Improving Conversational Recommender System by Pretraining Billion-scale Knowledge Graph论文笔记
原文章:Improving Conversational Recommender System by Pretraining Billion-scale Knowledge Graph (ICDE ‘21’)
这篇文章的思路相对比较简洁,同时从标题就能看出工作量很大,整体的模型框架是一个deep-cross网络,作者建立亿级的CKG并对其预训练得到两个特征:user-state和dialogue- interaction,把这两个特征以及其他常用特征作为D&C的输入来做一个推荐。
(下面就是我臭又长的翻译大作业了 写完真的人麻了
摘要
电子商务平台中的会话推荐系统 (CRS) 旨在通过多个会话交互向用户推荐商品,点击率 (CTR) 预测模型通常用于对候选项目进行排名。然而,大多数CRS都存在数据稀缺和稀疏的问题。为了解决这个问题,我们提出了一种新的知识增强型深度交叉网络 (K-DCN),一种两阶段(预训练和微调)CTR 预测模型来推荐项目。首先,我们利用用户、项目和对话的信息构建一个十亿级的对话知识图(CKG),然后引入知识图嵌入方法和图卷积网络对 CKG 进行预训练,分别对语义信息和结构信息进行编码。为了使 CTR 预测模型能够理解用户的当前状态以及对话和项目之间的关系,我们基于预训练的 CKG 引入了用户状态表示(user-state)和对话交互表示(dialogue-interaction),并提出了 K-DCN。在 K-DCN 中,我们通过深度交叉网络融合用户状态表示、对话交互表示和其他特征表示,排序候选项目用于推荐。通过实验证明我们提出的模型明显优于基线,并展示了它在 Alime 中的实际应用。
关键词:会话推荐系统、知识图、实体表示、点击率。
1.介绍
会话推荐系统(CRS)[1]-[5]通常用于改善电子商务平台上的用户体验, 许多在线店铺都有客户服务聊天机器人来帮助用户找到理想的商品,这对收入的贡献很大。 这些聊天机器人的目标是通过多次对话交互来识别用户的意图,然后向他们推荐最合适的项目列表。如图 1所示,在某个对话中,当用户请求推荐时,CRS 采用了三级流水线。 首先,它对查询进行语义分析,然后获取候选项目列表,最后通过深度点击率(CTR)模型对候选项目进行排名。

在本文中,我们关注 CRS 的排序过程,因此关键任务是预测 CTR,前人已经提出了各种基于深度网络的 CTR 预测模型[6]-[8],并取得了良好的性能。 然而,它们主要依赖于大量的用户行为记录,而这些记录可能非常稀少,因为与数百万在线商店中的只存在小部分聊天机器人,交互有限会导致过拟合问题。
为了解决数据稀缺和稀疏问题,我们建议考虑用户、项目和会话信息,因为会话中可能会表达对项目的某些偏好。
为了更好地组织和利用信息,我们的建议主要包括两部分:1)会话知识图谱(CKG)的构建和预训练; 2) 采用知识增强型de 深度交叉网络 (K-DCN) 进行微调。首先,我们根据用户、项目和对话的信息构建了一个十亿级的 CKG,然后学习一个预训练的模型以获得更好的实体表示。有两种常用的方法来学习 KG 中的实体表示,一种是基于图神经网络(GNN)的方法[9]-[13],它通过聚合其所有邻居的信息来对实体的结构信息进行建模,如 GCN[9]。另一种是知识图谱嵌入(KGE)方法,它们擅长捕获实体的语义信息,如基于翻译的方法[14]-[22]。由于实体的结构和语义信息都很重要,我们将基于 GNN 的方法和 KGE 方法结合起来,通过联合学习对 CKG 进行预训练。在第二部分中,我们提出了一种新颖的两阶段排序模型 K-DCN,在该模型中,我们引入了预训练得到的 CKG 的用户状态表示和对话交互表示,以帮助 CTR 预测模型感知到用户对话和项目之间的状态和关系。我们在现实生活中电子商务平台上的 CRS 中测试我们的模型。结果表明,我们的模型优于基线并且在训练过程中收敛速度更快。最后,我们展示了我们的模型在淘宝聊天机器人 Alimi 中的应用。
总之,我们的贡献如下:
- 我们建议以会话知识图(CKG)的形式整合用户、项目和会话信息,以解决CRS 中CTR 预测模型的数据稀缺和稀疏问题。
