【Effective Objective-C】—— 系统框架
第47条:熟悉系统框架
编写OC应用程序的时候我们几乎都会用到系统框架,其中提供了很多我们经常使用的类,并且我们使用的系统框架也是会随着官方的更新而更新的。
将一系列代码封装为动态库,并在其中放入描述其接口的头文件,这样做出来的东西就叫框架。
我们经常使用的就是Foundation框架,像NSObject、NSArray等等的类都在其中。这个框架中的类通常都是以NS前缀开头的,此前缀是在OC语言用作NeXTSTEP操作系统的编程语言时首度确定的,这个框架基本上就可以说是OC应用程序的基础了。
还有个与Foundation相伴的框架,叫做CoreFoundation框架,虽然从技术上讲它不是OC框架,但是它却是编写OC应用程序时所应熟悉的重要框架。他其中的很多类都和Foundation框架相似,并且我们还可以通过“无缝桥接”功能实现CoreFoundation框架中的C语言数据结构平滑转换为Foundation框架中的OC对象,也可以反向转换。无缝桥接技术是用某些相当复杂的代码实现出来的,这些代码可以使运行期系统把CoreFoundation框架中的对象视为普通的OC对象。
除了上述的两个之外,还有很多,就像下面这些:
由此可以看出OC编程的特点会经常用底层的C语言级API。用它肯定是有一定好处的:可以绕过OC的运行期系统,从而提升执行速度。当然由于ARC只负责OC对象的内存管理,所以我们在使用这些API时要注意内存管理问题。
下面还有一些框架:
CoreAnimation是用OC语言写成的,它提供了一些工具,而UI框架则用这些工具来渲染图形并播放动画。但是它本身并不是框架,它只是QuartzCore框架的一部分。
CoreGraphics框架以C语言写成,其中提供了2D渲染所必备的数据结构与函数,例如:CGPoint、CGSize、CGRect等等。
MapKit框架,他可以为iOS程序提供地图功能。
Social框架,它为Mac OS X及iOS程序提供了社交网络功能。
要点:
- 许多系统框架都可以直接使用。其中最重要的是Foundation与CoreFoundation,这两个框架提供了构建应用程序所需的许多核心功能。
- 很多常见任务都能用框架来做,例如音频与视频处理、网络通信、数据管理等。
- 请记住:用纯C写成的框架与用OC写成的一样重要,若想成为优秀的OC开发者,应该掌握C语言的核心概念。
第48条:多用块枚举,少用for循环
平常我们在编程的时候会经常用到列举元素的方法,下面就为大家简单的说说那些方法:
1.for循环:
它是C语言中我们经常用到的一种循环方式,当然在OC中也可以使用,这是很基本的方法,因而功能非常有限。通常会这样写:
因为字典和set与数组不同所以会比较麻烦:

因为字典和set都是无序的,所以要先把它转换为数组才可以正常使用for循环来使用。当然for循环也可以实现反向遍历,只需要让其从“元素个数减1”开始,每次迭代时递减,直到0为止就行,执行反向遍历,使用for循环要比其他方式简单很多。
2.使用OC 1.0的NSEnumerator来遍历:
NSEnumerator是个抽象基类,其中只定义了两个方法,供其具体子类来实现:
- (NSArray *)allObjects;
- (id)nextObject;
其中最关键的方法是nextObject,他返回枚举里的下个对象。每次调用该方法时,其内部数据结构都会更新,使得下次调用方法时能返回下个对象。等到枚举中的全部对象都已返回之后,再调用就将返回nil,这表示达到枚举末端了。
就像这样:

这种写法与for循环相似,但是代码稍多一些,其真正的优势在于:不论遍历那种collection,都可以采用这套相似的语法,并且她还有多种“枚举器”可以使用。
就比如反向遍历:

3.快速遍历:
OC 2.0引入了这一功能,它不仅语法简介而且更快更实用。
如果某个类的对象支持快速遍历,那么就可以宣称自己遵从名为NSFastEnumeration的协议,从而令开发者可以采用此语法来迭代该对象,此协议只定义了一个方法:
- (NSUInteger)countByEnumeratingWithState:(NSFastEnumerationState *)state objects:(id *)stackbuffer count:(NSUInteger)length;
其要点在于:该方法允许类实例同时返回多个对象,这就使得循环遍历操作更为高效了。下面是一些例子:


并且它也可以实现反向遍历:
但是,这种写法有缺点:它无法轻松获取当前遍历操作所针对的下标,就导致他可能做不了一些算法有关的东西。
4.基于块的遍历方式:
这种方法就弥补了之前说的不足:
基于数组的方法:
- (void)enumerateObjectsUsingBlock:(void(^)(id object, NSUInteger idx, BOOL *stop))block;
这个块有三个参数,分别是当前迭代所针对的对象、所针对的下标,以及指向布尔值的指针。通过改变第三个参数我么可以使循环停止。例如:
基于字典的方法:
- (void)enumerateKeysAndObjectsUsingBlock:(void(^)(id key, id object, BOOL *stop))block;

基于set的方法:
- (void)enumerateObjectsUsingBlock:(void(^)(id object, BOOL *stop))block;

此方式大大胜过其他方式的地方在于:遍历时可以直接从块里获取更多信息,并且它能够修改块的方法签名,以免进行类型转换操作。就用字典来说,假如你知道它的键的类型是NSString类型,那么就可以直接这么写:
指定对象的精确类型之后,编译器就可以检测出开发者是否调用了该对象所不具备的方法,并在发现这种问题时报错。如果能够通知某collection里的对象是什么类型,那就应该使用这种方法指明其类型。
当然这种方法也可以实现反向遍历,不过每个方法之中都会多一个参数:

这里新添加了一个枚举值,其各种取值可用“按位或”连接,用以表明遍历方式。如果使用该功能,那么底层会通过GCD来处理并发执行事宜,具体实现时很可能会用到dispatch group。要注意:只有在遍历数组或有序set等有顺序的collection时,这么做才有意义。
总体来看,块枚举拥有其他遍历方式都具备的优势,而且还能带来更多好处。
5.要点:
- 遍历collection有四种方式。最基本的办法是for循环,其次是NSEnumerator遍历法及快速遍历法,最新、最先进的方式则是“块枚举法”。
- “块枚举法”本身就能通过GCD来并发执行遍历操作,无须另行编写代码。而采用其他遍历方式则无法轻易实现这一点。
- 若提前知道待遍历的collection含有何种对象,则应修改块签名,指出对象的具体类型。
第49条:对自定义其内存管理语义的collection使用无缝桥接
“无缝桥接”技术其实就是不同库之间相同类型的相互转换。
使用“无缝桥接”技术,可以在定义于Foundation框架中的OC类和定义于CoreFoundation框架中的C数据结构之间互相转换。举例说明:

转换操作中的__bridge告诉ARC如何处理转换所涉及的OC对象。__bridge本身的意思是:ARC仍然具备这个OC对象的所有权。而__bridge_retained则与之相反,意味着ARC将交出对象的所有权。与之相似,反向转换可通过__bridge_transfer来实现,也就是将对象的所有权交给ARC。这三种转换方式称为“桥式转换”。
以纯OC来编写应用程序时,为何要用到这种功能呢?
这是因为:Foundation框架中的OC类所具备的某些功能,是CoreFoundation框架中的C语言数据结构所不具备的,反之亦然。
就用Foundation框架中的字典来说,其键的内存管理语义为“拷贝”,而值的语义却是“保留”,而CoreFoundation框架中的字典CFDictionary语义却要自己来设置,当然我们也可以通过这个特性来设置自己的一款类。创建其字典时,可以通过下列方法来制定键和值的内存管理语义:

首个参数表示将要使用的内存分配器,NULL表示使用默认的分配器。第二个参数定义了字典的初始大小,它并不会限制字典的最大容量,只是向分配器提示了一开始应该分配多少内存。最后两个参数都是指向结构体的指针,二者所对应的结构体如下:
![]()

version参数目前应设为0,当前编程时总是取这个值,可能还没有官方的版本号。结构体中的其余成员都是函数指针,他们定义了当前各种时间发生时应该采用那个函数来执行相关任务。比如说:如果字典中加入了新的键与值,那么就会调用retain函数,此参数的类型定义如下:
由此可见,retain是个函数指针,其所指向的函数接受两个参数,其类型分别时CFAllocatorRef与const void*。传给此函数的value参数表示即将加入字典中的键或值。而返回的void*则表示要加到字典里的最终值。
下面就完整的演示了这种字典的创建步骤:

在设定回调函数时,copyDescription取值为NULL,因为采用默认实现就很好。而equal与hash回调函数分别设为CFEqual与CFHash,因为这两者所采用的做法与NSMutableDictionary的默认实现相同。CFEqual最终会调用NSObject的“isEqual:”方法,而CFHash则会调用hash方法。
键与值所对应的retain与release回调函数指针分别指向EOCRetainCallback与EOCReleaseCallback函数。在向NSMutableDictionary中加入键和值时,字典会自动“拷贝”键并“保留”值。如果用作键的对象不支持拷贝操作,那么我们就不能使用普通的NSMutableDictionary了,假如用了,会导致下面这种运行期错误:
该错误表明,对象所属的类不支持NSCopying协议,因为“copyWithZone:”方法未实现。
通过类似的手段我们就可以创建出自己想要的底层内存管理类了,但是一定要经过严谨的思考后再确定要不要使用。
要点:
- 通过无缝桥接技术,可以在Foundation框架中的OC对象与CoreFoundation框架中的C语言数据结构之间来回转换。
- 在CoreFoundation层面创建collection时,可以指定许多回调函数,这些函数表示此collection应如何处理其元素。然后,可运用无缝桥接技术,将其转换成具备特殊内存管理语义的OC collection。
第50条:构建缓存时选用NSCache而非NSDictionary
开发应用程序时,经常会遇到一个问题,那就是从因特网下载的图片应如何来缓存。首先想到的最好办法就是把内存中的图片直接保存到字典里,这样的话,稍后使用时就无须再次下载了。其实,NSCache类更好,它是Foundation框架专门为处理这种任务而设计的。
NSCache胜过NSDiactionary之处在于,当系统资源将要耗尽的时,他可以自动删减缓存。NSCache并不会“拷贝”键,而是会“保留”它。此行为用NSDiactionary也可以实现,然而需要编写相当复杂的代码。NSCache对象不拷贝键的原因在于:很多时候,键都是由不支持拷贝操作的对象来充当的。另外,NSCache是线程安全的,而NSDiactionary则绝不具备此优势,意思就是:在开发者自己不编写加锁代码的前提下,多个线程便可同时访问NSCache。
开发者可以操控缓存删减其内容的时机。有两个与系统资源相关的尺度可供调整,其一是缓存中的对象总数,其二是所有对象的“总开销”。开发者在将对象加入缓存时,可为其指定“开销值”。当对象总数或总开销超过上限时,缓存就可能会删减其中的对象了,在可用的系统资源趋于紧张时,也会这么做。然而要注意,“可能”会删减某个对象,并不意味着“一定”会删减这个对象。删减对象时所遵照的顺序,是由具体实现来定。这尤其说明:想通过调整“开销值”来迫使缓存优先删减某对象,这不是个好主意。
同时,向缓存中添加对象时,只有在很快能计算出“开销值”的情况下,才应该考虑采用这个尺度,因为系统是要进行比较的,若长时间计算不出总开销,那么这种方法还有什么好处可言,反而还拖慢了系统的进程。
下面演示了缓存的用法:


在本例中,下载数据所用的URL,就是缓存的键。若缓存未命中,即缓存中没有访问者所需的数据,则下载数据并将其放入缓存。而数据的“开销值”则设为其长度。
还有个类叫做NSPurgeableData和NSCache搭配起来用,它是NSMutableData的子类,而且实现了NSDiscardableContent协议。如果某个对象所占的内存能够根据需要随时丢弃,那么就可以实现该协议所定义的接口。这就是说,当系统资源紧张时,可以把保存NSPurgeableData对象的那块内存释放掉。NSDiscardableContent协议里定义了名为isContentDiscarded的方法,可用来查询相关内存是否已释放。
如果需要访问某个NSPurgeableData对象,可以调用其beginContentAccess方法,告诉它现在还不应丢弃自己所占据的内存。用完之后,调用endContentAccess方法,告诉它在必要时可以丢弃自己所占据的内存了。这些调用可以嵌套,所以说,他们就像递增与递减引用计数所用的方法那样。只有对象的“引用计数”为0时才可以丢弃。
如果将NSPurgeableData对象加入NSCache,那么当该对象为系统所丢弃时,也会自动从缓存中移除。通过NSCache的evictsObjectsWithDiscardedContent属性,可以开启或者关闭此功能。
所以刚才的例子可以改写为:

注意,创建好NSPurgeableData对象之后,其“purge引用计数”会多1,所以无须再调用beginContentAccess了,然而其后必须调用endContentAccess,将多出来的这个“1”抵消掉。
要点:
- 实现缓存时应选用NSCache而非NSDictionary对象。因为NSCache可以提供优雅的自动删减功能,而且是“线程安全的”,此外,它与字典不同,并不会拷贝键。
- 可以给NSCache对象设置上限,用以限制缓存中的对象总个数及“总成本”,而这些尺度则定义了缓存删减其中对象的时机。但是绝对不要把这些尺度当成可靠的“硬限制”,它们仅对NSCache起指导作用。
- 将NSPurgeableData与NSCache搭配使用,可实现自动清除数据的功能,也就是说,当NSPurgeableData对象所内存为系统所丢弃时,该对象自身也会从缓存中移除。
- 如果缓存使用得当,那么应用程序的响应速度就能提高。只有那种“重新计算起来很费事的”数据,才值得放入缓存,比如那些需要从网络获取或从磁盘读取的数据。
第51条:精简initialize与load的实现代码
有时候,类必须先执行某些初始化操作,然后才能正常使用。在OC中,绝大多数的类都继承自NSObject这个根类,而该类有两个办法,可用来实现这种初始化操作。
1.load方法:
首先是load方法,其原型如下:
+ (void)load;
对于加入运行期系统中的每个类及分类来说,必定会调用此方法,而且仅调用一次。当包含类或分类的程序库载入系统时,就会执行此方法,而这通常就是指应用程序启动的时候。如果分类和其所属的类都定义了load方法,则先调用类里的,再调用分类里的。
load方法的问题在于,执行该方法时,运行期系统处于“脆弱状态”。在执行子类的load方法之前,必定会先执行所有超类的load方法,而如果代码还依赖了其他程序库,那么程序库里相关类的load方法也必定会先执行。然而,根据某个给定的程序库,却无法判断出其中各个类的载入顺序。因此,在load方法中使用其他类是不安全的。
并且在load方法里调用的类若之前没有加载好,那么再调用程序就会崩溃了,注意:程序在执行load方法时会阻塞系统,并且每个类都只能执行自己的load,不会执行超类的load的。
总的来说,load方法里代码要写的精简,能少写就少写,能不用就不用。
2.initialize方法:
想执行与类相关的初始化操作,还有个办法,就是覆写下列方法:
+ (void)initialize;
对于每个类来说,该方法会在程序首次用该类之前调用,且只调用一次。它是由运行期系统来调用的,绝不应该通过代码直接调用。
它和load的区别:
首先,它是“惰性调用的”,也就是说,只有当程序用到了相关的类时,才会调用。还有就是运行期系统在执行该方法时,是处于正常状态的,因此,从运行期系统完整度上来讲,此时可以安全使用并调用任意类中的任意方法。而且,运行期系统也能确保initialize方法一定会在“线程安全的环境”中执行,这就是说,只有执行initialize的那个线程可以操作类或类实例。其他线程都要先阻塞。等着initialize执行完。最后一个就是,initialize方法与其他消息一样,如果某个类未实现它,而其超类实现了,那么就会运行超类的实现代码。
initialize要保持精简的原因:
首先,大家都不想看到自己的应用程序“挂起”,若写的太过繁琐,导致其运行很慢那就适得其反了。其二,开发者无法控制类的初始化时机。最后,如果某个类的实现代码很复杂,那么其中可能会直接或间接用到其他类。若那些类尚未初始化,则系统会迫使其初始化。然而,本类的初始化方法此时尚未运行完毕。其他类在运行其initialize方法时,有可能会依赖本类中的某些数据,而这些数据此时也许还未初始化好,就会造成依赖环。
所以说,initialize方法只应该用来设置内部数据。不应该在其中调用其他方法,即便是本类自己的方法,也最好别调用。若某个全局状态无法在编译期初始化,则可以放在initialize里来做。
注意,某些OC对象也可以在编译期创建,例如NSString实例。
编写load或initialize方法时,一定要留心这些注意事项。把代码实现的简单一些,能节省很多调试时间。除了初始化全局状态之外,如果还有其他事情要做,那么可以专门创建一个方法来执行这些操作,并要求该类的使用者必须在使用本类之前调用此方法。
3.要点:
- 在加载阶段,如果类实现了load方法,那么系统就会调用它。分类里也可以定义此方法,类的load方法要比分类中的先调用。与其他方法不同,load方法不参与覆写机制。
- 首次使用某个类之前,系统会向其发送initialize消息。由于此方法遵从普通的覆写规则,所以通常应该在里面判断当前要初始化的是那个类。
- load与initialize方法都应该实现的精简一些,这有助于保持应用程序的响应能力,也能减少引入“依赖环”的几率。
- 无法在编译期设定的全局常量,可以放在initialize方法里初始化。
第52条:别忘了NSTimer会保留其目标对象
Foundation框架中有个类叫NSTimer,开发者可以指定绝对的日期与时间,以便到时执行任务,也可以指定执行任务的相对延迟时间。计时器还可以重复运行工作,有个与之相关联的“间隔值”可用来指定任务的触发频率。
计时器要和“运行循环(run loop)”相关联,运行循环到时候会触发任务。创建NSTimer时,可以将其“预先安排”在当前的运行循环中,也可以先创建好,然后由开发者自己来调度。无论采用哪种方式,只有把计时器放在运行环里,它才能正常触发任务。
创建计时器:
+ (NSTimer *)scheduledTimerWithTimeInterval:(NSTimerInterval)seconds target:(id)target selector:(SEL)selector userInfo:(id)userInfo repeats:(BOOL)repeats;
用此方法创建出来的计时器,会在指定的间隔时间之后执行任务。也可以令其反复执行任务,知道开发者稍后将其手动关闭为止。target与selector参数表示计时器将在哪个对象上调用哪个方法。**计时器会保留其目标对象,等到自身“失效”时再释放此对象。**调用invalidate方法可令计时器失效;执行完相关任务之后,一次性的计时器也会失效。开发者若将计时器设置成重复执行模式,那么必须自己调用invalidate方法,才能令其停止。
由于计时器会保留其目标对象,所以反复执行任务通常会导致应用程序出问题。也就是说,设置成重复执行模式的那种计时器,很容易引人“保留环”。就像下面这样:

创建计时器的时候,由于目标对象是self,所以要保留此实例。然而,因为计时器是用实例变量存放的,所以实例也保留了计时器,于是,就产生了保留环。所以说,那么调用stopPolling,要么令系统将此实例回收,只有这样才能打破保留环。
因为是类和这个类中的实例出现了保留环,不管你外界怎么对这个类释放,这个计时器始终都会保留这个类,而这个类也会保留这个计时器,他们的保留计数永远都不会降为0。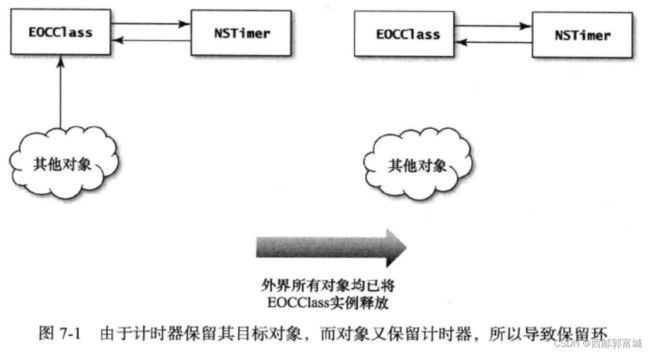
单从计时器本身入手,很难解决这个问题。可以要求外界对象在释放最后一个指向本实例的引用之前,必须先调用stopPolling方法。然而这种情况无法通过代码检测出来。此时我们就可以使用“块”来解决:


这段代码将计时器所应执行的任务封装成“块”,在调用计时器函数上,把它作为userInfo参数传进去。该参数可用来存放“不透明值”(即万能值),只要计时器还有效,就会一直保留着它。传入参数时要通过copy方法将block拷贝到“堆”上,否则等到稍后要执行它的时候,该块可能已经无效了。计时器现在的target是NSTimer类对象,这是个单例,因此计时器是否会保留它,其实都无所谓。此处依然有保留环,然而因为类对象无须回收,所以不用担心。
新改写的代码这样调用: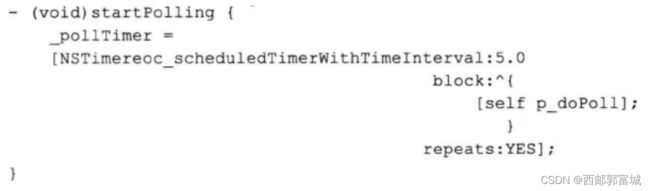
但是其实它还是有保留环的,因为块捕获了self变量,所以块要保留实例。而计时器又通过userInfo参数保留了块。最后,实例本身还是要保留计时器。不过,只要改用weak引用,即可打破保留环。


这段代码采用了一种很有效的写法,他先定义了一个弱引用,令其指向self,然后使块捕获这个引用,而不直接去捕获普通的self变量。也就是说,self不会为计时器所保留。当块开始执行时,立刻生成strong引用,以保证实例在执行期间持续存活。
要点:
- NSTimer对象会保留其目标,直到计时器本身失效为止,调用invalidate方法可令计时器失效,另外,一次性的计时器在触发完成任务之后也会失效。
- 反复执行任务的计时器,很容易引人保留环,如果这种计时器的目标对象又保留了计时器本身,那肯定会导致保留环。这种环状保留关系,可能是直接发生的,也可能是通过对象图里的其他对象间接发生的。
- 可以扩充NSTimer的功能,用“块” 来打破保留环。不过,除非NSTimer将来在公共接口里提供此功能,否则必须创建分类,将相关实现代码加入其中。