【深入理解Kotlin协程】协程中的Channel和Flow & 协程中的线程安全问题
热数据通道 Channel

Channel 实际上就是 个并发安全的队列,它可以用来连接协程,实现不同协程的通信,代码如代码清单所示
suspend fun testChannel() {
val channel = Channel<Int>()
var i = 0
//生产者 发
val producer = GlobalScope.launch {
while (true) {
delay(1000)
channel.send(i++)
}
}
//消费者 收
val consumer = GlobalScope.launch {
while (true) {
val value = channel.receive()
println("received <<<<<<<<<<<<<<<<<< $value")
}
}
producer.join()
consumer.join()
}
上述代码 构造了两个协程 producer 和 consumer, 没有为它们明确指定调度器,所以它们都是采用默认调度器,在 Java 平台上就是基于线程池实现的 Default。 它们可以运行在不同的线程上,也可以运行在同一个线程上,具体执行流程如图 6-2 所示。

producer 每隔 1s 向 Channel 发送 1 个数,consumer 一直读取 channel 来获取这个数字并打印,显然发送端比接收端更慢,在没有值可以读到的时候, receive 是挂起的,直到有新元素到达。
这么看来,receive 一定是一个挂起函数,那么 send 呢?
你会发现 send 也是挂起函数。发送端为什么会挂起?以我们熟知的 BlockingQueue 为例,当我们往其中添加元素的时候,元素在队列里实际上是占用了空间的,如果这个队列空间不足,那么再往其中添加元素的时候就会出现两种情况:
- 阻塞.等待队列腾出空间
- 异常,拒绝添加元素。
send 也会面临同样的问题, Channel 实际上就是个队列,队列中一定存在缓冲区,那么一旦这个缓冲区满了,并且也一直没有人调用 receive 并取走元素, send 就需要挂起,等待接收者取走数据之后再写入 Channel 。
Channel缓冲区
public fun <E> Channel(
capacity: Int = RENDEZVOUS,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND,
onUndeliveredElement: ((E) -> Unit)? = null
): Channel<E> =
when (capacity) {
RENDEZVOUS -> {
if (onBufferOverflow == BufferOverflow.SUSPEND)
RendezvousChannel(onUndeliveredElement) // an efficient implementation of rendezvous channel
else
ArrayChannel(1, onBufferOverflow, onUndeliveredElement) // support buffer overflow with buffered channel
}
CONFLATED -> {
require(onBufferOverflow == BufferOverflow.SUSPEND) {
"CONFLATED capacity cannot be used with non-default onBufferOverflow"
}
ConflatedChannel(onUndeliveredElement)
}
UNLIMITED -> LinkedListChannel(onUndeliveredElement) // ignores onBufferOverflow: it has buffer, but it never overflows
BUFFERED -> ArrayChannel( // uses default capacity with SUSPEND
if (onBufferOverflow == BufferOverflow.SUSPEND) CHANNEL_DEFAULT_CAPACITY else 1,
onBufferOverflow, onUndeliveredElement
)
else -> {
if (capacity == 1 && onBufferOverflow == BufferOverflow.DROP_OLDEST)
ConflatedChannel(onUndeliveredElement) // conflated implementation is more efficient but appears to work in the same way
else
ArrayChannel(capacity, onBufferOverflow, onUndeliveredElement)
}
}
我们构造 Channel 的时候调用了一个名为 Channel 的函数,虽然两个 “Channel" 起来是 样的,但它却确实不是 Channel 的构造函数。在 Kotlin 中我们经常定义 一个顶级函数来伪装成同名类型的构造器,这本质上就是工厂函数。Channel 函数有一个参数叫 capacity, 该参数用于指定缓冲区的容量,RENDEZVOUS 默认值为 0,RENDEZVOUS 本意就是描述“不见不散"的场景, 如果不调用 receive, send 就会一直挂起等待。如果把上面代码中consumer的channel.receive()注释掉,则producer中send方法第一次调用就会挂起。

- Channel(Channel.RENDEZVOUS ) 的方式是有人接收才会继续发,边收边发,如果没有接受的,则发送者会挂起等待。
- Channel(Channel.UNLIMITED ) 的方式是发送者发送完毕,就直接返回,不管有没有接受者。
- Channel(Channel.CONFLATED ) 的方式是不管发送者发了多少个,接受者只能收到最后一个,也是发送完就返回了,不管有没有接受者。
- Channel(Channel.BUFFERED ) 的方式也是发送者发送完就返回了,不管有没有接受者,可以指定buffer大小。
- Channel(1) 的方式指定管道的容量大小,如果数据超过容量,发送者就会挂起等待,直到有接受者取走数据,发送者才发送下一批数据。
Channel的迭代

Channel可以通过迭代器迭代访问:
GlobalScope.launch {
val iterator = channel.iterator()
while (iterator.hasNext()) { // 挂起点
println("received <<<<<<<<<<<<<<<<<< ${iterator.next()}")
}
}
其中,iterator.hasNext() 是挂起函数,在判断是否有下个元素的时候就需要去Channel 中读取元素了,这个写法自然可以简化成 for-in。
GlobalScope.launch {
for (element in channel) {
println("received <<<<<<<<<<<<<<<<<< $element")
}
}
生产者和消费者协程构造器

我们可以通过 produce 方法启动一个生产者协程,并返回 ReceiveChannel,其他协程就可以用这个 Channel 来接收数据了。反过来,我们可以用 actor 启动一个消费者协程。
suspend fun producer() {
val receiveChannel = GlobalScope.produce {
for (i in 0..3) {
send(i)
println("send --------------> $i")
}
}
val consumer = GlobalScope.launch {
for (i in receiveChannel) {
println("received <<<<<<<<<<<<<<<< $i")
}
}
consumer.join()
}
suspend fun consumer() {
val sendChannel = GlobalScope.actor<Int> {
for (i in this) {
println("received <<<<<<<<<<<<<<<< $i")
}
}
val producer = GlobalScope.launch {
for (i in 0..3) {
sendChannel.send(i)
println("send --------------> $i")
}
}
producer.join()
}
使用这两种构造器也可以指定Channel对应的缓冲区类型,如:
val receiveChannel = GlobalScope.produce(capacity = Channel.UNLIMITED) {
for (i in 0..3) {
send(i)
}
}
ReceiveChannel SendChannel 都是 Channel 的父接口,前者定义了 receive, 后者定义了 send, Channel 也因此既可以使用 receive 又可以使用 send。
通过 produce 和 actor 这两个协程构造器启动的协程也与返回的 Channel 自然地绑定到了一起,因此在协程结束时返回的 Channel 也会被立即关闭。
以 produce 为例,它构造出了一个 ProducerCoroutine 对象,该对象也是 Job 的实现:
private class ProducerCoroutine<E>(
parentContext: CoroutineContext, channel: Channel<E>
) : ChannelCoroutine<E>(parentContext, channel, true, active = true), ProducerScope<E> {
override val isActive: Boolean
get() = super.isActive
override fun onCompleted(value: Unit) {
_channel.close() // 协程完成时关闭channel
}
override fun onCancelled(cause: Throwable, handled: Boolean) {
val processed = _channel.close(cause) // 协程取消时关闭channel
if (!processed && !handled) handleCoroutineException(context, cause)
}
}
注意,在协程完成和取消的方法调用 中, 对应的_channel 都会被关闭。produc actor 这两个构造器看上去都很有用,不过目前前者仍被标记为 Experimental CoroutinesApi, 后者则被标记为 ObsoleteCoroutinesApi, 后续仍然可能会有较大的改动。
Channel的关闭
对千一个 Channel 如果我们调用了它的 close() 方法,它会立即停止接收新元素,也就是说这时候它的 isClosedForSend 会立即返回 true 而由于 Channel 缓冲区的存在, 这时候可能还有一些元素没有被处理完,因此要等所有的元素都被读取之后 isClosedForReceive 才会返回 true。
一说到关闭,我们很容易想到 I/0, 如果不关闭 1/0 可能会造成资源泄露。那么 Channel 关闭有什么意义呢?前面我们提到过,Channel 内部的资源其实就是个缓冲区,如果我们创建 Channel 而不去关闭它。虽然并不会造成系统资源的泄露,但却会让接收端一直处千挂起等待的状态,因此一定要在适当的时机关闭 Channel。
究竟由谁来关闭Channel,需要根据业务场景由发送端和接受端之间进行协商决定。如果发送端关闭了Channel,接受端还在调用receive方法,会导致异常,这时就需要进行异常处理:
suspend fun testChannel2() {
val channel = Channel<Int>()
//生产者 发
val producer = GlobalScope.launch {
for (i in 0..3) {
println("sending --------------> $i")
channel.send(i)
}
channel.close() // 发送端关闭channel
}
//消费者 收
val consumer = GlobalScope.launch {
try {
while (true) {
val value = channel.receive()
// val value = channel.receiveCatching() // 这个方法不会抛出异常
println("received <<<<<<<<<<<<<<<<<< $value")
}
} catch (e : ClosedReceiveChannelException) {
println("catch ClosedReceiveChannelException: ${e.message}")
}
}
producer.join()
consumer.join()
}
发送端关闭了Channel,接受端还在调用receive方法,会抛出ClosedReceiveChannelException异常,如果使用receiveCatching()遇到close时就不会抛出异常,但是会使用null作为返回结果。
BroadcastChannel


