woff字体图元结构剖析,自定义字体的制作与匹配和识别
下次点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
归山深浅去,须尽丘壑美。
大家好,我是小小明。
前面我在2万字硬核剖析网页自定义字体解析(css样式表解析、字体点阵图绘制与本地图像识别等)一文中,讲解了通过图像识别来解析自定义字体,但是图像识别的缺点在于准确率并不能达到100%,还需要二次修改。
前面将字体的称为点阵图,其实根据TrueType字体实际采用的技术,称为轮廓图更为合适,所以本文所说的轮廓图就是上篇的点阵图。
由于目前几个大厂的网站的自定义字体的轮廓图都是那个固定的顺序,所以上文只处理了所有字体文件轮廓图顺序都一致的情况,并没有继续深挖去处理轮廓图顺序出现随机的情况。
本文就将针对未来自定义字体的轮廓图顺序出现随机的情况进行处理。
具体处理思路就是,提取字体的图元数据,包括控制点位置和标志位,转成二进制字节进行唯一标识,与现有的已知的字符集进行映射。后续任何Unicode代码点顺序随机和轮廓图顺序随机的字体文件,都可以提取图元数据转换后进行唯一匹配从而解码出唯一正确的字符。
不过上述思路还只是处理了轮廓图顺序随机,其实还可以再变态点以多个基础字形制作自定义字体取随机,意味着每个字符的图元数据都会发生较大变化,上面的匹配方法就会直接失效。此时便只能通过机器学习计算字符间的相似度,从而识别出图元对应的真实字符。
字体格式类型介绍
字体格式类型主要有几个大分类:TrueType、Embedded Open Type 、OpenType、WOFF 、SVG。
TrueType:
Windows和Mac系统最常用的字体格式,基于轮廓技术的数学模式来进行定义,比基于矢量的字体更容易处理,保证了屏幕与打印输出的一致性。同时,这类字体和矢量字体一样可以随意缩放、旋转而不必担心会出现锯齿。
EOT – Embedded Open Type (.eot):
微软开发的嵌入式字体,允许OpenType字体用@font-face嵌入到网页并下载至浏览器渲染,存储在临时安装文件夹下。
OpenType (.otf):
微软和Adobe共同开发的字体,微软的IE浏览器全部采用这种字体,致力于替代TrueType字体。
WOFF – Web Open Font Format (.woff):
专门为了Web而设计的字体格式标准,实际上是对TrueType/OpenType等字体格式的封装,每个字体文件中含有字体以及针对字体的元数据(Metadata),字体文件被压缩,以便于网络传输。
SVG (Scalable Vector Graphics) Fonts (.svg):
使用SVG技术来呈现字体,支持gzip压缩格式。
在上次从css的@font-face提取出字体URL链接时,就包含了eot和woff两种格式。鉴于woff字体更容易被分析,所以我们上次选择了只下载woff字体格式,今天这篇文章也一样。
字体格式转换工具:
https://www.fontsquirrel.com/tools/webfont-generator
https://everythingfonts.com/可以生成自定义字体的网站:
https://icomoon.io/app/#/select
http://fontello.com如何生成自定义字体
先生成svg字体,再导入到自定义字体生成网站,再定义字体映射关系,最后导入字体即可。
由于https://everythingfonts.com/对文件较大的字体转换需要收费,这里我使用https://www.fontsquirrel.com/tools/webfont-generator将系统自带的arial.ttf字体文件转换为svg字体:

下载并解压得到一个arial-webfont.svg文件。
接下来打开https://icomoon.io/app/#/select,选择需要被自定义的字符:

本例选择了0-9作为被自定义的字符,然后点击右下角 Generate Font 按钮准备设置字符映射:

设置好映射关系后,点击下载字体。
下载的压缩包包含多种字体,解压出其中的icomoon.woff字体文件。
用FontCreator字体设计工具打开后可以看到如下结果:
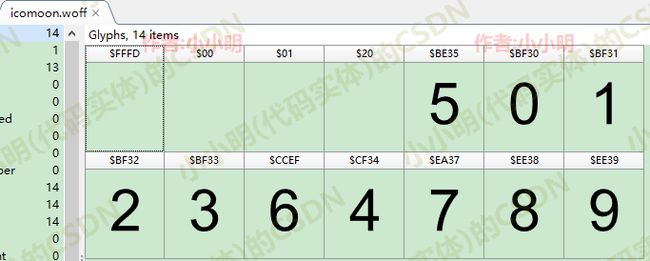
可以看到与我们前面在网站中自定义的映射一致。
woff字体的解析 首先,我们用python的fontTools库读取上次下载的字体文件:
from fontTools.ttLib import TTFont
font = TTFont("tagName.woff")可以一次性将相关数据保存到本地:
font.saveXML("tagName.xml")字体文件都包含了一个TableDirectory结构,保存了多张表,每个表保存了不同的信息。
TrueType字体中常见的表有:

字体头表(head表)
字体头表(head表)中包含了TrueType字体的全局信息,在c语言中的结构定义如下:
typedef sturct
{
Fixed Table;//x00010000 ro version 1.0
Fixed fontRevision;//Set by font manufacturer.
