complexity:复杂性
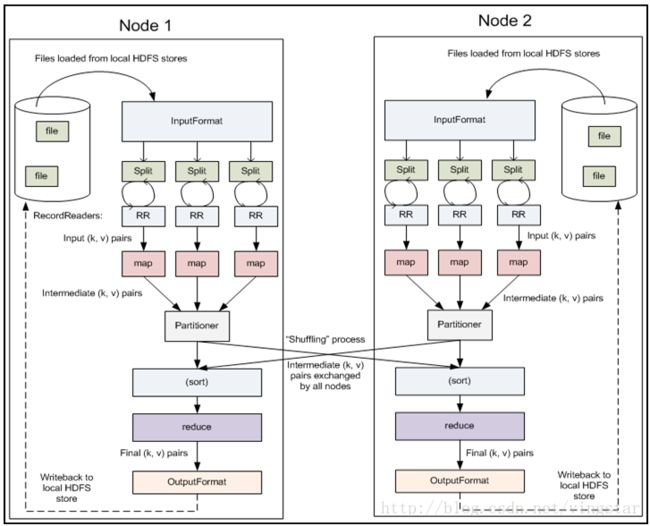
MapReduce简介 什么是MapReduce? MapReduce是面向大规模数据并行处理的: 允许用市场上现成的普通PC或性能较高的刀架或机架式服务器,构成一个包含数千个节点的分布式并行计算集群 提供了一个庞大但设计精良的并行计算软件构架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行子任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算中的很多复杂细节交由系统负责处理,大大减少了软件开发人员的负担 借助于函数式语言中的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了完整的并行编程接口,完成大规模数据处理 (。。。。各种喊口号式的展望!用来忽悠忽悠很有用~哈) (其实想想如何从和IoT物联网向对比的角度看一下,两者作为先后出现的比较火热的技术还是有挺多相似指出的,从各种分层、各种技术层面的新问题,各种较大范围的应用等等···) Ch.2.MapReduce简介 (下面这一段基本上点明了MR的主要的构思,十分具有总结性!结合前面介绍的MPI实例加以体会这种更加抽象层次的进步) 大规模数据处理时,MapReduce在三个层面上的基本构思 如何对付大数据处理:分而治之 对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略 上升到抽象模型:Mapper与Reducer MPI等并行计算方法缺少高层并行编程模型,为了克服这一缺陷,MapReduce借鉴了Lisp函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型 上升到构架:统一构架,为程序员隐藏系统层细节 MPI等并行计算方法缺少统一的计算框架支持,程序员需要考虑数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节 如何对付大数据处理:分而治之 什么样的计算任务可进行并行化计算? 不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算! 2.构建抽象模型:Map与Reduce 下图非常核心: MapReduce中的Map和Reduce操作的抽象描述 MapReduce借鉴了函数式程序设计语言Lisp中的思想,定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现: 输入:键值对(k1; v1)表示的数据 处理:文档数据记录(如文本文件中的行,或数据表格中的行)将以“键值对”形式传入map函数;map函数将处理这些键值对,并以另一种键值对形式输出处理的一组键值对中间结果[(k2; v2)] 输出:键值对[(k2; v2)]表示的一组中间数据 输入: 由map输出的一组键值对[(k2; v2)] 将被进行合并处理将同样主键下的不同数值合并到一个列表[v2]中,故reduce的输入为(k2; [v2]) 处理:对传入的中间结果列表数据进行某种整理或进一步的处理,并产生最终的某种形式的结果输出[(k3; v3)] 。 输出:最终输出结果[(k3; v3)] Map和Reduce为程序员提供了一个清晰的操作接口抽象描述 由于两个阶段之间在对应维度上都可以进行正交的数据划分,所以可以分布式并行化处理。 上升到框架:自动并行化并隐藏底层实现细节
MapReduce提供一个统一的计算框架,可完成: MapReduce提供的主要功能*
