第 十九 章 Python 中的并发模型
并发是同时处理很多事情。
并行是同时执行很多事情。
虽然概念不一样,但是是相关的。
一是关于程序的结构,一是关于程序的执行。
并发提供了一种构建解决方案的方法,以解决一个可能(但不一定)可并行的问题
--------Rob Pike, Co-inventor of the Go language
本章是关于如何让 Python “同时处理很多事情”。这可能涉及并发或并行编程——即使是热衷于行话的学者也不知道如何使用这些术语。我将采用上面引用的 Rob Pike 的非正式定义,但请注意,我找到了声称与并行计算有关但却是关于并发的论文和书籍。
在 Pike 看来,并行是并发的一种特例。所有并行系统都是并发的,但并非所有并发系统都是并行的。在 2000 年代初期,我们使用了在 GNU Linux 上同时处理 100 个进程的单核CPU的机器。具有 4 个 CPU 内核的现代笔记本电脑在正常、随意使用的情况下,在任何时间通常会运行 200 多个进程。要并行执行 200 个任务,您需要 200 个内核。因此,在实践中,大多数计算是并发的而不是并行的。操作系统管理数百个进程,确保每个进程都有机会获得CPU的时间,即使 CPU 本身不能同时处理4件以上的事情。
本章假设读者没有并发或并行编程的经验知识。在简单的概念介绍之后,我们将学习简单的例子来介绍和比较 Python 并发编程的核心包:threading、multiprocessing和 asyncio。
本章的最后 30% 是对第三方工具、库、应用服务器和分布式任务队列的高级概述——所有这些都可以增强 Python 应用程序的性能和可扩展性。这些都是重要的主题,但超出了一本专注于 Python 语言核心特性的书的范围。尽管如此,我觉得在 Fluent Python 的第二版中介绍这些主题很重要,因为 Python 对并发和并行计算的适用性不仅限于标准库提供的内容。这就是为什么 YouTube、DropBox、Instagram、Reddit 和其他公司在开始使用 Python 作为他们的主要语言时能够实现 大规模Web应用 的原因——尽管他们一直声称“Python 无法扩展”。
本章的新内容
本章是 Fluent Python,第二版中的新增内容。 “并发 Hello World”中的spinner示例之前在有关 asyncio 的章节中。在这里,它们得到了改进,并首次展示了 Python 的三种并发方法:线程、进程和原生协程。
除了最初出现在关于 concurrent.futures 和 asyncio 的章节中的几段之外,剩下的内容是全新的。
“Python in the multi-core world” 与本书的其余部分不同:没有代码示例。目标是提及您可能想要研究的重要工具,以实现超出 Python 标准库所能实现的高性能并发性和并行性。
伟大的架构图The Big Picture
有很多因素使并发编程变得困难,但我想谈谈最基本的因素:启动线程或进程很容易,但如何跟踪它们?
当您调用函数时,调用代码将被阻塞,直到函数返回。所以你知道函数什么时候完成,你可以很容易地得到它返回的值。如果函数抛出异常,调用代码可以用 try/except 包围相应代码以捕获错误。
当您启动线程或进程时,这些熟悉的选项将不可用:您不会自动知道它何时完成,并且返回的结果或错误信息需要先建立一些通信通道才能获取,例如消息队列。
此外,启动一个线程或进程的代价并不低,因此您不想只是为了执行单个计算并退出而启用一个进程/线程。通常,您希望通过使每个线程或进程成为进入循环并等待输入工作的“工人”来分摊启动成本。这进一步使沟通复杂化并引入了更多问题。当你不再需要worker时,你如何让worker退出?以及如何让它在不中断工作的情况下退出,留下只处理部分的数据和未发布的资源——比如打开的文件?同样,通常的答案涉及消息和队列。
启动协程代价很低。如果你使用 await 关键字启动协程,很容易得到它返回的值,可以安全地取消它,并且你有一个明确的途径来捕获异常。但是协程通常由异步框架启动,这会使它们像线程或进程一样难以监控。
最后,我们将看到,Python 协程和线程不适合 CPU 密集型任务。
这就是并发编程需要学习新概念和编码模式的原因。让我们首先确保我们在一些核心概念上保持一致。
一部分行话
以下是我将在本章的其余部分和接下来的两章中使用的一些术语。
并发
处理多个待处理任务的能力,一次或并行(如果可能)获得进展,以便它们中的每一个最终都会执行成功或失败。如果单核 CPU 运行 OS 调度器来交错执行挂起的任务,则它具有并发能力。也称为多任务处理。
并行性
同时执行多个计算的能力。这需要一个多核 CPU、多个 CPU、一个 GPU 或集群中的多台计算机中的一种。
执行单元
并发执行代码的对象的总称,每个对象都有独立的状态和调用堆栈。 Python 原生支持三种执行单元:进程、线程和协程。
进程
运行中的计算机程序实例,使用内存和 CPU 时间片段。现代桌面操作系统通常同时管理数百个进程,每个进程都隔离在自己的私有内存空间中。进程通过管道、套接字或内存映射文件进行通信——所有这些都只能携带原始字节。Python 对象必须序列化(转换)为原始字节才能从一个进程传递到另一个进程。这代价高昂,而且并非所有 Python 对象都是可序列化的。一个进程可以产生sub-processes,每个sub-process称为一个子进程。这些子进程也彼此隔离并与父进程隔离。进程允许抢占式多任务处理:也就是挂起——每个正在运行的进程周期性地允许其他进程运行。这意味着从理论上冻结的进程不能冻结整个系统。
线程
一个进程中的执行单元。当一个进程启动时,它使用一个线程:也就是主线程。一个进程可以通过调用操作系统 API 来创建更多的线程进行并发操作。进程内的线程共享相同的内存空间,其中包含活动的 Python 对象。这允许线程之间轻松共享数据,但当多个线程同时更新同一个对象时,也会导致数据损坏。与进程一样,线程也可以在操作系统调度程序的监督下启用抢占式多任务处理。线程消耗的资源少于执行相同工作的进程。
协程
可以暂停自身并稍后恢复的功能。在 Python 中,经典协程是由生成器函数构建的,而原生协程是使用 async def 定义的。“经典协程”介绍了这个概念,第 21 章介绍了原生协程的使用。 Python 协程通常在事件循环的监督下在单个线程中运行,也在同一线程中。异步编程框架(例如 asyncio、Curio 或 Trio)为基于协程的非阻塞 I/O 提供事件循环和支持库。协程支持协作多任务处理:每个协程必须使用 yield 或 await 关键字显式放弃控制,以便另一个协程可以并发(但不能并行)进行。这意味着协程中的任何阻塞代码都会阻塞事件循环和所有其他协程的执行——与进程和线程支持的抢占式多任务处理形成相反的对比。另一方面,每个协程比执行相同工作的线程或进程消耗更少的资源。
队列