ULONG checkSumAdjustment;
ULONG magicNumer; //Set to 0x5f0f3cf5
USHORT flags;
USHORT unitsPerEm; //Valid range is from 16 to 16384
longDT created; //International date (8-byte field).
longDT modified; //International date (8-byte field).
FWord xMin; //For all glyph bounding boxes.
FWord yMin; //For all glyph bounding boxes.
FWord xMax; //For all glyph bounding boxes.
FWord xMax; //For all glyph bounding boxes.
USHORT macStyle;
USHORT lowestRecPPEM; //Smallest readable size in pixels.
SHORT fontDirctionHint;
SHORT indexToLocFormat; //0 for short offsets ,1 for long.
SHORT glyphDataFormat; //0 for current format.
}Table_head;上面各个字段定义基本都能直接在python中读取,其中日期字段有created和modified,分别表示字体创建时间和字体最后修改时间,使用8个字节记录从1904年1月1日午夜12:00开始的秒数。
获取字体的创建时间和字体最后修改时间:
import datetime
head = font['head']
base = datetime.datetime(1904, 1, 1, 0, 0, 0)
create_time = base+datetime.timedelta(seconds=head.created)
modifie_time = base+datetime.timedelta(seconds=head.modified)
print(f"创建时间:{create_time},最后修改时间:{modifie_time}")创建时间:2021-08-02 15:00:30,最后修改时间:2021-08-02 15:00:30字体是针对一个被称为em-square的参考网格设计的,字体中的图元用网格中的坐标表示。em-squrare的大小决定字体的图元被缩放的方式和质量。字体头中保存了每个em-square的格数和能 包含所有图元的边界框。Em-square的有效值是从16到16384。
读取每个em-square的格数和图元边界框范围:
print(f"每个em-square的格数:{head.unitsPerEm},边界框范围x: {head.xMin} - {head.xMax},y: {head.yMin} - {head.yMax}")每个em-square的格数:1000,边界框范围x: 0 - 1136,y: -112 - 833字体头表中的其他信息包括最小可读像素大小、字体方向、在位置表中图元索引的格式和图元数据格式等:
head.lowestRecPPEM, head.fontDirectionHint, head.indexToLocFormat, head.glyphDataFormat(8, 2, 0, 0)字符到图元索引的映射表(cmap表)
字符到图元索引的映射表(cmap表)定义了从不同代码页中的字符代码到图元索引的映射关系。cmap表包含几个子表以支持不同的平台和不同的字符编码方案。cmap表在c语言中的定义较为复杂,不作展示。
在python中我们可以通过cmap表获取字符代码到图元索引的映射关系:
cmap = font['cmap']
cmap.getBestCmap(){120: 'x',
57360: 'unie010',
57369: 'unie019',
57370: 'unie01a',
...
63699: 'unif8d3',
63718: 'unif8e6',
63724: 'unif8ec'}不过获取这个关系也并没有太大的意义,因为我们可以很轻松的进行相互转换:
"uni"+chr(57360).encode("unicode_escape").decode()[2:]就可以得到对应的unie010,反过来也可以:
char = 'unie010'
ord(("\\u"+char[3:]).encode().decode("unicode_escape"))即可得到57360。
当然fontTools本身也提供了反向获取的API:
cmap.buildReversed(){'x': {120},
'unie010': {57360},
'unie019': {57369},
'unie01a': {57370},
...
'unif8d3': {63699},
'unif8e6': {63718},
'unif8ec': {63724}}图元数据(glyf表)
图元数据(glyf表)是我们所需要的字体核心信息,以序列形式保存了图元数据,每个图元以图元头(GlyphHeader)结构开始,在c语言中的定义为:
typedef struct
{
WORD numberOfContours; //contor number,negative if composite
FWord xMin; //Minimum x for coordinate data.
FWord yMin; //Minimum y for coordinate data.
FWord xMax; //Maximum x for coordinate data.
FWord yMax; //Maximum y for coordinate data.
