目标检测学习--FPN(特征金字塔网络)-解决多尺度检测问题
论文地址
《Feature Pyramid Networks for Object Detection》
深度神经网络学习到的特征中,浅层特征学到的是物理信息,比如物体的角点、边缘的细节信息,而深层特征学到的是语义信息,更加高维与抽象;
目标检测包括分类和定位任务,对于分类任务来说,深层网络学到的特征可能更为重要,而对于定位任务来说,深层次和浅层次的特征同样重要;
之前的目标检测算法,多数只采用深层特征来做预测,所含的细节信息比较粗略,即使采用了特征融合的方法,也一般是采用融合后的特征进行预测的;
卷积网络可以得到不同尺寸的特征图,FPN就想既利用卷积网络本身的已经计算过的不同尺寸的特征,同时又想让低维的高分辨的特征具有很强的语义信息,所以想到把高维的低分辨的特征融合到低维的特征上;
特征图金字塔网络FPN(Feature Pyramid Networks)主要是解决目标检测中的多尺度问题,通过简单的改变网络连接,在基本不增加原有模型计算量的情况下,可以在不同的特征层上独立进行预测,大幅提升了小目标检测的性能;
不同方案的金字塔
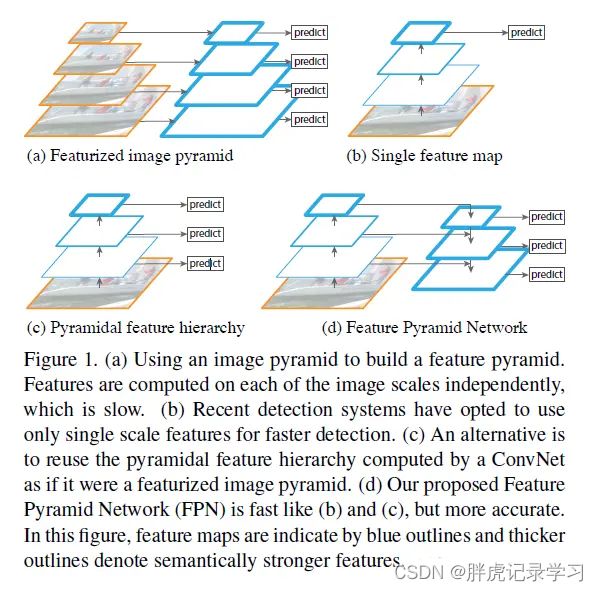
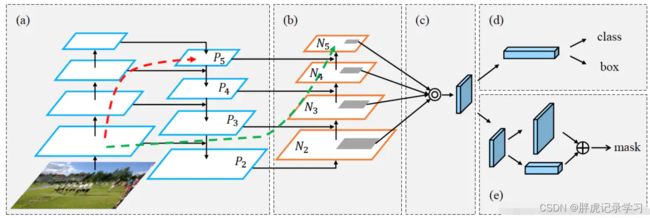
我们知道,多尺度目标检测一直是一个挑战, 需要检测出不同大小物体,常用的解决方案是构造多尺度金字塔,如上图所示;
上图(a)网络是一个特征图像金字塔,整个过程是先对原始图像构造图像金字塔,即先将图像做成不同的尺寸,然后在图像金字塔的每一层提取不同的特征,然后进行相应的Bbox位置回归;这种方法的缺点是计算量大,需要大量的内存,同时比较耗时,不太适合运用到实际当中;优点是可以获得较好的检测精度,可以在测试时使用;
上图(b)网络只使用单尺度维度的特征进行预测,为自底向上卷积,然后使用最后一层特征图进行预测,即利用卷积网络本身的特性,对原始图像进行卷积和池化操作,通过这种操作我们可以获得不同尺寸的feature map,即类似在图像的特征空间中构造金字塔;这种方法存在于大多数深度网络中,比如VGG、ResNet、Inception,它们都是利用深度网络的最后一层特征来进行分类,这种方法的优点是速度快、需要内存少,缺点是仅仅关注深层网络中最后一层的特征,却忽略了其它层的特征;
上图(c)同时利用低层特征和高层特征,分别在不同的层同时进行预测,一幅图像中可能具有多个不同大小的目标,区分不同的目标可能需要不同的特征,对于简单目标仅仅需要浅层的特征就可以检测到它,但对于复杂的目标(小目标)则需要利用复杂的特征来检测它;整个过程就是首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。它的优点是在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标,即对于有些目标来说,不需要进行多余的前向操作,这样可以在一定程度上对网络进行加速操作,同时可以提高算法的检测性能,它的缺点是获得的特征不鲁棒,都是一些从较浅的层获得的弱特征,SSD采用该多尺度融合的方法,但是没有用到足够低层的特征,底层大尺度的feature map语义信息少,虽然框出了小物体,但小物体容易被错分;