- 我们引入了一种组织和利用各种信息的新方法,首先从十亿级预训练的 CKG 中获得良好的实体表示,然后使用得到的用户状态表示和对话交互表示对 K-DCN 进行微调。
- 我们通过实验表明,我们的方法在现实电子商务数据集的训练过程中优于基线并且收敛速度更快,还展示了其在 Alimi 上的实际应用。
2.相关工作
A 基于翻译的知识图谱嵌入
基于翻译的方法采用评分函数 f ( h , r , t ) f (h, r, t) f(h,r,t) 来衡量来自 KG 的事实 ( h , r , t ) (h,r,t) (h,r,t) 的合理性。 例如,TransE [14] 中假设 f ( h , r , t ) = ∥ h + r − t ∥ f (h, r, t) = \mathbf{∥h + r − t∥} f(h,r,t)=∥h+r−t∥, TransH [15] 在计算分数之前将实体表示投影到关系的超平面上;TransR [16] 和 TransD [17] 通过投影矩阵将实体从实体空间投影到关系空间;TransEdge [18] 通过以边缘为中心的嵌入将关系上下文化;DistMult [19] 通过关系的组合来捕捉关系语义;RotateE [20] 旋转建模关系来学习各种关系模式。 然而,上述所有方法都没有学习KG的结构信息,而这是提供模型鲁棒性的重要来源。
B 基于GCN的知识图谱嵌入
基于 GCN 的方法通过迭代传播邻居信息来表示每个实体的嵌入。例如,GCN [9] 引入了 ChebNet 的一阶近似来进行图卷积,从而限制了参数的数量,避免了过拟合的问题; AGCN [10] 可以通过引入距离度量学习来学习所有图结构信息; DGCN [11] 提出了一个双图卷积,通过归一化邻接和正逐点互信息(PPMI)矩阵对局部和全局结构信息进行编码; GAT [12] 使用隐蔽的自我注意层为邻域信息分配不同的权重来学习其重要性; GeniePath [21] 使用自适应路径层来学习不同大小邻域的重要性,从而可以探索广度和深度以进行信息提取; Gaan [13] 通过子卷积网络控制每个注意力头的重要性。虽然这些方法可以对实体的邻居信息进行编码,但无法学习语义,会降低模型性能。
C 深度点击率预测模型
深度神经网络 (DNN) 和嵌入技术的发展为学习推荐系统中的特征表达提供了更好的方法。 例如,Deep & Cross Network(DCN) [6] 和 DeepFM [7], [23] 包含深层组件和浅层组件来自动捕获特征交互。 在常见的点击率预测模型中,具有稀疏和密集特征的输入数据主要关注用户行为和产品属性,仅使用嵌入技术来降低分类特征的维数。 但是在对话系统中,输入必须更具体地说明当前状态。 受 DKN [8] 的启发,对话系统中实体的知识级嵌入可以直接丰富用户状态和对话交互表示。
3.方法
我们的方法包含两部分:1)构建会话知识图(CKG)并对其进行预训练以编码结构信息和语义信息; 2)基于正常特征和来自预训练知识图表示的特征(包括用户状态表示和对话交互表示)微调排序模型 DCN。
A 构建和预训练CKG
1)构建对话知识图谱: 我们将知识图作为一种编码与对话推荐系统相关的各种信息的方式,并从用户聊天机器人对话的真实世界场景中构建 CKG。 CKG中包含三种信息:
-
用户信息:在我们的平台中,每个用户都有一个标签列表,例如性别、购物历史等,可以帮助捕捉用户的兴趣。 因此,我们在 CKG 中构建了以 (user, has, user tag) 形式对标签信息进行编码的三元组。
-
商品信息:我们的平台包含丰富的商品信息,如商品的类别、卖家、颜色、品牌等属性。对于品类和卖家信息,我们以 (item,belong to, category) 和 (seller, has, item) 的形式分别构建了三元组。 对于属性和值,构建了两种三元组(item, has, value)和(property, has, value),该项目信息可以极大地促进对用户兴趣的映射。
-
会话信息:在聊天机器人中,用户与机器人聊天时会创建很多会话,会话中的意图和关键字有助于准确地了解用户的意图。 因此,我们可以基于对话历史构建四种三元组,(user, created, session),(session, relate to, seller), (session, has, intention) 和 (intention, has, keywords)。
