tinyxml源码解析(上)
前言:
前段时间做功能可行性的时候简单的使用了tinyxml。在sourceforge下载的时候,看到老外对于这个库的评价很高,因此就有冲动进行学习这么一个优秀的框架。简单查看了代码,代码量也不是很大。刚好事情做的差不多,索性就学习学习好了。第一次尝试阅读正式的框架,水平也不是很好,可能多少会有点出错,要是有错误还望多包涵并且提出来,一起进步哈。
文章打算分为三部分,第一部分介绍了TiXmlBase,TiXmlNode这两个基类,第二部分详细了介绍了代表节点的几个类,第三部分介绍了库中提供的一些工具类。
正言:
先简单介绍下tinyxml吧。在我的前一篇文章也介绍了下,还有使用方法。tinyxml是一款轻量级的xml parser。其目的在于在提供基本的xml操作的同时保持一个简单的用户接口供用户使用。其能实现基本的xml的特性。如遍历xml文件,获取节点等。至于dtd,xstl等特性并不支持。详细可以查看我的上一篇文章。
tinyxml整体的类的架构图如下:
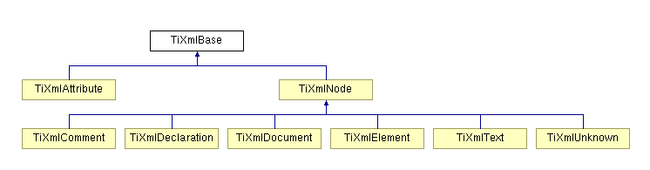
TiXmlBase是所有tinyxml里面的元素的基类,其提供了一些基本的操作和属性。一会分析。
xml中的节点的所有父类皆为TiXmlNode,其可以转化成任意一种特定的节点。而对于我们的element节点中的属性来说,其在构造时也是做为element的子节点来构建的,不过由于其只能出现在element中,因此并没有继承自TiXmlNode。
TiXmlNode也提供了一些基本的节点操作,如获取子节点,插入子节点等。
这篇文章将主要讲解TiXmlBase以及TiXmlNode。
TiXmlBase:
先讲下所有类的基类TiXmlBase吧。
这里是头文件的内容。
1 //TiXmlBase,所有的基类,提供了一些基本的操作和元素 2 class TiXmlBase 3 { 4 friend class TiXmlNode;//这里使用friend让人比较困惑,因为这三个都是子类,应该不用才是.在查看了tinyxmlparser.cpp的679行,主要是因为在函数中调用了做为参数的TiXmlNode的streamIn函数,而该函数是protected的,所以需要friend.当然肯定不止这么一个函数,应该用到了很多protected内的方法和参数. 5 friend class TiXmlElement;//这边就是同理了. 6 friend class TiXmlDocument; 7 8 public: 9 TiXmlBase() : userData(0) {} 10 virtual ~TiXmlBase() {} 11 12 /** Print是带格式输出,如果想不带格式可以直接使用<< 13 */ 14 virtual void Print( FILE* cfile, int depth ) const = 0; 15 16 /** 由于xml中空格是否算元素还未定,因此作者留了个选项供用户选择 17 */ 18 static void SetCondenseWhiteSpace( bool condense ) { condenseWhiteSpace = condense; } 19 20 static bool IsWhiteSpaceCondensed() { return condenseWhiteSpace; } 21 22 /** 返回的值为该元素在文件中的位置 23 注意:增加或者删除节点并不会改变位置,这个位置实际上实在load的时候确定的. 24 同时,计算位置有一点的性能损失,可以选择关闭 25 */ 26 int Row() const { return location.row + 1; } 27 int Column() const { return location.col + 1; } ///< See Row() 28 29 void SetUserData( void* user ) { userData = user; } ///< Set a pointer to arbitrary user data. 30 void* GetUserData() { return userData; } ///< Get a pointer to arbitrary user data. 31 const void* GetUserData() const { return userData; } ///< Get a pointer to arbitrary user data. 32 33 // 用来判断UTF-8字符集字符长度的数组(1~4),具体定义在tinyxmlparser.cpp中 34 static const int utf8ByteTable[256]; 35 //纯虚函数,在子类中会重新定义,对不同节点进行不同处理,纯虚函数也使得该类为虚基类,不可生成变量 36 virtual const char* Parse( const char* p, 37 TiXmlParsingData* data, 38 TiXmlEncoding encoding /*= TIXML_ENCODING_UNKNOWN */ ) = 0; 39 40 /** 工具函数,将节点值encode成相应的xml,其实就是对于<,>等xml特殊元素进行处理 41 */ 42 static void EncodeString( const TIXML_STRING& str, TIXML_STRING* out ); 43 //定义了一些转化的时候的错误. 44 enum 45 { 46 TIXML_NO_ERROR = 0, 47 TIXML_ERROR, 48 TIXML_ERROR_OPENING_FILE, 49 TIXML_ERROR_PARSING_ELEMENT, 50 TIXML_ERROR_FAILED_TO_READ_ELEMENT_NAME, 51 TIXML_ERROR_READING_ELEMENT_VALUE, 52 TIXML_ERROR_READING_ATTRIBUTES, 53 TIXML_ERROR_PARSING_EMPTY, 54 TIXML_ERROR_READING_END_TAG, 55 TIXML_ERROR_PARSING_UNKNOWN, 56 TIXML_ERROR_PARSING_COMMENT, 57 TIXML_ERROR_PARSING_DECLARATION, 58 TIXML_ERROR_DOCUMENT_EMPTY, 59 TIXML_ERROR_EMBEDDED_NULL, 60 TIXML_ERROR_PARSING_CDATA, 61 TIXML_ERROR_DOCUMENT_TOP_ONLY, 62 63 TIXML_ERROR_STRING_COUNT 64 }; 65 66 protected: 67 //工具函数,使之在处理文本的时候跳过空格.tinyxml中很多处理只针对english,latin,比如符号,字符等.