python绘制月亮_数据挖掘——月亮数据
一、问题描述
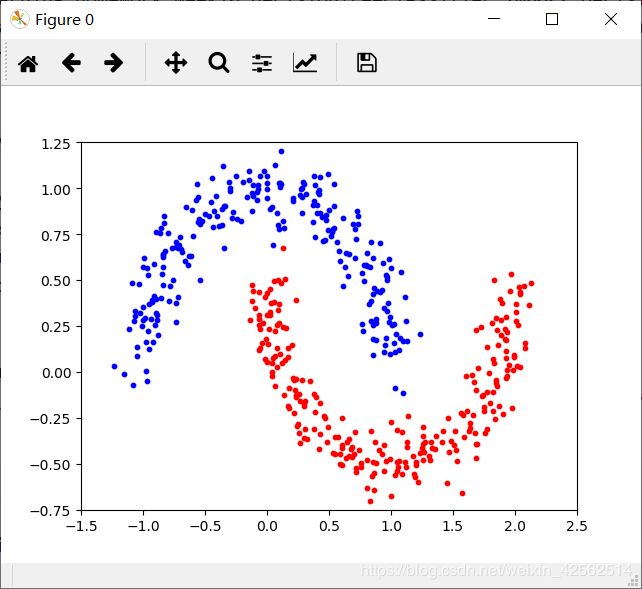
月亮数据是sklearn工具库提供的一个数据集。它上用于分类和聚类算法的实践实验。图中每一个点是一条数据。其中(x1,x2)是特征组,颜色是标签值。
二、实验目的
学习决策树和随机森林
三、实验内容
1.数据导入:采用自动生成的数据
2.数据预处理:使用库函数进行数据处理
四、实验结果及分析
原始数据:
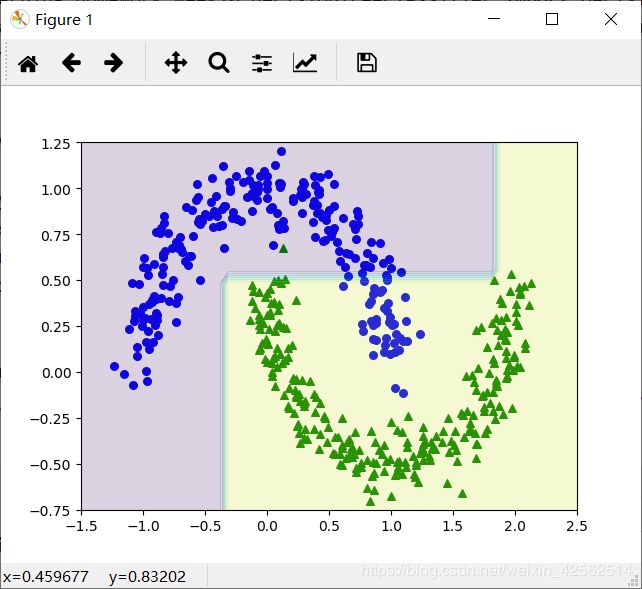
Max_depth=2:
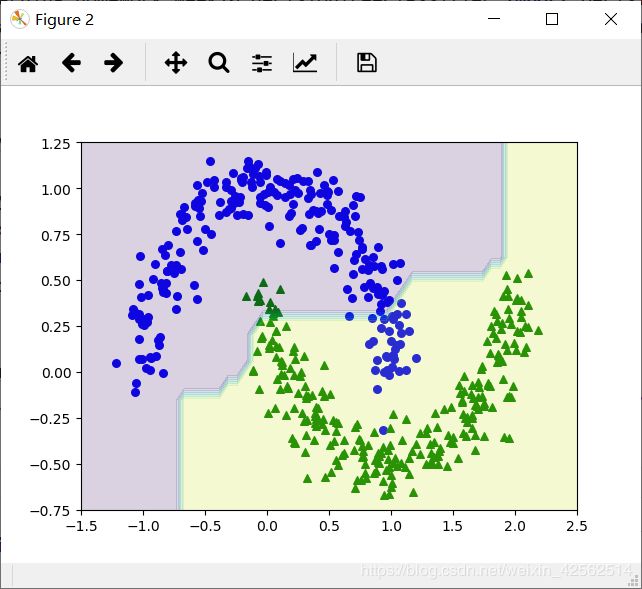
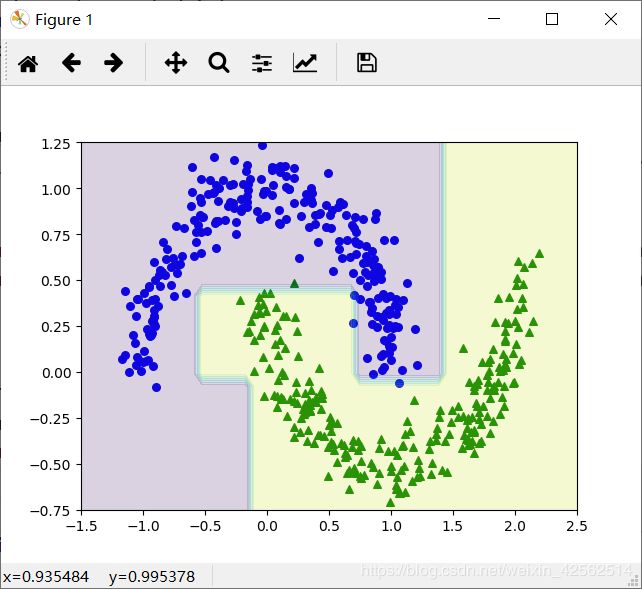
Max_depth = 5:
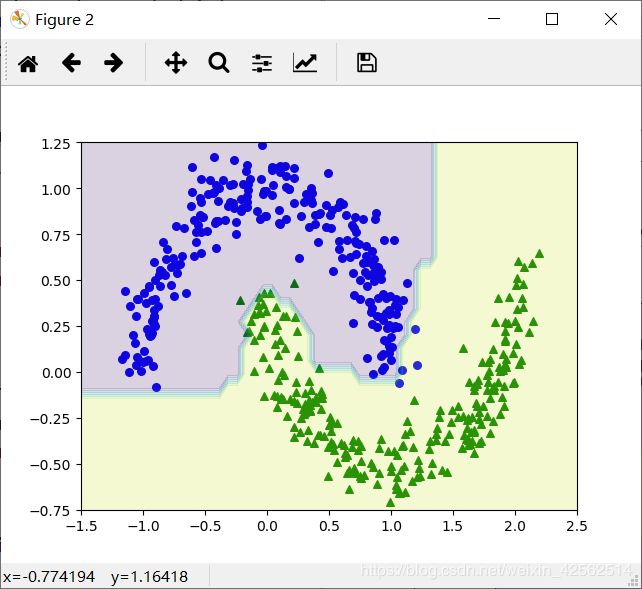
五、遇到的问题和解决方法
图像处理的时候不太懂,参考别人的做的。
六、完整代码
decisionTreeBase.py
import numpy as np
from machine_learning.homework.week10.TreeNode import Node
class DecisionTreeBase:
def __init__(self, max_depth, feature_sample_rate, get_score):
self.max_depth = max_depth
self.feature_sample_rate = feature_sample_rate
self.get_score = get_score
def split_data(self, j, theta, X, idx):
idx1, idx2 = list(), list()
for i in idx:
value = X[i][j]
if value <= theta:
idx1.append(i)
else:
idx2.append(i)
return idx1, idx2
def get_random_features(self, n):
shuffled = np.random.permutation(n)
size = int(self.feature_sample_rate * n)
selected = shuffled[:size]
return selected
def find_best_split(self, X, y, idx):
m, n = X.shape
best_score = float("inf")
best_j = -1
best_theta = float("inf")
best_idx1, best_idx2 = list(), list()
selected_j = self.get_random_features(n)
for j in selected_j:
thetas = set([x[j] for x in X])
for theta in thetas:
idx1, idx2 = self.split_data(j, theta, X, idx)
if min(len(idx1), len(idx2)) == 0:
continue
score1, score2 = self.get_score(y, idx1), self.get_score(y, idx2)
w = 1.0 * len(idx1) / len(idx)
score = w * score1 + (1 - w) * score2
if score < best_score:
best_score = score
best_j = j
best_theta = theta
best_idx1 = idx1
best_idx2 = idx2
return best_j, best_theta, best_idx1, best_idx2, best_score
def generate_tree(self, X, y, idx, d):
r = Node()
r.p = np.average(y[idx], axis=0)
if d == 0 or len(idx) < 2:
return r
current_score = self.get_score(y, idx)
j, theta, idx1, idx2, score = self.find_best_split(X, y, idx)
if score >= current_score:
return r
r.j = j
r.theta = theta
r.left = self.generate_tree(X, y, idx1, d - 1)
r.right = self.generate_tree(X, y, idx2, d - 1)
return r
def fit(self, X, y):
self.root = self.generate_tree(X, y, range(len(X)), self.max_depth)
def get_prediction(self, r, x):