CKG 的架构如图 3 所示。最终,CKG 包含 6 亿个实体和 60 亿个三元组。

2)预训练对话知识图谱: 众所周知,结构信息和语义信息在知识图谱中都很有价值,因此我们的 CKG 预训练包含两个模块,结构嵌入模块和语义嵌入模块分别捕获这两种信息。
结构嵌入模块: 图神经网络(GNN)已被证明可用于编码结构信息 [9]- [13]。 因此,我们使用 GCN [9] 来学习 CKG 中实体的结构表示,其中每个实体 e ∈ K e ∈ \mathcal{K} e∈K 的向量表示为 e ∈ R d e ∈ \mathbb{R}^d e∈Rd。将所有实体嵌入按顺序收集在一起,我们得到 E ∈ R n e × d E ∈ \mathbb{R}^{n_e \times d} E∈Rne×d,其中 n e n_e ne 是 实体数量, d d d 是嵌入维度。 一个多层 GCN 给出了一个简单的逐层传播规则,第 i 层可以表示为:
X ( i + 1 ) = σ ( D ^ 1 2 A ^ D ^ − 1 2 X ( i ) W ( i ) ) X^{(i+1)} = \sigma (\hat D^{\frac{1}{2}} \hat A \hat D^{-\frac{1}{2}}X^{(i)}W^{(i)}) X(i+1)=σ(D^21A^D^−21X(i)W(i))
其中, A ^ ∈ R n × n \hat A \in \mathbb{R}^{n \times n} A^∈Rn×n 是邻接矩阵,当CKG中 e i e_i ei 和 e j e_j ej 有边相连, A ^ i j = 1 \hat A_{ij} = 1 A^ij=1 ;否则, A ^ i j = 0 \hat A_{ij} = 0 A^ij=0 。 D ^ \hat D D^ 是 A ^ \hat A A^ 的对角度矩阵。 n n n 是CKG中实体的数量, σ \sigma σ 是激活函数,在实验中使用的是sigmoid。 W ( i ) W^{(i)} W(i) 是第 i i i 层的权重矩阵。输出 X ( i + 1 ) X^{(i+1)} X(i+1) 把来自第 i i i 层的结构信息 X ( i ) X^{(i)} X(i) 进行编码。 在第一层, X ( 1 ) = E X^{(1)} = \mathbf {E} X(1)=E。
语义嵌入模块: 许多知识图谱嵌入(KGE)方法提出隐式编码语义信息,考虑到有效性和效率,我们在语义嵌入模块中使用 TransE。对于一个三元组 ( e i , r , e j ) (e_i,r,e_j) (ei,r,ej),评分函数定义如下
f ( e i , r , e j ) = ∣ ∣ e i , r , e j ∣ ∣ f(e_i,r,e_j) = ||\mathbf{e_i,r,e_j}|| f(ei,r,ej)=∣∣ei,r,ej∣∣
其中, e i , r , e j \mathbf{e_i,r,e_j} ei,r,ej 分别是 e i , r , e j e_i,r,e_j ei,r,ej 的嵌入想了,通过这个函数,正三元组得分较低,负三元组得分较高。
预训练: 联合训练结构嵌入模块和语义嵌入模块来学习实体和关系嵌入。 在协同训练期间,将GCN的输出 X i + 1 X^{i+1} Xi+1作为TransE的实体嵌入矩阵,即 e k = X k ( i + 1 ) ( k ∈ [ 0 , n − 1 ] ) e_k=X^{(i+1)}_k(k\in[0,n-1]) ek=Xk(i+1)(k∈[0,n−1]) ,训练目标是最小化基于边际的排名损失:
L = ∑ ( e i , r , e j ) ∈ T [ f ( e i , r , e j ) + γ − f ( e i ′ , r ′ , e j ′ ) ] + L=\sum \limits_{(e_i,r,e_j)\in \mathcal{T}}[f(e_i,r,e_j)+\gamma-f(e'_i,r',e'_j)]_+ L=(ei,r,ej)∈T∑[f(ei,r,ej)+γ−f(ei′,r′,ej′)]+