不过通常情况下,这种处理结果还不错 68 static const char* SkipWhiteSpace( const char*, TiXmlEncoding encoding ); 69 70 inline static bool IsWhiteSpace( char c ) 71 { 72 return ( isspace( (unsigned char) c ) || c == '\n' || c == '\r' ); 73 } 74 inline static bool IsWhiteSpace( int c ) 75 { 76 if ( c < 256 ) 77 return IsWhiteSpace( (char) c ); 78 return false; // Again, only truly correct for English/Latin...but usually works. 79 } 80 //由于tinyxml对于一些不使用stl的用户也提供了接口,因此这样的宏很常见,也增加了不少接口. 81 #ifdef TIXML_USE_STL 82 static bool StreamWhiteSpace( std::istream * in, TIXML_STRING * tag ); 83 static bool StreamTo( std::istream * in, int character, TIXML_STRING * tag ); 84 #endif 85 86 /*工具函数,用来读取p中的名字,比如tagname,属性名,属性值等. 87 */ 88 static const char* ReadName( const char* p, TIXML_STRING* name, TiXmlEncoding encoding ); 89 90 /*读取in中的文本,即<> </>中的文本, 91 */ 92 static const char* ReadText( const char* in, // where to start 93 TIXML_STRING* text, // the string read 94 bool ignoreWhiteSpace, // whether to keep the white space 95 const char* endTag, // what ends this text 96 bool ignoreCase, // whether to ignore case in the end tag 97 TiXmlEncoding encoding ); // the current encoding 98 99 // 处理xml中的实体,将<,>转化回来,实现中用了些trick,之后展现 100 static const char* GetEntity( const char* in, char* value, int* length, TiXmlEncoding encoding ); 101 102 // 转化一个char,如果是实体,同时进行转化,在ReadText中被调用 103 inline static const char* GetChar( const char* p, char* _value, int* length, TiXmlEncoding encoding ) 104 { 105 assert( p ); 106 if ( encoding == TIXML_ENCODING_UTF8 ) 107 { 108 *length = utf8ByteTable[ *((const unsigned char*)p) ]; 109 assert( *length >= 0 && *length < 5 ); 110 } 111 else 112 { 113 *length = 1; 114 } 115 116 if ( *length == 1 ) 117 { 118 if ( *p == '&' ) 119 return GetEntity( p, _value, length, encoding ); 120 *_value = *p; 121 return p+1; 122 } 123 else if ( *length ) 124 { 125 //strncpy( _value, p, *length ); // lots of compilers don't like this function (unsafe), 126 // and the null terminator isn't needed 127 for( int i=0; p[i] && i<*length; ++i ) { 128 _value[i] = p[i]; 129 } 130 return p + (*length); 131 } 132 else 133 { 134 // Not valid text. 135 return 0; 136 } 137 } 138 139 // 进行比较,ignoreCase只针对英文支持. 140 static bool StringEqual( const char* p, 141 const char* endTag, 142 bool ignoreCase, 143 TiXmlEncoding encoding ); 144 145 static const char* errorString[ TIXML_ERROR_STRING_COUNT ]; 146 //TiXmlCursor 提供了位置信息,是一个包涵row,column的结构体 147 TiXmlCursor location; 148 149 /// Field containing a generic user pointer 150 void* userData; 151 152 //三个函数只针对英文有用.