一种允许我们放入和获取元素的数据结构,通常按 FIFO 顺序:先进先出。队列允许单独的执行单元交换应用程序数据和控制消息,例如错误代码和终止信号。队列的实现因底层并发模型不同而变化:Python 标准库中的 queue 包提供了队列类来支持线程,而 multiprocessing 和 asyncio 包实现了自己的队列类。queue 和 asyncio 包还包括非 FIFO 的队列:LifoQueue 和 PriorityQueue。
锁
执行单元用于同步操作并避免损坏数据的对象。在更新共享数据结构时,正在运行的代码应该持有与之相关联的锁。这向程序的其他部分发出信号,在访问相同的数据结构之前等待锁被释放。最简单的锁类型也称为互斥锁(用于互斥)。锁的实现取决于底层并发模型。
竞争
对有限资源的竞争。当多个执行单元尝试访问共享资源(例如锁或存储)时,就会发生资源竞争。当计算密集型进程或线程必须等待操作系统调度程序为它们分配 CPU 时间时,还会发生 CPU 争用。
现在让我们使用一些术语来理解 Python 对并发的支持。
进程、线程和 Python 臭名昭著的 GIL
以下是我们刚刚看到的概念如何应用于 Python 编程的十点。
- Python 解释器的每个实例都是一个进程。您可以使用 multiprocessing 或 concurrent.futures 库启动其他 Python 进程。Python 的sub-processing库旨在启动进程以运行外部程序,无需关注编写外部程序的语言。
- Python 解释器使用单线程运行用户程序和内存垃圾收集器。您可以使用 threading 或 concurrent.futures 库启动其他 Python 线程。
- 对对象引用计数和其他内部解释器状态的访问由锁控制,全局解释器锁 (GIL)。任何时候只有一个 Python 线程可以持有 GIL。这意味着在任何时候都只有一个线程可以执行 Python 代码,和CPU 内核的数量无关。
- 为了防止 Python 线程无限期地持有 GIL,Python 的字节码解释器默认每 5 毫秒暂停当前 Python 线程 ,从而释放 GIL。然后线程可以尝试重新获取 GIL,但如果有其他线程在等待它,操作系统调度程序可能会选择其中之一继续。
- 当我们编写 Python 代码时,我们无法控制 GIL。但是用 C 编写的内置函数或扩展(或任何在 Python/C API 级别接口的语言)可以在运行耗时任务时释放 GIL。
- 每个调用syscall 的 Python 标准库函数都会释放 GIL。这包括执行磁盘 I/O、网络 I/O 和 time.sleep() 的所有函数。NumPy/SciPy 库中的许多 CPU 密集型函数以及来自 zlib 和 bz2 模块的压缩/解压缩函数也都会释放 GIL。
- 在 Python/C API 级别集成的扩展也可以启动不受 GIL 影响的其他非 Python 线程。这样的GIL-free线程一般不能改变Python对象,但它们可以对支持 buffer protocol的内存底层对象进行读写,例如bytearray、array.array和NumPy数组。
- GIL 对使用 Python 线程进行网络编程的影响相对较小,因为 I/O 函数会释放 GIL,并且与读取和写入内存相比,对网络的读取或写入总是意味着高延迟。因此,无论如何,每个单独的线程都会花费大量时间等待,因此它们的执行可以交错执行,而不会对整体吞吐量产生重大影响。这就是为什么 David Beazley 说:“Python 线程擅长无所事事。”
- 对 GIL 的争用会降低计算密集型 Python 线程的速度。对于此类任务,顺序的单线程代码更简单、更快。
- 要在多个内核上运行 CPU 密集型 Python 代码,您必须使用多个 Python 进程。
这是threading模块文档中的一个很好的总结:
CPython 实现细节:在 CPython 中,由于全局解释器锁,一次只有一个线程可以执行 Python 代码(即使某些面向性能的库可能会克服这一限制)。如果你想让你的应用更好地利用多核机器的计算资源,建议你使用 multiprocessing 或 concurrent.futures.ProcessPoolExecutor。但是,如果您想同时运行多个 I/O 密集型任务,线程仍然是一个合适的模型。
上一段以“CPython 实现细节”开头,因为 GIL 不是 Python 语言定义的一部分。Jython 和 IronPython 实现都没有 GIL。不幸的是,两者都落后了——仍处于 Python 2.7的阶段。高性能 PyPy 解释器在其 2.7 和 3.7 版本中也有一个 GIL——最新版本截至 2021 年 6 月。
Note:
本节没有提到协程,因为默认情况下,它们之间共享同一个 Python 线程,并且具有异步框架提供的监督事件循环,因此 GIL 不会影响协程。在一个异步程序中可以使用多个线程,但最佳实践是一个线程运行事件循环和所有协程,而其他线程可以执行特定任务。这将在“将任务委派给执行者”中解释。
现在我们了解了足够多的概念。让我们看一些代码。
并发的 Hello World
在讨论线程以及如何避免 GIL的影响 时,Python 贡献者 Michele Simionato 发布了一个类似于并发“Hello World”的示例:展示 Python 如何“一边走路一边嚼口香糖”的最简单程序。
Simionato 的程序使用multiprocessing,但我对其进行了修改以引入threading和asyncio。让我们从threading版本开始,如果您研究过 Java 或 C 中的线程,它可能看起来很熟悉。
使用threads的Spinner
下面几个例子的想法很简单:启动一个函数,在终端中动画字符的同时阻塞 3 秒,让用户知道程序正在“思考”而不是停止。
该脚本制作了一个动画spinner,在同一屏幕位置切换显示字符串“\|/-”中的每个字符。当慢计算完成时,带有spinner的那一行被清除并显示结果:answer:42。
图 19-1 显示了旋转示例的两个版本的输出:首先使用线程,然后使用协程。如果您没有电脑,请想象最后一行中的 \ 正在旋转。
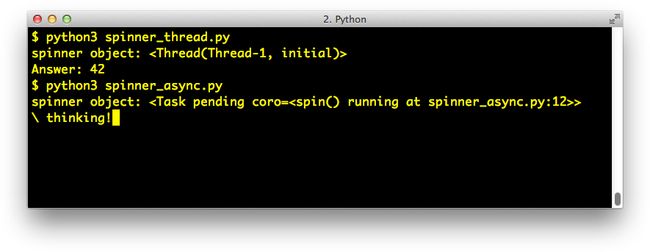
Figure 19-1. The scripts spinner_thread.py and spinner_async.py produce similar output: the repr of a spinner object and the text “Answer: 42”. In the screenshot, spinner_async.py is still running, and the animated message “/ thinking!” is shown; that line will be replaced by “Answer: 42” after 3 seconds.