其中,其中当 x < 0 x<0 x<0, [ x ] + = 0 [x]_+= 0 [x]+=0 ,否则 [ x ] + = x [x]_+= x [x]+=x, ( e i ′ , r ′ , e j ′ ) (e'_i,r',e'_j) (ei′,r′,ej′)是negative sample,随机替换了 ( e i , r , e j ) (e_i,r,e_j) (ei,r,ej)中的 e i e_i ei或 e j e_j ej生成。在构建和预训练 CKG 之后,训练好的实体嵌入将用于微调 CTR 预测模型以改进会话推荐系统。
B 用于微调的K-DCN
通常,CTR 预测模型中会出现常见的稀疏和密集特征,例如:统计特征。而在对话推荐系统中,用户直接对聊天机器人的问题对于理解用户的意图也很重要,因此我们考虑并构建基于预训练CKG的特征:用户状态表示和对话交互表示。
1)用户状态表示: 用户的状态可以从他们之前的行为中捕获到,对于一个用户来熟,假设他的行为集合 B \mathcal{B} B 有 k k k 个行为, B = { b i ∣ b i = { e 1 ( i ) , e 2 ( i ) , . . . } , i ∈ [ i , k ] } \mathcal{B} = \{ b_i|b_i = \{ e_1^{(i)},e_2^{(i)},... \},i \in [i,k] \} B={bi∣bi={e1(i),e2(i),...},i∈[i,k]} , b i b_i bi 是一个用户-项目点击序列。对于每一个 b i b_i bi ,我们对行为中的项目嵌入做平均处理,以此得到行为向量 b i \mathbf{b}_i bi :
b i = 1 b i ∑ e j ( i ) ∈ b i e j ( i ) \mathbf{b}_i = \frac {1} {b_i} \sum\limits_{e_j^{(i)} \in b_i}e_j^{(i)} bi=bi1ej(i)∈bi∑ej(i)
然后我们垂直连接所有行为向量形成图 2 中的 B ∈ R d × k \mathbf{B} \in \mathbb{R}^{d \times k} B∈Rd×k ,并在 B \mathbf B B 上使用卷积神经网络(CNN)[24] 对用户状态表示的局部信息进行建模:
u = f C N N ( B ∗ w + b ) \mathbf u = f_{CNN}(\mathbf{B * w}+b) u=fCNN(B∗w+b)
其中, w \mathbf w w 是卷积操作,$b \in \mathbb{R} $ 是偏置,我们在标记为用户状态表示层的图 2 右侧显示了此步骤的详细信息。

2)对话交互表示: 为了建立用户对话交互表示,我们首先提取了一组用户问题中的关键词 W q u e r y = { w q ( 1 ) , w q ( 2 ) , . . . , w q ( m ) } \mathcal{W}_{query} = \{w_q^{(1)},w_q^{(2)},...,w_q^{(m)} \} Wquery={wq(1),wq(2),...,wq(m)} 。对于一个候选项目 c c c ,我们同样从其标题中提取一组关键词 W t i t l e = { w t ( 1 ) , w t ( 2 ) , . . . , w t ( n ) } \mathcal{W}_{title} = \{w_t^{(1)},w_t^{(2)},...,w_t^{(n)} \} Wtitle={wt(1),wt(2),...,wt(n)} 。然后,我们将所有关键字收集在一起,并从预训练的 CKG 实体嵌入中获得它们的表示,表示为 W = { w ( 1 ) , w ( 2 ) , . . . w ( m + n ) } \mathbf{W} = \{w^{(1)},w^{(2)},...w^{(m+n)} \} W={w(1),w(2),...w(m+n)} ,再将其输入到多头自注意力网络 [25] 中,以此对查询和候选项目之间的相互关系进行建模:
a i j = e x p ( ( M a w i ) ∘ ( M b w j ) ) ∑ t = 1 m + n e x p ( ( M a w i ) ∘ ( M b w k ) ) a_{ij} = \frac {exp((\mathbf{M_a w_i}) \circ (\mathbf{M_b w_j}))} {\sum_{t=1}^{m+n} exp((\mathbf{M_a w_i}) \circ (\mathbf{M_b w_k}))} aij=∑t=1m+nexp((Mawi)∘(Mbwk))exp((Mawi)∘(Mbwj))