if r.left == None and r.right == None:
return r.p
value = x[r.j]
if value <= r.theta:
return self.get_prediction(r.left, x)
else:
return self.get_prediction(r.right, x)
def predict(self, X):
y = list()
for i in range(len(X)):
y.append(self.get_prediction(self.root, X[i]))
return np.array(y)
decisionTreeClassifier.py
import numpy as np
from machine_learning.homework.week10.decisionTreeBase import DecisionTreeBase
def get_impurity(y, idx):
p = np.average(y[idx], axis=0)
return 1 - p.dot(p.T)
def get_entropy(y, idx):
_, k = y.shape
p = np.average(y[idx], axis=0)
return - np.log(p + 0.001 * np.random.rand(k)).dot(p.T)
class DecisionTreeClassifier(DecisionTreeBase):
def __init__(self, max_depth=0, feature_sample_rate=1.0):
super().__init__(max_depth=max_depth,
feature_sample_rate=feature_sample_rate,
get_score=get_entropy)
def predict_proba(self, X):
return super().predict(X)
def predict(self, X):
proba = self.predict_proba(X)
return np.argmax(proba, axis=1)
moon.py
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from machine_learning.homework.week10.decisionTreeClassifier import DecisionTreeClassifier
from machine_learning.homework.week10.randomForestClassifier import RandomForestClassifier
from sklearn.metrics import accuracy_score
import numpy as np
def convert_to_vector(y):
m = len(y)
k = np.max(y) + 1
v = np.zeros(m * k).reshape(m,k)
for i in range(m):
v[i][y[i]] = 1
return v
X, y = make_moons(n_samples=1000, noise=0.1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
plt.figure(0)
plt.axis([-1.5, 2.5, -0.75, 1.25 ])
plt.scatter(X_train[:, 0][y_train==0], X_train[:, 1][y_train==0], c='b', marker='o', s=10)
plt.scatter(X_train[:, 0][y_train==1], X_train[:, 1][y_train==1], c='r', marker='o', s=10)
plt.show()
tree = DecisionTreeClassifier(max_depth=5)
tree.fit(X_train, convert_to_vector(y_train))
y_pred = tree.predict(X_test)
print("decision tree accuracy= {}".format(accuracy_score(y_test, y_pred)))
plt.figure(1)
x0s = np.linspace(-3, 4, 100)
x1s = np.linspace(-1, 6, 100)
x0, x1 = np.meshgrid(x0s, x1s)
W = np.c_[x0.ravel(), x1.ravel()]
u= tree.predict(W).reshape(x0.shape)
plt.axis([-1.5, 2.5, -0.75, 1.25 ])
plt.scatter(X_train[:, 0][y_train==0], X_train[:, 1][y_train==0], c='b', marker='o', s=30)
