OCR二次开发宝典:飞桨联合多家企业和高校发布《OCR产业范例20讲》

文字识别(Optical Character Recognition,OCR)作为AI领域发展较成熟的一种技术方向,已经在各种产业场景得到落地应用。除了文档电子化、卡证识别等典型的应用场景,还存在大量长尾场景,如工业场景的PCB文字识别、电表识别等。由于训练数据分布问题,通用OCR能力一般无法直接在长尾场景达到满意的效果,而一套通用的OCR能力经过微调往往能够在垂类场景中获得显著的性能提升。

OCR的长尾应用场景:自然场景

OCR的长尾应用场景:文档场景
对于不熟悉OCR领域的开发者来说,基于通用OCR能力的微调方法与落地步骤显得十分繁杂且无从下手。同时,市面上也没有系统性介绍OCR落地经验的材料。
针对以上问题,PaddleOCR联合北京师范大学副教授柯永红、云南省能源投资集团财务有限公司智能化项目经理钟榆星、信雅达科技股份有限公司高级研发工程师张少华、郑州三晖电气股份有限公司工程师郭媛媛、福建中烟工业有限责任公司工程师顾茜、内蒙古阿尔泰电子信息技术有限公司CTO欧日乐克、安科私(北京)科技有限公司创始人柯双喜等产学研同仁共同开源《OCR产业范例20讲》电子书,通过Notebook的形式系统展示OCR在产业界应用的具体场景的调优过程与落地经验。该书包含以下特点:
20例OCR在工业、金融、教育、交通等行业的关键场景应用范例;
覆盖从问题抽象、数据处理、训练调优、部署应用的全流程AI落地环节,为开发者提供常见的OCR优化思路;
每个范例配有交互式Notebook教程,通过代码展示获得实际结果,便于学习修改与二次开发;
GitHub和AI Studio上开源本书中涉及的范例内容和代码,方便开发者学习和使用。




<<< 滑动查看更多图片 >>>
扫描文末二维码,入群后免费领取!
GitHub传送门:
https://github.com/PaddlePaddle/PaddleOCR
 内容结构
内容结构
如下图所示,基于PaddleOCR完成一个范例的完整流程一般包含数据准备、模型训练、推理部署三个部分,具体来说:

数据准备
数据是保证模型效果的关键。而真实场景中往往存在数据不足的问题,因此在数据准备的部分,我们一般可以通过收集开源数据、数据增广、数据挖掘等手段来丰富训练数据。例如,在产品包装生产日期识别的范例中,我们利用现有的高精度大模型进行数据挖掘,补充真实场景训练数据,来优化小模型的效果。
模型训练
PP-OCR和PP-Structure系列模型都使用了大量训练数据,在通用场景可以一定程度地保证精度和泛化性,因此一般建议基于飞桨PP系列模型进行模型微调(finetune),从而实现使用较少的业务数据达到预期效果。基于不同场景业务数据训练的模型,有时需要针对前后处理进行任务适配,往往能进一步提升整体效果,偶尔甚至有“奇效”。如车牌识别范例中,通过后处理优化特殊符号的识别结果,大幅提升了整体识别精度。
推理部署
产业落地的最后一步是推理部署,如果在端侧部署,往往还需要做模型量化。我们在不同的范例中演示了不同的部署场景和方式,包括服务化部署、端侧部署等。
下表给出了本书20例的优化点汇总,方便查询阅读。
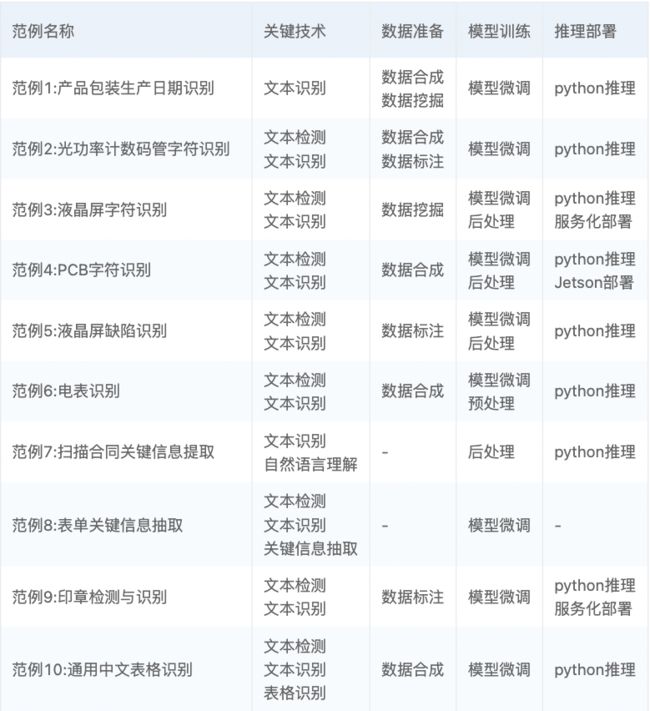
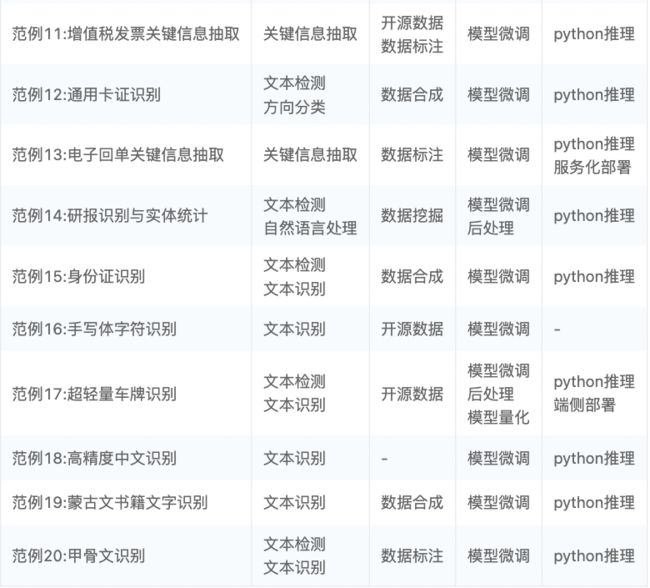
向下滑动查看所有优化点内容
 范例介绍
范例介绍
 智能电表缺陷检测
智能电表缺陷检测
郑州三晖电气股份有限公司
智能电表的外观检测是其质量检测的重要内容。液晶显示屏上的字符大小不一、密度大、种类多,特殊字符训练有难度。以往采用人工检测,耗费时间长、检测效率低下,传统机器视觉的模板匹配法上线新电表需要重新制作。采用深度学习的方法,基于PaddleOCR开发套件与PPOCRLabel半自动标注工具标注数据,微调PP-OCRv3检测与识别模型,最终在流水线上测试检测模型的准确率可达99%以上,识别模型的准确率达到96%以上。