创建 broadcastCbannel 的方法与创建普通的 Channel 几乎没有区别:
val broadcastChannel = broadcastChannel<Int>(5)
如果要订阅功能,那么只 要调用如下方法
val receiveChannel = broadcastChannel.openSubscription()
这样我们就得到了一个 ReceiveChannel,如果想要想获取订阅的消息,只需要调用它的 receive 函数;如果想要取消订阅则调用 cancel 函数即可。
我们来看一个比较完整的例子,本示例中我们在发送端发 0 1 2, 并启动 3个协程同时接收广播,相关代码如下所示。
suspend fun broadcast() {
//下面几种都可以创建一个BroadcastChannel
//val broadcastChannel = BroadcastChannel(Channel.BUFFERED)
//val broadcastChannel = Channel(Channel.BUFFERED).broadcast()
val broadcastChannel = GlobalScope.broadcast {
for (i in 0..2) {
send(i)
}
}
//启动3个子协程作为接受者,每个都能收到
List(3) { index ->
GlobalScope.launch {
val receiveChannel = broadcastChannel.openSubscription() // 订阅
for (i in receiveChannel) {
println("[#$index] received: $i")
}
}
}.joinAll()
}
除了直接创建以外,我们也可以用前面定义的普通 Channel 进行转换,代码如下所示。
// 通过 Channel 实例直接创建广播
val channel = Channel<Int>()
val broadcastChannel = channel.broadcast()
Channel 版本的序列生成器
// 使用channel模拟序列生成器
val channel = GlobalScope.produce {
println("A")
send(1)
println("B")
send(2)
println("Done")
}
for (item in channel) {
println("get $item")
}
冷数据流Flow
Sequence中不能调用其他挂起函数,不能设置调度器,只能单线程中使用。而Flow可以支持:
// 序列生成器中不能调用其他挂起函数
sequence {
(1..3).forEach {
yield(it)
delay(100) // ERROR
}
}

创建Flow
val intFlow = flow {
(1..3).forEach {
emit(it)
delay(100)
}
}
Flow 也可以设定它运行时所使用的调度器:
intFlow.flowDn(Dispatchers.IO)
通过 flowOn 设置的调度器只对它之前的操作有影响,因此这里意味着 intFlow 的构造逻辑会在 IO 调度器上执行。

最终读取 intFlow 需要调用 collect 函数, 这个函数也是一个挂起函数。我们启动一个协程来消费 intFlow, 代码如下所示
suspend fun testFlows(){
val dispatcher = Executors.newSingleThreadExecutor {
Thread(it, "MyThread").also { it.isDaemon = true }
}.asCoroutineDispatcher()
GlobalScope.launch(dispatcher) {
val intFlow = flow {
(1..3).forEach {
emit(it)
println("${Thread.currentThread().name}: emit $it")
delay(1000)
}
}
intFlow.flowOn(Dispatchers.IO)
.collect {
println("${Thread.currentThread().name}: collect $it")
}
}.join()
}
为了方便区分,我们为协程设置了一个自定义的调度器,它会将协程调度到名叫 MyThread 的线程上,结果如下:

也就是说,collect中的代码运行在Global.launch指定的调度器上,flow{…} 中的代码运行在 flowOn 指定的调度器上。

对比 RxJava 的线程切换
RxJava 也是 个基千响应式编程模型的异步框架,它提供了两个切换调度器的 API, 分别是 subscribeOn observeOn, 其中 subscribeOn 指定的调度器执行被观察者的代码, observeOn 指定调度器运行观察者的代码,观察者最后在observeOn 指定调度器上收集结果。flowOn 就相当于subscribeOn,而 launch的调度器 就相当于 observeOn 指定的调度器。

在一个 Flow 创建出来之后,不消费则不生产,多次消费则多次生产,生产和消费总是相对应的,代码如下所示。
GlobalScope.launch(dispatcher) {
val intFlow = flow {
(1..3).forEach {
emit(it)
delay(1000)
}
}
// Flow 可以被重复消费
intFlow.collect { println(it) }
intFlow.collect { println(it) }
}.join()
消费它会输出 “1, 2, 3", 重复消费它会重复输出“1, 2, 3"。
这一点类似于我们前面提到的序列生成器和 RxJava 的例子,它们也都有自己的消费端。我们创建序列后去迭代它,每次迭代都会创建一个新的迭代器从头开始迭代RxJava Observable 也是如此,每次调用它的 subscribe 都会重新消费一次。
所谓冷数据流,就是只有消费时才会生 的数据流,这一点 Channel 正好相反,Channel 发送端并不依赖于接收端。
异常处理
Flow 的异常处理也比较 接,直接调用 catch 函数即可,如下所示。

