论文阅读笔记-TransFG: A Transformer Architecture for Fine-Grained Recognition
目录
摘要
1.引言
2.相关工作
3.方法
3.1 Vit
3.1.1 图像分块处理
3.1.2 图像块嵌入
3.1.3 位置编码
3.1.4 前向流程
3.2 Vit作为特征提取器
3.2.1 图像序列化
3.2.2 patch嵌入
3.3 TransFG 结构
3.3.1 区域选择模块
3.3.2 对比特征学习
4.实验
4.1 不同数据集实验
4.2 消融实验
5.总结
摘要
细粒度视觉分类(FGVC)旨在从子类别中识别对象,这是一项非常具有挑战性的任务,因为其固有的微妙的类间差异。现有的工作主要通过重用主干网络提取检测到的识别区域的特征来解决这一问题。然而,这种策略不可避免地会使管道复杂化,并推动建议的区域包含对象的大部分部分,因此无法定位真正重要的部分。
近年来,视觉变压器(ViT)在传统的分类任务中表现出了较强的性能。transforme的self attention机制将每个patch任务链接到分类任务。在这项工作中,我们首先评估了ViT框架在细粒度识别设置中的有效性。然后出于注意链接的强度可以直观地认为是一个指标的重要性,我们进一步提出一个新颖的区域选择模块,可以应用于大多数的变压器架构。
我们整合所有transformer的attention权重到一个attention map去指导网络有效准确地选择有区别的图像块并计算它们的关系。利用对比损失来扩大混淆类的特征表示之间的距离。我们将基于增强变压器的模型命名为TransFG,并通过在五个流行的细粒度基准上进行实验来证明它的价值,在这些基准中我们实现了最先进的性能。定性结果为了更好地理解我们的模型。
(注释:bechmark -- 基准测试是一种测试代码性能的方法, 同时也可以用来识别某段代码的CPU或者内存效率问题. 许多开发人员会用基准测试来测试不同的并发模式, 或者用基准测试来辅助配置工作池的数量, 以保证能最大化系统的吞吐量 )
作者想解决的问题:传统的细粒度分类会使得管道复杂化,并且无法定位真正重要的部分
作者解决问题的理论/模型:提出了一个可以应用于大多数transofemr结构的part selection module,称为TransFG
这个方法的优越性(创新点)在哪?:新模块整合所有transformer的attention权重到一个attention map去指导网络有效准确地选择有区别的图像块并计算它们的关系。
1.引言
细粒度视觉分类旨在对给定对象类别的子类别进行分类,FGVC的性能近年来取得了稳定的进步。为了避免劳动密集型的部分注释,社区目前关注于弱监督的FGVC,只有图像级别的标签。方法现在大致可以分为定位方法和特征编码方法两类。与特征编码方法相比,定位方法的优势是显式地捕获子类之间的细微差异,更具可解释性,产生更好的结果。
早期的定位方法依赖于部分的注释来定位鉴别区域,而最近的工作主要采用区域建议网络(提出包含鉴别区域的边界框。在获得选定的图像区域后,将它们调整为预定义的大小,并再次通过主干网络转发,以获取信息丰富的局部特征。然而,这种机制忽略了选定区域之间的关系,因此不可避免地鼓励RPN提出大型边界框,其中包含的大部分对象无法定位真正重要的区域。有时,这些边界框甚至可以包含大面积的背景内容。并导致混淆。此外,与主干网络相比,优化目标不同的RPN模块使得网络更难训练,而主干网络的重用使整个管道变得复杂。
基于这一观点,在本文中,我们提出了第一个研究,探索了Vit在细粒度视觉分类中的潜力。我们发现,在FGVC上直接应用ViT已经产生了令人满意的结果,而根据FGVC的特性进行了大量的适应,可以进一步提高性能。具体来说,我们提出了一个可以找到区分区域和去除冗余信息的部分选择模块。引入了对比损失,使模型更具鉴别性。我们将这种新颖而简单的基于转换器的框架命名为TransFG,并在五个流行的细粒度视觉分类基准(CUB-200-2011、斯坦福汽车、斯坦福狗、nabirds、inat2017)上对其进行了广泛的评估。图1可以从性能比较中看到,我们的TransFG在大多数数据集上优于现有的SOTACNN方法。总之,我们在这项工作中做出了几个重要的贡献:
1.据我们所知,我们是第一个验证Vit在细粒度视觉分类上的有效性的人,它为RPN模型设计提供了一个替代主导CNN主干的替代方案。
2.我们引入了TransFG,这是一种用于细粒度视觉分类的新型神经架构,它自然地专注于对象中最具鉴别性的区域,并在几个基准测试中实现了SOTA的性能。
3.可视化结果说明了我们的TransFG准确捕获有鉴别图像区域的能力,并帮助我们更好地理解它是如何做出正确的预测。
为什么研究这个课题:早期的细粒度分类依赖于RPN,无法定位到真正重要的区域,以及管道会变得复杂
h2研究进行到了哪个阶段:Vit中,CNN主要利用图像的局部性,只在非常高的层中捕获弱随机关系,细粒度之间的细微差异只存在某些地方,因此对一个能够捕获图像中所有地方的细微差异的滤波器进行卷积是不合理的。
使用理论基于哪些假设:提出了一个可以找到区分区域和去除冗余信息的部分选择模块。引入了对比损失,使模型更具鉴别性
2.相关工作
细粒度视觉分类
旨在解决细粒度视觉分类问题,大致可以分为两类:定位方法和特征编码方法。前者侧重于训练一个检测网络来定位鉴别部分区域,并重用它们来进行分类。后者的目标是通过计算高阶信息或寻找对比对之间的关系来学习信息更丰富的特征
3.方法
3.1 Vit