工具函数 153 static int IsAlpha( unsigned char anyByte, TiXmlEncoding encoding ); 154 static int IsAlphaNum( unsigned char anyByte, TiXmlEncoding encoding ); 155 inline static int ToLower( int v, TiXmlEncoding encoding ) 156 { 157 if ( encoding == TIXML_ENCODING_UTF8 ) 158 { 159 if ( v < 128 ) return tolower( v ); 160 return v; 161 } 162 else 163 { 164 return tolower( v ); 165 } 166 } 167 //UTF32到UTF8的转化函数,挺复杂的,我没有研究,稍后展示. 168 static void ConvertUTF32ToUTF8( unsigned long input, char* output, int* length ); 169 170 private: 171 TiXmlBase( const TiXmlBase& ); //防止复制 172 void operator=( const TiXmlBase& base ); // 防止复制 173 174 //定义了一些实体,在ReadText中用于转化 175 struct Entity 176 { 177 const char* str; 178 unsigned int strLength; 179 char chr; 180 }; 181 enum 182 { 183 NUM_ENTITY = 5, 184 MAX_ENTITY_LENGTH = 6 185 186 }; 187 static Entity entity[ NUM_ENTITY ];//在tinyxmlparser.cpp中定义了. 188 static bool condenseWhiteSpace;//是否跳过空格 189 };
读完头文件,来看看具体的实现
首先是之前提到的entity,定义在tinyxmlparser.cpp
//定义了xml中的entity数组.用于函数转化 TiXmlBase::Entity TiXmlBase::entity[ TiXmlBase::NUM_ENTITY ] = { { "&", 5, '&' }, { "<", 4, '<' }, { ">", 4, '>' }, { """, 6, '\"' }, { "'", 6, '\'' } };
接下来就是说到的EncodeString了.
1 //对xml中实体进行转化,TIXML_STRING是作者封的一个宏.当定义了TIXML_USE_STL时,其即为string,否则就是作者自己实现的一个类.之后在讲解工具类时会提到. 2 void TiXmlBase::EncodeString( const TIXML_STRING& str, TIXML_STRING* outString ) 3 { 4 int i=0; 5 6 while( i<(int)str.length() ) 7 { 8 unsigned char c = (unsigned char) str[i]; 9 10 if ( c == '&' 11 && i < ( (int)str.length() - 2 ) 12 && str[i+1] == '#' 13 && str[i+2] == 'x' )//为16进制的字符,直接复制.知道遇到';' 14 { 15 while ( i<(int)str.length()-1 ) 16 { 17 outString->append( str.c_str() + i, 1 ); 18 ++i; 19 if ( str[i] == ';' ) 20 break; 21 } 22 } 23 //转化字符为数组中的实体. 24 else if ( c == '&' ) 25 { 26 outString->append( entity[0].str, entity[0].strLength ); 27 ++i; 28 } 29 else if ( c == '<' ) 30 { 31 outString->append( entity[1].str, entity[1].strLength ); 32 ++i; 33 } 34 else if ( c == '>' ) 35 { 36 outString->append( entity[2].str, entity[2].strLength ); 37 ++i; 38 } 39 else if ( c == '\"' ) 40 { 41 outString->append( entity[3].str, entity[3].strLength ); 42 ++i; 43 } 44 else if ( c == '\'' ) 45 { 46 outString->append( entity[4].str, entity[4].strLength ); 47 ++i; 48 } 49 //是特殊不显示字符,扩展 50 else if ( c < 32 ) 51 { 52 // Easy pass at non-alpha/numeric/symbol 53 // Below 32 is symbolic. 54 char buf[ 32 ]; 55 //取低8位进行转化,TIXML_SNPRINTF是宏, 56 //在tinyxml.h 62行中定义,主要是为了解决编译器兼容性问题 57 58 #if defined(TIXML_SNPRINTF) 59 TIXML_SNPRINTF( buf, sizeof(buf), "&#x%02X;", (unsigned) ( c & 0xff ) ); 60 #else 61 sprintf( buf, "&#x%02X;", (unsigned) ( c & 0xff ) ); 62 #endif 63 64 //*ME: warning C4267: convert 'size_t' to 'int' 65 //*ME: Int-Cast to make compiler happy ... 66 outString->append( buf, (int)strlen( buf ) ); 67 ++i; 68 } 69 else 70 { 71 //直接复制 72 *outString += (char) c; 73 ++i; 74 } 75 } 76 }
SkipWhiteSpace:这个实在没什么好说的.