让我们先看一下 spinner_thread.py 脚本。示例 19-1 列出了脚本中的前两个函数,示例 19-2 显示了其余部分。
例 19-1。 spinner_thread.py:spinner和slow函数。
import itertools
import time
from threading import Thread, Event
def spin(msg: str, done: Event) -> None: 1
for char in itertools.cycle(r'\|/-'): 2
status = f'\r{char} {msg}' 3
print(status, end='', flush=True)
if done.wait(.1): 4
break 5
blanks = ' ' * len(status)
print(f'\r{blanks}\r', end='') 6
def slow() -> int:
time.sleep(3) 7
return 42- 此函数将在单独的线程中运行。 done 参数是 threading.Event 的一个实例,一个用于同步线程的简单对象。
- 这是一个无限循环,因为 itertools.cycle 一次产生一个字符,无限循环遍历字符串。
- 文本模式动画的技巧:将光标移回带有 ASCII 控制字符 ('\r') 的行的开头。
- 当事件被另一个线程设置时,Event.wait(timeout=None) 方法返回 True;如果timeout超时后,则返回 False。.1s 超时将动画的“帧速率”设置为 10FPS。如果您希望spinner运行得更快,请使用较小的超时时间。
- 退出无限循环。
- 通过用空格覆盖并将光标移回开头来清除状态行。
- slow() 将被主线程调用。想象一下,假如是一个通过网络进行的缓慢 API 调用。调用 sleep 会阻塞主线程,但 GIL 会被释放,以便spinner线程可以向前执行。
TIP
这个例子的第一个重点是 time.sleep() 阻塞调用线程但释放了 GIL,允许运行其他 Python 线程。
spin和slow函数将同时执行。主线程——程序启动时的唯一线程——将启动一个新线程运行spin,然后调用slow。按照设计,Python 中没有用于终止线程的 API。您必须向其发送消息才能关闭线程。
threading.Event 类是 Python 最简单的协调线程的信号机制。Event实例有一个内部布尔标志,初始化为False.调用 Event.set() 将标志设置为 True。虽然该标志为 false,但如果一个线程调用 Event.wait(),它将被阻塞,直到另一个线程调用 Event.set(),此时 Event.wait() 返回 True。
例 19-2 中列出的 supervisor函数使用一个Event来通知spinner函数退出。
例 19-2。 spinner_thread.py:supervisor和main函数。
def supervisor() -> int: 1
done = Event() 2
spinner = Thread(target=spin, args=('thinking!', done)) 3
print(f'spinner object: {spinner}') 4
spinner.start() 5
result = slow() 6
done.set() 7
spinner.join() 8
return result
def main() -> None:
result = supervisor() 9
print(f'Answer: {result}')
if __name__ == '__main__':
main()supervisor返回slow的结果。- threading.Event 实例是协调主线程和spinner线程活动的关键,如下所述。
- 要创建新线程,需要提供一个函数作为关键字参数target,并将位置参数args元组作为参数提供给target。
- 打印spinner对象。输出是
-
启动
spinner线程. -
调用slow,阻塞主线程。同时,辅助线程正在运行spinner动画。
-
将Event标志设置为 True;这将终止spinner函数内的 for 循环。
-
等待直到spinner线程完成。
-
运行
supervisor函数。我编写了单独的 main 和 supervisor 函数,以使这个示例看起来更像示例 19-4 中的 asyncio 版本。
当主线程设置Done Event时,spinner线程最终会注意到并干净地退出。
现在让我们看一个使用 multiprocessing 包的相似示例。
多进程版本的Spinner
multiprocessing 包支持在单独的 Python 进程而不是线程中并发执行任务。当您创建 multiprocessing.Process 实例时,一个全新的 Python 解释器会在后台作为子进程启动。由于每个 Python 进程都有自己的 GIL,这允许您的程序使用所有可用的 CPU 内核——但这最终取决于操作系统调度程序。我们将在“A Homegrown Process Pool”中看到实际效果,但对于这个简单的程序来说,这并没有真正的区别。
本节的重点是介绍multiprocessing并展示其 API 模拟threading API,从而可以轻松地将简单程序从线程转换为进程,如 spinner_proc.py(示例 19-3)所示。
例 19-3。 spinner_proc.py:仅显示更改的部分。其他一切都与 spinner_thread.py 相同。
import itertools
import time
from multiprocessing import Process, Event 1
from multiprocessing import synchronize 2
def spin(msg: str, done: synchronize.Event) -> None: 3
# [snip] the rest of spin and slow functions are unchanged from spinner_thread.py
def supervisor() -> int:
done = Event()
spinner = Process(target=spin, 4
args=('thinking!', done))
print(f'spinner object: {spinner}') 5
spinner.start()
result = slow()
done.set()
spinner.join()
return result
# [snip] main function is unchanged as well- 基本的 multiprocessing API 模仿了 threading API,但是 type hints 和 mypy 暴露了二者的区别:multiprocessing.Event 是一个函数(而 threading.Event 是一个类),它返回一个 synchronized.Event 实例......
- ...这个机制强制我们导入 multiprocessing.synchronize ...
- ...编写类型提示
- Process 类的基本用法类似于 Thread。
- spinner 对象显示为
,其中 14868 是运行 spinner_proc.py 的 Python 实例的进程 ID。
线程和多进程的基本 API 是相似的,但它们的实现却大不相同,多进程有一个更大的 API 来处理多进程编程增加的复杂性。例如,从线程转换为进程时的一个挑战是如何在被操作系统隔离且无法共享 Python 对象的进程之间进行通信。这意味着跨越进程边界的对象必须被序列化和反序列化,这会产生开销。在示例 19-3 中,唯一跨越进程边界的数据是Event状态,它是在multiprocessing模块底层的 C 代码中使用低级操作系统信号量实现的。
TIP:
从 Python 3.8 开始,标准库中有一个 multiprocessing.shared_memory 包,但它不支持用户定义类的实例。除了原始字节之外,该包还允许进程共享一个 ShareableList,这是一种可变序列类型,可以保存固定数量的 int、float、bool、None 类型的项,和 str 和bytes一样,每个项最大为 10MB 。有关更多信息,请参阅 ShareableList 文档。
NOTE:
信号量是可用于实现其他同步机制的基本构建块。Python 提供了不同的信号量类,用于线程、进程和协程。我们将在“使用 asyncio.as_completed 和线程”(第 21 章)中看到 asyncio.Semaphore。
现在让我们看看如何使用协程来实现和线程或进程相同的行为。
协程版本的Spinner
NOTE:
第 21 章完全致力于使用协程进行异步编程。这只是将这种方法与线程和进程并发模型进行对比的高级介绍。因此,我们将忽略许多细节。
操作系统调度程序的工作是分配 CPU 时间来驱动线程和进程。相比之下,协程由应用程序级事件循环驱动,该循环管理待处理的协程队列,逐个驱动它们,监视由协程发起的 I/O 操作触发的事件,并在每个事件发生时将控制权交还给相应的协程。事件循环和标准库协程以及用户协程都在一个线程中执行。因此,在协程中花费的任何时间都会减慢事件循环以及所有其他协程的速度。
如果我们从main函数开始,然后研究supervisor,那么spinner程序的协程版本更容易理解。这就是示例 19-4 所展示的内容。
例 19-4。 spinner_async.py:main函数和supervisor协程
def main() -> None: 1
result = asyncio.run(supervisor()) 2
print(f'Answer: {result}')
async def supervisor() -> int: 3
spinner = asyncio.create_task(spin('thinking!')) 4
print(f'spinner object: {spinner}') 5
result = await slow() 6
spinner.cancel() 7
return result
if __name__ == '__main__':
main()- main 是这个程序中定义的唯一一个常规函数——其他的都是协程。
- asyncio.run 函数启动事件循环以驱动最终将其他协程设置为运动的协程。main函数将保持阻塞状态,直到supervisor返回。 supervisor 的返回值将是 asyncio.run 的返回值。
- 原生协程用 async def 来定义。
- asyncio.create_task 调度spin的最终执行,并立即返回 asyncio.Task 的一个实例。
- Spinner 对象的 repr 看起来像
> - await 关键字调用slow方法并阻塞supervisor,直到slow返回。slow的返回值将赋值给result。
- Task.cancel 方法在spin协程中抛出 CancelledError 异常,我们将在示例 19-5 中看到。
例 19-4 演示了运行协程的三种主要方式:
asyncio.run(coro())
从常规函数调用以驱动协程对象,该对象通常是程序中所有异步代码的入口点,例如本例中的supervisor。调用随后阻塞主线程,直到 coro 的主体返回。 run() 调用的返回值是 coro 的主体的返回值。
asyncio.create_task(coro())
从协程调用以安排另一个协程最终执行。此调用不会挂起当前协程。它返回一个 Task 实例,Task实例包装了协程对象并提供控制和查询其状态的方法。
await coro()
从协程调用以将控制转移到由 coro() 返回的协程对象。这会暂停当前的协程,直到 coro 的主体返回。 await 表达式的值是 coro 函数体的返回值。
Note:
请记住:以 coro() 调用协程会立即返回一个协程对象,但不会运行 coro 的函数体。驱动协程的主体是事件循环的工作。
现在让我们研究示例 19-5 中的spin和slow协程
例 19-5。 spinner_async.py:spin和slow协程
import asyncio
import itertools
async def spin(msg: str) -> None: 1
for char in itertools.cycle(r'\|/-'):
status = f'\r{char} {msg}'
print(status, flush=True, end='')
try:
await asyncio.sleep(.1) 2
except asyncio.CancelledError: 3
break
blanks = ' ' * len(status)
print(f'\r{blanks}\r', end='')
async def slow() -> int:
await asyncio.sleep(3) 4
return 42- 我们不需要用于在 spinner_thread.py(示例 19-1)中表示 slow 已完成其工作的 Event 参数。
- 使用 await asyncio.sleep(.1) 而不是 time.sleep(.1),在不阻塞其他协程的情况下暂停。请参阅此示例后的说明。
- 在控制此协程的Task上调用cancel方法时抛出asyncio.CancelledError异常。是时候退出循环了。
- slow协程也使用 await asyncio.sleep 而不是 time.sleep。
实验:拆开并了解spinner的细节
这是我推荐的一个实验来了解 spinner_async.py 的工作原理。导入 time 模块,然后转到slow协程并将 await asyncio.sleep(3) 行替换为 time.sleep(3) ,如下所示:
例 19-6。 spinner_async.py: 用 time.sleep (3) 替换 await asyncio.sleep (3)
async def slow() -> int:
time.sleep(3)
return 42观察程序的行为比阅读行为会让人记忆更深刻。加油,我等着。
当您运行实验时,您会看到以下内容:
- spinner对象将被打印,类似于:
> - 旋转器永远不会出现。程序挂起 3 秒钟。
- 最后显示answer:42,程序结束。
例 19-7。 spinner_async_experiment.py:supervisor和slow协程
async def slow() -> int:
time.sleep(3) 4
return 42
async def supervisor() -> int:
spinner = asyncio.create_task(spin('thinking!')) 1
print(f'spinner object: {spinner}') 2
result = await slow() 3
spinner.cancel() 5
return result- 创建 Spinner 任务,以最终驱动 spin 的执行
- 终端显示状态为“pending”。
- await 表达式将控制转移到slow协程。
- time.sleep(3) 阻塞 3 秒;程序中不会发生任何其他事情,因为主线程被阻塞了——而且它是唯一的线程。操作系统将继续进行其他活动。 3 秒后,sleep解除阻塞,随后slow返回。
- 在slow返回后,spinner任务立即被取消。控制流从未到达spin协程的主体。
spinner_async_experiment.py 说明了一个重要的教训:
WARNING
除非您想暂停整个程序,否则切勿在 asyncio 协程中使用 time.sleep(...)。如果协程需要花一些时间什么都不做,应该这样写await asyncio.sleep(DELAY)。这将控制权交还给 asyncio 事件循环,它可以驱动其他挂起的协程。
GREENLET 和 GEVENT
当我们讨论与协程的并发时,重要的是要提到已经存在多年并被大规模使用的 greenlet包。该包通过轻量级协程(名为 greenlets)支持协作多任务处理,不需要任何特殊语法,例如 yield 或 await,因此更容易集成到现有的顺序代码库中。SQL Alchemy 1.4 ORM 在内部使用 greenlets 来实现其与 asyncio 兼容的新异步 API。
gevent网络库对Python 的标准库的socket套接字模块打了猴子补丁,通过用greenlets 替换其部分代码使其非阻塞。在很大程度上,gevent 对周围的代码是透明的,因此更容易适应顺序应用程序和库(例如数据库驱动程序)来执行并发网络 I/O。许多开源项目都使用 gevent,包括广泛部署的 Gunicorn——在“WSGI 应用服务器”中提到。
Supervisors Side-by-side
spinner_thread.py 和 spinner_async.py 的行数几乎相同。supervisor功能是这些示例的核心。现在对它们进行详细的比较。示例 19-8 仅列出示例 19-2 中的supervisor。
例 19-8。 spinner_thread.py:线程实现的supervisor函数
def supervisor() -> int:
done = Event()
spinner = Thread(target=spin,
args=('thinking!', done))
print('spinner object:', spinner)
spinner.start()
result = slow()
done.set()
spinner.join()
return result为了进行比较,示例 19-9 显示了示例 19-4 中的supervisor协程。
例 19-9。 spinner_async.py:异步supervisor协程
async def supervisor() -> int:
spinner = asyncio.create_task(spin('thinking!'))
print('spinner object:', spinner)
result = await slow()
spinner.cancel()
return result以下是两个supervisor实现之间要注意的差异和相似之处的摘要:
- asyncio.Task 大致相当于 threading.Thread。
- 一个Task驱动一个协程对象,一个Coroutine调用一个可调用对象。
- 协程使用 await 关键字显式获取线程控制权。
- 不需要自己实例化 Task 对象,而是通过将协程传递给 asyncio.create_task(...) 来获取Task。
- 当 asyncio.create_task(…) 返回一个 Task 对象时,它已经被调度运行,但是对于thread必须通过调用它的 start 方法明确告诉 Thread 实例运行。
- 在线程管理器中,slow 是一个普通函数,由主线程直接调用。在异步supervisor中,slow是await驱动的协程。
- 没有从外部终止线程的 API;相反,你必须发送一个信号——比如设置 done 的Event对象。对于Task,存在Task.cancel() 实例方法,它在协程主体当前挂起的 await 表达式处抛出 CancelledError异常。
- supervisor协程必须在main函数中使用 asyncio.run 启动。
这种比较应该可以帮助您了解如何使用 asyncio 来编排并发任务,而不是使用您可能更熟悉的 Threading 模块来完成它。
关于线程与协程的最后一点:如果您使用线程进行过任何复杂的编程,您就会知道对程序进行推理是多么具有挑战性,因为调度程序可以随时中断线程。您必须记住持有锁以保护程序的关键部分,以避免在多步操作中间被中断——这可能会使数据处于无效状态。
使用协程,您的代码在默认情况下不受中断保护。您必须显式使用await才能让程序的其余部分运行。
协程不是持有锁来同步多个线程的操作,而是根据定义保证其是“同步”:任何时候只有其中一个协程在运行。当您想放弃控制权时,您可以使用 await 将控制权交还给调度程序。这就是为什么可以安全地取消协程的原因:根据定义,协程只有在await表达式处挂起时才能取消,因此您可以通过处理 CancelledError 异常来执行清理。
time.sleep() 调用阻塞但不执行任何操作。现在,我们将试验 CPU 密集型调用,以更好地了解 GIL,以及异步代码中处理 CPU 密集型函数的效果。
GIL 的真正影响
在线程版的代码(示例 19-1)中,您可以使用来自您喜欢的库的 HTTP 客户端请求替换slow函数中的 time.sleep(3) 调用,并且spinner将继续旋转。那是因为一个设计良好的网络库会在等待网络的同时会释放 GIL。
您还可以替换slow协程中的 asyncio.sleep(3) 表达式以等待设计良好的异步网络库的响应,因为这样的库提供了协程,在等待网络时将控制权交还给事件循环。同时,spinner将继续旋转。
对于 CPU 密集型代码,情况就不同了。如示例 19-10 中的函数 is_prime,如果参数是素数,则返回 True,否则返回 False。
例 19-10。 primes.py:可读性强的素数检查,来自 Python 的 ProcessPoolExecutor 示例。
def is_prime(n: int) -> bool:
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
root = math.isqrt(n)
for i in range(3, root + 1, 2):
if n % i == 0:
return False
return True在我现在使用的公司笔记本电脑上调用 is_prime(5_000_111_000_222_021) 大约需要 3.3 秒。
快速测验
根据我们目前了解的知识,请花点时间考虑以下由三部分组成的问题。答案的一部分很难以理解(至少对我来说是这样)。
如果您进行以下更改,spinner的动画会发生什么情况,假设 n = 5_000_111_000_222_021,这个质数在我的机器需要 3.3 秒才能验证完:
- 在 spinner_proc.py 中,将 time.sleep(3) 替换为对 is_prime(n) 的调用?