3.1.1 图像分块处理
在CNN中,直接对图像进行二维卷积处理即可。但Transformer结构不能直接处理图像,在此之前需要对其进行分块处理。
假设一个图像x∈H×W×C,现在将其分成P×P×C的patches,那么实际有N=HW/P2个patches,全部patches的维度就可以写为N×P×P×C。然后将每个patch进行展平,相应的数据维度就可以写为N×(P2×C)。这里N可以理解为输入到Transformer的序列长度,C为输入图像的通道数,P为图像patch的大小。
3.1.2 图像块嵌入
要将N×(P2×C)的向量维度,转化为N×D大小的二维输入,还需要做一个图像块嵌入的操作
所谓图像块嵌入,其实就是对每一个展平后的patch向量做一个线性变换,即全连接层,降维后的维度为D。
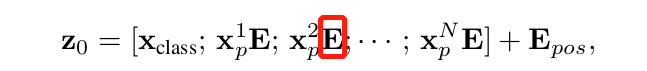
上式中的E即为块嵌入的全连接层,其输入大小为(P2×C),输出大小为D。
(上面的每一个XE都可以理解成一个token,类似于自然语言中的单词标记)
值得注意的是,上式中给长度为N的向量还追加了一个分类向量,用于Transformer训练过程中的类别信息学习。假设将图像分为9个patch,即N=9,输入到Transformer编码器中就有9个向量,但对于这9个向量而言,该取哪一个向量做分类预测呢?取哪一个都不合适。一个合理的做法就是人为添加一个类别向量,该向量是可学习的嵌入向量,与其他9个patch嵌入向量一起输入到Transformer编码器中,最后取第一个向量作为类别预测结果。所以,这个追加的向量可以理解为其他9个图像patch寻找的类别信息。
3.1.3 位置编码
为了保持输入图像patch之间的空间位置信息,还需要对图像块嵌入中添加一个位置编码向量,如上式中的Epos所示。
3.1.4 前向流程
ViT的编码器前向计算过程可以归纳如下
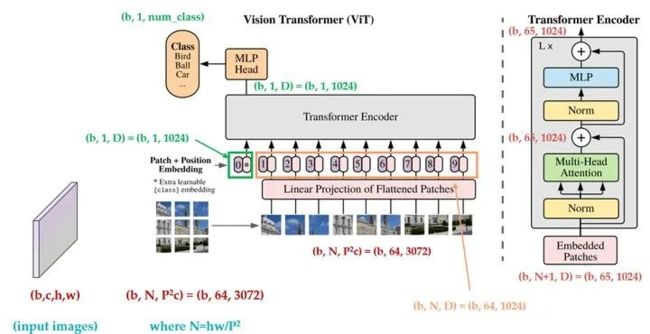
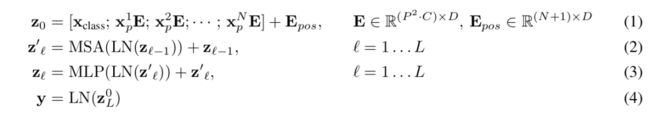
第一个式子即前述的图像块嵌入、类别向量追加和位置编码;
第二个式子为MSA部分,包括多头自注意力、跳跃连接 (Add) 和层规范化 (Norm) 三个部分,可以重复L个MSA block;
第三个式子为MLP部分,包括前馈网络 (FFN)、跳跃连接 (Add) 和层规范化 (Norm) 三个部分,也可以重复L个MSA block。
第四个式子为层规范化。最后以一个MLP作为分类头 (Classification Head)。
其他注解:全网最强ViT (Vision Transformer)原理及代码解析_CHAOS万有引力的博客-CSDN博客_vit源码
3.2 Vit作为特征提取器
3.2.1 图像序列化
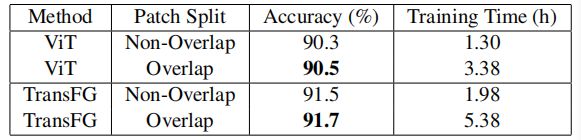
在ViT之后,我们首先将输入的图像预处理成一系列扁平的补丁xp。然而,原始的分割方法将图像切割成不重叠的斑块,这损害了局部邻近结构,特别是当区分区域被分割时。为了缓解这一问题,我们建议生成带有滑动窗口的重叠斑块。具体来说,我们将分辨率为H∗W的输入图像,图像补丁的大小表示为P,滑动窗口的步长表示为s,因此输入图像将被分割成N个patch。
![]() (原始分割方式)
(原始分割方式)