MR在工程上的主要架构思想(一切以实际上能提高处理速度为目标): 向“外”横向扩展,而非向“上”纵向扩展 Scale “out", not “up” 即MapReduce集群的构筑选用价格便宜、易于扩展的大量低端商用服务器,而非价格昂贵、不易扩展的高端服务器(SMP)
失效被认为是常态 Assume failuresare common 把处理向数据迁移 Moving processingto the data MapReduce采用了数据/代码互定位的技术方法,计算节点将首先将尽量负责计算其本地存储的数据,以发挥数据本地化特点(locality),仅当节点无法处理本地数据时,再采用就近原则寻找其它可用计算节点,并把数据传送到该可用计算节点。
顺序处理数据、避免随机访问数据 Process datasequentially and avoid random access
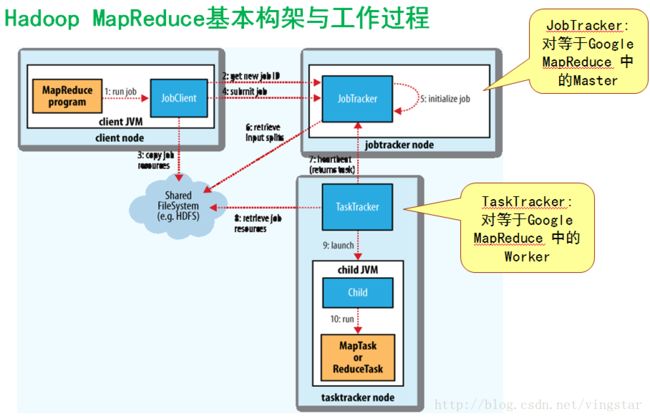
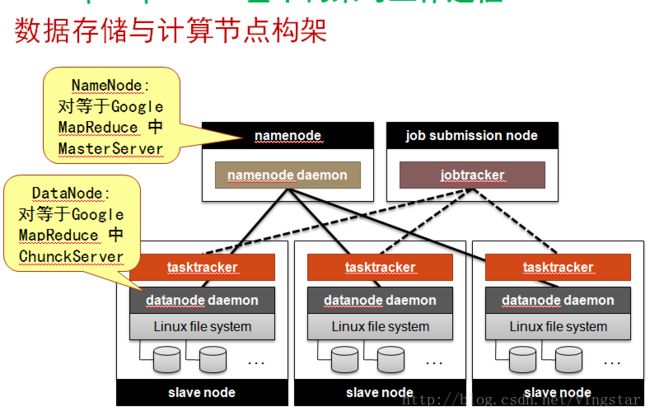
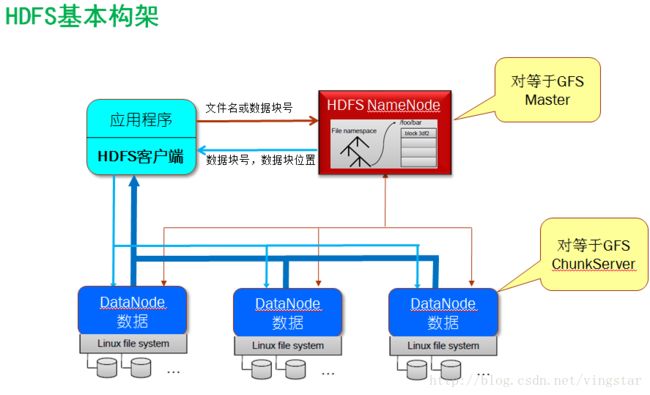
为应用开发者隐藏系统层细节 Hide system-leveldetails from the application developer 平滑无缝的可扩展性 Seamlessscalability 主要包括两层意义上的扩展性:数据扩展和系统规模扩展 第三章 Google和Hadoop MapReduce基本构架 Google MR的基本工作: 这里在PPT中以动态图的方式非常直观的展示了这一过程的执行流程。有几点需要注意的是, 1,数据是在程序运行之间已经保存在GFS中的。 2,一个具体的程序job是运行在MapReduce平台之上的,MapReduce内部的Master已经相关的map和reduce的worker是随整个平台而存在和调配的,并不是随着一个具体的程序Job而产生和结束的。 分布式文件系统GFS的工作原理 解决如何存储和方便上层进行对海量数据的读取、操作需求
GoogleGFS的基本设计原则 Google GFS是一个基于分布式集群的大型分布式文件系统,为MapReduce计算框架提供低层数据存储和数据可靠性支撑; GFS是一个构建在分布节点本地文件系统之上的一个逻辑上文件系统,它将数据存储在物理上分布的每个节点上,但通过GFS将整个数据形成一个逻辑上整体的文件。 GFSMaster Master上保存了GFS文件系统的 三种元数据 : 分布式文件系统的目录结构 GFS ChunkServer 即用来保存大量实际数据的数据 服务器。 BigTable数据模型 进行索引和查询定位的。 (row:string, column:string,time:int64)à 结果数据字符串 一个SSTable实际上对应于GFS中的一个64MB的数据块(Chunk) HadoopMapReduce的基本工作原理 文件数据存储架构: 基本工作流程: 文件输入格式InputFormat 输入数据分块InputSplits 数据记录读入RecordReader 将数据记录转化为一个(key,value)对 的详细方法,并将数据记录传给 Mapper类 Mapper Combiner Partitioner & Shuffle Sort Reducer 文件输出格式OutputFormat HDFS的两种操作方法 一是通过命令行执行一些文件创建等基本管理命令,二是在程序中调用相关的库下接口。 第四章 Hadoop的安装和基本运行测试 (参考其他博文)
编程实现 程序员主要的编码工作如下: 实现Map类 public static class TokenizerMapper //定义Map类实现字符串分解 extends Mapper public void map(Object key, Text value, Contextcontext) throws IOException, InterruptedException 实现Reduce类 (key,values) 是由 Map 任务输出的中间结果,values 是一个