- 在 spinner_thread.py 中,将 time.sleep(3) 替换为对 is_prime(n) 的调用?
- 在 spinner_async.py 中,将 await asyncio.sleep(3) 替换为对 is_prime(n) 的调用?
在您运行代码或继续阅读之前,我建议您自己找出答案。然后,您可能希望按照建议复制和修改 spinner*.py_ 示例。
1多进程的答案:
Spinner 由子进程控制,因此它继续旋转,而父进程计算素数测试
2多线程的答案:
Spinner 由辅助线程控制,因此它继续旋转,而主线程计算素数测试。
最开始我没有得到正确的答案:我原以为旋转器会冻结,因为我高估了 GIL 的影响。
在这个特定的例子中,spinner一直在旋转,因为 Python 每 5 毫秒(默认情况下)暂停正在运行的线程,使 GIL 可用于其他挂起的线程。因此,运行 is_prime 的主线程每 5ms 中断一次,让从线程唤醒并通过 for 循环迭代一次,直到它调用 done 事件的 wait 方法,此时它会释放 GIL。然后主线程将获取 GIL,并且 is_prime 计算将继续进行 5ms。
这对这个特定示例的运行时间没有明显影响,因为spinner函数快速迭代一次并在等待Done事件时释放 GIL,因此对 GIL 没有太多争用。
在这个简单的实验中,我们使用线程处理计算密集型任务,因为只有两个线程:一个占用 CPU,另一个每秒仅唤醒 10 次以更新spinner.
但是如果您有两个或更多线程争夺大量 CPU 时间,多线程的程序将比顺序执行的代码慢。
3 Asyncio的答案
如果在 spinner_async.py 示例的slow协程中调用 is_prime(5_000_111_000_222_021),则spinner永远不会出现。当我们将 await asyncio.sleep(3) 替换为 time.sleep(3) 时,效果将与示例 19-6 中的效果相同:旋转不会出现。控制流将从supervisor传递到slow,然后传递到is_prime。当 is_prime 返回时,slow 也返回,随后 supervisor 恢复,但是会在执行前调用spinner 任务的cancel。程序似乎冻结了大约 3 秒,随后打印出答案。
使用sleep(0)将控制还给事件循环
保持微调器处于活动状态的一种方法是将 is_prime 重写为协程,并在 await 表达式中定期调用 asyncio.sleep(0) 以将控制权交还给事件循环,如下所示:
例 19-11。 spinner_async_nap.py: is_prime 现在是一个协程
async def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
root = math.isqrt(n)
for i in range(3, root + 1, 2):
if n % i == 0:
return False
if i % 100_000 == 1:
await asyncio.sleep(0) 1
return True1每 50,000 次迭代睡眠一次(因为range内的步长为 2)
asyncio 仓库中的Issue #284 有一个关于使用 asyncio.sleep(0) 的讨论。
但是,请注意这会减慢 is_prime 的执行速度,而且——更重要的是——仍然会减慢事件循环和整个程序的速度。当我每 100,000 次迭代使用 一次await asyncio.sleep(0) 时,微调器很流畅,但程序在我的机器上运行时间为 4.9 秒,比具有相同参数 (5_000_111_000_222_021) 的原始 primes.is_prime 函数本身执行时间长了几乎 50%。
在重构异步代码以将 CPU 密集型计算委托给另一个进程之前,应将使用 await asyncio.sleep(0) 视为一个workaround。我们将在第 21 章中介绍其中的一种方法是使用 asyncio.loop.run_in_executor 。另一种选择是任务队列,我们将在“Distributed task queues”中简要讨论。
到目前为止,我们只尝试了一次对 CPU 密集型函数的调用。下一节介绍多个 CPU 密集型调用的并发执行。
一个本地进程池
Note:
我写这个部分是为了展示对 CPU 密集型任务使用多个进程,以及使用队列来分发任务和收集结果的常见模式。第 20 章将展示一种将任务分配给进程的更简单方法:来自 concurrent.futures 包的 ProcessPoolExecutor,它在内部维护使用了一个队列。
在本节中,我们将编写程序来计算 20 个整数样本的素性,从 2 到 9,999,999,999,999,999,i.e. 10的16次方-1,或者大于2的53次方。样本包括小的素数和大的素数,以及小素数和大素数因子组成的合数。
sequence.py 程序提供了性能基线。这是示例的运行:
$ python3 sequential.py
2 P 0.000001s
142702110479723 P 0.568328s
299593572317531 P 0.796773s
3333333333333301 P 2.648625s
3333333333333333 0.000007s
3333335652092209 2.672323s
4444444444444423 P 3.052667s
4444444444444444 0.000001s
4444444488888889 3.061083s
5555553133149889 3.451833s
5555555555555503 P 3.556867s
5555555555555555 0.000007s
6666666666666666 0.000001s
6666666666666719 P 3.781064s
6666667141414921 3.778166s
7777777536340681 4.120069s
7777777777777753 P 4.141530s
7777777777777777 0.000007s
9999999999999917 P 4.678164s
9999999999999999 0.000007s
Total time: 40.31结果分为三列:
- 要检查的数字;
- 如果是质数,值为P;如果不是,则为空;
- 检查这个数是否为素数所用的时间。
在这个例子中,总时间大约是每次计算的时间总和——每次都是单独计算,如例 19-12 所示。
例 19-12。 sequence.py:对小数据集进行顺序的素数检查
#!/usr/bin/env python3
"""
sequential.py: baseline for comparing sequential, multiprocessing,
and threading code for CPU-intensive work.