}GlyphHeader;合成图元由多个简单图元或合成图元组成,简单图元的numberOfContours字段保存了当前图元的轮廓线的数目。而合成图元的numberOfContours字段为负值,表示需要基于组成该合成图元的所有简单图元的轮廓线的数目计算得到。后四个字段记录了图元的边界框。
简单图元的图元描述信息紧跟在其GlyphHeader结构之后,c语言定义为:
USHORT endPtsOfContours[n]; //n=number of contours
USHORT instructionlength;
BYTE instruction[i]; //i = instructionlength
BYTE flags[]; //variable size
BYTE xCoordinates[]; //variable size
BYTE yCoordinates[]; //variable size包括所有轮廓线结束点的索引、图元指令和一系列的控制点,每个控制点包括包括一个标志和xy轴坐标。
endPtsOfContours数组保存了每一条轮廓线终点的索引,通过该索引可以计算出每条轮廓线中点的数量。比如,endPtsOfContours[0]+1是第一条轮廓线上点的数量,endPtsOfContours[1]-endPtsOfContours[0]是第二条轮廓线上点的数量。
图元的控制点保存在三个数组中:标志获得组、x坐标数组和y坐标数组。为了节省存储空间,图元中保存的是相对坐标。第一个点的坐标是相对原点(0, 0)记录的,随后的点记录和上一个点的坐标差值。标志数组保存了每个坐标的编码信息以及其他一些信息。下面是标志中各个位的含义(c语言定义):
typedef enum
{
G_ONCURVE=0x01, // on curve ,off curve
G_REPEAT=0x08, // next byte is flag repeat count
G_XMASK=0x12,
G_XADDBYTE=0x12, //X is positive byte
G_XSUBBYTE=0x12, //X is negative byte
G_XSAME=0x10, //X is same
G_XADDINT=0x00, //X is signed word
G_YMASK=0x24,
G_YADDBYTE=0x24, //Y is positive byte
G_YSUBBYTE=0x04, //Y is negative byte
G_YSAME=0x20, //Y is same
G_YADDINT=0x00, //Y is signed word
};在轮廓技术的数学模式中,一段三阶的Bezier曲线由四个控制点定义:位于曲线上的起始点、两个不在曲线上(off-curve)的控制点和一个曲线上的结束点。
字体中的图元轮廓用二阶Bezier曲线定义,有三个点:一个曲线上的点,一个曲线外的点和另一个曲线上的点。对于多个连续不在曲线上的点,会隐式加入一些点使其符合二阶Bezier曲线曲线的定义。例如,on-off-off-on模式的四个点,会隐式加入一个点使之成为on-off-on-off-on的五个点。
G_ONCURVE位表示控制点是否在曲线上,设置G_REPEAT位表示标志数组的下一字节表示重复次数,当前标志被重复指定的次数。解码图元的描述需要两次扫描起始点,然后再遍历图元定义中的每一个点进行转换。
图元指令具体细节比较复杂,主要是为了控制图元轮廓从em-square到栅格网格的缩放过程,通过网格调整技术使缩放后的渲染不失真,而记录控制值的一张表。
整体来说渲染图元是一个非常复杂的算法,咱们不再继续深究。
下面看看fontTools库能够读取到的图元数据,首先读取glyf表:
glyf = font["glyf"]我们以字符0为例进行演示,查看到该字体中数字0对应的代码点为unif82e。
首先查看图元头信息:
glyph = glyf['unif82e']
print(f"轮廓线数目:{glyph.numberOfContours},边界范围:({glyph.xMin},{glyph.yMin})-({glyph.xMax},{glyph.yMax})")轮廓线数目:2,边界范围:(0,-14)-(550,729)前面已经提到,每个点记录的是和上一个点的坐标差值,所以边界范围存在负数很好理解。
获取每条轮廓线终点的索引:
glyph.endPtsOfContours[12, 25]可以计算出两条轮廓线点的数量:
num1 = glyph.endPtsOfContours[0]+1
num2 = glyph.endPtsOfContours[1]-glyph.endPtsOfContours[0]
print(f"第一条轮廓线上点的数量为{num1},第二条轮廓线上点的数量为{num2}")第一条轮廓线上点的数量为13,第二条轮廓线上点的数量为13对于控制点数据中的标志,python的fontTools库似乎只能读取G_ONCURVE标志位,即是否存在于曲线上。
首先查看控制点的坐标coordinates:
glyph.coordinatesGlyphCoordinates([(300, 728),(171, 729),(107, 615),(50, 519),(50, 195),(107, 99),(171, -14),(427, -14),(493, 99),(550, 195),(550, 519),(493, 615),(427, 729),(300, 658),(396, 658),(438, 555),(469, 483),(469, 233),(438, 159),(396, 57),(204, 57),(162, 159),(132, 233),(132, 483),(162, 555),(204, 658)])可以借助numpy计算出偏移后的实际坐标:
coordinates = np.array(glyph.coordinates).cumsum(axis=0)
print(coordinates.shape, coordinates.tolist())(26, 2) [[300, 728], [471, 1457], [578, 2072], [628, 2591], [678, 2786], [785, 2885], [956, 2871], [1383, 2857], [1876, 2956], [2426, 3151], [2976, 3670], [3469, 4285], [3896, 5014], [4196, 5672], [4592, 6330], [5030, 6885], [5499, 7368], [5968, 7601], [6406, 7760], [6802, 7817], [7006, 7874], [7168, 8033], [7300, 8266], [7432, 8749], [7594, 9304], [7798, 9962]]控制点是否存在于曲线上:
glyph.flagsbytearray(b'\x01\x00\x01\x00\x00\x01\x00\x00\x01\x00\x00\x01\x00\x01\x00\x01\x00\x00\x01\x00\x00\x01\x00\x00\x01\x00')可以用numpy横向拼接,方便查看:
data = np.c_[coordinates, glyph.flags].astype("int16")
print(data)[[ 300 728 1]
[ 471 1457 0]
[ 578 2072 1]
[ 628 2591 0]
[ 678 2786 0]
[ 785 2885 1]
[ 956 2871 0]
[1383 2857 0]
[1876 2956 1]
[2426 3151 0]
[2976 3670 0]
[3469 4285 1]
[3896 5014 0]
[4196 5672 1]
[4592 6330 0]
[5030 6885 1]
[5499 7368 0]
[5968 7601 0]
[6406 7760 1]
[6802 7817 0]
[7006 7874 0]
[7168 8033 1]
[7300 8266 0]
[7432 8749 0]
[7594 9304 1]
[7798 9962 0]]对于连续不在曲线上的点都会自动添加隐式的点。
如何将这些控制点数据用最简化的2进制的形式描述呢?