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Contextcontext ) throws IOException, InterruptedException
实现main函数(运行Job) Job job = new Job(conf, “word count”); //新建一个用户定义的Job job.setJarByClass(WordCount.class); //设置执行任务的jar job.setMapperClass(TokenizerMapper.class); //设置Mapper类 job.setCombinerClass(IntSumReducer.class); //设置Combine类 job.setReducerClass(IntSumReducer.class); //设置Reducer类 job.setOutputKeyClass(Text.class); //设置job输出的key //设置job输出的value job.setOutputValueClass(IntWritable.class); //设置输入文件的路径 FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //设置输出文件的路径 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //提交任务并等待任务完成 第五章 MapReduce算法设计 可以通过定制FileInputFormat来实现同现的定义。 第六章 Hbase和Hive程序设计基础 Hbase是BigTable的一个开源实现,这就基本上可以推断出它的基本设计目标和功能了。解决大规模的结构化和半结构化数据存储访问问题。 HBase在MapReduce中的生态环境: 构建在分布式系统HDFS之上,为上层应用提供对结构化半结构化数据的存储访问能力。 与MapReduce协同工作,为mapReduce提供数据输入输出,以完成数据的并行化处理。 HMaster Server+HRegion Server 两种接口:一个是hbase shell直接进行操作命令。另一个是Java编程接口: HBaseConfiguration \HBaseAdmin创建表、put插入数据、delete等等 Hive是建立在Hadoop之上的,这一点是与HBase不同的。它旨在为上层提供一个SQL的执行引擎,而其内部存储依赖于HDFS,已经依赖MapReduce具体的实现这些SQL所需要完成的functionality。 第七章 高级MapReduce编程技术 本章介绍一些更加tricky的方法来实现一些更加灵活的程序。 使用复合键以及自制Partitioner来进行value值排序。 小键值对合并成为大键值对以减少传输开销。 用户自定义数据类型的实现是实现WritableComparable接口,主要是具体实现其中的readFields()、write、compareTo函数。 用户可以自定义InputFormat和RecordReader以实现自我定制的文件读取到的key等形式。同样的也可以自定义OutputFormat和RecordWriter。:job.setInputFormatClass(...) 用户自定义Partitioner和Combiner 自定义Partitioner来改变Map中间结果到Reduce节点的分区方式。