1 //折叠又打不开了.就不折叠了 2 const char* TiXmlBase::SkipWhiteSpace( const char* p, TiXmlEncoding encoding ) 3 { 4 if ( !p || !*p ) 5 { 6 return 0; 7 } 8 if ( encoding == TIXML_ENCODING_UTF8 ) 9 { 10 while ( *p ) 11 { 12 const unsigned char* pU = (const unsigned char*)p; 13 14 // 跳过ms的UTF8头 15 if ( *(pU+0)==TIXML_UTF_LEAD_0 16 && *(pU+1)==TIXML_UTF_LEAD_1 17 && *(pU+2)==TIXML_UTF_LEAD_2 ) 18 { 19 p += 3; 20 continue; 21 } 22 else if(*(pU+0)==TIXML_UTF_LEAD_0 23 && *(pU+1)==0xbfU 24 && *(pU+2)==0xbeU ) 25 { 26 p += 3; 27 continue; 28 } 29 else if(*(pU+0)==TIXML_UTF_LEAD_0 30 && *(pU+1)==0xbfU 31 && *(pU+2)==0xbfU ) 32 { 33 p += 3; 34 continue; 35 } 36 37 //仍然采用了英文的,ansi的方式进行判断. 38 if ( IsWhiteSpace( *p ) ) 39 ++p; 40 else 41 break; 42 } 43 } 44 else 45 { 46 //对于其他编码也是 47 while ( *p && IsWhiteSpace( *p ) ) 48 ++p; 49 } 50 51 return p; 52 }
ReadName
1 //读取element中的tagname和属性的name,写得很清晰,不用怎么解释 2 const char* TiXmlBase::ReadName( const char* p, TIXML_STRING * name, TiXmlEncoding encoding ) 3 { 4 *name = ""; 5 assert( p ); 6 7 if ( p && *p 8 && ( IsAlpha( (unsigned char) *p, encoding ) || *p == '_' ) ) 9 { 10 const char* start = p; 11 while( p && *p 12 && ( IsAlphaNum( (unsigned char ) *p, encoding ) 13 || *p == '_' 14 || *p == '-' 15 || *p == '.' 16 || *p == ':' ) ) 17 { 18 //(*name) += *p; // while中的性能优化,将复制提到外头去. 19 ++p; 20 } 21 if ( p-start > 0 ) { 22 name->assign( start, p-start ); 23 } 24 return p; 25 } 26 return 0; 27 }
ReadText: 读取属性中的值,读取<></>之间的文本.
1 const char* TiXmlBase::ReadText( const char* p, //被读的文本 2 TIXML_STRING * text, //读取的字符 3 bool trimWhiteSpace, //是否要跳过空格 4 const char* endTag, //结束的tag,看起来比较别扭,不过用起来很方便 5 bool caseInsensitive, //判断tag相等,是否关注大小写 6 TiXmlEncoding encoding ) 7 { 8 *text = ""; 9 if ( !trimWhiteSpace // certain tags always keep whitespace 10 || !condenseWhiteSpace ) 11 { 12 // Keep all the white space. 13 while ( p && *p 14 && !StringEqual( p, endTag, caseInsensitive, encoding ) 15 ) 16 { 17 int len; 18 char cArr[4] = { 0, 0, 0, 0 }; 19 p = GetChar( p, cArr, &len, encoding );//详细看GetChar,这里取出的char已经是对实体进行了相应转化了 20 text->append( cArr, len ); 21 } 22 } 23 else //这里操作其实差不多,只是跳不跳过空格的区别. 24 { 25 bool whitespace = false; 26 27 // Remove leading white space: 28 p = SkipWhiteSpace( p, encoding ); 29 while ( p && *p 30 && !StringEqual( p, endTag, caseInsensitive, encoding ) ) 31 { 32 if ( *p == '\r' || *p == '\n' ) 33 { 34 whitespace = true; 35 ++p; 36 } 37 else if ( IsWhiteSpace( *p ) ) 38 { 39 whitespace = true; 40 ++p; 41 } 42 else 43 { 44 // If we've found whitespace, add it before the 45 // new character. Any whitespace just becomes a space. 46 if ( whitespace ) 47 { 48 (*text) += ' '; 49 whitespace = false; 50 } 51 int len; 52 char cArr[4] = { 0, 0, 0, 0 }; 53 p = GetChar( p, cArr, &len, encoding ); 54 if ( len == 1 ) 55 (*text) += cArr[0]; // more efficient 56 else 57 text->append( cArr, len ); 58 } 59 } 60 } 61 if ( p && *p ) 62 p += strlen( endTag ); 63 return ( p && *p ) ? p : 0; 64 }
StringEqual:就是一个比较函数,比较简单.