 甲骨文识别
甲骨文识别
北京师范大学
当前甲骨文尚未完成国际编码,甲骨文字形多以图片而非矢量字体呈现,这给甲骨文的研究、应用和传播带来了诸多不便。利用计算机对甲骨文字形进行自动检测和识别,具有重要的现实意义。传统研究多是基于小样本的训练集,不能满足实用的需要。针对该场景,本案例构建了一个包括1,000个单字、374,161个字样的甲骨文已识字数据集,基于PaddleOCR和PaddleClas进行检测和识别训练。实验结果显示,本范例的检测精度为98%,识别精度为94%,帮助实现甲骨文已识字的快速检索和广泛传播。

 蒙文识别
蒙文识别
内蒙古阿尔泰电子信息技术有限公司
蒙古文文字识别技术在蒙古文信息处理领域是一个亟待解决的问题。由于蒙古文字符复杂、排版方向与简体中文不同、行宽的不一致等问题,导致目前产品化蒙古文文字识别仍有很多阻碍。针对以上问题,本例选用PP-OCRv3这一开源超轻量OCR系统进行蒙古文文本识别系统的开发,加入250万合成数据,在现有模型基础上进行微调,通过修正训练集,设定评估标准,最终将蒙古文识别精度从42%提升至75%。

 银行回单关键信息识别
银行回单关键信息识别
安科私(北京)科技有限公司
银行回单是企业财务记账的重要原始凭证之一。目前是由财务人员进行人工读取,提取账单中的收付款人、流水单号、金额等关键信息,结合财务记账规则进行处理,加工成记账凭证、资产负债表、开具发票。针对该场景,本范例基于PP-Structure训练命名实体识别、关系抽取模型并基于Hub Serving完成关键信息抽取的服务化部署,实现代替记账公司实现自动化记账报税功能。

 更多内容
更多内容
除了《OCR产业范例20讲》以外,深度学习和理解OCR的理论知识也必不可少。《动手学OCR》覆盖文本检测识别、文档分析等OCR全栈技术,配套电子书与教学视频,是开发者在OCR领域夯实理论基础、动手代码实践的另一本必不可少的书籍!



<<< 滑动查看更多图片 >>>
【获取方式】

更多内容可参考以下链接
飞桨官网
https://www.paddlepaddle.org.cn
PaddleOCR项目地址(Github)
https://github.com/PaddlePaddle/PaddleOCR
Gitee
https://gitee.com/PaddlePaddle/PaddleOCR

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~