其中, ∘ \circ ∘ 是点积操作, W a ∈ R d × d \mathbf{W_a} \in \mathbb{R}^{d \times d} Wa∈Rd×d 、 W b ∈ R d × d \mathbf{W_b} \in \mathbb{R}^{d \times d} Wb∈Rd×d 是将输入转换到新空间的矩阵。 ψ ( w i , w j ) = i n n e r p r o d u c t ( ( M a w i , M b w j ) ) \psi(\mathbf w_i,\mathbf w_j ) = inner product((\mathbf{M_a w_i},\mathbf{M_b w_j})) ψ(wi,wj)=innerproduct((Mawi,Mbwj)) 是注意力函数。
接下来我们通过加权和来更新表示:
w ~ ( i ) = ∑ j = 1 m + n a i , j ( W v e ( i ) ) \tilde w^{(i)} = \sum \limits^{m+n}_{j=1} a_{i,j} (\mathbf W_v \mathbf e^{(i)}) w~(i)=j=1∑m+nai,j(Wve(i))
最后,我们连接所有更新的词嵌入作为作为对话交互表示 $\mathbf d \in \mathbb R^{(m+n) \times d } $ :
d = [ w ~ ( 1 ) , w ~ ( 2 ) , . . . , w ~ ( m + n ) ] \mathbf d = [\tilde w^{(1)},\tilde w^{(2)},...,\tilde w^{(m+n)} ] d=[w~(1),w~(2),...,w~(m+n)]
3)K-DCN模型: K-DCN 的输入是候选项目 e e e 的各种特征表示。 除了上述用户状态表示 u \mathbf u u 和对话交互表示 d \mathbf d d 之外,还考虑了其他共同特征,如分类特征、统计特征。 首先,我们按如下方式连接所有特征向量:
f = [ c e ( 1 ) , c e ( 2 ) , . . . , c e ( k ) , x d e n s e , u , d ] \mathbf f = [\mathbf c^{(1)}_e,\mathbf c^{(2)}_e,...,\mathbf c^{(k)}_e,\mathbf x_{dense},\mathbf u,\mathbf d ] f=[ce(1),ce(2),...,ce(k),xdense,u,d]
其中, c e ( 1 ) , c e ( 2 ) , . . . , c e ( k ) \mathbf c^{(1)}_e,\mathbf c^{(2)}_e,...,\mathbf c^{(k)}_e ce(1),ce(2),...,ce(k) 是目标项目 e e e 所属类别的嵌入,会在训练期间随机初始化。 x d e n s e \mathbf x_{dense} xdense 是 e e e 的统计特征向量,值可以是价格、销售额等。
我们将 e e e 的特征表示 f f f 分别输入交叉网络和深度网络,这是 CTR 预测模型中的两个常见组件。 交叉网络由 n c n_c nc 个交叉层组成,第 i i i 层可以表示为:
x c ( i + 1 ) = f ( x c ( i + 1 ) ) T w i + b i + x c ( i ) \mathbf x_c^{(i+1)} = \mathbf f ( \mathbf x_c^{(i+1)})^T \mathbf w_i + \mathbf b_i +\mathbf x_c^{(i)} xc(i+1)=f(xc(i+1))Twi+bi+xc(i)
x c 0 = f \mathbf x_c^0 = \mathbf f xc0=f ,深度网络是一个 n d n_d nd 层全连接的前馈网络,第 i i i 层的可以表示为:
x d ( i + 1 ) = σ ( W i x d ( i ) + b l ) \mathbf x_d^{(i+1)} = \sigma(W_i\mathbf x_d^{(i)} + \mathbf b_l ) xd(i+1)=σ(Wixd(i)+bl)
然后我们将两个网络的输出连接起来,送入一个标准的 logits 层:
p = σ ( [ x c ( n c ) , x d ( n d ) ] W l o g i t s ) p = \sigma([\mathbf x_c^{(n_c)},\mathbf x_d^{(n_d)}] \mathbf W_{logits} ) p=σ([xc(nc),xd(nd)]Wlogits)
为了训练 k-DCN,我们最小化如下的对数似然损失函数:
L K − D C N = − 1 N ∑ i = 1 N y i l o g ( p i ) + ( 1 − y i ) l o g ( 1 − p i ) L_{K-DCN} = -\frac {1} {N} \sum\limits^N_{i=1} y_i {\rm log} (p_i) + (1-y_i) {\rm log}(1-p_i) LK−DCN=−N1i=1∑Nyilog(pi)+(1−yi)log(1−pi)
其中, N N N 是输入样本的数量, y i ∈ R n c a n d × 1 y_i \in \mathbb R ^{n_{cand} \times 1 } yi∈Rncand×1 是第 i i i 个样本的推荐标签, n c a n d n_{cand} ncand是要推荐的候选项目数。
4.实验与讨论
A 数据集
K-DCN 在私有数据集上进行预训练和微调。 训练 CTR 预测模型的数据集来自Alime salebot的对话(如图1所示)。 表 1 展示了我们从 10 个类别中抽取的 90 万条记录。

B 实验细节
- CKG: 预训练的 KG 模型在十亿级对话知识图(CKG)上进行训练。 CKG 共有 5 亿个实体和 60 亿个三元组。 我们使用阿里巴巴的 max-reduce 框架(Maxcompute)将数据处理成三元组。 删除了 CKG 中出现次数小于 5000 的属性,因为这些属性非常稀疏,很可能会降低模型性能。 训练阶段,我们使用 [26] 中的工具 Graph-learn 对 10 个邻居进行采样以进行结构预训练,批大小为 512。采用 Adam 优化器,初始学习率 = 0.0001; 每个训练批次大小 = 1000,节点嵌入大小 = 64。该模型使用 50 个参数服务器和 200 块GPU 训练 5 个周期。 整个训练耗时2天。
- K-DCN: K-DCN 在 Tensorflow 上实现。超参数通过网格搜索进行调整,最佳超参数设置是 2 个 512 的深度层和 4 个交叉层。 具体来说,我们在用户状态表示中使用了 4 种行为,卷积算子的大小为 N × i t e m E m b e d d i n g S i z e N × itemEmbeddingSize N×itemEmbeddingSize,其中 N N N 为 2 和 4。文本嵌入的注意力头数为 4。对于不同大小的卷积算子, 输出连接为最终输出。 我们使用带有 Adam [27] 优化器的小批量随机优化,批量大小设置为 512。
C 结果和讨论
我们将我们的方法与 5 个基线在 10 个数据集中进行比较:deep&cross网络 (DCN) [6]、Wide&Deep网络 (WDN) [28]、深度神经网络 (DNN) [29]、梯度提升决策树 (GBDT) [30] 和逻辑回归 (LR) [31] ,结果如表 2 所示, K-DCN 优于所有数据集中的所有基线。
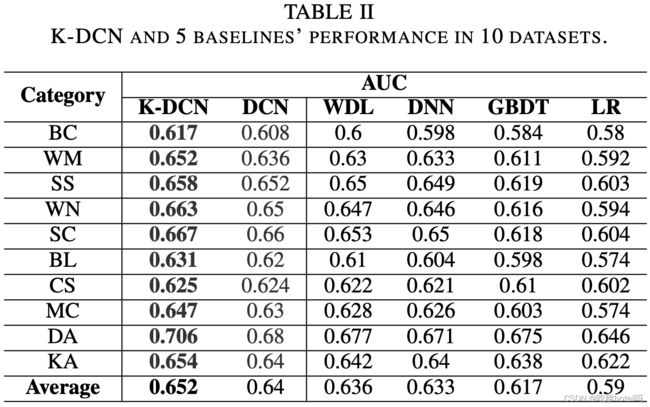
具体而言,K-DCN 在数码配件类别中高出了 2.6% 。主要原因是数码配件类别的训练数据数量非常有限,这验证了我们从会话知识中预训练的模型可以缓解数据稀缺的问题。对于所有数据集,K-DCN 的平均改进了 1.2%,这验证了从对话知识图中提出的 KG 嵌入可以为 CTR 预测模型提供有意义且有用的结构信息和语义信息。更重要的是,如图 5 所示,当使用预训练的 KG 嵌入来初始化 CTR 预测模型时,它也会加速收敛。我们还在 Alime 的实际应用中(如图 4 所示)测试了我们的 K-DCN 与 DCN,从表 3 中可以看出,K-DCN 相对于 DCN 有 4.2% 的改进,这证明了 K-DCN 的有效性。