1 bool TiXmlBase::StringEqual( const char* p, 2 const char* tag, 3 bool ignoreCase, 4 TiXmlEncoding encoding ) 5 { 6 assert( p ); 7 assert( tag ); 8 if ( !p || !*p ) 9 { 10 assert( 0 ); 11 return false; 12 } 13 14 const char* q = p; 15 16 if ( ignoreCase ) 17 { 18 while ( *q && *tag && ToLower( *q, encoding ) == ToLower( *tag, encoding ) ) 19 { 20 ++q; 21 ++tag; 22 } 23 24 if ( *tag == 0 ) 25 return true; 26 } 27 else 28 { 29 while ( *q && *tag && *q == *tag ) 30 { 31 ++q; 32 ++tag; 33 } 34 35 if ( *tag == 0 ) // Have we found the end of the tag, and everything equal? 36 return true; 37 } 38 return false; 39 }
ConvertUTF32ToUTF8:这是个转化工具,我也不大懂.根据编码规则应该就能实现.贴出来吧.
1 void TiXmlBase::ConvertUTF32ToUTF8( unsigned long input, char* output, int* length ) 2 { 3 const unsigned long BYTE_MASK = 0xBF; 4 const unsigned long BYTE_MARK = 0x80; 5 const unsigned long FIRST_BYTE_MARK[7] = { 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC }; 6 7 if (input < 0x80) 8 *length = 1; 9 else if ( input < 0x800 ) 10 *length = 2; 11 else if ( input < 0x10000 ) 12 *length = 3; 13 else if ( input < 0x200000 ) 14 *length = 4; 15 else 16 { *length = 0; return; } // This code won't covert this correctly anyway. 17 18 output += *length; 19 20 // Scary scary fall throughs. 21 switch (*length) 22 { 23 case 4: 24 --output; 25 *output = (char)((input | BYTE_MARK) & BYTE_MASK); 26 input >>= 6; 27 case 3: 28 --output; 29 *output = (char)((input | BYTE_MARK) & BYTE_MASK); 30 input >>= 6; 31 case 2: 32 --output; 33 *output = (char)((input | BYTE_MARK) & BYTE_MASK); 34 input >>= 6; 35 case 1: 36 --output; 37 *output = (char)(input | FIRST_BYTE_MARK[*length]); 38 } 39 }
看完了最基础的TiXmlBase类之后,也能感觉到,这个基类就是提供了基本的处理工具的作用,以及为后续的类设定了一些虚函数供后续继承.而且由于是纯虚类,因此也不能声明TiXmlBase的对象.
接下来就看看还具有一定实用性的TiXmlNode类吧.
这个类是除了TiXmlAttribute之外的所有元素类的父类,里面提供了对于xml对象基本的操作.如遍历子节点,访问兄弟节点,插入,删除节点等操作.这样在后面的子类继承时,就不用考虑这些操作了.
先看看头文件吧.