"""
from time import perf_counter
from typing import NamedTuple
from primes import is_prime, NUMBERS
class Result(NamedTuple): 1
prime: bool
elapsed: float
def check(n: int) -> Result: 2
t0 = perf_counter()
prime = is_prime(n)
return Result(prime, perf_counter() - t0)
def main() -> None:
print(f'Checking {len(NUMBERS)} numbers sequentially:')
t0 = perf_counter()
for n in NUMBERS: 3
prime, elapsed = check(n)
label = 'P' if prime else ' '
print(f'{n:16} {label} {elapsed:9.6f}s')
elapsed = perf_counter() - t0 4
print(f'Total time: {elapsed:.2f}s')
if __name__ == '__main__':
main()
- check 函数(如下所示)返回一个 Result 元组,其中包含 is_prime 调用结果布尔值和执行的时间。
- check(n) 调用 is_prime(n) 并计算返回结果所用的时间。
- 对于样本中的每个数字,我们调用 check方法 并打印结果。
- 计算并打印总执行时间。
基于进程的解决方案
下一个示例 procs.py 展示了如何使用多个进程在多个 CPU 内核之间分发素数检查。这些是我使用 procs.py 的时间:
$ python3 procs.py
Checking 20 numbers with 12 processes:
2 P 0.000002s
3333333333333333 0.000021s
4444444444444444 0.000002s
5555555555555555 0.000018s
6666666666666666 0.000002s
142702110479723 P 1.350982s
7777777777777777 0.000009s
299593572317531 P 1.981411s
9999999999999999 0.000008s
3333333333333301 P 6.328173s
3333335652092209 6.419249s
4444444488888889 7.051267s
4444444444444423 P 7.122004s
5555553133149889 7.412735s
5555555555555503 P 7.603327s
6666666666666719 P 7.934670s
6666667141414921 8.017599s
7777777536340681 8.339623s
7777777777777753 P 8.388859s
9999999999999917 P 8.117313s
20 checks in 9.58s输出的最后一行显示 procs.py 比 Sequential.py 快 4.2 倍。
理解耗费的时间
请注意,第一列中的经过时间用于检查这个特定的数字。例如,is_prime(7777777777777753) 花了将近 8.4 秒才返回 True。同时,其他进程正在并行计算其他数字。
一共有 20 个数字需要检查。我编写了 procs.py 来启动与 CPU 内核数相等的工作进程数,由 multiprocessing.cpu_count() 确定。
在这种情况下,总时间远小于每次计算检查所用时间的总和。由于在启动进程和进程间通信方面存在一些开销,因此最终结果是多进程版本仅比顺序执行快 4.2 倍。结果看起来不错,但考虑到代码启动了 12 个进程来使用这台笔记本电脑上的所有内核,这个结果有点令人失望。
NOTE
multiprocessing.cpu_count() 函数在我用来编写本章的 MacBook Pro 上返回 12。它实际上是一个 6-CPU Core-i7,但操作系统报告了 12 个 CPU,因为超线程是一种英特尔技术,每个内核执行 2 个线程。然而,当其中一个线程不像同一个内核中的另一个线程那样努力工作时,超线程工作得更好——也许第一个线程在缓存未命中后停止等待数据,而另一个线程正在处理数字。所以,天下没有免费的午餐:这台笔记本电脑用于不会使用大量内存的计算密集型工作时——就像简单的素数测试一样,性能就像一台 6 CPU 机器,
多核 Prime Checker 的代码
当我们将计算委托给线程或进程时,我们的代码不会直接调用工作函数,因此我们不能简单地获取返回值。相反,worker 是由线程或进程库驱动的,它最终会产生一个需要存储在某个地方的结果。worker间的协作和收集结果是队列在并发编程中的常见用途——在分布式系统中也是如此。
procs.py 中的大部分新代码都与设置和使用队列有关。文件的顶部在示例 19-13 中。
WARNING:
SimpleQueue 在 Python 3.9 中被添加到multiprocessing中。如果您使用的是早期版本的 Python,则可以在示例 19-13 中将 SimpleQueue 替换为 Queue。
例 19-13。 procs.py:多进程素数检查;导入、类型和函数
import sys
from time import perf_counter
from typing import NamedTuple
from multiprocessing import Process, SimpleQueue, cpu_count 1
from multiprocessing import queues 2
from primes import is_prime, NUMBERS
class PrimeResult(NamedTuple): 3
n: int
prime: bool
elapsed: float
JobQueue = queues.SimpleQueue[int] 4
ResultQueue = queues.SimpleQueue[PrimeResult] 5
def check(n: int) -> PrimeResult: 6
t0 = perf_counter()
res = is_prime(n)
return PrimeResult(n, res, perf_counter() - t0)
def worker(jobs: JobQueue, results: ResultQueue) -> None: 7
while n := jobs.get(): 8
results.put(check(n)) 9
results.put(PrimeResult(0, False, 0.0)) 10
def start_jobs(
procs: int, jobs: JobQueue, results: ResultQueue 11
) -> None:
for n in NUMBERS:
jobs.put(n) 12
for _ in range(procs):
proc = Process(target=worker, args=(jobs, results)) 13
proc.start() 14
jobs.put(0) 15
- 为了模拟threading,multiprocessing 提供了 multiprocessing.SimpleQueue,但这是一个绑定到较低级别 BaseContext 类的预定义实例的方法。我们必须调用这个 SimpleQueue 来构建一个队列,我们不能在类型提示中使用它。
- multiprocessing.queues 有我们需要类型提示的 SimpleQueue 类。
- PrimeResult 包括检查素数的数字。将 n 与其他结果字段放在一起可以简化以后的结果显示。
- 这是 SimpleQueue 的类型别名,main函数(示例 19-14)将使用它向将执行工作的进程发送数字。
- 第二个 SimpleQueue 的类型别名,用于在 main 中收集结果。队列中的值是由要测试的是否为素数的数字和一个 Result 元组组成的元组。
- 这个函数类似于sequential.py。
- workers获得一个包含要检查的数字的队列,和另一个用于放置结果的队列。
- 在这段代码中,我使用数字 0 作为毒药片:worker完成的信号。如果 n 不为 0,则继续循环。
- 调用素数检查并将 PrimeResult 加入队列。
- 发回 PrimeResult(0, False, 0.0) 以让主循环知道这个线程的worker已完成。
- procs 是将并行计算素数检查的进程数。
- 将要在worker中检查的数字排入队列。
-
为每个worker派生一个子进程。每个子进程都将在它自己的worker函数实例内运行循环,直到它从jobs队列中获取 0.
-
启动每个子进程。
-
每个进程都让 0入队,以终止进程。
循环、哨兵和毒药片
示例 19-13 中的worker函数遵循并发编程中的一个常见模式:使用无限循环,同时从队列中取出项并使用执行实际工作的函数处理每个项。当队列产生一个哨兵值时,循环结束。在这种模式下,关闭worker的哨兵通常被称为“毒药片”。
None 通常用作哨兵值,但如果它可以出现在数据流中,则可能并不合适。调用 object() 是获取唯一值以用作标记的常用方法。但是,这不适用于进程之间,因为 Python 对象必须序列化才能进行进程间通信,当你 pickle.dump 和 pickle.load 一个对象实例时,反序列化的实例与原始实例不同:它比较不相等。一个很好的替代 None 是 Ellipsis 内置对象(又名...),它在序列化后id不会发生变化。
Python 的标准库使用许多不同的值作为标记。 PEP 661—Sentinel Values 提出了标准的哨兵类型。截至 2021 年 9 月,它只是一个草案。
现在让我们研究例 19-14 中 procs.py 的main函数。
例 19-14。 procs.py:多进程素数检查;main函数
def main() -> None:
if len(sys.argv) < 2: 1
procs = cpu_count()
else:
procs = int(sys.argv[1])
print(f'Checking {len(NUMBERS)} numbers with {procs} processes:')
t0 = perf_counter()
jobs: JobQueue = SimpleQueue() 2
results: ResultQueue = SimpleQueue()
start_jobs(procs, jobs, results) 3
checked = report(procs, results) 4
elapsed = perf_counter() - t0
print(f'{checked} checks in {elapsed:.2f}s') 5
def report(procs: int, results: ResultQueue) -> int: 6
checked = 0
procs_done = 0
while procs_done < procs: 7
n, prime, elapsed = results.get() 8
if n == 0: 9
procs_done += 1
else:
checked += 1 10
label = 'P' if prime else ' '
print(f'{n:16} {label} {elapsed:9.6f}s')
return checked
if __name__ == '__main__':
main()- 如果没有给出命令行参数,则将进程数设置为CPU内核数;否则,创建第一个参数数量相同的进程(尽可能多)。
- jobs和results是示例 19-13 中描述的队列。
- 启动 proc 进程以消费jobs并将结果放入result。
- 检索结果并显示;report函数在下面定义。
- 显示检查了多少个数字和总耗时。
- 参数是 procs 的数量和存放结果的队列
- 循环直到所有进程完成。
- 获得一个 PrimeResult。在队列中调用 .get() 会阻塞,直到队列中有一个项。也可以设置为非阻塞,或设置超时。有关详细信息,请参阅 SimpleQueue.get 文档。
- 如果 n 为零,则退出一个进程;增加 procs_done 计数。
- 否则,增加checked的计数(以跟踪检查的数字)并打印结果。
结果不会以提交作业的相同顺序返回。这就是我必须在每个 PrimeResult 元组中放入 n 的原因。否则,我无法知到数字对应哪个结果。
如果主进程在所有子进程完成之前退出,您可能会看到由多处理中的内部锁引起的 FileNotFoundError 异常的令人迷惑的问题回溯。调试并发代码总是很困难,而调试多进程则更加困难,因为线程式外观背后有很强的复杂性。幸运的是,我们将在第 20 章中遇到的 ProcessPoolExecutor 更易于使用且更健壮。
Note:
感谢读者 Michael Albert,他注意到我在early release发布的代码在示例 19-14 中存在竞争条件。竞争条件是一种错误,它可能会发生也可能不会发生,具体取决于并发执行单元执行的操作顺序。如果“A”发生在“B”之前,则一切正常;但是“B”首先发生,出了点问题。这就是竞争。
如果你好奇,这个差异显示了这个错误以及我是如何修复它的:example-code-2e/commit/2c123057——但请注意,我后来重构了这个例子,将 main 的部分委托给 start_jobs 和报告函数。同一目录中有一个 README.md 文件,解释了问题和解决方案。
试验:使用更多或者更少的进程
您可能想尝试运行 procs.py 传递参数来设置工作进程的数量。例如,这个命令...
