mmdetection2的使用教程从数据处理、配置文件到训练与测试(支持coco数据和pascal_voc数据)
本文主要讲述mmdetection的训练与测试,以数据处理为起点,到数据集划分、数据集转换、配置文件编写、模型训练与测试和使用。由于mmdetection2默认的数据格式是coco格式,而labelimg生成的标注文件却是xml(最贴近voc数据),为此以coco数据集为基准。我们可以使用mmdetection中的数据转换方法将pascal_voc数据集转换为coco数据集,从而实现对coco数据和pascal_voc数据的支持。pascal_voc数据集转换为coco数据集前需要注意,一定要先划分数据集(训练集、测试集等)。
1、数据集预处理(仅限于pascal_voc数据)
coco数据不需要进行以下操作,可以直接从第二章节开始。只需要注意以下coco数据路径的配置即可。
1.1 数据集整理
对于自己标注的数据,需要将xml文件全部放到VOC2007/Annotations目录下,将jpg图片放到VOC2007/JPEGImages目录下。具体的目录结构如图1所示。
 图1 pascal voc数据集
图1 pascal voc数据集
使用mmdetection的数据集格式转换方式,需要先将数据集进行划分。可以使用以下代码进行数据集进行划分(代码来自大神Bubbliiiing)。这里需要注意的是需要创建一个voc_classes.txt文件,记录label,VOCdevkit_path 要修改成自己的数据路径。可以将下列代码保存为deal_pascal_vocdata.py,然后在命令行执行 python deal_pascal_vocdata.py
import os
import random
import xml.etree.ElementTree as ET
import numpy as np
def get_classes(classes_path):
with open(classes_path, encoding='utf-8') as f:
class_names = f.readlines()
#class_names = ('chair', 'cow', 'diningtable')
class_names = [c.strip() for c in class_names]
return class_names, len(class_names)
#--------------------------------------------------------------------------------------------------------------------------------#
# annotation_mode用于指定该文件运行时计算的内容
# annotation_mode为0代表整个标签处理过程,包括获得VOCdevkit/VOC2007/ImageSets里面的txt以及训练用的2007_train.txt、2007_val.txt
# annotation_mode为1代表获得VOCdevkit/VOC2007/ImageSets里面的txt
# annotation_mode为2代表获得训练用的2007_train.txt、2007_val.txt
#--------------------------------------------------------------------------------------------------------------------------------#
annotation_mode = 0
#-------------------------------------------------------------------#
# 必须要修改,用于生成2007_train.txt、2007_val.txt的目标信息
# 与训练和预测所用的classes_path一致即可
# 如果生成的2007_train.txt里面没有目标信息
# 那么就是因为classes没有设定正确
# 仅在annotation_mode为0和2的时候有效
#-------------------------------------------------------------------#
classes_path = 'voc_classes.txt'
#--------------------------------------------------------------------------------------------------------------------------------#
# trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1
# train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1
# 仅在annotation_mode为0和1的时候有效
#--------------------------------------------------------------------------------------------------------------------------------#
trainval_percent = 0.9
train_percent = 0.9
#-------------------------------------------------------#
# 指向VOC数据集所在的文件夹
# 默认指向根目录下的VOC数据集
#-------------------------------------------------------#
VOCdevkit_path = 'C:/AI_Dataset/VOCtest_06-Nov-2007/VOCdevkit'
VOCdevkit_sets = [('2007', 'train'), ('2007', 'val')]
classes, _ = get_classes(classes_path)
#-------------------------------------------------------#
# 统计目标数量
#-------------------------------------------------------#,
nums = np.zeros(len(classes))
def convert_annotation(year, image_id, list_file):
in_file = open(os.path.join(VOCdevkit_path, 'VOC%s/Annotations/%s.xml'%(year, image_id)), encoding='utf-8')
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = 0
if obj.find('difficult')!=None:
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
nums[classes.index(cls)] = nums[classes.index(cls)] + 1
if __name__ == "__main__":
random.seed(0)
if annotation_mode == 0 or annotation_mode == 1:
print("Generate txt in ImageSets.")
xmlfilepath = os.path.join(VOCdevkit_path, 'VOC2007/Annotations')
saveBasePath = os.path.join(VOCdevkit_path, 'VOC2007/ImageSets/Main')
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num = len(total_xml)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval= random.sample(list,tv)
train = random.sample(trainval,tr)
print("train and val size",tv)
print("train size",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("Generate txt in ImageSets done.")
if annotation_mode == 0 or annotation_mode == 2:
print("Generate 2007_train.txt and 2007_val.txt for train.")
for year, image_set in VOCdevkit_sets:
image_ids = open(os.path.join(VOCdevkit_path, 'VOC%s/ImageSets/Main/%s.txt'%(year, image_set)), encoding='utf-8').read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w', encoding='utf-8')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg'%(os.path.abspath(VOCdevkit_path), year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
print("Generate 2007_train.txt and 2007_val.txt for train done.")