如果想要在 Flow 完成时执行逻辑,可以使用 onCompletion,onCompletion 用起来类似于 try… catch… finally 中的 finally, 无论前面是否存在异常,它都会被调用,参数 t 则是前面未捕获的异常。
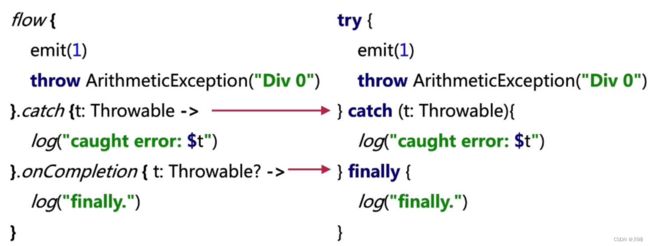
这套处理机制的设计初衷是确保 Flow 操作中异常的透明。因此,直接使用 try - catch - finally 的写法是违反 Flow 的设计原则的。
suspend fun exception(){
flow<Int> {
emit(1)
throw ArithmeticException("Div 0")
}.catch {t: Throwable ->
log("caught error: $t")
}.onCompletion { t: Throwable? ->
log("finally.")
}.flowOn(Dispatchers.IO)
.collect { log(it) }
// 不推荐直接使用 try - catch - finally 写法
// flow { // bad!!!
// try {
// emit(1)
// throw ArithmeticException("Div 0")
// } catch (t: Throwable){
// log("caught error: $t")
// } finally {
// log("finally.")
// }
// }
}
我们在 Flow 操作内部使用 try… catch. … finally, 这样的写法后续可能会被禁用。
// Flow 从异常中恢复
flow {
emit(1)
throw ArithmeticException("divide 0")
}.catch { t : Throwable ->
println("caught error $t")
emit(10)
}
这里我们可以使用 emit 重新生产新元素。细 心的读者一定会发现, emit 定义在 FlowCollector 中,因此只要遇到 Receiver 为 FlowCollector 的函数,我们就可以生产新元素。
Flow中的常用操作符
Flow中的map操作符:
GlobalScope.launch {
flow {
List(5) {
emit(it)
}
}.map {
it * it
}.collect {
println(it)
}
}.join()
输出:
0
1
4
9
16
Flow中的Fliter操作符:
GlobalScope.launch {
val flow = (1..10).asFlow()
flow.filter {
it % 2 == 0
}.collect {
println(it)
}
}.join()
输出:
2
4
6
8
10
filter会将满足指定条件为true的数据保留下来。
Flow中的onEach操作符:
GlobalScope.launch {
(1..5).asFlow()
.onEach {
println(it)
}.collect {
println(it)
}
}.join()
可以在onEach中访问到流中发射的每一个数据。
Flow中的count操作符:
GlobalScope.launch {
val flow = (1..10).asFlow()
val count = flow.count {
it % 2 == 0
}
println("count: $count")
}.join()
输出:
count: 5
count操作符主要用来计数统计,count的返回值是Int,因此它后面不能继续再跟其他操作符了。
Flow中的reduce操作符:
GlobalScope.launch {
val sum = (1..10).asFlow().reduce { accumulator, value ->
accumulator + value // 这句相当于每次执行 accumulator = accumulator + value
}
println("sum: $sum")
}.join()
输出:
sum: 55
reduce操作符主要用来进行数学计算,上面是计算累加1到10的结果。
Flow中的fold操作符:
GlobalScope.launch {
val sum = (1..10).asFlow()
.fold(100) { acc, value ->
acc + value
}
println("sum: $sum")
}.join()
输出:
sum: 155
fold跟reduce功能类似,提供一个初始值。
Flow中的take限长操作符:
GlobalScope.launch {
(1..10).asFlow().take(5).collect {
println("$it")
}
}.join()
很简单,就是取前5个数据。类似操作符的还有takeWhile:
GlobalScope.launch {
(1..10).asFlow().takeWhile {
it < 5
}.collect {
println("$it")
}
}.join()
会输出前4个数据,注意这里takeWhile中的判断有点讲究,如果你把上面的 it < 5 改成 it > 5 不会有输出,因为它是遇到第一个不符合条件的就停止了。同样改成 it % 2 == 0 不会有输出,而改成it % 2 == 0只会输出1。
Flow中的zip操作符:
GlobalScope.launch {
val flow1 = (1..10).asFlow().onEach { delay(1000L) }
val flow2 = ('a'..'z').asFlow().onEach { delay(300L) }
flow1.zip(flow2) { number, char ->
println("($number, $char)")
}.collect()
}.join()
这里创建了两个Flow,第一个Flow中每个数据发射后延时1s,第二个Flow中每个数据发射后延时300ms,因此第二个流发射速度比第一个快,zip操作符在压缩时,会等待两个流中的数据都到达后,才会执行后面大括号里的压缩操作,因此发射快的流会等待发射慢的流,这里会看到每隔1s输出一个数据。
输出:
(1, a)
(2, b)
(3, c)
(4, d)
(5, e)
(6, f)
(7, g)
(8, h)
(9, i)
(10, j)
Flow中的merge操作符:
GlobalScope.launch {
val flow1 = (1..10).asFlow().onEach { delay(1000L) }
val flow2 = ('a'..'z').asFlow().onEach { delay(500L) }
(flow1, flow2).collect {
println("$it")
}
}.join()
输出:
a
1
b
c
2
d
e
3
f
g
4
.
.
.
merge操作符中快流不会等待慢流,它们是按时间先后顺序输出的,因此你看到上面每隔1个数字中间会有2个字母输出。
Flow中的transform操作符:
GlobalScope.launch {
(1..3).asFlow().transform { id ->
emit("Making request: $id")
emit(performRequest(id))
}.collect {
println(it)
}
}.join()
// 模拟网络请求
suspend fun performRequest(id: Int) : String {
delay(1000L)
return "Response by Id: $id"
}
输出:
Making request: 1
Response by Id: 1
Making request: 2
Response by Id: 2
Making request: 3
Response by Id: 3
Flow中的展平流操作符:
flattenConcat操作符:
GlobalScope.launch {
val flow = (1..3).asFlow()
flow.map {
flow { emit(it + 1000) }
}.flattenConcat()
.collect {
println(it)
}
}.join()
输出:
1001
1002
1003
上面代码实际上我们得到的是一个数据类型为 Flow 的 Flow, 即Flow也就是二维的Flow,如果不使用 flattenConcat, 那么在 collect 中得到的 it 实际上是一个Flow。
拼接的操作中, flattenConcat 是按顺序拼接的,结果的顺序仍然是生产时的顺序。此外,我们还可以使用 flattenMerge 行会并发拼接,但得到的结果不会保证顺序与生产是一致。
flatMapConcat操作符:
GlobalScope.launch {
val flow = (1..3).asFlow()
flow.flatMapConcat {
flow {
emit(it + 1)
delay(1000)
}
}.collect {
println(it)
}
}.join()
输出:
2
3
4
flatMapConcat跟flattenConcat操作符差不多,将map操作移到了大括号里面了。与flatMapConcat类似的也有flatMapMerge操作符,它也是并发顺序的。
这种展平操作符在实际业务中有什么使用场景呢?比如,我在本地数据库缓存了一些商品信息的选项,同时在展示的时候又需要从网络中获取服务器上的这些商品菜单的打折信息(动态变化),而本地的查询一般是比远程的网络请求快的,因此我们可以先在查询本地得到的第一个Flow中发射本地数据,而后在网络请求完成创建的第二个Flow中,在本地查询的结果之上添加一些折扣信息,然后将这些数据重新emit发射出去,这样再次返回的是一个包装的Flow作为最终的返回结果。在UI界面使用时我们想获得商品打折信息肯定是拿最里面的Flow中的数据,这时使用展平操作符即可。
末端操作符
前面的例子中,我们用 collect 消费 flow 的数据 collect 是最基本的末端操作符,功能与 RxJava 的 subscribe 类似。
除了 collect 之外,还有其他常见的末端操作符,它们大体分为两类:
- 集合类型转换操作符,包括 toList toSet
- 聚合操作符,包括将 flow 规约到单值的 reduce、fold 等操作;还有获得单个元素的操作符,包括 sing、singleOrNull、first 等。
实际上,识别是否为末端操作符 ,还有一个简单方法 :由于 Flow 的消费端一定需要运行在协程中 ,因此末端操作符都是挂起函数。
分离 Flow 的消费和触发
我们除了可以在 collect 处消费 Flow 的元素以外,还可以通过 onEach 来做到这一点。这样消费的具体操作就不需要与末端操作符放到一起, collect 函数可以放到其他任意位置调用,例如代码如下所示。
// 分类 Flow 的消费和触发
fun createFlow() = flow<Int> {
(1..3).forEach {
emit(it)
delay(100)
}
}.onEach { println(it) }
fun main() {
GlobalScope.launch {
createFlow().collect()
}
}
由此,我们又可以衍生出一种新的消费 Flow 的写法,代码如下所示。
fun main() {
// 使用协程作用域直接触发 Flow
createFlow().launchIn(GlobalScope)
}
其中, launchln 函数只接收 CoroutineScope 类型的参数。
Flow的取消