np.array(glyph.coordinates).astype("int16").tobytes()+glyph.flagsb',\x01\xd8\x02\xab\x00\xd9\x02k\x00g\x022\x00\x07\x022\x00\xc3\x00k\x00c\x00\xab\x00\xf2\xff\xab\x01\xf2\xff\xed\x01c\x00&\x02\xc3\x00&\x02\x07\x02\xed\x01g\x02\xab\x01\xd9\x02,\x01\x92\x02\x8c\x01\x92\x02\xb6\x01+\x02\xd5\x01\xe3\x01\xd5\x01\xe9\x00\xb6\x01\x9f\x00\x8c\x019\x00\xcc\x009\x00\xa2\x00\x9f\x00\x84\x00\xe9\x00\x84\x00\xe3\x01\xa2\x00+\x02\xcc\x00\x92\x02\x01\x00\x01\x00\x00\x01\x00\x00\x01\x00\x00\x01\x00\x01\x00\x01\x00\x00\x01\x00\x00\x01\x00\x00\x01\x00'
1位置索引(loca表)
前面在读取glyf表中的图元数据时就需要读取loca表的图元索引的偏移量。
位置索引表中保存了n+1个图元数据表的索引,其中的n是保存在最大需求表中的图元数量。最后一个额外的偏移量指向最后一个图元的偏移量和当前图元的偏移量间的差值得到的图元长度。
python中能够读取到:
loca = font["loca"]
loca.locationsarray('I', [0, 0, 24, 68, 168, 304, 364, 480, 612, 652, 824, 948, 1040, 1164, 1252, 1432, 1660, 1856, 1944, 2052, 2140,
......
97488, 97624, 97776, 98036, 98180, 98320, 98480, 98676, 98832, 99020, 99308])最大需求表(maxp表)
最大需求表的目的是告知字体栅格器(rasterizer)对内存的需求,以便 在出来字体前分配合适大小的内存。下面是maxp表的结构在c语言中的定义:
typedef struct
{
Fixed Version;//0x00010000 for version 1.0.
USHORT numGlypha; //Number of glyphs in the font .
USHORT maxPoints; //Max points in noncomposite glyph .
RSHORT maxContours; //Max contours in noncomposite glyph.
USHORT maxCompositePoints;//Max points in a composite glyph.
USHORT maxCompositeContours; //Max contours in a composite glyph.
USHORT maxZones;// 1 if not use the twilight zone [Z0],
//or 2 if so use Z0;2 in most cases.
USHORT max TwilightPoints ;/ Maximum points used in Z0.
USHORT maxStorage; //Number of storage area locations.
USHORT maxFunctionDefs; //Number of FDEFs.
USHORT maxStackElements; //Number of depth.
USHORT maxSizeOfInstructions; //Max byte count for glyph inst.
USHORT maxComponentElements; //Max number top components refernced.
USHORT maxComponentDepth; //Max levels of recursion.
}Table_maxp;numGlyphs字段保存了字体中图元的总数,这决定了到位置表的图元索引的数量,可以验证图元索引的有效性。maxPoints\maxCountors\maxCompositePoints maxCompositeContours这几个字段说明了图元定义的复杂度。
python中的读取一下:
maxp = font["maxp"]
maxp.numGlyphs, maxp.maxPoints, maxp.maxContours, maxp.maxCompositePoints, maxp.maxCompositeContours(603, 134, 11, 0, 0)命名表(name) 包含版权说明、字体名、字体族名、风格名等,直接通过python查看:
for n in font["name"].names:
print(repr(n), n)
print(n.platformID, n.nameID, n.string)
print("----------------")1 0 b'\n Created by font-carrier\n '
----------------
......
1 10 b'Generated by svg2ttf from Fontello project.'