def printTable(List1, List2):
for i in range(len(List1[0])):
print("|", end=' ')
for j in range(len(List1)):
print(List1[j][i].rjust(int(List2[j])), end=' ')
print("|", end=' ')
print()
str_nums = [str(int(x)) for x in nums]
tableData = [
classes, str_nums
]
colWidths = [0]*len(tableData)
len1 = 0
for i in range(len(tableData)):
for j in range(len(tableData[i])):
if len(tableData[i][j]) > colWidths[i]:
colWidths[i] = len(tableData[i][j])
printTable(tableData, colWidths)
if np.sum(nums) == 0:
print("在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")
print("在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")
print("在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")
print("(重要的事情说三遍)。")
我这里使用的是原始的pascal voc2007数据集,因此我的voc_classes.txt长这样。这个文件的具体内容需要按照自己数据集的实际情况进行修改。
aeroplane
bicycle
bird
boat
bottle
bus
car
cat
chair
cow
diningtable
dog
horse
motorbike
person
pottedplant
sheep
sofa
train
tvmonitor执行代码后的输出如下所示

1.2 数据集格式转换
使用以下代码将pascal voc数据转换为coco数据集(需要进入到mmdetection的目录下,同时要在mmdetection目录下创建data目录,代码中的路径要修改为自己数据的路径)
如果是自己的数据集,则需要修改一下.\tools\dataset_converters\pascal_voc.py中voc_classes的定义,博主此次的数据中只有一个shoot类别,故进行了以下修改(否则会导致生成的coco数据格式有误)
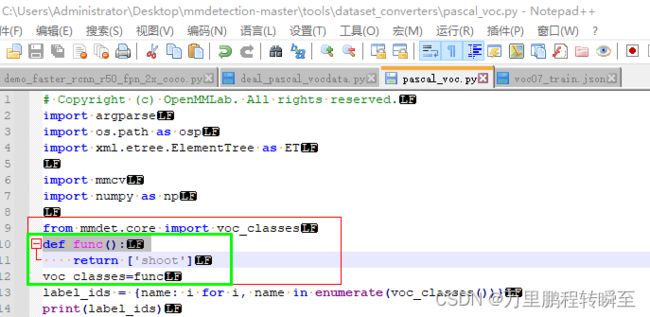
#数据集转换 在目录下创建data文件夹,在目录C:\AI_Dataset\VOCtest_06-Nov-2007\VOCdevkit下必须存在VOC2007或者VOC2012文件夹
python .\tools\dataset_converters\pascal_voc.py C:\AI_Dataset\VOCtest_06-Nov-2007\VOCdevkit --out-dir .\data --out-format coco 代码执行结果如下所示

2、mmdetection的配置
2.1 数据加载器设置
打开mmdetection-master\configs\_base_\datasets|\coco_detection.py进行配置。这里主要是设置data pipeline(指定图像的shape和增强方式)与coco数据的路径。可以不修改,只使用默认值。
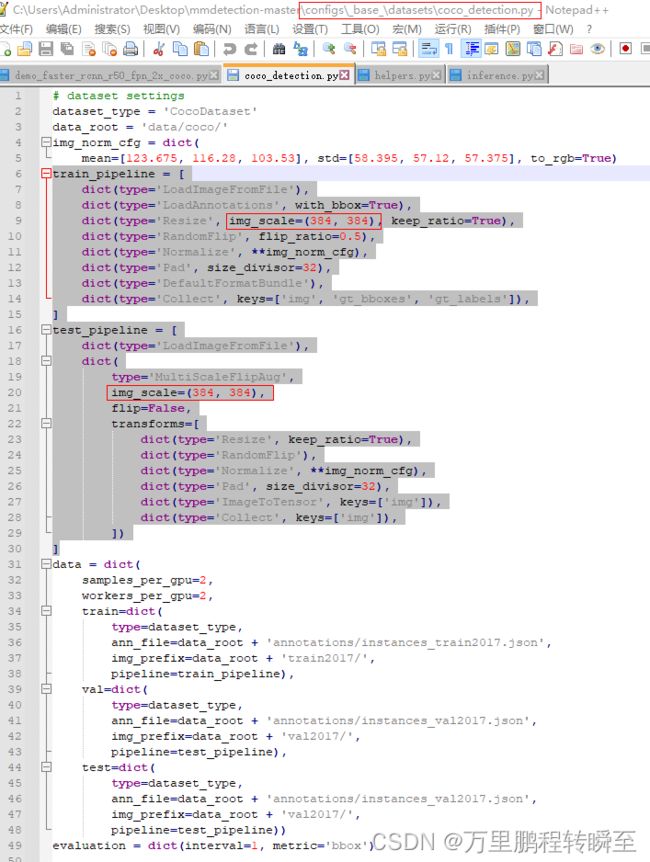
2.2 配置文件设置
这里使用faster_rcnn_r50_fpn_2x_coco.py里的配置进行训练,将下列代码保存为demo_faster_rcnn_r50_fpn_2x_coco.py。
可以参考代码里面的注释修改epoch、classes、batch size、num_worker、optimizer和lr_config,同时还支持加载预训练模型。预训练模型可以到以下地址下载:模型库 — MMDetection 2.25.0 文档
如果是自己的数据集,则需要修改一下classes。同时需要根据自己选用的模型在configs目录下找到py文件的路径赋值给_base_,同时到官网下载预训练模型,并把预训练模型的路径赋值给load_from
# 这个新的配置文件继承自一个原始配置文件,只需要突出必要的修改部分即可
_base_ = './configs/faster_rcnn/faster_rcnn_r50_fpn_2x_coco.py'
#1、 设置训练超参数----------
#修改模型分类数
model = dict(
roi_head=dict(
bbox_head=dict(num_classes=20)))
#要加载的预训练权重
load_from="./work_dirs/faster_rcnn_r50_fpn_1x_coco/epoch_12.pth"
#训练的epcoh数
runner = dict(type='EpochBasedRunner', max_epochs=3)
#验证时的间隔epcoh数(并不是每一个epoch都进行验证)
evaluation = dict(interval=3, metric='bbox')
#2、 修改数据集相关设置----------
#数据集类型
dataset_type = 'COCODataset'