(Key相同的一定会被系统自动的按该函数的功能分到同一个Reduce节点 Combiner是一个本地的Reducer所以它也是实现Reducer接口下的reduce函数。 job.setCombinerClass(....) 迭代MapReduce计算 组合式MR程序设计 JobControl .addJob(...) ChainMapper.addMapper(.....) ChainReduce.setReducer(...)、ChainReduce.addMapper(....) "在Map阶段,数据依次经过Mapper1和Mapper2处理;在Reduce阶段,数据经过shuffle和sort后;交由对应的Reducer处理,但Reducer处理之后并没有直接写到HDFS上,而是交给另外一个Mapper处理,它产生的结果写到最终的HDFS输出目录中。" "需要注意的是,对于任意一个MapReduce作业,Map和Reduce阶段可以有无限个Mapper,但Reducer只能有一个。"---http://book.51cto.com/art/201312/422168.htm 多数据源连接 1,用DataJoin类在Reduce中最终实现Join操作。即在Map过程中进行加标签,而在Reduce中将可以读取这些标签以区分不同的数据源,并将相关的数据加以Join。(缺点是Join在Reduce阶段才能处理,之前的partitioner等需要较多的通信带宽占用) 2,小文件复制的形式:Job.addCacheFile(....) 其他技术: 全局作业参数的传递可以通过Configuration提供的一些setXXX和getXXX接口来进行存与读取。通过setup()内部读取 而全局数据文件的传递可以通过addCacheFile()方法实现,在需要时可以通过getLocalCacheFiles实现读取。 划分多个输出文件:MultiOutputFormat类。通常需要继承并实现MultipleOutputFormat的一个子类并实现其中的generateFileNameForKeyValue()方法以根据当前的键值对h和当前数据文件名由程序产生并返回一个输出文件路径 输入输出到关系数据库接口:通过DBInputFormat和DBRecordReader类等相关工具来实现。 第八章 基于MR的搜索引擎算法-PageRank实现 随机浏览模型,d表示按照原先超链关系进行浏览的概率,1-d就是终断本次chain式浏览,重新开始一个随意的新页面。 使用MR来实现: 第一步,图建立GraphBuilder 第二步,迭代计算PR值,直到PR值收敛或达到直到迭代次数 第三步,Rankviewer,输出最终的排名结果。 第九章 在数据挖掘基础算法上的应用 介绍了几个典型的数据挖掘算法如何使用MapReduce提高其实际的计算效率、降低其复杂性。 第十章 应用实例 在DNA序列比对、机器翻译、重复文档检测等较大的完备系统中的应用。 第十一章 与云计算相结合的展望 极大地计算能力,极方便的使用方式。 把计算能力变成像水电一样的公共服务,随取随用,按需分配。 资源虚拟化和弹性调度(计算资源、存储资源、网络资源) 大规模的并行服务。
/*每个节点计算一个颜色组的矩形面积并累加*/
x = a + i*dx +dx/2; /* 以每个矩形的中心点x值计算矩形高度 */
MPI_Reduce(&local,&inte,1,MPI_DOUBLE,MPI_SUM, 0,MPI_COMM_WORLD);
if(myid==0) /* 规约所有节点上的累加和并送到主节点0 */
{ /*主节点打印累加和*/
printf("The integal of x*x in region [%d,%d] =%16.15f\n", a, b, inte);
}
MPI_Finalize();
}