Flow 没有提供取消操作的方法,因为并不需要。
我们前面已经介绍了 Flow 的消费依赖于 collect 这样的末端操作符,而它们又必须在协程中调用,因此 Flow 的取消主要依赖于末端操作符所在的协程的状态。
也就是说, 要取消Flow只需要取消 flow.collect { } 所在的协程即可。
Flow 取消相关代码如下所示
// Flow 的取消
val job = GlobalScope.launch {
val intFlow = flow {
(1..3).forEach {
delay(1000)
emit(it)
}
}
intFlow.collect {
println(it)
}
}
delay(2500)
job.cancelAndJoin()
channelFlow
我们已经知道了 flow{…} 这种形式的创建方式,不过在这当中无法随意切换调度器,这是因为 emit 函数非线程安全的,代码如下所示是错误示例。
// 不能在 flow 中直接切换调度器
flow { // BAD !!
emit(1)
withContext(Dispatchers.IO) {
emit(2)
}
}
想要在生成元素时切换调度器,就必须使用 channelFlow 函数来创建 Flow:
channelFlow {
send(1)
withContext(Dispatchers.IO) {
send(2)
}
}
或者:
val channel = Channel<Int>()
channel.consumeAsFlow()
其他Flow的创建方式
此外,我们也可以通过集合框架来创建 Flow:
listOf(1, 2, 3, 4).asFlow()
setOf(1, 2, 3, 4).asFlow()
(1..5).asFlow()
flowOf(1, 2, 3, 4)
Flow的背压

只要是响应式编程,就一定会有背压问题,先来看看背压究竟是什么。背压问题在生产者的生产速率高于消费者的处理速率的情况下出现。为了保证数据不丢失,我们也会考虑添加缓冲来缓解背压问题,如下代码所示
// 为 Flow 添加缓冲
flow{
List(100) {
emit(it)
}
}.buffer()
我们也可以为 buffer 指定一个容量。不过,如果只是单纯地添加缓冲,而不是根本上决问题,就会造成数据积压。
出现背压问题的根本原因是生产和消费速率不匹配,此时除可直接优化消费者的性能以外 ,还可以采取一些取舍手段。
第一种是 conflate 。与 Channel 的 Conflate 模式一致,新数据会覆盖老数据,例如下代码所示
// 使用 conflate 解决背压问题
flow {
List(100) {
emit(it)
}
}.conflate()
.collect() {
println("colleting $it")
delay(100)
println("$it collected")
}
我们快速发送了 100 个元素,最后接收到的只有 2 个,当然这个结果不一定每次都一样:

第二种是 collectLatest 顾名思义,其只处理最新的数据 这看上去似乎与 conflate 没有区别,其实区别很大:collectLatest 并不会直接用新数据覆盖老数据,而是每一个数据都会被处理,只不过如果前一个还没被处理完后一个就来了的话,处理前一个数据的逻辑就会被取消。
// 使用 collectLatest 解决背压问题
suspend fun backPressure(){
flow {
emit(1)
delay(50)
emit(2)
}.collectLatest { value ->
println("Collecting $value")
delay(100) // Emulate work
println("$value collected")
}
}
运行结果如下:
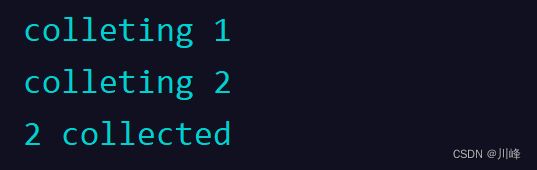
上面的例子collectLatest当中100毫秒之后只能接受到2,因为延时100的过程中发送2的时候会把1取消掉。
collectLatest 在实际业务中应用是什么呢?比如我的UI界面可能会不停的从服务器后台获取数据,那么我只想要展示最新的数据,这时就可以使用 collectLatest。
Select 多路复用
在 UNIX 的 IO 多路复用中,我们应该都接触过 select, 其实在协程中,select 的作用也与在 UNIX 中类似。
复用多个await
我们前面已经接触过很多挂起函数,如果有这样一个场景,两个 API 分别从网络和本地缓存获取数据,期望哪个先返回就先用哪个做展示,实现代码如下代码所示。
// 网络获取用户信息
fun CoroutineScope.getUserFromApi(name: String) = async(Dispatchers.IO) {
githubApi.getUserSuspend(name)
}
// 本地获取用户信息
fun CoroutineScope.getUserFromLocal(name: String) = async(Dispatchers.IO) {
File(localDir, name).takeIf { it.exists()}
?.readText()
?.let {
gson.fromGson(it, Uset::class.java)
}
}
不管先调用哪个 API, 返回的 Deferred 的 await 都会被挂起,最终得到的结果可能并不是最先返回的,这不符合预期。当然,我们也可以启动两个协程来分别调用 await,不过这样会将问题复杂化。
接下来我们用 select 来解决这个问题,具体代码如下代码所示。
// 使用 select 复用 await
GlobalScope.launch {
val name ="xxx"
val localDeffered = getUserFromLocal(name)
val remoteDeffered = getUserFromApi(name)
val useResponse = select<Response<User?>> {
localDeffered.onAwait{ Response(it, true) }
remoteDeffered.onAwait{ Response(it, false) }
}
...
}.join()
可以看到,我们没有直接调用 await, 是调用了 onAwait 在 select 中注册了回调,select 总是会立即调用最先返回的事件的回调。如图 6-6 示,假设 localDeferred.onAwait 先返回,那么 userResponse 的值就是 Response(it, true) ,由于我们的本地缓存可能不存在,因此 select 的结果类型是 Response
对千这个案例,如果先返回的是本地缓存,那么我们还需要获取网络结果来展示最终结果,完整代码如下所示。
val localDir = File("localCache").also { it.mkdirs() }
val gson = Gson()
// 网络获取用户信息
fun CoroutineScope.getUserFromApi(login: String) = async(Dispatchers.IO){
gitHubServiceApi.getUserSuspend(login)
}
// 本地获取用户信息
fun CoroutineScope.getUserFromLocal(login:String) = async(Dispatchers.IO){
File(localDir, login).takeIf { it.exists() }?.readText()?.let { gson.fromJson(it, User::class.java) }
}
fun cacheUser(login: String, user: User){
File(localDir, login).writeText(gson.toJson(user))
}
data class Response<T>(val value: T, val isLocal: Boolean)
suspend fun main() {
val login = "test"
GlobalScope.launch {
val localDeferred = getUserFromLocal(login)
val remoteDeferred = getUserFromApi(login)
//select选择优先返回的结果
val userResponse = select<Response<User?>> {
localDeferred.onAwait { Response(it, true) }
remoteDeferred.onAwait { Response(it, false) }
}
userResponse.value?.let { println(it) } //获取结果显示 输出
//如果是本地的结果,重新请求,并缓存本地
userResponse.isLocal.takeIf { it }?.let {
val userFromApi = remoteDeferred.await()
cacheUser(login, userFromApi)
println(userFromApi)
}
}.join()
}
复用多个channel
val channels = List(10) {Channel<Int>()}
GlobalScope.launch {
delay(100)
channels[Random.nextInt(10)].send(200)
}
val result = select<Int?> {
channels.forEach { channel ->
channel.onReceive { it }
}
}
println(result)
对于 onRceceive, 如果 Channel 被关闭, select 会直接抛出异常 ;如果不希望抛出异常,可以使用 onReceiveCatching。
SelectClause
我们怎么知道哪些事件可以被 select 呢?其实所有能够被 select 的事件都是 SelectClauseN 类型,包括:
- SelectClause0:对应事件没有返回值,例如 join 没有返回值,那么 onJoin 就是 SelectClauseN 类型 使用时, onJoin 参数是 个无参函数,如下所示。
// 复用无参数的join
select<Unit> {
job.onJoin(){ println("Join resumed!")}
}
- SelectClause1: 对应事件有返回值,前面的 onAwait 和 onReceive 都是此类情况
- SelectClause2:对应事件有返回值,此外还需要一个额外的参数,例如 channel.onSend 有两个参数,第一个是 Channel 数据类型的值,表示即将发送的值;第二个是发送成功时的回调参数。相关代码如下所示。
// 复用两个参数的send
List(100){ element ->
select<Unit> {
channels.forEach { channel ->
channel.onSend(element) { sentChannel ->
println("sent on $sentChannel")
}
}
}
}
onSend 的第 个参数的 sentChannel 表示数据成功发送到的 Channel 对象。因此,如果大家想要确认挂起函数是否支持 select 只需要查看其是否存在对应的 SelectC!auseN 类型可回调即可。
另外官方的源码注释中也为我们列出了目前支持Select语法的挂起函数:

使用 Flow 实现多路复用

在代码清单 6-59 中,① 处建了由两个函数引用组成的 List; ② 处调用这两个函数得到deferred; ③ 处比较关键,对于每一个 deferred 我们创建一个单独的 Flow, 并在 Flow 内部发送 deferred. await( )返回的结果,即返回的 User 象。现在有了两个 Flow 实例,我们需要将它们整合成一个 Flow 进行处理,此时调用 merge 函数即可,如图 6-7 所示。

同样, channel 读取复用的场景也可以使用 Flow 来完成:
// 使用 Flow 实现对 Channel 的复用
val channels = List(10) {Channel<Int>()}
...
val result = channels.map {
it.consumeAsFlow()
}
.merge()
.first()
这比使用 select 实现的版本看上去要更简洁明了,每个 channel 都通过 consumeAsFlow 函数被映射成 Flow 再组合成 Flow, 取第一个元素。
StateFlow和SharedFlow
StateFlow和SharedFlow与Flow的区别:
- Flow是冷流:有人执行collect,它的emit才会执行发射数据,如果没有人collect,它就不会emit。
- StateFlow和SharedFlow是热流:当它的数据发生变化或者emit被调用时,collect接受方会自动收到数据,类似于订阅模式。在垃圾回收之前,都是存在内存之中,并且处于活跃状态。
- 普通的flow中emit函数可以发射多个不同类型的数据,但是StateFlow和SharedFlow只能发射同一数据类型单个值,它们是带有泛型参数的接口。
StateFlow
StateFlow是一个状态容器式可观察数据流,可以向收集器发出当前状态更新和新状态更新。还可通过其value属性读取当前状态值。
在界面中对StateFlow的value进行修改时, 它的collect会自动触发,例如一个简单的计数器的例子,代码如下
class NumberViewModel : ViewModel() {
val number = MutableStateFlow(0)
fun increment() {
number.value++
}
fun decrement() {
number.value--
}
}
在UI界面中使用:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
...
addBtn.setOnClickListener {
viewModel.increment()
}
minusBtn.setOnClickListener {
viewModel.decrement()
}
lifecycleScope.launchWhenCreated {
viewModel.number.collect { value ->
tvNumber.text = "$value"
}
}
}

