KGAT 2019(KDD)Knowledge Graph Attention Network for Recommendation
提出背景
- 基于CF的方法无法利用用户和物品的辅助信息,像用户简介,物品属性,以及上下文环境,在用户和无匹交互较少的情况下表现较差。
- FM,NFM,Wide&Deep等模型将用户和物品表示为向量,同时将辅助信息表示为特征向量与用户,物品向量相结合,提高推荐的准确性。
- 上述方法对用户与物品的每一个交互独立处理,并没有考虑他们之间的联系。
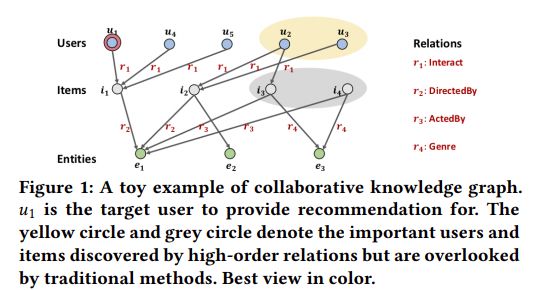
从知识图谱中更加充分的可以挖掘用户和用户,物品和物品之间的关系。如图所示,该图由用户物品交互图和异构知识图谱组成,称作协作知识图谱(CKG)。目标用户为 u 1 u_1 u1,传统的user-based CF方法考虑具有相似历史行为的用户为相似用户,比如 u 1 u_1 u1和 u 4 u_4 u4h和 u 5 u_5 u5都购买了 i 1 i_1 i1,这三个用户为相似用户,item-based CF考虑物品的相似性,例如 i 1 i_1 i1和 i 2 i_2 i2具有相同的属性 e 1 e_1 e1,这两个物品属于相似物品。然而,我们可以探索更高层次的交互,比如,用户 u 2 u_2 u2和 u 3 u_3 u3与物品 i 2 i_2 i2交互,而物品 i 2 i_2 i2和物品 i 1 i_1 i1和实体 e 1 e_1 e1具有相同的关系,所以从某种程度上说明 u 1 u_1 u1和 u 2 , u 3 u_2,u_3 u2,u3也是相似用户,因此,我们需要充分发掘high-order relation高阶连通性,例如
u 1 ⟶ r 1 i 1 ⟶ − r 2 e 1 ⟶ r 2 i 2 ⟶ − r 1 { u 2 , u 3 } , u 1 ⟶ r 1 i 1 ⟶ − r 2 e 1 ⟶ r 3 { i 3 , i 4 } , \begin{array}{l} u_{1} \stackrel{r_{1}}{\longrightarrow} i_{1} \stackrel{-r_{2}}{\longrightarrow} e_{1} \stackrel{r_{2}}{\longrightarrow} i_{2} \stackrel{-r_{1}}{\longrightarrow}\left\{u_{2}, u_{3}\right\}, \\ u_{1} \stackrel{r_{1}}{\longrightarrow} i_{1} \stackrel{-r_{2}}{\longrightarrow} e_{1} \stackrel{r_{3}}{\longrightarrow}\left\{i_{3}, i_{4}\right\}, \end{array} u1⟶r1i1⟶−r2e1⟶r2i2⟶−r1{u2,u3},u1⟶r1i1⟶−r2e1⟶r3{i3,i4},
什么是高阶连通性?
定义两个节点之间的L-order连通性
e 0 ⟶ r 1 e 1 ⟶ r 2 ⋯ ⟶ r L e L e_{0} \stackrel{r_{1}}{\longrightarrow} e_{1} \stackrel{r_{2}}{\longrightarrow} \cdots \stackrel{r_{L}}{\longrightarrow} e_{L} e0⟶r1e1⟶r2⋯⟶rLeL
- 发掘高阶关系面临的挑战
- 随着层次加深,节点数量急剧上涨,计算开销大
- 高阶关系对预测的贡献不同,需要权衡。
现有的基于知识图谱的推荐方法的缺点
基于路径的方法
两个节点之间拥有大量的可选择路径,需要设计选择算法选择较优的路径,或者定义源路径模式对路径进行约束,这两种方法的缺点是,选择算法的性能影响推荐的性能;源路径的设计需要领域专业知识,需要大量的人工劳动力。
基于正则的方法
基于正则的方法设计了其他的损失函数项,这些方法没有直接将高阶关系嵌入为推荐而优化的模型中,而是仅以隐式方式对它们进行编码。 由于缺少显式建模,因此不能保证可以捕获远程连接性,也不能解释高阶建模的结果。
本文贡献
- 我们强调了在协作知识图中显式建模高阶关系的重要性,利附加信息提高更好的推荐。
- 我们开发了一种新的方法KGAT,它在图神经网络框架下以显式且端到端的方式实现了高阶关系建模。
- 我们在三个公开基准上进行了广泛的实验,证明了KGAT的有效性及其在理解高级关系重要性方面的可解释性。
基本架构
Embedding Layer
将CKG中的每一个节点,关系表示为一个向量,以此保留知识图谱的结构信息。本文采用transR进行Knowledge graph embedding,对于给定的三元组,得分函数为
g ( h , r , t ) = ∥ W r e h + e r − W r e t ∥ 2 2 g(h, r, t)=\left\|\mathbf{W}_{r} \mathbf{e}_{h}+\mathbf{e}_{r}-\mathbf{W}_{r} \mathbf{e}_{t}\right\|_{2}^{2} g(h,r,t)=∥Wreh+er−Wret∥22
损失函数为
