什么是CUDA? GPU的并行编程
CUDA是Nvidia开发的一种并行计算平台和编程模型,用于在其自己的GPU(图形处理单元)上进行常规计算。 CUDA使开发人员能够利用GPU的能力来实现计算的可并行化部分,从而加快计算密集型应用程序的速度。
虽然还有其他提议的GPU API,例如OpenCL ,并且还有其他公司(例如AMD )的竞争性GPU,但CUDA和Nvidia GPU的结合在包括深度学习在内的多个应用领域中占主导地位,并且是其中一些基础世界上最快的计算机。
图形卡可以说与PC一样古老,也就是说,如果您将1981 IBM Monochrome Display Adapter视为图形卡。 到1988年,您可以从ATI(该公司最终被AMD收购)那里获得16位2D VGA Wonder卡。 到1996年,您可以从3dfx Interactive购买3D图形加速器,以便全速运行第一人称射击游戏Quake。
同样是在1996年,英伟达开始尝试用弱势产品来竞争3D加速器市场,但是随着它的发展,它得到了了解。1999年,英伟达成功推出了GeForce 256,这是第一款被称为GPU的图形卡。 当时,拥有GPU的主要原因是游戏。 直到后来人们才将GPU用于数学,科学和工程学。
CUDA的由来
2003年,由伊恩·巴克(Ian Buck)领导的一组研究人员揭开了布鲁克(Brook)的神秘面纱,这是第一个被广泛采用以数据并行结构扩展C的编程模型。 Buck随后加入Nvidia,并于2006年领导CUDA的发布,这是第一个用于GPU的通用计算的商业解决方案。
OpenCL与CUDA
CUDA的竞争对手OpenCL由Apple和Khronos Group于2009年推出,旨在为异构计算提供标准,该标准不限于具有Nvidia GPU的Intel / AMD CPU。 尽管OpenCL由于其通用性听起来很吸引人,但在Nvidia GPU上的表现却不如CUDA,许多深度学习框架要么不支持它,要么仅在发布CUDA支持后才支持它。
CUDA性能提升
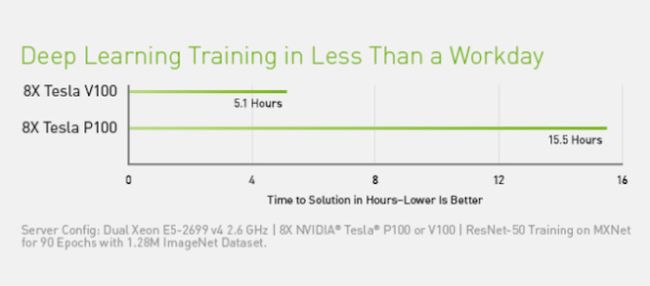
多年来,CUDA不断改进和扩展了其范围,而改进的Nvidia GPU则或多或少地步调一致。 从CUDA 9.2版开始,使用多个P100服务器GPU,您可以将CPU的性能提高多达50倍。 对于某些负载,V100(此图中未显示)要快3倍。 上一代服务器GPU K80与CPU相比,性能提高了5到12倍。
 英伟达
英伟达
GPU的速度提升已成为高性能计算的紧缺时间。 随时间推移,CPU的单线程性能提高(摩尔定律建议每18个月增加一倍),由于芯片制造商遇到物理限制(包括制造过程中对芯片掩模分辨率和芯片成品率的限制),因此每年降低到10%。在运行时限制时钟频率。
 英伟达
英伟达
CUDA应用程序域
 英伟达
英伟达
如上图所示,CUDA和Nvidia GPU已在许多需要高浮点计算性能的领域中采用。 更全面的列表包括:
- 计算金融
- 气候,天气和海洋模拟
- 数据科学与分析
- 深度学习和机器学习
- 国防与情报
- 制造/ AEC(建筑,工程和施工):CAD和CAE(包括计算流体力学,计算结构力学,设计和可视化以及电子设计自动化)
- 媒体和娱乐(包括动画,建模和渲染;色彩校正和纹理管理;合成;完成和效果;编辑;编码和数字分发;直播图形;现场,审阅和立体声工具;以及天气图形)
- 医学影像
- 油和气
- 研究:高等教育和超级计算(包括计算化学和生物学,数值分析,物理学和科学可视化)
- 安全保障
- 工具与管理
深度学习中的CUDA
深度学习对计算速度的需求过大。 例如, 为了在2016年训练Google Translate的模型 ,Google Brain和Google Translate团队使用GPU进行了数百次为期一周的TensorFlow运行; 为此,他们从Nvidia购买了2,000个服务器级GPU。 如果没有GPU,那么这些训练运行将花费数月而不是一周的时间。 为了将这些TensorFlow转换模型进行生产部署,Google使用了新的自定义处理芯片TPU(张量处理单元)。
除了TensorFlow以外,许多其他DL框架还依赖CUDA来提供GPU支持,包括Caffe2,CNTK,Databricks,H2O.ai,Keras,MXNet,PyTorch,Theano和Torch。 在大多数情况下,他们使用cuDNN库进行深度神经网络计算。 该库对于深度学习框架的培训是如此重要,以至于使用给定版本的cuDNN的所有框架对于等效的用例而言,其性能数字基本相同。 当CUDA和cuDNN从一个版本升级到另一个版本时,所有更新到新版本的深度学习框架都将获得性能提升。 各个框架的性能往往会有所不同的地方在于它们可扩展到多个GPU和多个节点的程度。