$ python3 procs.py 2...将启动两个工作进程,产生的结果几乎是sequential.py 的两倍——如果你的机器至少有两个内核并且没有长时间运行其他程序。
我用 1 到 20 个进程运行了 procs.py 12 次,总共运行了 240 次。然后我计算了具有相同进程数的所有执行结果的中位时间,并绘制了图 19-2。

在这台 6 核笔记本电脑中,最低的中位数时间是 6 个进程:10.39 秒——用图 19-2 中的虚线标记。由于 CPU 争用,我预计运行时间会在 6 个进程后增加,并且在 10 个进程时达到本地最大值 12.51s。 意料之外的事实是性能在 11 个进程时有所提高,而从 13 到 20 个进程几乎保持不变,中值时间仅略高于 6 个进程的最低中值时间。
基于线程的非解决方案
我还编写了threads.py,它是procs.py 的一个版本,使用线程而不是多进程。代码非常相似——在这两个 API 之间转换简单示例时通常就是这种情况。由于 is_prime 的 GIL 和计算密集型特性,线程版本比示例 19-12 中的顺序代码慢,由于 CPU 争用和上下文切换的成本,它随着线程数量的增加而变慢:要切换到新线程,操作系统需要保存 CPU 寄存器并更新程序计数器和堆栈指针——这个副作用的触发成本很昂贵,例如使 CPU 缓存失效,甚至可能交换内存页。
接下来的两章将详细介绍 Python 中的并发编程,使用高级 concurrent.futures 库来管理线程和进程(第 20 章)和用于异步编程的 asyncio 库(第 21 章)。
本章的其余部分旨在回答以下问题:
鉴于目前讨论的局限性,Python 如何在多核世界中蓬勃发展?
多核世界中的 Python
想想赫伯·萨特 (Herb Sutter) 广泛引用的文章《免费午餐已经结束了》中的引用:
主要的处理器制造商和架构,从 Intel 和 AMD 到 Sparc 和 PowerPC,他们的大多数传统方法已经没有空间来提高 CPU 性能。他们没有将时钟速度和直线指令吞吐量推得更高,而是集体转向超线程和多核架构。
Sutter 称之为“免费午餐”的趋势是,无需额外的开发人员努力,软件就会变得更快,因为 CPU 每年都可以更快地执行顺序代码。自 2004 年以来,情况不再如此:时钟速度和执行优化到达了瓶颈期,现在,任何显着的性能提升都必须通过利用多核或超线程,这些进步只会使为并发执行而编写的代码受益。
Python 的故事始于 1990 年代初,当时 CPU 在顺序代码执行方面的速度仍然呈指数级增长。除了当时的超级计算机之外,没有场景会谈论多核 CPU。当时,决定加入 GIL 是轻而易举的事。GIL 使解释器在单核上运行速度更快,并且解释器的实现更简单。GIL 还使通过 Python/C API 编写简单扩展程序变得更加容易。
Note:
我只是写了“简单扩展”,因为扩展应用无需处理 GIL。用 C 或 Fortran 编写的函数可能比 Python 中的等价函数快数百倍。因此,在许多情况下释放 GIL 以利用多核 CPU 带来的额外复杂度可能是不需要的。所以我们要感谢 GIL 为 Python 提供了许多可用的扩展——这当然是python在今天如此流行的关键原因之一。
尽管有 GIL的限制,Python 在需要并发或并行执行的应用程序中还是蓬勃发展,这要归功于解决 CPython 限制的库和软件架构。
现在让我们讨论在 2021 年的多核分布式计算世界中如何将 Python 用于系统管理、数据科学和服务器端应用程序开发。
系统管理
Python 广泛用于管理大量服务器、路由器、负载均衡、网络附加存储 (NAS)。它也是软件定义网络 (SDN) 和有底线道德的黑客的优先选择。主要的云服务提供商通过由提供商自己或其庞大的 Python 用户社区编写的库和教程来支持 Python。
在这个领域中,Python 脚本通过发出由远程机器执行的命令来自动执行配置任务,因此很少 需要完成CPU 密集型操作。线程或协程非常适合此类工作。特别是,我们将在第 20 章中看到的 concurrent.futures 包可用于同时在许多远程机器上执行相同的操作,并且操作并不复杂。
除了标准库之外,还有一些流行的基于 Python 的项目来管理服务器集群:像 Ansible 和 Salt 这样的工具,以及像 Fabric 这样的库。
还有越来越多的系统管理库支持协程和asyncio。2016 年,Facebook 的生产工程团队报告说:“我们越来越依赖 Python 3.4 中引入的 AsyncIO,并且随着我们将代码库从 Python 2 升级到3,性能得到了巨大提升。”
数据科学
Python 为数据科学(包括人工智能)和科学计算提供了很好的服务。这些领域的应用程序是计算密集型的,但 Python 用户受益于用 C、C++、Fortran、Cython 等编写的庞大的数值计算库生态系统。其中许多能够在异构集群中利用多核机器、GPU 和/或分布式并行计算。
截至 2021 年,Python 的数据科学生态系统包括令人印象深刻的工具,例如:
Project Jupyter:
两个基于浏览器的界面——Jupyter Notebook 和 JupyterLab——允许用户在远程机器上运行和记录可能通过网络运行的分析代码。两者都是混合 Python/JavaScript 应用程序,支持用不同语言编写的计算内核,都通过 ZeroMQ 集成——一个用于分布式应用程序的异步消息传递库。Jupyter 这个名字实际上来自于 Notebook 支持的前三种语言 Julia、Python 和 R。建立在 Jupyter 工具之上的丰富生态系统包括 Bokeh, 一个强大的交互式可视化库,由于现代 JavaScript 引擎和浏览器的性能,它允许用户导航并与大型数据集或不断更新的流数据进行交互。
TensorFlow and PyTorch:
根据 O'Reilly Media 2021 年 1 月关于其 2020 年学习资源使用情况的报告,这是排名前二的深度学习框架。这两个项目都是用 C++ 编写的,并且能够利用多个内核、GPU 和集群。它们也支持其他语言,但 Python 是它们的主要焦点,并且被大多数用户使用。TensorFlow 由 Google 创建并在内部使用; Facebook 创建了 PyTorch。
Dask:
一个并行计算库,可以将工作外包给本地进程或机器集群,“已经在世界上一些最大的超级计算机上进行测试”——正如他们的主页所说。Dask 提供的 API 可以模拟 NumPy、Pandas 和 Scikit-Learn——当今数据科学和机器学习领域最受欢迎的库。Dask 可以在 JupyterLab 或 Jupyter Notebook 中使用,并且利用 Bokeh 用于数据可视化和交互式仪表板,以近乎实时的方式显示跨进程/机器的数据和计算流。Dask 令人印象深刻,我推荐观看一个视频,例如15-minute demo ,其中 Matthew Rocklin(该项目的维护者)展示了 Dask 对分布在 AWS 上的 8 台 EC2 机器上的 64 个内核的数据进行处理。
这些只是一些示例,用于说明数据科学社区如何创建利用 Python 的最佳优势并克服 CPython 运行时限制的解决方案。
服务器端网页/移动开发