5.总结
在本文中,我们提出了一个两阶段 CTR 预测模型 K-DCN。 我们首先构建了一个基于数十亿规模的对话知识图的预训练模型 KGM。 然后我们提出了一种基于 KGM 以及一些密集和稀疏特征的知识增强型深度交叉网络(K-DCN)模型。 实验结果表明,与基线相比,我们的模型在 10 个数据集上获得了可观的性能。 K-DCN 已应用于最大的电子商务公司的聊天机器人。 在未来的工作中,我们计划设计一个学习框架,该框架可以统一利用来自异构知识源的证据,例如实体描述和知识模式。
参考文献
[1] J. Gao, M. Galley, and L. Li, “Neural approaches to conversational ai,” in The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, 2018, pp. 1371–1374.
[2] A. Rahman, A. Al Mamun, and A. Islam, “Programming challenges of chatbot: Current and future prospective,” in 2017 IEEE Region 10 Humanitarian Technology Conference (R10-HTC). IEEE, 2017, pp. 75–78.
[3] A. Fadhil, “Can a chatbot determine my diet?: Addressing chal- lenges of chatbot application for meal recommendation,” arXiv preprint arXiv:1802.09100, 2018.
[4] I. Nica, O. A. Tazl, and F. Wotawa, “Chatbot-based tourist recommen- dations using model-based reasoning.” in ConfWS, 2018, pp. 25–30.
[5] C. Hildebrand and A. Bergner, “Ai-driven sales automation: Using chatbots to boost sales,” NIM Marketing Intelligence Review, vol. 11, no. 2, pp. 36–41, 2019.
[6] R. Wang, B. Fu, G. Fu, and M. Wang, “Deep & cross network for ad click predictions,” in Proceedings of the ADKDD’17, 2017, pp. 1–7.
[7] H. Guo, R. Tang, Y. Ye, Z. Li, and X. He, “Deepfm: a factorization- machine based neural network for ctr prediction,” arXiv preprint arXiv:1703.04247, 2017.
[8] H. Wang, F. Zhang, X. Xie, and M. Guo, “Dkn: Deep knowledge-aware network for news recommendation,” in Proceedings of the 2018 world wide web conference, 2018, pp. 1835–1844.
[9] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
[10] R. Li, S. Wang, F. Zhu, and J. Huang, “Adaptive graph convolutional neural networks,” in Thirty-second AAAI conference on artificial intel- ligence, 2018.