----------------
1 11 b'http://fontello.com'
----------------
3 0 b'\x00\n\x00 \x00 \x00C\x00r\x00e\x00a\x00t\x00e\x00d\x00 \x00b\x00y\x00 \x00f\x00o\x00n\x00t\x00-\x00c\x00a\x00r\x00r\x00i\x00e\x00r\x00\n\x00 \x00 '
......截取了部分结果,可以看到该自定义字体通过fontello.com生成。
水平布局(hmtx)
Python查看字体的水平布局:
for code, width in hmtx.metrics.items():
print(code, width)glyph00000 (1136, 0)
x (100, 0)
uniec3e (600, 0)
...
unif82e (600, 0)
unie7c5 (1000, 0)
...
unif69c (1000, 0)二进制匹配解析轮廓图顺序随机的woff字体
有了前面的基础,现在对于乱序了轮廓图顺序的woff字体,已经变得非常简单。
我们使用上次下载的address.woff文件作为已知训练集,然后将shopNum.woff字体文件的轮廓图,进行一定的乱序处理,看看能否正确的提取出需要的文字。
首先使用FontCreator.exe打开shopNum.woff字体文件,然后修改轮廓图顺序。
最终在我一顿操作后,形成下面的顺序:

再将字体导出为random.woff。
那么我们能否通过address.woff文件和已知字符列表作为训练集,正确匹配出random.woff文件每个Unicode代码点对应的字符呢?
首先读取address.woff文件的每个图元数据转成二进制后和之前已经识别出来的字符列表建立映射关系:
from fontTools.ttLib import TTFont
import numpy as np
def get_glyphBytes(glyph):
coordinates = np.array(glyph.coordinates).astype("int16")
return coordinates.tobytes()+glyph.flags
font = TTFont("address.woff")
glyf = font["glyf"]
chars = ' `1234567890店中美家馆小车大市公酒行国品发电金心业商司超生装园场食有新限天面工服海华水房饰城乐汽香部利子老艺花专东肉菜学福饭人百餐茶务通味所山区门药银农龙停尚安广鑫一容动南具源兴鲜记时机烤文康信果阳理锅宝达地儿衣特产西批坊州牛佳化五米修爱北养卖建材三会鸡室红站德王光名丽油院堂烧江社合星货型村自科快便日民营和活童明器烟育宾精屋经居庄石顺林尔县手厅销用好客火雅盛体旅之鞋辣作粉包楼校鱼平彩上吧保永万物教吃设医正造丰健点汤网庆技斯洗料配汇木缘加麻联卫川泰色世方寓风幼羊烫来高厂兰阿贝皮全女拉成云维贸道术运都口博河瑞宏京际路祥青镇厨培力惠连马鸿钢训影甲助窗布富牌头四多妆吉苑沙恒隆春干饼氏里二管诚制售嘉长轩杂副清计黄讯太鸭号街交与叉附近层旁对巷栋环省桥湖段乡厦府铺内侧元购前幢滨处向座下澩凤港开关景泉塘放昌线湾政步宁解白田町溪十八古双胜本单同九迎第台玉锦底后七斜期武岭松角纪朝峰六振珠局岗洲横边济井办汉代临弄团外塔杨铁浦字年岛陵原梅进荣友虹央桂沿事津凯莲丁秀柳集紫旗张谷的是不了很还个也这我就在以可到错没去过感次要比觉看得说常真们但最喜哈么别位能较境非为欢然他挺着价那意种想出员两推做排实分间甜度起满给热完格荐喝等其再几只现朋候样直而买于般豆量选奶打每评少算又因情找些份置适什蛋师气你姐棒试总定啊足级整带虾如态且尝主话强当更板知己无酸让入啦式笑赞片酱差像提队走嫩才刚午接重串回晚微周值费性桌拍跟块调糕'
glyphBytes2char = {}
for code, char in zip(glyf.glyphOrder, chars):
glyph = glyf[code]
if not hasattr(glyph, 'coordinates'):
continue
glyphBytes2char[get_glyphBytes(glyph)] = char有了映射关系,我们再开始尝试匹配random.woff文件每个Unicode代码点对应的字符:
font = TTFont("random.woff")
glyf = font["glyf"]
code2char = {}
for code in glyf.glyphOrder:
glyph = glyf[code]
if not hasattr(glyph, 'coordinates'):
continue
glyphBytes = get_glyphBytes(glyph)
if glyphBytes not in glyphBytes2char:
print("不在资料库的代码点:", code)
continue
code2char[code] = glyphBytes2char[glyphBytes]
code2char结果:
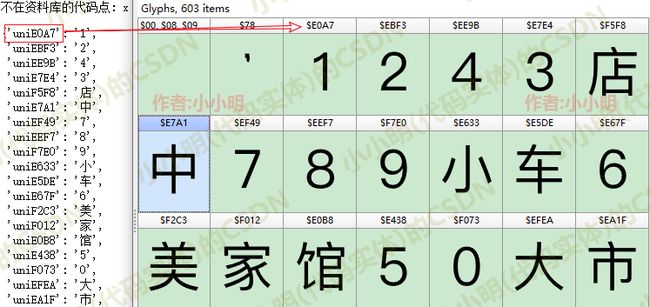
可以看到每一个代码点都一一精准的匹配出正确的结果。
可以将上述过程封装成类,方便以后随时调用使用:
from fontTools.ttLib import TTFont
import numpy as np
class FontMatch:
"""用于字体图元数据匹配的类"""
@staticmethod
def get_glyphBytes(glyph):
coordinates = np.array(glyph.coordinates).astype("int16")
return coordinates.tobytes() + glyph.flags
def __init__(self, sample_font="sample.woff", chars=None, dest_font=None):
"""
传入已知轮廓图顺序的字体文件和真实字符作为训练集,去匹配目标字体,后面能够得到该目标字体映射字符对应的真实字符
:param sample_font: 已知轮廓图顺序的字体文件
:param chars: 该字体文件每个轮廓图对应的真实字符
:param dest_font: 要进行匹配的目标字体,可以后面再调用 load_dest_font 传入