L K G = ∑ ( h , r , t , t ′ ) ∈ T − ln σ ( g ( h , r , t ′ ) − g ( h , r , t ) ) \mathcal{L}_{\mathrm{KG}}=\sum_{\left(h, \boldsymbol{r}, t, t^{\prime}\right) \in \mathcal{T}}-\ln \sigma\left(g\left(h, r, t^{\prime}\right)-g(h, r, t)\right) LKG=(h,r,t,t′)∈T∑−lnσ(g(h,r,t′)−g(h,r,t))
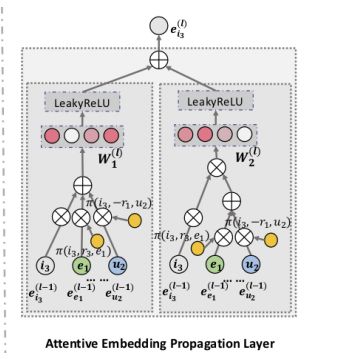
Attentive Embedding Propagation Layers
我们在图卷积网络GCN的架构基础上,沿着高阶连通性递归传播嵌入;此外,通过利用图注意力网络的思想,我们生成级联传播的注意力权重,以揭示这种连通性的重要性。
在这里,我们首先描述一个单层,它由信息传播、知识感知注意力和信息聚合三个部分组成,然后讨论如何将其推广到多层。
Information Propagation
如图所示,一个实体可以被包含在多个三元组中,充当多个三元组链接和传播信息的桥梁,例如实体 i 2 i_2 i2, e 1 ⟶ r 2 i 2 ⟶ − r 1 u 2 e_{1} \stackrel{r_{2}}{\longrightarrow} i_{2} \stackrel{-r_{1}}{\longrightarrow} u_{2} e1⟶r2i2⟶−r1u2和 e 2 ⟶ r 3 i 2 ⟶ − r 1 u 2 e_{2} \stackrel{r_{3}}{\longrightarrow} i_{2} \stackrel{-r_{1}}{\longrightarrow} u_{2} e2⟶r3i2⟶−r1u2, i 2 i_2 i2具有属性 e 1 e_1 e1和 e 2 e_2 e2,因为 u 2 u_2 u2与 i 2 i_2 i2有交互,所以 e 1 e_1 e1和 e 2 e_2 e2体现了 u 2 u_2 u2的偏好,即 e 1 e_1 e1, e 2 e_2 e2的信息可以传播到 u 2 u_2 u2
定义
给定一个实体 h h h,以 h h h为头实体的三元组的集合定义为
N h = { ( h , r , t ) ∣ ( h , r , t ) ∈ G } \mathcal{N}_{h}=\{(h, r, t) \mid(h, r, t) \in \mathcal{G}\} Nh={(h,r,t)∣(h,r,t)∈G}
实体 h h h的一阶连通性定义为
e N h = ∑ ( h , r , t ) ∈ N h π ( h , r , t ) e t \mathbf{e}_{\mathcal{N}_{h}}=\sum_{(h, r, t) \in \mathcal{N}_{h}} \pi(h, r, t) \mathbf{e}_{t} eNh=(h,r,t)∈Nh∑π(h,r,t)et
其中, π ( h , r , t ) \pi(h, r, t) π(h,r,t)控制着边(h,r,t)上每次传播的衰减因子,表示在关系r的条件下,从t传播到h的信息量。
Knowledge-aware Attention
通过注意力机制实现,我们将 t t t到 h h h的注意力得分取决于在关系 r r r空间下 e t e_t et和 e h e_h eh的距离,越近的实体传播越多的信息,在关系r空间中,采用内积衡量两个实体的距离。最后通过softmax函数标准化注意力得分。公式如下
π ( h , r , t ) = ( W r e t ) ⊤ tanh ( ( W r e h + e r ) ) \pi(h, r, t)=\left(\mathbf{W}_{r} \mathbf{e}_{t}\right)^{\top} \tanh \left(\left(\mathbf{W}_{r} \mathbf{e}_{h}+\mathbf{e}_{r}\right)\right) π(h,r,t)=(Wret)⊤tanh((Wreh+er))
π ( h , r , t ) = exp ( π ( h , r , t ) ) ∑ ( h , r ′ , t ′ ) ∈ N h exp ( π ( h , r ′ , t ′ ) ) \pi(h, r, t)=\frac{\exp (\pi(h, r, t))}{\sum_{\left(h, r^{\prime}, t^{\prime}\right) \in \mathcal{N}_{h}} \exp \left(\pi\left(h, r^{\prime}, t^{\prime}\right)\right)} π(h,r,t)=∑(h,r′,t′)∈Nhexp(π(h,r′,t′))exp(π(h,r,t))
Information Aggregation
最后一个阶段是将实体表示 e h e_h eh及其ego-network表示 e N h e_{N_h} eNh聚合为实体 h h h的新表示,即 e h ( 1 ) = f ( e h , e N h ) 。 e^{(1)}_h = f (e_h,e_{N_h} )。 eh(1)=f(eh,eNh)。我们使用三种类型的聚合器来实现 f ( ) f() f()。