上图(d)为特征图金字塔网络FPN(Feature Pyramid Networks),为了使不同尺度的特征都包含丰富的语义信息,同时又不使得计算成本过高,作者采用top-down和lateral connection的方式,让低层高分辨率低语义的特征和高层低分辨率高语义的特征融合在一起,同时融合原来的特征,使得最终得到的不同尺度的特征图都有丰富的语义信息,即顶层特征通过上采样与低层特征做融合,而且每层都进行独立预测;
特征图金字塔网络FPN(Feature Pyramid Networks)
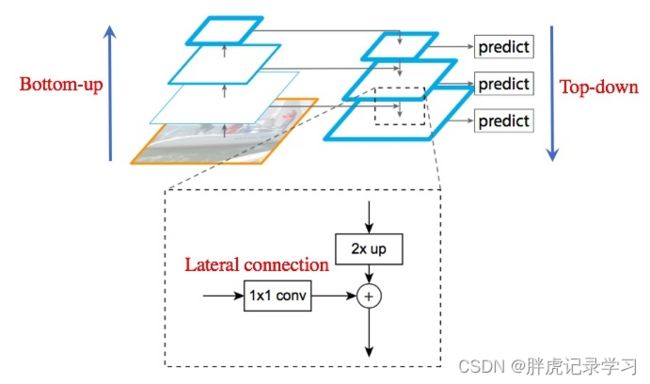
特征金字塔网络相当于先进行传统的bottom-up自低向上的特征卷积(图中左侧),然后FPN融合左侧特征图的相邻的特征图自顶向下进行高维特征融合(图中右侧), 横向的箭头叫横向连接,用来融合特征语义多的高层特征与特征语义少但位置信息多的低层特征(图中放大部分);
Bottom-up
即神经网络普通的前向传播过程,将图片输入到主干卷积网络中提取特征的过程中。主干卷积网络输出的feature map的尺寸有的不变,有的成2倍减小;对于那些输出的尺寸不变的层,把他们归为一个stage,那么每个stage的最后一层输出的特征就将被抽取出来;
以ResNet为例,将卷积块conv2, conv3, conv4, conv5的输出定义为{![]() } ,这些都是每个stage中最后一个残差块的输出,并且它们相对于输入图像具有{4, 8, 16, 32} 的步长,所以这些输出分别是原图的{1/4 , 1/8 , 1/16 , 1/32}倍,即成2倍减小;
} ,这些都是每个stage中最后一个残差块的输出,并且它们相对于输入图像具有{4, 8, 16, 32} 的步长,所以这些输出分别是原图的{1/4 , 1/8 , 1/16 , 1/32}倍,即成2倍减小;
Top-down
即将高层得到的feature map进行上采样然后往下传递,因为高层的特征包含丰富的语义信息,经过top-down的传播就能使得这些语义信息传播到低层特征上,使得低层特征也包含丰富的语义信息,原论文中采用的是最近邻插值方法,使特征图尺寸扩大为原来的两倍,即放大到上一个stage的特征图一样的大小;上采样使用最近邻值插值法,可以在上采样的过程中最大程度地保留特征图的语义信息,有利于分类,从而与bottom-up过程中相应的具有丰富的空间信息,高分辨率有利于定位的特征图进行融合,从而得到既有良好的空间信息又有较强烈的语义信息的特征图,最近邻值插值法是最简单的一种插值方法,不需要计算,在待求像素的四个邻近像素中,将距离待求像素最近的邻近像素值赋给待求像素,但可能会造成插值生成的图像灰度上的不连续,在灰度变化的地方可能出现明显的锯齿状;
Lateral connection