"""
sample_font = TTFont(sample_font)
glyf = sample_font["glyf"]
if chars is None:
chars = ' `1234567890店中美家馆小车大市公酒行国品发电金心业商司超生装园场食有新限天面工服海华水房饰城乐汽香部利子老艺花专东肉菜学福饭人百餐茶务通味所山区门药银农龙停尚安广鑫一容动南具源兴鲜记时机烤文康信果阳理锅宝达地儿衣特产西批坊州牛佳化五米修爱北养卖建材三会鸡室红站德王光名丽油院堂烧江社合星货型村自科快便日民营和活童明器烟育宾精屋经居庄石顺林尔县手厅销用好客火雅盛体旅之鞋辣作粉包楼校鱼平彩上吧保永万物教吃设医正造丰健点汤网庆技斯洗料配汇木缘加麻联卫川泰色世方寓风幼羊烫来高厂兰阿贝皮全女拉成云维贸道术运都口博河瑞宏京际路祥青镇厨培力惠连马鸿钢训影甲助窗布富牌头四多妆吉苑沙恒隆春干饼氏里二管诚制售嘉长轩杂副清计黄讯太鸭号街交与叉附近层旁对巷栋环省桥湖段乡厦府铺内侧元购前幢滨处向座下澩凤港开关景泉塘放昌线湾政步宁解白田町溪十八古双胜本单同九迎第台玉锦底后七斜期武岭松角纪朝峰六振珠局岗洲横边济井办汉代临弄团外塔杨铁浦字年岛陵原梅进荣友虹央桂沿事津凯莲丁秀柳集紫旗张谷的是不了很还个也这我就在以可到错没去过感次要比觉看得说常真们但最喜哈么别位能较境非为欢然他挺着价那意种想出员两推做排实分间甜度起满给热完格荐喝等其再几只现朋候样直而买于般豆量选奶打每评少算又因情找些份置适什蛋师气你姐棒试总定啊足级整带虾如态且尝主话强当更板知己无酸让入啦式笑赞片酱差像提队走嫩才刚午接重串回晚微周值费性桌拍跟块调糕'
glyphBytes2char = {}
for code, char in zip(glyf.glyphOrder, chars):
glyph = glyf[code]
if not hasattr(glyph, 'coordinates'):
continue
glyphBytes2char[FontMatch.get_glyphBytes(glyph)] = char
self.glyphBytes2char = glyphBytes2char
sample_font.close()
if dest_font is not None:
self.load_dest_font(dest_font)
def load_dest_font(self, dest_font):
"""传入要进行匹配的目标字体,之前已经传入的目标字体会被覆盖"""
font = TTFont(dest_font)
self.code2name = font.getBestCmap()
self.glyf = font["glyf"]
def getRealChar(self, char):
code = ord(char)
if code not in self.code2name:
return
name = self.code2name[code]
glyphBytes = FontMatch.get_glyphBytes(self.glyf[name])
return self.glyphBytes2char.get(glyphBytes)调用方式:下面的代码将前面已经下载的任意一个字体文件重命名为sample.woff作为训练集,random.woff是要处理的目标字体。对于任何给点的映射字符都可以匹配出正确结果:
from FontMatch import FontMatch
font = FontMatch(sample_font="sample.woff", dest_font="random.woff")
print(font.getRealChar("\uEE9B"))'4'对前面我们自行乱序后的自定义字体前面几个字符批量匹配测试一下:
real_map = {'\uE0A7': '1', '\uEBF3': '2', '\uEE9B': '4', '\uE7E4': '3', '\uF5F8': '店', '\uE7A1': '中', '\uEF49': '7', '\uEEF7': '8', '\uF7E0': '9', '\uE633': '小', '\uE5DE': '车', '\uE67F': '6', '\uF2C3': '美', '\uF012': '家', '\uE0B8': '馆', '\uE438': '5'}
for char, real in real_map.items():
r = font.getRealChar(char)
print("真实结果与匹配结果:", real, "|", r)真实结果与匹配结果: 1 | 1
真实结果与匹配结果: 2 | 2
真实结果与匹配结果: 4 | 4
真实结果与匹配结果: 3 | 3
真实结果与匹配结果: 店 | 店
真实结果与匹配结果: 中 | 中
真实结果与匹配结果: 7 | 7
真实结果与匹配结果: 8 | 8
真实结果与匹配结果: 9 | 9
真实结果与匹配结果: 小 | 小
真实结果与匹配结果: 车 | 车
真实结果与匹配结果: 6 | 6
真实结果与匹配结果: 美 | 美
真实结果与匹配结果: 家 | 家
真实结果与匹配结果: 馆 | 馆
真实结果与匹配结果: 5 | 5一样也是完全正确。
图像识别解析字形随机的woff字体
上述代码解决了轮廓图顺序随机的问题,但是假如字形也发生随机怎么破呢?例如用10套基础字体随机生成自定义字体。那么之前的获取到的图元数据就无法直接匹配。
此时我们需要使用机器学习或深度学习相关的算法,或者能够完成图元数据渲染字体图形的大佬可以直接使用逻辑算法完成。
自己尝试了一些分类模型发现效果并不比图像识别算法好,所以最终我们依然还是决定使用一开始采用的图像识别来解决这个问题,优点是通用性强,但缺点是准确率再也无法达到100%。
前面下载的字体文件定义最常用的601个字符,这里我们也只对这601个字符进行测试。
首先,创建文字识别类:
from ddddocr import DdddOcr, np
class OCR(DdddOcr):
def __init__(self):
super().__init__()
def ocr(self, image):
image = np.array(image).astype(np.float32)
image = np.expand_dims(image, axis=0) / 255.