- GCN聚合函数将两个表征相加,并进行非线性变换,如下所示
f G C N = LeakyReLU ( W ( e h + e N h ) ) f_{\mathrm{GCN}}=\text { LeakyReLU }\left(\mathbf{W}\left(\mathbf{e}_{h}+\mathbf{e}_{\mathcal{N}_{h}}\right)\right) fGCN= LeakyReLU (W(eh+eNh)) - GraphSage聚集函数将链接两个表示,然后通过一个非线性转换
f GraphSage = LeakyReLU ( W ( e h ∥ e N h ) ) f_{\text {GraphSage }}=\text { LeakyReLU }\left(\mathbf{W}\left(\mathbf{e}_{h} \| \mathbf{e}_{\mathcal{N}_{h}}\right)\right) fGraphSage = LeakyReLU (W(eh∥eNh)) - Bi-Interaction聚集函数考虑 e h e_h eh和 N h {\mathcal{N}_{h}} Nh两种不同的特征交互方法 f Bi-Interaction = LeakyReLU ( W 1 ( e h + e N h ) ) + LeakyReLU ( W 2 ( e h ⊙ e N h ) ) \begin{aligned} f_{\text {Bi-Interaction }} &=\text { LeakyReLU }\left(\mathbf{W}_{1}\left(\mathbf{e}_{h}+\mathbf{e}_{\mathcal{N}_{h}}\right)\right)+\\ & \operatorname{LeakyReLU}\left(\mathbf{W}_{2}\left(\mathbf{e}_{h} \odot \mathbf{e}_{\mathcal{N}_{h}}\right)\right) \end{aligned} fBi-Interaction = LeakyReLU (W1(eh+eNh))+LeakyReLU(W2(eh⊙eNh))
高阶传播
通过高阶传播获取更多的高阶连接性信息,因此递归定义实体表示
e h ( l ) = f ( e h ( l − 1 ) , e N h ( l − 1 ) ) \mathbf{e}_{h}^{(l)}=f\left(\mathbf{e}_{h}^{(l-1)}, \mathbf{e}_{\mathcal{N}_{h}}^{(l-1)}\right) eh(l)=f(eh(l−1),eNh(l−1))
其中,实体 h h h在l-ego网络中信息传播定义如下:
e N h ( l − 1 ) = ∑ ( h , r , t ) ∈ N h π ( h , r , t ) e t ( l − 1 ) \mathbf{e}_{\mathcal{N}_{h}}^{(l-1)}=\sum_{(h, r, t) \in \mathcal{N}_{h}} \pi(h, r, t) \mathbf{e}_{t}^{(l-1)} eNh(l−1)=(h,r,t)∈Nh∑π(h,r,t)et(l−1)
模型预测
用户表示和物品表示
e u ∗ = e u ( 0 ) ∥ ⋯ ∥ e u ( L ) , e i ∗ = e i ( 0 ) ∥ ⋯ ∥ e i ( L ) \mathbf{e}_{u}^{*}=\mathbf{e}_{u}^{(0)}\|\cdots\| \mathbf{e}_{u}^{(L)}, \quad \mathbf{e}_{i}^{*}=\mathbf{e}_{i}^{(0)}\|\cdots\| \mathbf{e}_{i}^{(L)} eu∗=eu(0)∥⋯∥eu(L),ei∗=ei(0)∥⋯∥ei(L)
采用内积实现用户对物品的预测
y ^ ( u , i ) = e u ∗ ⊤ e i ∗ \hat{y}(u, i)=\mathbf{e}_{u}^{* \top} \mathbf{e}_{i}^{*} y^(u,i)=eu∗⊤ei∗
模型优化
采用BPR损失函数
L C F = ∑ ( u , i , j ) ∈ O − ln σ ( y ^ ( u , i ) − y ^ ( u , j ) ) \mathcal{L}_{\mathrm{CF}}=\sum_{(u, i, j) \in O}-\ln \sigma(\hat{y}(u, i)-\hat{y}(u, j)) LCF=(u,i,j)∈O∑−lnσ(y^(u,i)−y^(u,j))
最终端到端的训练损失函数为
L K G A T = L K G + L C F + λ ∥ Θ ∥ 2 2 \mathcal{L}_{\mathrm{KGAT}}=\mathcal{L}_{\mathrm{KG}}+\mathcal{L}_{\mathrm{CF}}+\lambda\|\Theta\|_{2}^{2} LKGAT=LKG+LCF+λ∥Θ∥22
数据集

开源代码地址
论文开源