1 /** The parent class for everything in the Document Object Model. 2 (Except for attributes). 3 Nodes have siblings, a parent, and children. A node can be 4 in a document, or stand on its own. The type of a TiXmlNode 5 can be queried, and it can be cast to its more defined type. 6 */ 7 class TiXmlNode : public TiXmlBase 8 { 9 friend class TiXmlDocument;//这个原因就不用解释了吧,还是和上头一样,需要访问protected或者private的member function/property 10 friend class TiXmlElement; 11 12 public: 13 //只有允许使用STL才有这两个操作符 14 #ifdef TIXML_USE_STL 15 16 /** 17 将结果输入到base中,这三个操作符都是友元函数,定义在类的外头. 18 作者在注释中提到了,operator>>允许空格和回车,内部处理机制更为复杂,之后我们可以看看. 19 */ 20 friend std::istream& operator >> (std::istream& in, TiXmlNode& base); 21 22 /* 23 这个输出是不带格式的.即不带空格和回车,因此显示的并不好看,不过计算机处理的时候也不用那么多好看的空格是吧. 24 */ 25 friend std::ostream& operator<< (std::ostream& out, const TiXmlNode& base); 26 27 //将元素的值增加到string后头 28 friend std::string& operator<< (std::string& out, const TiXmlNode& base ); 29 30 #endif 31 32 /** 33 这就是node所支持的元素类型了,可以看到除了attribute都在了.不过attribute的实现方法可能和大家所想的不大一样.我会在中篇的时候给大家展示一下. 34 所有在处理过程中未识别的元素都将被认为是unknown. 35 */ 36 enum NodeType 37 { 38 TINYXML_DOCUMENT, 39 TINYXML_ELEMENT, 40 TINYXML_COMMENT, 41 TINYXML_UNKNOWN, 42 TINYXML_TEXT, 43 TINYXML_DECLARATION, 44 TINYXML_TYPECOUNT 45 }; 46 47 virtual ~TiXmlNode();//析构函数是虚函数,其目的在于以后在delete时,也能利用多态处理,调用真正的析构函数 48 49 /** 50 Value对于不同的节点,其意义不尽相同.下面是各个类型的Value所代表的含义 51 Document: xml的文件名 52 Element: tagName 53 Comment: 注释的内容 54 Unknown: tag的内容 55 Text: text 56 */ 57 const char *Value() const { return value.c_str (); } 58 59 #ifdef TIXML_USE_STL 60 // 只有stl才能使用的函数,注释说明这种方式在实际使用中更为高效 61 62 const std::string& ValueStr() const { return value; } 63 #endif 64 65 //在STL模式下,TIXML_STRING=string,在普通模式下为作者自己实现的string 66 const TIXML_STRING& ValueTStr() const { return value; } 67 68 /** 修改Value 69 对应的意义和Value()函数想同 70 */ 71 void SetValue(const char * _value) { value = _value;} 72 73 #ifdef TIXML_USE_STL 74 /// STL std::string form. 75 void SetValue( const std::string& _value ) { value = _value; } 76 #endif 77 78 /// 删除所有的子节点 79 void Clear(); 80 81 /// 父节点,为了支持const类型,因此也包括了const的函数 82 ///下面的很多函数都采用了这种写法.我就列举了Parent,其他删掉了.不然好长.. 83 TiXmlNode* Parent() { return parent; } 84 const TiXmlNode* Parent() const { return parent; } 85 86 TiXmlNode* FirstChild() { return firstChild; }//当没有时返回Null 87 const TiXmlNode* FirstChild( const char * value ) const; ///第一个符合value的child,如果没有返回null 88 TiXmlNode* FirstChild( const char * _value ) { 89 // 调用const的方法,因此先将this用const_cast转化,再将返回值const_cast回来 90 return const_cast< TiXmlNode* > ((const_cast< const TiXmlNode* >(this))->FirstChild( _value )); 91 } 92 TiXmlNode* LastChild() { return lastChild; }/// 最后一个child,没有则返回null 93 //和上面的firstchild一样的处理 94 const TiXmlNode* LastChild( const char * value ) const; 95 TiXmlNode* LastChild( const char * _value ) { 96 return const_cast< TiXmlNode* > ((const_cast< const TiXmlNode* >(this))->LastChild( _value )); 97 } 98 99 //提供了string版本的FirstChild,LastChild,调用指针版本的结果 100 #ifdef TIXML_USE_STL 101 const TiXmlNode* FirstChild( const std::string& _value ) const { return FirstChild (_value.c_str ()); } 102 TiXmlNode* FirstChild( const std::string& _value ) { return FirstChild (_value.c_str ()); } 103 const TiXmlNode* LastChild( const std::string& _value ) const { return LastChild (_value.c_str ()); } 104 TiXmlNode* LastChild( const std::string& _value ) { return LastChild (_value.c_str ()); } 105 #endif 106 107 /** 108 提供了遍历子节点的方法. 