CUDA程式设计
 英伟达
英伟达
CUDA工具包
CUDA工具包包括库,调试和优化工具,编译器,文档以及用于部署应用程序的运行时库。 它具有支持深度学习,线性代数,信号处理和并行算法的组件。 通常,CUDA库支持所有Nvidia GPU系列,但在最新一代产品上表现最佳,例如V100,对于深度学习培训工作负载,其速度可能比P100快3倍。 只要在适当的库中实现了所需的算法,使用一个或多个库就是利用GPU的最简单方法。
 英伟达
英伟达
CUDA深度学习库
在深度学习领域,有三个主要的GPU加速库:cuDNN,我之前提到它是大多数开源深度学习框架的GPU组件; TensorRT是Nvidia的高性能深度学习推理优化器和运行时; 和DeepStream ,一个视频推理库。 TensorRT帮助您优化神经网络模型,以较低的精度进行高精度校准,并将经过训练的模型部署到云,数据中心,嵌入式系统或汽车产品平台。
 英伟达
英伟达
CUDA线性代数和数学库
线性代数是张量计算和深度学习的基础。 自从1989年以来,科学家和工程师一直在使用BLAS(基本线性代数子程序),它是在Fortran中实现的矩阵算法的集合。 cuBLAS是BLAS的GPU加速版本,是使用GPU进行矩阵运算的性能最高的方法。 cuBLAS假定矩阵是密集的; cuSPARSE处理稀疏矩阵。
 英伟达
英伟达
CUDA信号处理库
快速傅里叶变换(FFT)是用于信号处理的基本算法之一。 它将信号(例如音频波形)转换为频谱。 cuFFT是GPU加速的FFT。
使用H.264等标准的编解码器对视频进行编码/压缩和解码/解压缩,以进行传输和显示。 Nvidia Video Codec SDK通过GPU加快了此过程。
 英伟达
英伟达
CUDA并行算法库
这三个用于并行算法的库都有不同的用途。 NCCL (Nvidia集体通信库)用于在多个GPU和节点之间扩展应用程序; nvGRAPH用于并行图分析; Thrust是基于C ++标准模板库的CUDA的C ++模板库。 Thrust提供了数据并行原语的丰富集合,例如扫描,排序和精简。
英伟达
CUDA与CPU性能
在某些情况下,可以使用嵌入式CUDA函数代替等效的CPU函数。 例如,只需链接到NVBLAS库即可将BLAS的GEMM矩阵乘法例程替换为GPU版本:
 英伟达
英伟达
CUDA编程基础
如果找不到CUDA库例程来加速程序,则必须尝试低级CUDA编程 。 现在,这比我在2000年代末首次尝试时要容易得多。 除其他原因外,语法更简单,开发工具也更好。 我唯一的疑问是,在MacOS上,最新的CUDA编译器和最新的C ++编译器(来自Xcode)很少同步。 必须从苹果公司下载较旧的命令行工具,然后使用xcode-select切换到它们,以获取CUDA代码进行编译和链接。
例如,考虑使用以下简单的C / C ++例程添加两个数组:
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
} 通过将__global__关键字添加到声明中,可以将其变成将在GPU上运行的内核,然后使用三括号语法调用该内核:
add<<<1, 1>>>(N, x, y); 您还必须更改对cudaMallocManaged和cudaFree malloc / new和free / delete调用,以便在GPU上分配空间。 最后,您需要等待GPU计算完成,然后才能在CPU上使用结果,可以使用cudaDeviceSynchronize完成cudaDeviceSynchronize 。
上面的三重支架使用一个线程块和一个线程。 当前的Nvidia GPU可以处理许多块和线程。 例如,基于Pascal GPU架构的Tesla P100 GPU具有56个流式多处理器(SM),每个处理器最多可支持2048个活动线程。
内核代码将需要知道其块和线程索引才能找到其在传递数组中的偏移量。 并行化的内核通常使用网格跨度循环,例如:
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
} 如果您查看CUDA工具包中的示例,您会发现,除了上面介绍的基础知识之外,还有更多需要考虑的问题。 例如,某些CUDA函数调用需要包装在checkCudaErrors()调用中。 同样,在许多情况下,最快的代码将使用诸如cuBLAS库,以及主机和设备内存的分配以及来回矩阵的复制。
总之,您可以在多个级别使用GPU来加速您的应用程序。 您可以编写CUDA代码; 您可以调用CUDA库; 您可以使用已经支持CUDA的应用程序。
From: https://www.infoworld.com/article/3299703/what-is-cuda-parallel-programming-for-gpus.html