机器学习算法之分类
1. 机器学习
机器学习是近20多年兴起的一门多领域交叉学科,它涉及到概率论、统计学、计算机科学以及软件工程等多门学科。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类能从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法 [1]。
机器学习(Machine Learning)是人工智能(AI)中很重要的一部分,因为在目前的实践过程中,大多数人工智能问题是由机器学习的方式实现的。所以说机器学习是实现人工智能(AI)的一个途径,即以机器学习的手段解决人工智能中的问题。它可以被设计用程序和算法自动学习并进行自我优化,同时,需要一定数量的训练数据集(traing dataset)来构建过往经验“知识”。
目前机器学习已经广泛应用于数据挖掘、计算机视觉、自然语言处理、语音和手写识别、生物特征识别、医学诊断、检测信用卡欺诈、证券市场分析、搜索引擎、DNA序列测序、无人驾驶、机器人等领域。
2. 机器学习方法
机器学习算法有很多,有分类、回归、聚类、推荐、图像识别领域等等,具体算法比如线性回归、逻辑回归、朴素贝叶斯、随机森林、支持向量机、神经网络等等。在机器学习算法中,没有最好的算法,只有“更适合”解决当前任务的算法。
机器学习算法的分类方式有很多种,
- 如果按照学习方式分类可分为
| 学习方式 | 英文 | 描述 |
|---|---|---|
| 监督式学习 | Supervised Learning | 训练集目标:有标注; 如回归分析,统计分类 |
| 非监督式学习 | Unsupervised Leanring | 训练集目标:无标注;如聚类、GAN(生成对抗网络) |
| 半监督式学习 | Semi-supervised Leanring | 介于监督式与无监督式之间 |
| 增强学习 | Reinforcement Leanring | 智能体不断与环境进行交互,通过试错的方式来获得最佳策略 |
- 如果按照学习任务分类可分为以下三类:
| 学习任务 | 英文 | 描述 |
|---|---|---|
| 分类 | Classification | 分类是预测一个标签 (是离散的),属于监督学习 |
| 回归 | Regression | 回归是预测一个数量 (是连续的),属于监督学习 |
| 聚类 | Clustering | 属于无监督学习 |
- 它们之间的关系如下图所示 [2]
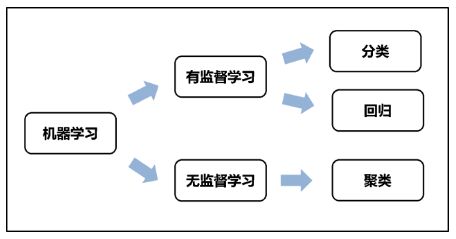
这篇入门教程主要介绍机器学习中的分类任务。
3. 机器学习方法——分类
分类方法是一种对离散型随机变量建模或预测的监督学习方法。其中分类学习的目的是从给定的人工标注的分类训练样本数据集中学习出一个分类函数或者分类模型,也常常称作分类器(classifier)。当新的数据到来时,可以根据这个函数进行预测,将新数据项映射到给定类别中的某一个类中。
对于分类,输入的训练数据包含信息有特征(Feature),也称为属性(Attribute),有标签(label),也常称之为类别(class),具体可表示为(F1,F2,...Fn; label)。而所谓的学习,其本质就是找到特征与标签间的关系(mapping 即映射) 。所以说分类预测模型是求取一个从输入变量 (特征) x 到离散的输出变量(标签)y 之间的映射函数f(x)。这样当有特征而无标签的未知数据输入时,可以通过映射函数预测未知数据的标签。
简单地说,分类就是按照某种标准给对象贴标签,再根据标签来区分归类。类别是事先定义好的,例如,在CTR(点击率预测)中,对于一个特定商品,一个用户可以根据过往的点击商品等信息被归为两类【会点击】和【不会点击】;类似的,房屋贷款人可以根据以往还款经历等信息被归为两类【会拖欠贷款】和【不会拖欠贷款】; 一个文本邮件可以被归为【垃圾邮件】和【非垃圾邮件】两类。
机器学习分类算法:
3.1. Logistic 回归 (对数几率回归)
Logistic Regression不光可以做二元分类,也可以解决多元分类问题。
3.2. 最小二乘回归(Ordinary Least Squares Regression)
3.3. 贝叶斯分类
-
- 朴素贝叶斯(Navie Bayesian Classification)
-
prior probability 先验概率
-
posterior probability后验概率
-

3.4. 分类树
决策树(Decision Tree)可分为分类树与回归树。分类树使用信息增益或信息增益比率来划分节点,每个节点样本的类别情况投票(voting)决定测试样本的类别。下图[4]是在西瓜数据集2.0上基于信息增益生成的决策树。

-
- ID3(Iterative Dichotomiser)迭代二分器
-
- 最优划分属性方法:信息增益 (Information Gain)
-
- C4.5
-
- 最优划分属性方法:信息增益率 (Gain ratio)
-
- CART (分类与回归树:Classification and Regression Tree)
-
- 可做分类也可做回归分析
-
- 最优划分属性方法:基尼指数 (Gini index)
3.5. 支持向量机 (Support Vector Machine)
SVM可通过升维来解决在低维中线性不可分的问题,旨在找到一个超平面(Hyperlane)作为线性决策边界(decision boundry),最大化分类边界,将特征空间中的数据更好的分隔开。SVM有着优秀的泛化能力,但更适用于小样本训练,因为svm对于内存消耗很大。若数据量很大,训练时间会较长。且SVM在小样本上能够得到比其他算法好很多的结果。