Python 广泛用于 Web 应用程序和支持移动应用程序的后端 API。Google、YouTube、Dropbox、Instagram、Quora 和 Reddit 等公司是如何成功构建 Python 服务器端应用程序,为数亿用户提供 7X24小时服务的?同样,答案远远超出 Python 提供的“开箱即用”的功能。
在我们讨论大规模支持 Python 的工具之前,我必须引用 Thoughtworks 技术雷达的一条警告:
不必要的高性能/网络规模扩展欲望
我们看到许多团队遇到麻烦,因为他们选择了复杂的工具、框架或架构,因为他们“可能需要扩展”。Twitter 和 Netflix 等公司需要支持极端负载,因此需要这些架构,但他们也拥有能够处理复杂性的非常熟练的开发团队。大多数情况不需要这些工程专长;团队应该控制他们对网络规模的扩张欲望,以支持仍然可以完成工作的更简单的解决方案
在 Web 规模上,关键是允许水平扩展的架构。那时,所有系统都是分布式系统,没有一种编程语言可能是解决方案每个部分的正确选择。分布式系统是一个学术研究领域,但幸运的是,一些从业者已经编写了基于扎实的研究和实践经验的易于阅读的书籍。其中之一是 Martin Kleppmann,他是《设计数据密集型应用程序》(O'Reilly,2017 年)的作者。
考虑图 19-3,这是 Kleppmann 书中许多架构图的第一个。以下是我在 Python 项目中看到的一些我参与过或拥有第一手知识的组件:
- 应用缓存:memcached、Redis、Varnish;
- 关系型数据库:PostgreSQL、MySQL;
- 文档型数据库:Apache CouchDB、MongoDB;
- 全文索引:Elasticsearch、Apache Solr;
- 消息队列:RabbitMQ、Redis。

在这些类别中,还有其他具有工业强度的开源产品。主要的云提供商也提供他们自己的专有替代方案。
Kleppmann 的图表是通用的且与语言无关——就像他的书一样。对于 Python 服务器端应用程序,通常会部署两个特定组件:
- 将负载分配给多个Python 应用程序的实例的应用程序服务器。 应用服务器将出现在图 19-3 的顶部附近,在客户端请求到达应用程序代码之前处理它们。
- 围绕图 19-3 右侧的消息队列构建的任务队列,提供更高级别、更易于使用的 API 来将任务分发到其他机器上运行的进程。
接下来的两节探讨了这些组件,这些组件是 Python 服务器端部署中推荐的最佳实践。
WSGI Application servers
WSGI(Web Server Gateway Interface)是 Python 框架或应用程序的标准 API,用于接收来自 HTTP 服务器的请求并向其发送响应。WSGI 应用服务器管理一个或多个运行应用的进程,最大限度地利用可用的 CPU。
图 19-4 演示了一个典型的部署。

TIP:
如果我们想合并图19-3和19-4,图 19-4 中虚线矩形的内容将替换图 19-3 顶部的实心“Application code”矩形。
Python Web 项目中最出名的应用服务器是:
-
mod_wsgi;
-
uWSGI;
-
Gunicorn;
-
NGINX Unit.
对于 Apache HTTP Server 的用户,mod_wsgi 是最好的选择。它与 WSGI 本身一样古老,但仍然进行积极的维护,现在提供了一个名为 mod_wsgi-express 的命令行启动器,它更容易配置,更适合在 Docker 容器中使用。
uWSGI 和 gunicorn 是我最近知道的项目中的首选。两者都经常与 NGINX HTTP 服务器一起使用。uWSGI 提供了许多额外的功能,包括应用程序缓存、任务队列、类似 cron 的周期性任务以及许多其他功能。另一方面,uWSGI 比 gunicorn 更难正确配置。
NGINX Unit于2018年发布,是著名的 HTTP服务器和反向代理制造商NGINX的新产品。
mod_wsgi 和 gunicorn 仅支持 Python Web 应用程序,而 uWSGI 和 NGINX Unit 也适用于其他语言。请浏览他们的文档以了解更多信息。
要点:所有这些应用程序服务器都可以通过派生多个 Python 进程来运行使用 Django、Flask、Pyramid 等古老的顺序代码编写的传统 Web 应用程序,从而潜在地使用服务器上的所有 CPU 内核。这解释了为什么无需学习thread、multiprocess或 asyncio 模块就可以作为 Python Web 开发人员:应用程序服务器已经透明地处理了并发。
ASGI—ASYNCHRONOUS SERVER GATEWAY INTERFACE
WSGI 是一个同步 API。它不支持带有 async/await 的协程——这是在 Python 中实现 WebSockets 或 HTTP 长轮询的最高效的方法。ASGI 规范是 WSGI 的继承者,为异步 Python Web 框架(例如 aiohttp、Sanic、FastAPI 等) 设计,同时Django 和 Flask这些框架正在逐步添加异步功能。
现在让我们转向另一种绕过 GIL 的方法,以使服务器端 Python 应用程序实现更高的性能。
分布式任务队列
当应用程序服务器向运行代码的Python 进程之一发送请求时,您的应用程序需要快速响应:因为您希望该进程能够尽快处理下一个请求。但是,某些请求需要执行可能需要更长时间的操作 — 例如,发送电子邮件或生成 PDF。这就是分布式任务队列旨在解决的问题。
Celery 和 RQ是最著名的带有 Python API 的开源任务队列。云提供商还提供他们自己的专有任务队列。
这些产品包装了一个消息队列并提供了一个高级 API,用于将任务委派给可能在不同机器上运行的worker。
Note:
在任务队列的上下文中,使用生产者和消费者这两个词代替传统的客户端/服务器术语。例如,Django 视图处理程序生产(produce)任务请求,这些请求被放入队列以供一个或多个 PDF 渲染进程消费(consume)。
直接引用 Celery 的常见问题解答,这里有一些典型的用例:
- 在后台运行一些东西。例如,为了尽快完成 Web 请求,然后逐步更新用户页面。这给用户留下了良好的性能和“快速”的印象,即使实际的任务实际上可能需要一些时间。
- 在 Web 请求完成后运行一些东西。
- 通过异步执行和使用tries来确保某个任务完成。
- 遍排定期任务。
除了解决这些紧迫的问题外,任务队列还支持水平可扩展性。生产者和消费者是解耦的:生产者不调用消费者,而是将请求放入队列中。消费者不需要知道任何关于生产者的信息(但如果需要确认,请求可能包括关于生产者的信息)。至关重要的是,随着需求的增长,您可以轻松添加更多的worker来消费任务。这就是为什么 Celery 和 RQ 被称为分布式任务队列。
回想一下,我们的简单 procs.py(示例 19-13)使用了两个队列:一个用于任务请求,另一个用于收集结果。Celery 和 RQ 的分布式架构使用了类似的模式。两者都支持使用Redis NoSQL数据库作为消息队列和结果存储。Celery 还支持其他消息队列,如 RabbitMQ 或 Amazon SQS,以及其他用于结果存储的数据库。
我们对 Python 中的并发性的介绍到此结束。接下来的两章将继续这个主题,重点介绍标准库的 concurrent.futures 和 asyncio 包。