109 previous可以为空. 110 */ 111 const TiXmlNode* IterateChildren( const TiXmlNode* previous ) const; 112 TiXmlNode* IterateChildren( const TiXmlNode* previous ) { 113 return const_cast< TiXmlNode* >( (const_cast< const TiXmlNode* >(this))->IterateChildren( previous ) ); 114 } 115 116 /// 迭代具有特殊value的所有子节点 117 const TiXmlNode* IterateChildren( const char * value, const TiXmlNode* previous ) const; 118 TiXmlNode* IterateChildren( const char * _value, const TiXmlNode* previous ) { 119 return const_cast< TiXmlNode* >( (const_cast< const TiXmlNode* >(this))->IterateChildren( _value, previous ) ); 120 } 121 122 //stl版本.我就不展现了. 123 124 /** 125 在最后插入子节点.返回null如果有错误发生 126 */ 127 TiXmlNode* InsertEndChild( const TiXmlNode& addThis ); 128 129 130 /** 131 这个函数与上个不同的就是对于新添加的addThis,其父节点变成了this(减少拷贝的考虑),因此在使用时需要特别注意. 132 */ 133 TiXmlNode* LinkEndChild( TiXmlNode* addThis ); 134 135 /** 136 在某个节点前添加某个节点,返回新节点或者为NULL 137 */ 138 TiXmlNode* InsertBeforeChild( TiXmlNode* beforeThis, const TiXmlNode& addThis ); 139 140 /** 141 在某个节点之后添加某个节点,返回新节点或者为NULL 142 */ 143 TiXmlNode* InsertAfterChild( TiXmlNode* afterThis, const TiXmlNode& addThis ); 144 145 /** 覆盖某个节点 146 */ 147 TiXmlNode* ReplaceChild( TiXmlNode* replaceThis, const TiXmlNode& withThis ); 148 149 /// 移除某个节点 150 bool RemoveChild( TiXmlNode* removeThis ); 151 152 ///上一个兄弟节点 153 const TiXmlNode* PreviousSibling() const { return prev; } 154 TiXmlNode* PreviousSibling() { return prev; } 155 156 /// Navigate to a sibling node. 157 const TiXmlNode* PreviousSibling( const char * ) const; 158 TiXmlNode* PreviousSibling( const char *_prev ) { 159 return const_cast< TiXmlNode* >( (const_cast< const TiXmlNode* >(this))->PreviousSibling( _prev ) ); 160 } 161 162 //STL模式,提供string的接口. 163 164 ///下一个兄弟节点 165 TiXmlNode* NextSibling() { return next; } 166 167 ///下一个具有特定值的兄弟节点 168 const TiXmlNode* NextSibling( const char * ) const; 169 TiXmlNode* NextSibling( const char* _next ) { 170 return const_cast< TiXmlNode* >( (const_cast< const TiXmlNode* >(this))->NextSibling( _next ) ); 171 } 172 173 /** 174 返回下一个兄弟节点,同时是element类型. 175 */ 176 const TiXmlElement* NextSiblingElement() const; 177 TiXmlElement* NextSiblingElement() { 178 return const_cast< TiXmlElement* >( (const_cast< const TiXmlNode* >(this))->NextSiblingElement() ); 179 } 180 181 /** 182 返回下一个具有特定值的兄弟节点 183 */ 184 const TiXmlElement* NextSiblingElement( const char * ) const; 185 TiXmlElement* NextSiblingElement( const char *_next ) { 186 return const_cast< TiXmlElement* >( (const_cast< const TiXmlNode* >(this))->NextSiblingElement( _next ) ); 187 } 188 189 //stl模式参数string的接口 190 191 ///用于遍历是element类型的子节点 192 const TiXmlElement* FirstChildElement() const; 193 TiXmlElement* FirstChildElement() { 194 return const_cast< TiXmlElement* >( (const_cast< const TiXmlNode* >(this))->FirstChildElement() ); 195 } 196 197 ///用于遍历具有特定值且是element类型的子节点 198 const TiXmlElement* FirstChildElement( const char * _value ) const; 199 TiXmlElement* FirstChildElement( const char * _value ) { 200 return const_cast< TiXmlElement* >( (const_cast< const TiXmlNode* >(this))->FirstChildElement( _value ) ); 201 } 202 203 ///stl接口 204 205 /// 返回该node的类型,用于转化,进行进一步处理 206 207 int Type() const { return type; } 208 209 //返回根 210 const TiXmlDocument* GetDocument() const; 211 TiXmlDocument* GetDocument() { 212 return const_cast< TiXmlDocument* >( (const_cast< const TiXmlNode* >(this))->GetDocument() ); 213 } 214 215 /// Returns true if this node has no children. 