#label值
classes = ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
'tvmonitor')
#3、 训练集与测试集的的预处理------------
#多次测试发现在这里定义的pipeline是无效操作,且发现如果在后续的data中设置pipeline会导致报错
#因此要修改_base_\datasets\下的数据集文件
#4、 设置数据集的路径---------------
data_root="C:\AI_Dataset\VOCtest_06-Nov-2007\VOCdevkit"
data = dict(
samples_per_gpu=4, # batch size
workers_per_gpu=4, # num_workers
train=dict(
img_prefix=data_root,
classes=classes,
ann_file='data/voc07_train.json'),
val=dict(
img_prefix=data_root,
classes=classes,
ann_file='data/voc07_val.json'),
test=dict(
img_prefix=data_root,
classes=classes,
ann_file='data/voc07_test.json'))
#5、 训练策略设置
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# 学习策略
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[7])3、训练与测试
3.1 训练
使用以下代码训练模型,训练过程中的结果文件多会保存到work_dirs目录下,成功运行后会输出loss等信息
python ./tools/train.py ./demo_faster_rcnn_r50_fpn_2x_coco.py

3.3 测试map
测试coco数据集的map代码如下所示,测试数据的可视化结果保存在faster_rcnn_r50_fpn_1x_results目录下,测试结果的文件保存在demo_faster_rcnn_r50_fpn_2x_coco.pkl中。测试的map结果如下图所示
python tools/test.py demo_faster_rcnn_r50_fpn_2x_coco.py work_dirs/demo_faster_rcnn_r50_fpn_2x_coco/epoch_3.pth --eval-options 'classwise=True' --eval bbox proposal --show-dir faster_rcnn_r50_fpn_1x_results --out ./demo_faster_rcnn_r50_fpn_2x_coco.pkl

3.3 测试图片
测试的代码如下所示,只能一次只能测试单个图片。
import mmcv
from mmdet.apis import init_detector, inference_detector,show_result_pyplot
base_root="C:/Users/Administrator/Desktop/mmdetection-master/"
config_file = base_root+'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
# 从 model zoo 下载 checkpoint 并放在 `checkpoints/` 文件下
# 网址为: http://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
checkpoint_file = base_root+'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
device = 'cuda:0'
# 初始化检测器
model = init_detector(config_file, checkpoint_file, device=device)
# 推理演示图像
img='d:/daxiang.jpg'
result=inference_detector(model, img)
#获取可视化结果
#返回一个绘制好标注框的BGR图像
img_result=model.show_result(img,result,score_thr=0.01)
img_result=mmcv.bgr2rgb(img_result)
#直接使用系统工具进行图像展示
show_result_pyplot(model,img,result,score_thr=0.01)
测试结果的解读如下代码所示,result为一个len为classes_num的list对象,其中的每一个元素表示每一类的结果数。结果的shape为(n,5),n表示检测到的结果数, 5表示(x0,y0,x1,y1,score)
import numpy as np
#len(result)->类别数
#result[14].shape->n,5 n为检测出的结果数,5为检测出的结果(格式为x0,y0,x1,y1,score)
np.set_printoptions(suppress=True)#np.around(result[14],3)
print(len(result),result[14].shape,result[0].shape)
print(result) 代码执行结果如下所示