使用StateFlow基本可以替代MVVM中的LiveData,而在Google最新推出的Compose UI中使用它更加简单,不需要自己显示的调用collect函数,通过StateFlow的扩展方法collectAsState就可以轻松使用,代码如下:
class StateFlowUseActivity: ComponentActivity() {
private val viewModel = NumberViewModel()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
Surface(color = MaterialTheme.colorScheme.background) {
Column(horizontalAlignment = Alignment.CenterHorizontally) {
Row(horizontalArrangement = Arrangement.Center,
modifier = Modifier.fillMaxWidth()
) {
Button( onClick = { viewModel.increment() },) {
Text("增加")
}
Button( onClick = { viewModel.decrement() },) {
Text("减少")
}
}
val uiState by viewModel.uiState.collectAsState()
Text(text = "$uiState")
}
}
}
}
}
class NumberViewModel : ViewModel() {
private val number = MutableStateFlow(0)
val uiState : StateFlow<Int> = number.asStateFlow()
fun increment() {
number.value++
}
fun decrement() {
number.value--
}
}
如果是在Compose中使用collectAsState,Google最近推出了一个相对更加安全且性能更高的Api 它就是 collectAsStateWithLifecycle。
那么 collectAsStateWithLifecycle 这个 Api 和 collectAsState 有什么区别呢?
collectAsState 和 collectAsStateWithLifecycle 在 Compose 中各有用途。
- collectAsStateWithLifecycle主要用于开发 Android 应用,而 collectAsState 可用于在其他平台进行开发(Compose目前支持跨平台)。
- 在 Android 应用中使用 Compose 时,Android 生命周期会对资源的管理方式产生非常大的影响。即使 Compose 在 Android 应用处于后台时停止重组,collectAsState 也会继续收集数据流。这使得层次结构的其余部分无法释放资源。 让不必要的资源保持活跃可能会产生负面影响。在界面层中使用 collectAsStateWithLifecycle 可以让层次结构的其余部分得以释放资源。
- ViewModel 可以通过以收集器感知的方式生成界面状态来完成相同的操作。如果没有收集器,例如当界面在屏幕上不可见时,则停止收集来自数据层的上游数据流。
collectAsStateWithLifecycle 在实现机制上使用了 repeatOnLifecycle API,不过截止本文发布时collectAsStateWithLifecycle目前仍然是一个ExperimentalLifecycleComposeApi,如需了解更多,请参考这个链接:在 Jetpack Compose 中安全地使用数据流 ,使用sample请参考:nowinandroid
上面提到在Compose 的项目中StateFlow可以使用collectAsState或者collectAsStateWithLifecycle这样的api,那么如果在传统xml布局的项目中,也想要这个功能该怎么办呢,可以仿照collectAsStateWithLifecycle写一个扩展方法:
fun <T> LifecycleOwner.collectLifecycleFlow(flow: Flow<T>, collect: suspend (T) -> Unit) {
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
flow.collect(collect)
// flow.collectLatest(collect) // collect Latest Flow if you need
}
}
}
使用:
class MyActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
/* ... */
collectLifecycleFlow(viewModel.stateFlow) { uiState ->
updateUi(uiState)
}
}
}
当生命周期至少为STARTED时,在协程中运行代码块。当ON_STOP事件发生时,协程将被取消,如果生命周期再次接收到ON_START事件,协程将重新开始执行,即有效期被限定在 [ON_START, ON_STOP ] 之间。
StateFlow结合combine操作符使用
class FlowExampleViewModel: ViewModel() {
// 用户信息
data class User(val userName : String? = null,
val description: String? = null,
val profilePicUrl : String? = null)
// 用户的发帖信息
data class Post(val imageUrl : String? = null,
val userName: String? = null,
val description : String? = null)
// 发帖状态
data class ProfileState(
val profilePicUrl : String? = null,
val userName : String? = null,
val description: String? = null,
val posts: List<Post> = emptyList() // 发帖列表
)
private val isAuthenticated = MutableStateFlow(true) // 是否登录
private val user = MutableStateFlow<User?>(null) // 用户信息
private val posts = MutableStateFlow(emptyList<Post>()) // 帖子列表
private val _profileState = MutableStateFlow<ProfileState?>(null) // 私有使用
val profileState = _profileState.asStateFlow() // 给外部使用
init {
// combine操作符结合两个流,其中有一个流发射数据变化就会触发{}中的代码块执行
isAuthenticated.combine(user) { isAuthenticated, user ->
if (isAuthenticated) user else null // 已经登录就返回用户信息,否则返回空
}.combine(posts) { user, posts ->
// 不管是user流发来的数据还是posts流发来的数据都会走这里
user?.let {
// 更新发帖状态信息
_profileState.value = profileState.value?.copy(
profilePicUrl = user.profilePicUrl,
userName = user.userName,
description = user.description,
posts = posts
)
}
}
}
}
外部使用viewmodel的界面拿profileState去访问post列表,如:
val profileState = viewModel.profileState.collectAsState().value
val posts = profileState?.posts
SharedFlow
SharedFlow中的数据变化时会向所有collect方发送数据。功能上有点类似BroadcastChannel。上面的StateFlow实际上是SharedFlow的一个特殊的子类。
例如我们可以利用SharedFlow定义一个简单的EventBus:
data class Event(val msg : Int = 0)
object LocalEventBus {
val eventsFlow = MutableSharedFlow<Event>()
suspend fun postEvent(event: Event) {
eventsFlow.emit(event)
}
}
/**
* 为LifecycleOwner定义一个扩展函数
*/
fun LifecycleOwner.postEvent(msg: Int) : Job {
return lifecycleScope.launch {
LocalEventBus.postEvent(Event(msg))
}
}
这样,在一个Activity中调用上面的postEvent()方法发送数据,而在其他Activity中的collect会自动收到发送数据:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
lifecycleScope.launchWhenCreated {
LocalEventBus.eventsFlow.collect { value ->
tvNumber.text = "$value"
}
}
}
或者我们为LfecycleOwner也定义一个接受Event的扩展函数:
/**
* 订阅事件
* The returned [Job] can be cancelled
*/
fun LifecycleOwner.onReceiveEvent(
filter: suspend (e: Event) -> Boolean = { true },
block: suspend (e: Event) -> Unit,
): Job {
return LocalEventBus
.eventsFlow
.filter { filter.invoke(it) }
.onEach { block.invoke(it) }
.cancellable()
.launchIn(lifecycleScope)
}
在使用时就可更加简单一点:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
onReceiveEvent { event ->
println("${event.msg}")
}
}
有一点需要注意的是,SharedFlow在执行emit发射数据的那一时刻,如果没有发现收集器的存在,则什么都不会发生,就是说如果在emit行为之后定义了collect函数,则不会起作用,emit只对已存在的collect起作用。比如如下代码:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// 发送的时刻,如果没有发现收集器,则什么都不会发生,例如下面定义的收集器不会被触发
postEvent(1234)
onReceiveEvent { event ->
println("${event.msg}")
}
}
运行上面代码,不会得到任何输出。假如我们延时一会儿发送,就会看到结果:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
postEventDelay(msg = 2222, timeMillis = 100)
onReceiveEvent { event ->
println("${event.msg}")
}
}
当然在定义收集器之后的地方发送,肯定会收到:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
onReceiveEvent { event ->
println("${event.msg}")
}
// 只要在发送那一时刻,已经有收集器存在,则一定会被触发
postEvent(3333)
}
前面说的这种先后是指时间上的先后顺序,而不是代码定义的先后顺序,比如以下代码:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// 在发送时刻之后调用collect不会接收到任何数据
lifecycleScope.launch {
delay(1000)
onReceiveEvent {
println("${it.msg}")
}
}
postEvent(3333)
}
这段代码的意图是发送一个数据,然后在之后的某个时候去收集并处理它,然而实际上在这之后并不会收到任何数据。
这跟普通的flow有很大的区别,普通的flow是不管你在什么时候collect都会接收到数据,并且多次collect则会多次收到数据,而SharedFlow不支持多次collect,如果多次执行collect只有第一次起作用(实际上AS编译器会提示你)

这里AS直接给你提示第二个collect是Unreachable code,即不可达的代码,实际上你在第一个collect之后写的任何代码都是Unreachable code。如果你打开collect的源码注释查看它会用加粗的字体告诉你:“A shared flow never completes.”翻译过来就是一个共享的流永远不会完成。那如果真的需要多次执行collect里的代码,该怎么办呢?那么可以这样写:
lifecycleScope.launch {
LocalEventBus.eventsFlow.collect {
...
}
}
lifecycleScope.launch {
LocalEventBus.eventsFlow.collect {
...
}
}
即只需要放在不同的协程作用域里面就可以了。
关于前面提到的这个问题可能一般会发生在同一个页面中,实际业务中如果你是多个Activity页面,那么要接收数据的Activity页面显然相对于发送者要发送数据的那一刻而言是已经存活的,不然也不会有意义,因为你不会给一个不存在的页面发送数据来更新UI,比如点击登录按钮,登录成功之后发送消息,那么接收登录消息的页面肯定是那些已经打开的关联页面。
replay
但是,有时候我们的确需要在某个页面打开之前就向其中的订阅者发送通知,等到该页面真正被打开时,则立马接受到通知, 例如在Android原生开发中著名的三方库EventBus中就有“粘性事件”的概念,那么如果想要使用SharedFlow发送类似这种“粘性事件”怎么办呢?MutableSharedFlow函数中提供了一个replay参数,它表示会发送给新的订阅收集器的数据的个数,例如:
object LocalEventBus {
val eventsFlow = MutableSharedFlow<Event>(replay = 5)
...
}
这里replay = 5表示它会向新的订阅collector发送最新的5个数据,SharedFlow内部会在buffer缓存中使用一部分来用作replayCache缓存需要replay的数据。这样我们就可以在发送时刻之后定义的collector收集器中接受到之前发送的数据了:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
(1..10).forEach {
postEvent(it)
}
onReceiveEvent {
println("${it.msg}")
}
}
运行上面代码输出:

假如我们向一个未打开的Activity页面发送数据,那么跳转到该Activity页面时,其中的onReceiveEvent就会接收到数据。但是你会发现一个问题,就是每次打开这个该Activity页面时都会重复接受到数据,如果我们只想要执行一次这样的行为怎么办,目前MutableShareFlow提供了一个resetReplayCache()方法可以重设replayCache,我们改一下onReceiveEvent扩展函数的实现:
/**
* 订阅事件
* The returned [Job] can be cancelled
*/
@OptIn(ExperimentalCoroutinesApi::class)
fun LifecycleOwner.onReceiveEvent(
filter: suspend (e: Event) -> Boolean = { true },
resetReplay: Boolean = false,
onEach: suspend (e: Event) -> Unit
): Job {
return LocalEventBus.eventsFlow
.filter { filter.invoke(it) }
.onEach { onEach.invoke(it) }
.cancellable()
.onCompletion {
if (resetReplay) {
LocalEventBus.eventsFlow.resetReplayCache()
}
}
.launchIn(lifecycleScope)
}
在重复接受数据的Activity页面只需要调用:
onReceiveEvent(resetReplay = true) {
println("received : ${it.msg}")
}
这样在Activity页面被关闭时,就会执行flow的onCompletion方法在其中会调用resetReplayCache(),下次再次打开该Activity页面就不会重复接受到数据了。
但是目前我没有找到动态设置MutableSharedFlow的replay这个参数的方法,如果想动态控制是否replay,目前看来只能使用两个MutableSharedFlow实例动态切换了。如果有知道的请留言告诉我。
Flow VS StateFlow VS ShareFlow
这三者在实际开发该如何选择呢?这需要根据它们的特点结合具体的场景来决定:
- Flow:多次发射,多次接受,一次可发射多个数据,每次发射之间可以调用挂起函数如delay延时,因此更加适合倒计时、计数器等需要反复、持续、间歇性的执行的业务场景
- StateFlow:数据变化后自动触发更新,观察者模式,适合自动订阅场景,如我将UI和数据通过 StateFlow 绑定之后,后面就不用去管UI了,因为它会自动触发组件更新,只需要关心在何时去发送新的数据,这就是为啥有人直接用它替代LiveData来用。并且它会缓存数据,针对屏幕旋转后Activity重建等场景做了优化,Activity不会丢失页面状态。
- SharedFlow:只能发射one time数据,不会重复发射,发射一次的数据多次collect也不会重复接受到,因此更加适合用于事件触发,事件通信,发送广播等场景,例如实现EventBus
协程中的线程安全问题
由于协程是运行在线程框架之上的,协程的异步回调依赖于其调度器的具体实现,而调度器的实现一般是基于线程的封装,所以在协程中依然存在线程安全问题(除非你只在单线程中使用它)。

不安全的并发访问
我们看一个简单的并发计数问题,代码如下所示
// 不安全的计数
suspend fun main() {
var count = 0
List(1000) {
GlobalScope.launch {
count++
}
}.joinAll()
println("count: $count")
}
输出结果:
count:992
运行在 Java 平台上,通过GlobalScope.launch启动的协程默认会被调度到 Dispatchers.Default这个基于线程池的调度器上,因此 count++是不安全的,最终的结果也证实了这一点。
不安全的原因主要有以下两点:
- count++不是原子操作。
- count 的修改不会立即刷新到主存 ,导致读写不一致。
解决这个问题我们都有丰富的经验,例如将 count 声明为原子类型,确保自增操作为原子操作,代码如下所示
// 确保修改的原子性
suspend fun main() {
val count = AtomicInteger(0)
List(1000) {
GlobalScope.launch {
count.getAndIncrement()
}
}.joinAll()
println("count: ${count.get()}")
}
当然,直接粗暴地加锁也是一种思路,虽然我们都知道这不是一个好的解决方法。
使用synchronized加锁的代码如下:
suspend fun main() {
val lock = "lock" // 需要保证锁的是同一个对象
var count = 0
List(1000) {
GlobalScope.launch {
synchronized(lock) {
count++
}
}
}.joinAll()
println("count: $count")
}
使用ReentrantLock加锁的代码如下:
suspend fun main() {
var count = 0
val lock = ReentrantLock()
List(1000) {
GlobalScope.launch {
try {
lock.lock()
count++
} finally {
lock.unlock()
}
}
}.joinAll()
println("count: $count")
}
这跟在Java世界里使用加锁的方式没有区别。
协程的并发工具
除了我们在Java世界中常用的解决并发问题的手段之外,协程框架也提供了一些并发安全的工具,包括:
- Channel: 并发安全的消息通道,前面已经介绍过(但是它更加适合用于不同业务端之间的通信,如生产者和消费者,不太适合用于控制对某一个共享资源的多线程操作)
- Mutex:轻量级锁,它的 lock 和 unlock 语义上与线程锁比较类似,之所以轻量是因为它在获取不到锁时不会阻塞线程而只是挂起等待锁的释放,代码如下所示
// Mutex使用示例
suspend fun main() {
var count = 0
val mutex = Mutex()
List(1000) {
GlobalScope.launch {
mutex.withLock {
count++
}
}
}.joinAll()
println("count: $count")
}
- Semaphore:轻量级信号量,信号量可以有多个,协程在获取到信号量后即可执行并发操作。当 Semaphore 的参数为 1 时,效果等价于 Mutex,相关示例代码如下
// Semaphore使用示例
suspend fun testSync() {
var count = 0
val semaphore = Semaphore(1)
List(1000) {
GlobalScope.launch {
semaphore.withPermit {
count++
}
}
}.joinAll()
println("count: $count")
}
注意这里的Semaphore是kotlinx.coroutines.sync包下面的,而不是原来java的concurrent包下的Semaphore,导包的时候需要注意。

与线程相比,协程的 API 在需要等待时挂起即可,因而显得更加轻量,加上它更具表现力的异步能力,只要使用得当,就可以用更少的资源实现更复杂的逻辑。
避免访问外部可变状态
我们前面一直在探讨如何正面解决线程安全的问题,实际上多数时候我们并不需要这么做。我们完全可以想办法规避因可变状态的共享而引发的安全问题,上述计数程序出现问题的根源是启动了多个协程且访问一个公共的变量 count,如果我们能避免在协程中访问可变的外部状态,就基本上不用担心并发安全的问题。
如果我们编写函数时要求它不得访问外部状态,只能基于参数做运算,通过返回值提供运算结果,这样的函数不论何时何地调用,只要传入的参数相同,结果就保持不变,因此它就是可靠的,这样的函数也被称为 纯函数。我们在设计基于协程的逻辑时,应当尽可能地编写纯函数,以降低程序出错的风险。
前面计数的例子的目的是在协程中确定数值的增量,那么我们完全可以改造成如下代码来满足需求
suspend fun main() {
val count = 0
val result = count + List(1000) {
GlobalScope.async { 1 }
}.sumOf {
it.await()
}
println("result: $result")
}
你可能会觉得这个例子过于简单,然而实际情况也莫过于此。
总而言之, 如非必须,则避免访问外部可变状态;如无必要,则避免共享可变状态。
可变状态的共享是并发操作不安全的主要原因,如果你不知道什么是不可变状态,可以先尝试理解一下java中的String类为什么是不可变的。其实相比java而言,在kotlin中很多关键字已经为我们标明了哪些是可变不可变的,如 val 声明的就是不可变量,所有 MutableXXX开头的api创建的数据结构都是可变的。
尝试在单线程调度器中操作共享资源
前面提到,在 Java 平台上,通过GlobalScope.launch启动的协程默认会被调度到 Dispatchers.Default线程池上,这里有个点就是使用相同名字的调度器不一定就是相同的线程,这是理所当然的,因为调度器是基于线程池,而线程池不一定是只有一个线程的。但是同一个调度器的内部什么时候切换线程我们是无法控制的,这取决于其具体实现。因此我们诞生了一个非常简单的想法:假如我们能将所有操作共享资源的地方都切到同一个只有一个线程的调度器上去执行,不就可以避免并发安全问题了吗?
首先我们定义一个单线程池的调度器:
object SingleThreadDispatcher {
val SingleDispatcher = Executors.newSingleThreadExecutor { runnable ->
Thread(runnable, "MyThread").also { it.isDaemon = true }
}.asCoroutineDispatcher()
}
val Dispatchers.SINGLE: CoroutineDispatcher
get() = SingleThreadDispatcher.SingleDispatcher
这里定义一个Object单例确保不会在每次使用时都创建一个新的单线程池的实例,那样将没有意义,然后我们将其定义成Dispatcher的扩展属性。
然后我们将前面的业务代码修改如下:
suspend fun main() {
var count = 0
val cost = measureTimeMillis {
GlobalScope.launch {
repeat(1000) {
launch(Dispatchers.IO) {
withContext(Dispatchers.SINGLE) {
val old = count
count++
if (count != (old + 1)) {
println("修改后的值与期望值不一致,存在线程安全问题")
}
}
}
}
}.join()
}
println("cost-----------------------$cost")
println("result---------------------$count")
}
这里使用 withContext(Dispatchers.SINGLE) 获得了跟 mutex.withLock{…} 同样的功能,效果上就相当于加了一把锁,但实际上是将不同协程中withContext中的代码块切到同一个线程中去按顺序处理从而得到安全保证的。