(本文分割方式)
这样,两个相邻的斑块共享一个重叠的大小区域(P−S)∗P,这有助于保存更好的局部区域信息。
3.2.2 patch嵌入

3.3 TransFG 结构
我们提出了区域选择模块(PSM),并应用对比特征学习来扩大混淆子类别之间的表示距离。我们提出的TransFG的框架如图2所示。
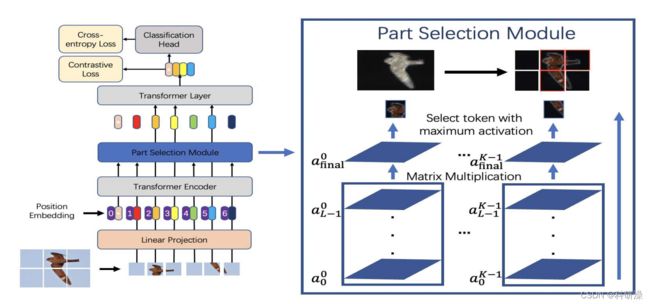
图2:我们提出的TransFG的框架。图像被分割成小块(这里显示了一个不重叠的分割),并投影到嵌入空间中。变压器编码器的输入由补丁嵌入和可学习的位置嵌入组成。在最后一个变压器层之前,应用一个部件选择模块(PSM)来选择与鉴别图像补丁对应的标记,并且只使用这些选择的标记作为输入。
3.3.1 区域选择模块
为了充分利用注意力信息,将改变最后一层的输入,对最后一层前面的所有层的权重累乘,选出
然后选择权重最大的A_k个token作为最后一层的输入。
(token:)

选取afinal中K个不同注意力首部的最大值A1、A2、…、AK,并将其与分类token进行拼接,其结果如公式(4)所示。该步骤不仅保留了全局信息,也让模型更加关注与不同类别之间的微小差异。

3.3.2 对比特征学习
因为简单的交叉熵损失函数不足以完全监督特征学习,因为子类别之间的差异可能非常小。
采用对比损失最小化不同标签对应的分类token的相似度,最大化具有相同标签y的样的分类token的相似度
z:token y:标签 sim():相似性函数

总之,最后的模型是用交叉熵损失和对比损失的综合训练的:(trick:可以用两个损失函数结果的运算来构成一个“新的”损失函数)

4.实验
4.1 不同数据集实验
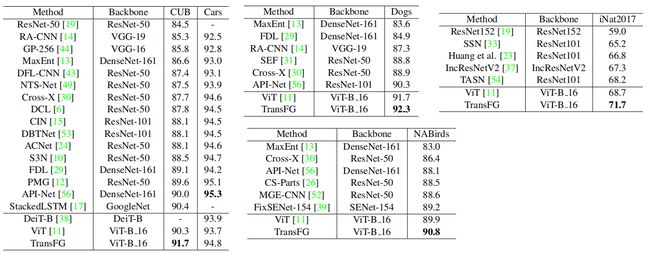
4.2 消融实验
patch重叠的影响:
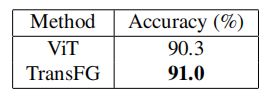
部分选择模块的影响:
对比损失影响:

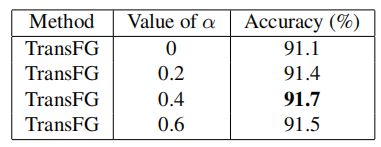
alphaα的影响:
5.总结
本文提出了一种细粒度视觉分类框架 TransFG,取得了最先进的结果。
利用self-attention来捕捉最具辨别力的区域。与其他方法产生的边界框相比,选择的图像块要小得多,因此通过显示哪些区域真正有助于细粒度分类而变得更有意义。
这种小图像块的有效性也来自于 Transformer Layer 来处理这些区域之间的内部关系,而不是依赖它们中的每一个来分别产生结果。
引入对比特征学习以提高分类标记的判别能力。
定性可视化进一步证明了方法的有效性和可解释性。