image = (image - 0.5) / 0.5
ort_inputs = {'input1': np.array([image])}
ort_outs = self._DdddOcr__ort_session.run(None, ort_inputs)
result = []
last_item = 0
for item in ort_outs[0][0]:
if item == 0 or item == last_item:
continue
result.append(self._DdddOcr__charset[item])
last_item = item
return ''.join(result)
ocr = OCR()定义需要被测试的正确字符:
chars = '1234567890店中美家馆小车大市公酒行国品发电金心业商司超生装园场食有新限天面工服海华水房饰城乐汽香部利子老艺花专东肉菜学福饭人百餐茶务通味所山区门药银农龙停尚安广鑫一容动南具源兴鲜记时机烤文康信果阳理锅宝达地儿衣特产西批坊州牛佳化五米修爱北养卖建材三会鸡室红站德王光名丽油院堂烧江社合星货型村自科快便日民营和活童明器烟育宾精屋经居庄石顺林尔县手厅销用好客火雅盛体旅之鞋辣作粉包楼校鱼平彩上吧保永万物教吃设医正造丰健点汤网庆技斯洗料配汇木缘加麻联卫川泰色世方寓风幼羊烫来高厂兰阿贝皮全女拉成云维贸道术运都口博河瑞宏京际路祥青镇厨培力惠连马鸿钢训影甲助窗布富牌头四多妆吉苑沙恒隆春干饼氏里二管诚制售嘉长轩杂副清计黄讯太鸭号街交与叉附近层旁对巷栋环省桥湖段乡厦府铺内侧元购前幢滨处向座下澩凤港开关景泉塘放昌线湾政步宁解白田町溪十八古双胜本单同九迎第台玉锦底后七斜期武岭松角纪朝峰六振珠局岗洲横边济井办汉代临弄团外塔杨铁浦字年岛陵原梅进荣友虹央桂沿事津凯莲丁秀柳集紫旗张谷的是不了很还个也这我就在以可到错没去过感次要比觉看得说常真们但最喜哈么别位能较境非为欢然他挺着价那意种想出员两推做排实分间甜度起满给热完格荐喝等其再几只现朋候样直而买于般豆量选奶打每评少算又因情找些份置适什蛋师气你姐棒试总定啊足级整带虾如态且尝主话强当更板知己无酸让入啦式笑赞片酱差像提队走嫩才刚午接重串回晚微周值费性桌拍跟块调糕'先对系统自带的微软雅黑字体进行测试:
from PIL import ImageFont, Image, ImageDraw
size = 64
font = ImageFont.truetype("msyh.ttc", size-24)
error = 0
for char in chars:
im = Image.new(mode='L', size=(size, size), color=255)
draw = ImageDraw.Draw(im=im)
w, h = draw.textsize(char, font)
o1, o2 = font.getoffset(char)
fontx, fonty = (size-w-o1)/2, (size-h-o2)/2
draw.text(xy=(fontx, fonty), text=char, fill=0, font=font)
result = ocr.ocr(im)[0]
if result != char:
print("正确结果:", char, ",识别结果:", result)
error += 1
print("识别错误的字符数量:", error)正确结果: 二 ,识别结果: 一
正确结果: 澩 ,识别结果: 檗
正确结果: 昌 ,识别结果: 目
正确结果: 町 ,识别结果: 盯
正确结果: 丁 ,识别结果: j
正确结果: 入 ,识别结果: 人
识别错误的字符数量: 6可以看到对该字体601字符的识别只存在6个错误,其他都正确。
再对之前下载的自定义字体进行测试:
from fontTools.ttLib import TTFont
font = TTFont("shopNum.woff")
name2char = dict(zip(font.getGlyphOrder()[2:], chars))
size = 64
imageFont = ImageFont.truetype("shopNum.woff", size-24)
error = 0
for code, name in font.getBestCmap().items():
if name not in name2char:
continue
char = chr(code)
real_char = name2char[name]
im = Image.new(mode='L', size=(size, size), color=255)
draw = ImageDraw.Draw(im=im)
w, h = draw.textsize(char, imageFont)
o1, o2 = imageFont.getoffset(char)
fontx, fonty = (size-w-o1)/2, (size-h-o2)/2
draw.text(xy=(fontx, fonty), text=char, fill=0, font=imageFont)
result = ocr.ocr(im)[0]
if result != real_char:
print("正确结果:", real_char, "识别结果:", result)
error += 1
print("识别错误的字符数量:", error)正确结果: 町 识别结果: 盯
正确结果: 二 识别结果: 一
正确结果: 澩 识别结果: 嗅
识别错误的字符数量: 3可以看到对该字体601字符的识别只存在3个错误,其他都正确。
那么对于任何一个未知的自定义字体,如何通过图像识别技术知道真实字符是什么呢?