这里真的得猛夸一波withContext这个函数,试想如果我们使用Android原生java的写法可能无法做到这样简洁,比如从一个子线程切到另一个子线程,首先我们需要在不同的线程中开启Looper循环机制,然后在其中创建handler,然后将handler传递到其他线程中去切…十分麻烦,就单论“从当前线程切出去,完事之后自动再切回来”这件事,即便是使用RxJava这种提供了非常方便的线程切换操作符的框架,也无法做到像withContext这样一行代码的简洁度。
另外注意withContext是一个挂起函数,在同一个协程作用域内,挂起函数是会阻塞排在它后面的代码的,这一点非常重要,因此在同一个协程作用域内,原本按先后顺序执行的代码,在加入withContext之后,不会改变原有的顺序,后执行的代码仍然会等待挂起函数返回之后再继续执行。

注意这种方案只能使用withContext(Dispatchers.SINGLE),而不能使用launch(Dispatchers.SINGLE),假如我们使用了launch,可能会改变原本的代码先后的执行顺序,如果你打印log就会发现launch之后的代码是先输出的:

原因就是launch并不是一个挂起函数,它只是起了一个协程作用域,而是withContext一个挂起函数,只有挂起函数会阻塞。所以这种方案的本质其实是通过一行阻塞式的代码切换到单线程中执行完后再自动切换回来,那么符合这个要求的貌似kotlin协程中就只有withContext了(或者你可以自己仿照它写一个函数)。
下面讨论一下这种方案不足的地方:
(1)我们知道 Executors.newSingleThreadExecutor() 使用的阻塞队列LinkedBlockingQueue 是一个无界队列(默认大小是Integer.MAX_VALUE),而 核心线程数 和 最大线程数 都是1,因此后续提交的任务都会保存到 LinkedBlockingQueue 中,而withContext中的block代码块最终是会被包装成Runnable对象提交到线程池中的队列执行的,如果代码中并发调用withContext的协程非常的多,那么有可能会导致队列无限增大,最终撑爆内存。
如何改进:
有人会说可以不使用Executors.newSingleThreadExecutor()这个Api,采用自定义线程池,这样就可以自己指定线程池的队列容量大小了,但是这个容量设置多少合适呢?10个?20个?更关键的问题是:你有没有想过如果任务数量超出了队列大小,会发生什么情况?
我们看一下线程池扩展函数 asCoroutineDispatcher() 的实现:
public fun ExecutorService.asCoroutineDispatcher(): ExecutorCoroutineDispatcher =
ExecutorCoroutineDispatcherImpl(this)
internal class ExecutorCoroutineDispatcherImpl(override val executor: Executor) : ExecutorCoroutineDispatcher(), Delay {
override fun dispatch(context: CoroutineContext, block: Runnable) {
try {
executor.execute(wrapTask(block))
} catch (e: RejectedExecutionException) {
unTrackTask()
cancelJobOnRejection(context, e)
Dispatchers.IO.dispatch(context, block)
}
}
...
}
可以看到内部实现类中的dispatch()方法有个try-catch,捕获到线程池抛出的异常时直接调度到Dispatchers.IO这个调度器上执行,我们知道当线程池队列饱和之后会执行饱和策略,而默认的饱和策略就是抛出RejectedExecutionException。因此,即使你自定义线程池,队列的容量仍然不好设计,如果太小,超出就会被切到其他线程中执行,这样就不能满足单线程解决并发的需求了,所以你只能设置一个比较大的容量,一个实际业务中不会触及的大数,比如Integer.MAX_VALUE。。。所以最好的选择还是用Executors.newSingleThreadExecutor(),你可能会想在自定义线程池时指定饱和策略时不抛出RejectedExecutionException异常,但是如果不抛出异常,除了丢弃任务或者另外找个地方存起来外,好像也没有别的更好的选择了。
还有一个想法就是,我们可以自己定义类似asCoroutineDispatcher()的函数,然后修改dispatch()方法中catch的逻辑,不切到其他线程,而是使用前面的协程中的并发工具来处理,例如:
internal class ExecutorCoroutineDispatcherImpl(override val executor: Executor) : ExecutorCoroutineDispatcher(), Delay {
val mutex = Mutex()
override fun dispatch(context: CoroutineContext, block: Runnable) {
try {
executor.execute(wrapTask(block))
} catch (e: RejectedExecutionException) {
runBlocking {
mutex.withLock {
block.run()
}
}
}
}
...
}
这样catch中的逻辑还是在原来调用者的线程上运行只不过使用加锁的方式。这么看来我们就可以尝试使用自定义线程池+自定义阻塞队列容量大小+自定义CoroutineDispatcher的实现方案。(不过这个显然是有点复杂呢,我还没有尝试过)
(2)采用单线程池调度器这种方案的第二个缺陷就是性能的损耗,这不难理解,因为默认单线程池的阻塞队列是无界队列,所以即便你在某处仅仅使用withContext包裹了一行代码,但此时线程池中的任务队列中可能前面已经排了100多个任务,那么当前新加入的block就要等待队列前面所有的任务执行完毕,此时的耗时可能无法估量,因而可能会导致在withContext的下面那行代码会等待较长的时间才能被执行。因此如果是一些对性能比较敏感要求的业务,此时这种方案可能就不太适合了。
但是,等一下,这种性能损耗就真的没有改进的余地了吗?
在前面的代码中我们定义了一个单例的单线程池对象,但实际当中可能不需要单例,或者说是不需要全局单例,而是局部范围内单例。想象一下,假如是全局单例,那么我在N个Activity页面中的并发操作的业务逻辑全部都向这个单例的单线程池队列中提交任务,那么任务队列很快就满了。因此只需要在处理同一种业务逻辑时,使用同一个单线程池对象就可以了。什么意思呢,比如前面的示例代码中所有修改count的业务被视为同一种业务A,对这种业务A我们使用同一个单线程池对象即可满足其业务并发安全,假设有另一种业务是在不同的地方去修改一个叫name的全局共享变量,该业务被视为业务B,那么对这种业务B使用另外一个相同的单线程池对象即可满足其业务并发安全。 在业务A和 业务B中我们使用两个单线程池的实例。
参考:
- 《深入理解Kotlin协程》- 2020年-机械工业出版社-霍丙乾
- The Ultimate Guide to Kotlin Flows