华为机试——字符串过滤&字符串压缩
//完全原创也不是了,不过这是一个学习的过程。
华为校园招聘的机试题目
一、题目描述:
通过键盘输入一串小写字母(a~z)组成的字符串。请编写一个字符串过滤程序,若字符串中出现多个相同的字符,将非首次出现的字符过滤掉。
比如字符串“abacacde”过滤结果为“abcde”。
要求实现函数:void stringFilter(const char *pInputStr, long lInputLen, char *pOutputStr);
【输入】 pInputStr: 输入字符串
lInputLen: 输入字符串长度
【输出】 pOutputStr: 输出字符串,空间已经开辟好,与输入字符串等长;
【注意】只需要完成该函数功能算法,中间不需要有任何IO的输入输出
示例
输入:“deefd” 输出:“def”
输入:“afafafaf” 输出:“af”
输入:“pppppppp” 输出:“p”
main函数已经隐藏,这里保留给用户的测试入口,在这里测试你的实现函数,可以调用printf打印输出
当前你可以使用其他方法测试,只要保证最终程序能正确执行即可,该函数实现可以任意修改,但是不要改变函数原型。一定要保证编译运行不受影响。
//以下程序有借用前辈的算法。
源程序:
#include
#include
#define N 100
using namespace std;
int main()
{
void stringFilter(const char *pInputStr, long lInputLen, char *pOutputStr);
char a[N],b[N]={0};
cin>>a;
int len;
len=strlen(a);
stringFilter(a,len,b);
cout<<"please output the filtered string:\n";
cout< 运行结果:
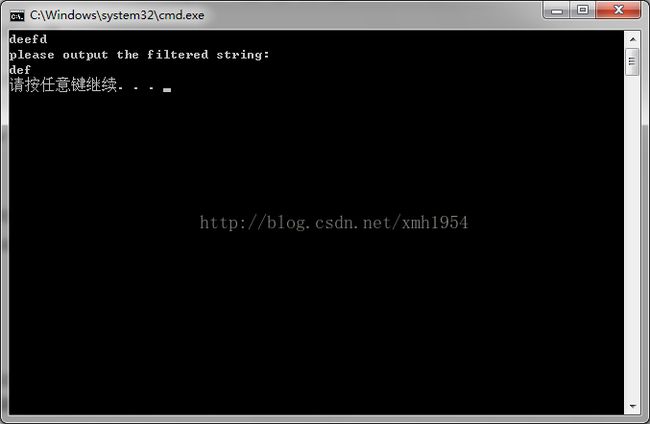
二、题目描述:
通过键盘输入一串小写字母(a~z)组成的字符串。请编写一个字符串压缩程序,将字符串中连续出席的重复字母进行压缩,并输出压缩后的字符串。
压缩规则:
1、仅压缩连续重复出现的字符。比如字符串"abcbc"由于无连续重复字符,压缩后的字符串还是"abcbc"。
2、压缩字段的格式为"字符重复的次数+字符"。例如:字符串"xxxyyyyyyz"压缩后就成为"3x6yz"。
要求实现函数:
void stringZip(const char *pInputStr, long lInputLen, char *pOutputStr);
【输入】 pInputStr: 输入字符串
lInputLen: 输入字符串长度
【输出】 pOutputStr: 输出字符串,空间已经开辟好,与输入字符串等长;
【注意】只需要完成该函数功能算法,中间不需要有任何IO的输入输出
示例
输入:“cccddecc” 输出:“3c2de2c”
输入:“adef” 输出:“adef”
输入:“pppppppp” 输出:“8p”
源程序:
#include
#include
#include
#include
using namespace std;
#define MAXCHAR 256
int main(void)
{
void stringZip(const char* pInputStr , long lInputLen , char* pOutputStr);
char pInputStr2[] = {"aaaaaaaaaabbcddde"};
char pOutputStr2[MAXCHAR] = {0};
stringZip(pInputStr2 , strlen(pInputStr2) , pOutputStr2);
puts(pInputStr2);
puts(pOutputStr2);
return 0;
}
void stringZip(const char* pInputStr , long lInputLen , char* pOutputStr)
{
int i , j , k , num;
char buffer[20];
for(i = 0 , k = 0; i < lInputLen; )
{
num = 0;
for(j = i ; j < lInputLen ; ++j)
{
if(pInputStr[j] == pInputStr[j+1])
//统计字符串中每个字符后面连续出现的重复字母次数
++num;
else
break;
}
if(0 != num) //num可能是两位或三位或更多位的整数
{
memset(buffer , 0 , sizeof(buffer));
itoa(num + 1 , buffer , 10); //将整数按10进制转换为字符串
strcpy(pOutputStr + k , buffer);
//将buffer里面的字符复制到pOutputStr+k里面去。
//buffer数组其实在整个程序运行过程中只用了buffer[0]这一位。超过两位时,错误!!!!
//memset函数每次都把它清零了。
k += strlen(buffer);// k++; //这里应该要k+=strlen(buffer),
/*前辈写的是:k += strlen(buffer);我觉得这里没有必要写成k += strlen(buffer);因为strlen(buffer)恒等于1.所以直接写成k++;*/
//我的这种思想是错误的,当连续重复出现的字符超过10个时,使用k++不能得到正确的结果,所以应该按前辈的来写。
}
pOutputStr[k++] = pInputStr[i];
i = i + num + 1;
}
pOutputStr[k] = '\0';
} 运行结果:
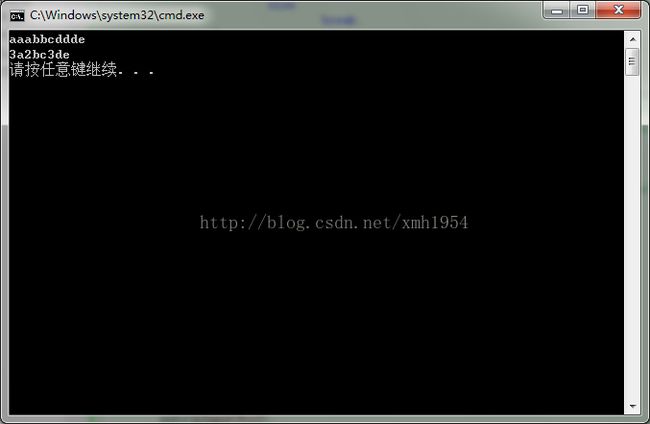

其他:
if(0 != num)
{
memset(buffer , 0 , sizeof(buffer));
itoa(num + 1 , buffer , 10);
strcpy(pOutputStr + k , buffer);
k += strlen(buffer);// k++; //这里应该要k+=strlen(buffer),
}
我最初写程序的时候,没有考虑周全,只考虑的连续重复出现的字符的个数小于10个的情况,误以为使用k++;语句就可以解决问题。这是错误的思想!