[11] C. Zhuang and Q. Ma, “Dual graph convolutional networks for graph- based semi-supervised classification,” in Proceedings of the 2018 World Wide Web Conference, 2018, pp. 499–508.
[12] R. Li, S. Wang, F. Zhu, and J. Huang, “Adaptive graph convolutional neural networks,” in Thirty-second AAAI conference on artificial intel- ligence, 2018.
[13] J.Zhang,X.Shi,J.Xie,H.Ma,I.King,andD.-Y.Yeung,“Gaan:Gated attention networks for learning on large and spatiotemporal graphs,”arXiv preprint arXiv:1803.07294, 2018.
[14] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” in Ad- vances in neural information processing systems, 2013, pp. 2787–2795.
[15] Z.Wang,J.Zhang,J.Feng,andZ.Chen,“Knowledgegraphembedding by translating on hyperplanes,” in Twenty-Eighth AAAI conference on artificial intelligence, 2014.
[16] Y.Lin,Z.Liu,M.Sun,Y.Liu,andX.Zhu,“Learningentityandrelation embeddings for knowledge graph completion,” in Twenty-ninth AAAI conference on artificial intelligence, 2015.
[17] G. Ji, S. He, L. Xu, K. Liu, and J. Zhao, “Knowledge graph embedding via dynamic mapping matrix,” in Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2015, pp. 687–696.
[18] Z. Sun, J. Huang, W. Hu, M. Chen, L. Guo, and Y. Qu, “Transedge: Translating relation-contextualized embeddings for knowledge graphs,” in International Semantic Web Conference. Springer, 2019, pp. 612– 629.
[19] B.Yang,W.-t.Yih,X.He,J.Gao,andL.Deng,“Embeddingentitiesand relations for learning and inference in knowledge bases,” arXiv preprint arXiv:1412.6575, 2014.
[20] Z. Sun, Z.-H. Deng, J.-Y. Nie, and J. Tang, “Rotate: Knowledge graph embedding by relational rotation in complex space,” arXiv preprint arXiv:1902.10197, 2019.
[21] Z. Liu, C. Chen, L. Li, J. Zhou, X. Li, L. Song, and Y. Qi, “Geniepath: Graph neural networks with adaptive receptive paths,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, 2019, pp. 4424–4431.
[22] W.Zhang,B.Paudel,W.Zhang,A.Bernstein,andH.Chen,“Interaction embeddings for prediction and explanation in knowledge graphs,” in WSDM. ACM, 2019, pp. 96–104.
[23] S. Wang, “Research of shopping recommendation system based on improved wide-depth network,” MS&E, vol. 768, no. 7, p. 072072, 2020.
[24] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097–1105.
[25] A.Vaswani, N.Shazeer, N.Parmar, J.Uszkoreit, L.Jones, A.N.Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advancesin neural information processing systems, 2017, pp. 5998–6008.
[26] R. Zhu, K. Zhao, H. Yang, W. Lin, C. Zhou, B. Ai, Y. Li, and J. Zhou, “Aligraph: a comprehensive graph neural network platform,” Proceedings of the VLDB Endowment, vol. 12, no. 12, pp. 2094–2105,2019.
[27] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014.
[28] H.-T. Cheng, L. Koc, J. Harmsen, T. Shaked, T. Chandra, H. Aradhye, G. Anderson, G. Corrado, W. Chai, M. Ispir et al., “Wide & deep learning for recommender systems,” in Proceedings of the 1st workshop on deep learning for recommender systems, 2016, pp. 7–10.
[29] W. Liu, Z. Wang, X. Liu, N. Zeng, Y. Liu, and F. E. Alsaadi, “A survey of deep neural network architectures and their applications,” Neurocomputing, vol. 234, pp. 11–26, 2017.
[30] G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.- Y. Liu, “Lightgbm: A highly efficient gradient boosting decision tree,” in Advances in neural information processing systems, 2017, pp. 3146– 3154.
[31] D. G. Kleinbaum, K. Dietz, M. Gail, M. Klein, and M. Klein, Logistic regression. Springer, 2002.