对于每个stage输出的feature map Cn,都先进行一个1*1的卷积整合信息并降低特征图维度;
然后再将得到的特征和上一层特征上采样得到特征图Pn+1进行融合,因为在主干卷积中每两个提取的特征层之间都是2倍的大小关系,而经过了自顶向下的上采样特征图尺寸扩大为原来的两倍,即放大到上一个stage的特征图一样的大小,而横向的1*1的卷积统一了相应的维度,所以可以直接进行相加,即element wise addition;
相加完后经过一个3*3的卷积得到本层的特征输出Pn,使用这个3*3卷积的目的是为了消除上采样产生的混叠效应(aliasing effect),混叠效应是指上边提到的‘插值生成的图像灰度不连续,在灰度变化的地方可能出现明显的锯齿状’,在论文中,因为金字塔所有层的输出特征都共享到分类与bbox回归,所以输出的维度都被统一为256,即这些3*3的卷积的channel都为256;
应用
FPN for RPN用于生成proposal
下图为Faster R-CNN中的RPN的网络结构,接收单尺度的特征输入,然后经过3*3的卷积,并在feature map上的每个点处生成9个anchor(3个尺寸,每种尺寸对应3个宽高比),之后再在两个分支并行的进行1*1卷积,分别用于对anchors进行分类和回归;
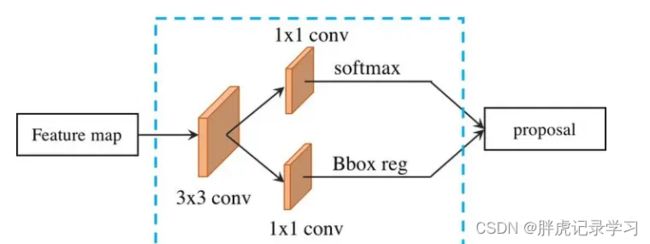
将FPN和RPN结合起来,那RPN的输入就会变成多尺度的feature map,那我们就需要在金字塔的每一层后边都接一个RPN head(即上图中蓝框所示一个3*3卷积,两个1*1卷积);
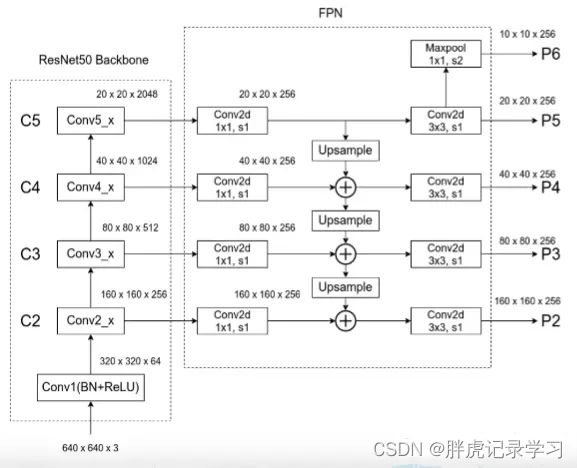
下图最左边是ResNet50的backbone,然后经历FPN网络,生成P2-P6特征层,其中P6是专门为了RPN网络而设计的,用来处理512大小的候选框,预测更大尺寸的目标;
针对不同的特征层,RPN和Fast RCNN的权重共享,所以P2-P6的channel都为256,P2-P6后面会接一个RPN Head,将其称之为网络头部(network head),5个网络头部的参数是共享的,作者通过实验发现,网络头部参数共享和不共享两种设置得到的结果几乎没有差别,这说明不同层级之间的特征有相似的语义层次,这和特征金字塔网络的原理一致;
在生成anchor的时候,因为输入是多尺度特征,就不需要再对每层都使用3种不同尺度的anchor,所以只为每层设定一种尺寸的anchor,每种尺寸对应3个宽高比,在feature map上的每个点处会生成3个anchor,五个特征层{P2,P3,P4,P5,P6}分别对应尺寸为{32^2,64^2,128^2,256^2,512^2}的anchor,即总共会有15种anchors,之后再在两个分支并行的进行1*1卷积,分别用于对anchors进行分类和回归;
Feature Pyramid Network for Fast R-CNN