3.6. KNN(K-Nearest Negihbour)
K近邻是基于实例的分类(instance-based learning) ,属于惰性学习 (lazy learning) 。比如在现实中,预测某一个房子的价格,就参考最相似的K个房子的价格,比如距离最近、户型最相似等等。KNN没有明显的训练学习过程,不同K值的选择都会对KNN算法的结果造成重大影响。如下图所示,k=1与k=3预测的类别是不同的。

3.7. 集成学习(Ensembale Learning)
-
- Bagging
-
Bagging这个名字是Boostrap AGGregatING缩写而来的,是并行式集成学习方法的最著名代表。
-
- Random Forest (随机森林)
 随机森林是一个包含多个决策树的分类器,其输出的类别是由各个子树数据类别的众数(majority voting)决定的。当你不知道该用什么算法来处理分类的时候,随机森林都是一个作为尝试的不错的选择。
随机森林是一个包含多个决策树的分类器,其输出的类别是由各个子树数据类别的众数(majority voting)决定的。当你不知道该用什么算法来处理分类的时候,随机森林都是一个作为尝试的不错的选择。
-
- Boosting
-
Boosting是一族将弱学习器提升为强学习器的算法[4]。
-
- GBDT(Gradient Boost Decision Tree)
-
- Adaboost
-
3.8. 深度学习(Deep Learning)
-
- CNN(卷积神经网络)
-
Convolutional Neural Networks [5]
-

卷积神经网络是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。在图像和语音识别方面能够给出更好的结果。
-
- [
GAN(生成对抗网络)](
http://arxiv.org/abs/1406.2661)
-
Generative Adversarial Networks [6]
-
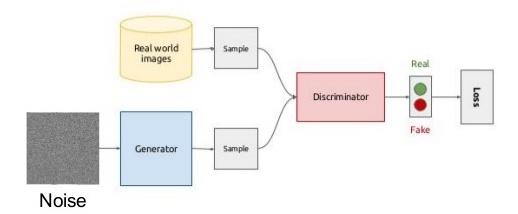 GAN是于2014年由Goodfellow提出,成为近几年比较流行的生成网络形式。对比传统的生成模型, GAN减少了模型限制和生成器限制, 具有有更好的生成能力。生成式网络(Generative Network)与判别式网络 (Discrimative Network)不断相互对抗(Adversarial)学习,达到优化生成网络的目的。在半监督式生成网络中,还可达到优化判别式网络(即分类器classifier)的母的。GAN的目前成功的应用在了在图像生成、高清图片生成、交互图像生成、图像修复、语义分割、视频生成、根据图片生成impressive的文字描述等领域。
GAN是于2014年由Goodfellow提出,成为近几年比较流行的生成网络形式。对比传统的生成模型, GAN减少了模型限制和生成器限制, 具有有更好的生成能力。生成式网络(Generative Network)与判别式网络 (Discrimative Network)不断相互对抗(Adversarial)学习,达到优化生成网络的目的。在半监督式生成网络中,还可达到优化判别式网络(即分类器classifier)的母的。GAN的目前成功的应用在了在图像生成、高清图片生成、交互图像生成、图像修复、语义分割、视频生成、根据图片生成impressive的文字描述等领域。
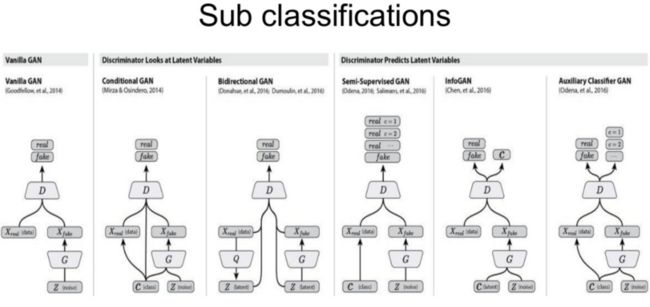
如下图所示[6],GAN的子类型有很多,如Deep Convolutional GAN(DCGAN), Semi-Supervised GAN, Conditional GAN等,可根据不同的任务目的选择不同类型的GAN来处理。
在下面一篇进阶版的教程中,会带大家一起动手练习如何用逻辑回归做鸢尾花数据集的分类 (1)。
4.更多分类算法应用项目
如果你想了解更多关于上述分类算法的应用实例,可以查看社区中其他用户创建的项目:
- 用逻辑回归实现鸢尾花数据集分类(2)
- 全新PaddlePaddle 0.11.0 --- 线性回归问题研究
- K最近邻分类算法(KNN)
- 利用决策树分析titanic数据
- 用KNN,Logisticregression预测股票
- 利用Keras探索Mnist数据集
- 在K-Lab中分别使用Tensorflow与Keras完成对Mnist数据集分析
- 用PaddlePaddle做深度学习 --- 识别数字
- 运用神经网络进行鸢尾花分类
参考文献
[1] https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0
[2] https://www.cnblogs.com/XinZhou-Annie/p/7253049.html
[3] https://kgpdag.wordpress.com/2015/08/12/svm-simplified/
[4] 周志华. 机器学习.清华大学出版社,2016
[5] https://adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
[6] https://www.slideshare.net/Artifacia/generative-adversarial-networks-and-their-applications