216 bool NoChildren() const { return !firstChild; } 217 218 //转化函数.这个设计的巧妙之处在于,子类也会相应继承这个函数并且重写相应的方法. 219 //对于不可转化的类来说,其返回NULL.因此就避免了TiXmlElement转化成TiXmlDocument. 220 virtual const TiXmlDocument* ToDocument() const { return 0; } 221 virtual const TiXmlElement* ToElement() const { return 0; } 222 virtual const TiXmlComment* ToComment() const { return 0; } 223 virtual const TiXmlUnknown* ToUnknown() const { return 0; } 224 virtual const TiXmlText* ToText() const { return 0; } 225 virtual const TiXmlDeclaration* ToDeclaration() const { return 0; } 226 227 virtual TiXmlDocument* ToDocument() { return 0; } 228 virtual TiXmlElement* ToElement() { return 0; } 229 virtual TiXmlComment* ToComment() { return 0; } 230 virtual TiXmlUnknown* ToUnknown() { return 0; } 231 virtual TiXmlText* ToText() { return 0; } 232 virtual TiXmlDeclaration* ToDeclaration() { return 0; } 233 234 ///克隆该节点,调用者必须手动删除该节点.另外由于是纯虚函数,因此,TiXmlNode也不能被构建 235 virtual TiXmlNode* Clone() const = 0; 236 237 /** 238 TiXmlVisitor是个工具类,Accept将调用该工具类进行输出.之后将会讲解 239 */ 240 virtual bool Accept( TiXmlVisitor* visitor ) const = 0; 241 242 protected: 243 TiXmlNode( NodeType _type ); 244 245 //统一的复制函数 246 void CopyTo( TiXmlNode* target ) const; 247 248 #ifdef TIXML_USE_STL 249 // The real work of the input operator. 250 virtual void StreamIn( std::istream* in, TIXML_STRING* tag ) = 0; 251 #endif 252 253 // 判断文本中接下来是什么类型的Node,以方便处理.在Parse中调用 254 TiXmlNode* Identify( const char* start, TiXmlEncoding encoding ); 255 256 TiXmlNode* parent; 257 NodeType type; 258 259 TiXmlNode* firstChild; 260 TiXmlNode* lastChild; 261 262 TIXML_STRING value; 263 264 TiXmlNode* prev; 265 TiXmlNode* next; 266 267 private: 268 TiXmlNode( const TiXmlNode& ); // 未实现 269 void operator=( const TiXmlNode& base ); // 禁止,通过设置成private的方式来避免错误的复制.这种方式的设置可以在编译的时候给予错误提示. 270 };
在头文件中,我们可以看到,TiXmlNode提供了很多遍历,查找子节点的函数.为后续继承的子类搭好了树结构的基础.同时通过私有化复制构造函数以及复制操作符的方式避免意外的复制从而导致错误以及额外的开销.
来看具体的实现.我们就挑几个重要的函数看看好了.
首先是遍历子节点的操作IterateChildren
1 const TiXmlNode* TiXmlNode::IterateChildren( const TiXmlNode* previous ) const 2 { 3 if ( !previous ) 4 { 5 return FirstChild(); 6 } 7 else 8 { 9 assert( previous->parent == this ); 10 return previous->NextSibling(); 11 } 12 }
至于带value版本的IterateChildren,也调用了其他的函数
而带value版本的FirstChild其实也没什么神秘的,就是对链表的操作而已.
1 const TiXmlNode* TiXmlNode::FirstChild( const char * _value ) const 2 { 3 const TiXmlNode* node; 4 for ( node = firstChild; node; node = node->next ) 5 { 6 if ( strcmp( node->Value(), _value ) == 0 ) 7 return node; 8 } 9 return 0; 10 }
那那些NextSibling等等其实也没有什么好深究的了.还是看看变动性操作吧.
LinkEndChild
分析之后可以看出整体采用的就是双向链表来组织数据的.其他的代码就不用怎么展示了,大多都是链表的操作.
总结:
第一节主要就介绍两个基类及其成员函数.整体显得会比较枯燥,而且看完还是不明白整体tinyxml的处理方式.
详细的tinyxml处理流程我将在第二节进行说明.有什么疑问欢迎交流.第一次写这样的文章,写得不是很好,望大家多包涵.