Fast R-CNN的ROI Pooling层是使用region proposal的结果和特征图作为输入,得到的每个proposal对应的特征然后pooling,之后再分别用于分类结果和边框回归;之前Fast R-CNN使用的是单尺度的特征图,但是现在使用不同尺度的特征图,那么RoI需要在哪一个尺度的特征图上提取对应的特征呢? 论文认为,不同尺度的RoI应该使用不同特征层作为RoI pooling层的输入,大尺度RoI就用后面一些的金字塔层,比如P5;小尺度RoI就用前面一点的特征层,比如P4;计算公式如下:
![]()
k表示映射到哪一层的P作为特征层传入到ROI Pooling层中,k0是基准值,设置为5或4,w和h表示RPN给出的Region Proposal的宽和高,例如k0=4,w和h都是112,则k=3(k值做取整处理),对应P3特征层和Region Proposal传入到ROI Pooling,得到一个尺寸为7*7的特征,再经过flatten之后输入到全连接层;
QA
Q:不同深度的feature map为什么可以经过upsample后直接相加?
A:作者解释说这个原因在于我们做了end-to-end的training,因为不同层的参数不是固定的,不同层同时给监督做end-to-end training,所以相加训练出来的东西能够更有效地融合浅层和深层的信息。
Q:为什么 FPN 相比去掉深层特征 upsample(bottom-up pyramid) 对于小物体检测提升明显?
A:对于小物体,一方面我们需要高分辨率的 feature map 更多关注小区域信息,另一方面,如图中的挎包一样,需要更全局的信息更准确判断挎包的存在及位置
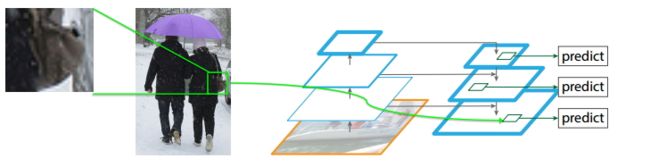
Q:如果不考虑时间情况下,image pyramid是否可能会比feature pyramid的性能更高?
A:作者觉得经过精细调整训练是可能的,但是image pyramid主要的问题在于时间和空间占用太大,而feature pyramid可以在几乎不增加额外计算量情况下解决多尺度检测问题。
后续
后来者PAN在FPN的基础上再加了一个bottom-up方向的增强,使得顶层feature map也可以享受到底层带来的丰富的位置信息,从而把大物体的检测效果也提上去了
总结
FPN(Feature Pyramid Network)算法可以同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到很好的预测效果,并且预测是在每个融合后的特征层上单独进行的;
FPN 构架了一个可以进行端到端训练的特征金字塔,通过CNN网络的层次结构高效的进行强特征计算,通过结合bottom-up与top-down方法获得较强的语义特征,提高目标检测和实例分割在多个数据集上面的性能表现,FPN这种架构可以灵活地应用在不同地任务中去,包括目标检测、实例分割等;
参考
【目标检测】FPN(Feature Pyramid Network)
【论文笔记】FPN —— 特征金字塔
FPN特征金字塔网络解读
【目标检测(九)】FPN详解——通过特征金字塔网络进行多尺度特征融合
仅为学习记录,侵删!