plt.scatter(X_train[:, 0][y_train==1], X_train[:, 1][y_train==1], c='g', marker='^', s=30)
plt.scatter(X_train[:, 0][y_train==2], X_train[:, 1][y_train==2], c='y', marker='s', s=30)
plt.contourf(x0, x1, u, c=u, alpha=0.2)
plt.show()
forest = RandomForestClassifier(max_depth=5, num_trees=100, feature_sample_rate=0.5, data_sample_rate=0.15)
forest.fit(X_train, convert_to_vector(y_train))
y_pred = forest.predict(X_test)
print("random forest accuracy= {}".format(accuracy_score(y_test, y_pred)))
plt.figure(2)
u= forest.predict(W).reshape(x0.shape)
plt.axis([-1.5, 2.5, -0.75, 1.25 ])
plt.scatter(X_train[:, 0][y_train==0], X_train[:, 1][y_train==0], c='b', marker='o', s=30)
plt.scatter(X_train[:, 0][y_train==1], X_train[:, 1][y_train==1], c='g', marker='^', s=30)
plt.scatter(X_train[:, 0][y_train==2], X_train[:, 1][y_train==2], c='y', marker='s', s=30)
plt.contourf(x0, x1, u, c=u, alpha=0.2)
plt.show()
randomForestClassifier.py
import numpy as np
from machine_learning.homework.week10.decisionTreeClassifier import DecisionTreeClassifier
class RandomForestClassifier:
def __init__(self, num_trees, max_depth, feature_sample_rate,
data_sample_rate, random_state=0):
self.max_depth, self.num_trees = max_depth, num_trees
self.feature_sample_rate = feature_sample_rate
self.data_sample_rate = data_sample_rate
self.trees = []
np.random.seed(random_state)
def get_data_samples(self, X, y):
shuffled_indices = np.random.permutation(len(X))
size = int(self.data_sample_rate * len(X))
selected_indices = shuffled_indices[:size]
return X[selected_indices], y[selected_indices]
def fit(self, X, y):
for t in range(self.num_trees):
X_t, y_t = self.get_data_samples(X, y)
model = DecisionTreeClassifier(
max_depth=self.max_depth,
feature_sample_rate=self.feature_sample_rate)
model.fit(X_t, y_t)
self.trees.append(model)
def predict_proba(self, X):
probas = np.array([tree.predict_proba(X) for tree in self.trees])
return np.average(probas, axis=0)
def predict(self, X):
proba = self.predict_proba(X)
return np.argmax(proba, axis=1)
TreeNode.py
# 树节点
class Node:
j = None
theta = None
p = None
left = None
right = None
原文链接:https://blog.csdn.net/weixin_42562514/article/details/106693231