我们改造一下前面的ocr类,封装一下:
from ddddocr import DdddOcr, np
from PIL import ImageFont, Image, ImageDraw
class FontOCR(DdddOcr):
def __init__(self, font_name, font_size=40):
super().__init__()
self.font = ImageFont.truetype(font_name, font_size)
self.cache = {}
self.im_cache = {}
def ocr(self, image):
image = np.array(image).astype(np.float32)
image = np.expand_dims(image, axis=0) / 255.
image = (image - 0.5) / 0.5
ort_inputs = {'input1': np.array([image])}
ort_outs = self._DdddOcr__ort_session.run(None, ort_inputs)
for item in ort_outs[0][0]:
if item == 0:
continue
return self._DdddOcr__charset[item]
def ocrFontChar(self, char):
if char in self.cache:
return self.cache[char]
im = self.getCharImage(char)
return self.cache.setdefault(char, self.ocr(im))
def getCharImage(self, char):
if char in self.im_cache:
return self.im_cache[char]
im = Image.new(mode='L', size=(64, 64), color=255)
draw = ImageDraw.Draw(im=im)
w, h = draw.textsize(char, self.font)
o1, o2 = self.font.getoffset(char)
fontx, fonty = (64-w-o1)/2, (64-h-o2)/2
draw.text(xy=(fontx, fonty), text=char, fill=0, font=self.font)
return self.im_cache.setdefault(char, im)调用方式:
fontocr = FontOCR("shopNum.woff")
fontocr.getRealChar("\uF7F2")'让'于是可以通过以下代码可以对自定义字体的全部unicode代码点识别一遍:
from fontTools.ttLib import TTFont
font_name = "address.woff"
fontocr = FontOCR(font_name)
font = TTFont(font_name)
for name, real_char in zip(font.getGlyphOrder(), chars):
if not name.startswith("uni"):
continue
char = f"\\u{name[3:]}".encode().decode("unicode_escape")
ocr_char = fontocr.ocrFontChar(char)
print(name, real_char, ocr_char)uniec3e 1 1
unif3fc 2 2
uniea1f 3 3
unie7f7 4 4
unie258 5 5
unif5aa 6 6
unif48c 7 7
unif088 8 8
unif588 9 9
unif82e 0 0
unie7c5 店 店
unie137 中 中
unie2cb 美 美
unif767 家 家
...
可以看到这些数据都被正确的解析出来,至此我们就完成了对任意自定义字体的智能解析。
总结
今天,我首先演示了如何生成自定义字体,并对字体的格式结构进行了较为详细的讲解,顺便演示如何通过python的fontools库获取相应的字体数据。
在上一篇文章中,我们通过二级缓存解决了cssURL和fontURL随机以及Unicode代码点顺序点随机的问题,本文进一步考虑针对自定义字体文件内部,轮廓图甚至基础字形也随机怎么处理。
本文针对轮廓图顺序随机,开发了FontMatch,传入已知字体的轮廓图顺序,能处理任何针对该字体进行轮廓图顺序随机的匹配,准确率能达到100%。
但针对字形也可能随机的情况,中间个人进行了很多基础研究,写了很多算法,但最终都还不如图像识别的效果更好。所以最终我封装了一个基于图像识别的OCR处理类,能够针对任何自定义字体传入输入字符识别出相应的结果字符。目前测试的600个高频字符,准确率达到98%以上,针对未来的不确定性,牺牲这一点准确率个人感觉也很值。
版权声明:本文为CSDN博主「小小明-代码实体」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/as604049322/article/details/119415686
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:
补充篇:盘点6种使用Python批量合并同一文件夹内所有子文件夹下的Excel文件内所有Sheet数据
盘点4种使用Python批量合并同一文件夹内所有子文件夹下的Excel文件内所有Sheet数据
手把手教你使用Python网络爬虫实现邮件定时发送(附源码)
番外篇:分享一道用Python基础+蒙特卡洛算法实现排列组合的题目(附源码)

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~