NeurIPS 2020 | 近期必读模仿学习精选论文
AMiner平台由清华大学计算机系研发,拥有我国完全自主知识产权。平台包含了超过2.3亿学术论文/专利和1.36亿学者的科技图谱,提供学者评价、专家发现、智能指派、学术地图等科技情报专业化服务。系统2006年上线,吸引了全球220个国家/地区1000多万独立IP访问,数据下载量230万次,年度访问量超过1100万,成为学术搜索和社会网络挖掘研究的重要数据和实验平台。

在传统的强化学习任务中,通常通过计算累积奖赏来学习最优策略,这种方式简单直接,而且在可以获得较多训练数据的情况下有较好的表现。然而在多步决策中,学习器不能频繁地得到奖励,且这种基于累积奖赏及学习方式存在非常巨大的搜索空间。而模仿学习(Imitation Learning)的方法经过多年的发展,已经能够很好地解决多步决策问题,在机器人、NLP等领域也有很多的应用。
模仿学习是指从示教者提供的范例中学习,一般提供人类专家的决策数据,每个决策包含状态和动作序列,将所有「状态-动作对」抽取出来构造新的集合。之后就可以把状态作为特征,动作作为标记进行分类(对于离散动作)或回归(对于连续动作)的学习从而得到最优策略模型。模型的训练目标是使模型生成的状态-动作轨迹分布和输入的轨迹分布相匹配。
根据AMiner-NeurIPS 2020词云图和论文可以看出,与Imitation Learning是在本次会议中的热点,下面我们一起看看Imitation Learning主题的相关论文。

1.论文名称:BAIL: Best-Action Imitation Learning for Batch Deep Reinforcement Learning
论文链接:https://www.aminer.cn/pub/5db80dc83a55acd5c14a24a2?conf=neurips2020
简介:深度强化学习(DRL)领域最近看到了批量强化学习的研究热潮,其目的是从给定的数据集中进行高效样本的学习,而无需与环境进行其他交互。 在批处理DRL设置中,常用的非政策性DRL算法的性能可能会很差,有时甚至完全无法学习。 在本文中,我们提出了一种新的算法,即最佳动作模仿学习(BAIL),与许多非政策性DRL算法不同,该算法不涉及在动作空间上最大化Q函数。 为了简化和提高性能,BAIL首先从批处理中选择认为是其相应状态的高性能操作的操作。 然后,它使用那些状态-动作对通过模仿学习来训练策略网络。 尽管BAIL很简单,但我们证明了BAIL在Mujoco基准测试中达到了最先进的性能。
2.论文名称:Adversarial Soft Advantage Fitting: Imitation Learning without Policy Optimization
论文链接:https://www.aminer.cn/pub/5ef476b691e01165a63bba7b?conf=neurips2020
简介:对抗式模仿学习是在学习区分器(将专家的论证与已产生的论证区分开来)与生成器的策略相结合的过程之间交替进行,该策略会欺骗该区分器。在实践中,这种替代的优化方法非常微妙,因为它使不稳定的对抗训练与易碎且样本效率低下的强化学习结合在一起。我们建议通过利用新颖的区分器公式消除政策优化步骤的负担。具体来说,我们的判别器明确地以两个策略为条件:一个来自上一个生成器的迭代的策略和一个可学习的策略。优化后,该鉴别器将直接学习最佳发电机的策略。因此,我们的鉴别器更新免费解决了生成器的优化问题:学习模仿专家的策略不需要附加的优化循环。通过完全消除强化学习阶段,该公式有效地将对抗模仿学习算法的实现和计算负担减少了一半。我们在各种任务上表明,我们更简单的方法比流行的模仿学习方法更具竞争力。

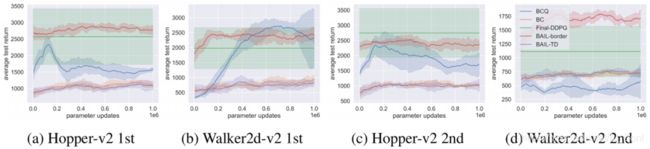
3.论文名称:Strictly Batch Imitation Learning by Energy-based Distribution Matching
论文链接:https://www.aminer.cn/pub/5ef5c78b91e011b29a6983fa?conf=neurips2020
简介:考虑纯粹根据已证明的行为来学习策略-即,没有获得强化信号的权限,没有过渡动态的知识,也没有与环境的进一步交互。在严格的批量模仿学习中,例如在医疗保健等实时实验中,这种问题都会出现。一种解决方案是简单地改造用于学徒学习的现有算法,使其可以在脱机环境下工作。但是,这种方法在模型估计或非政策评估上进行了大量讨价还价,并且可能是间接的且效率低下的。我们认为,一个好的解决方案应该能够显式地对策略进行参数化(即遵守操作条件),隐式考虑部署动态(即遵守状态边际),并且-关键地-以完全脱机的方式进行操作。为了应对这一挑战,我们提出了一种基于“基于能量的分布匹配”(EDM)的新技术:通过使用状态生成的(生成)能量函数来识别策略的(区分)模型的参数化,EDM提供了一种简单且一种有效的解决方案,可以最大程度地减少演示者和模仿者在占用率方面的差异。通过用于控制任务和医疗保健设置的应用实验,我们展示了与现有算法相比在严格批仿学习中始终具有的性能提升。
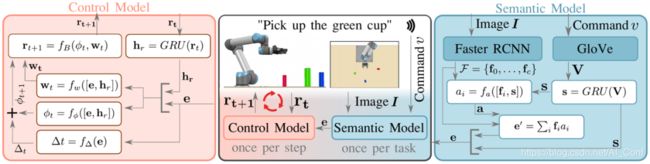
4.论文名称:Language-Conditioned Imitation Learning for Robot Manipulation Tasks
论文链接:https://www.aminer.cn/pub/5f7fdd328de39f08283980df?conf=neurips2020
简介:模仿学习是向机器人教授运动技能的一种流行方法。但是,大多数方法集中于仅从执行轨迹(即运动轨迹和感知数据)中提取策略参数。在人类专家和机器人之间没有足够的通信渠道来描述任务的关键方面,例如目标对象的属性或运动的预期形状。基于对人类教学过程的见识,我们引入了一种将非结构化自然语言纳入模仿学习的方法。在训练时,专家可以提供示范以及口头描述,以描述潜在意图(例如,“去大的绿色碗”)。然后,训练过程将这两种模态相互关联以对语言,感知和动作之间的相关性进行编码。可以在运行时以新的人工命令和指令为最终的以语言为条件的可视化运动策略进行条件调整,从而可以对受过训练的策略进行更细粒度的控制,同时还可以减少情况的歧义。我们在一组模拟实验中演示了我们的方法如何学习针对七自由度机械臂的语言条件操作策略,并将结果与多种替代方法进行比较。
5.论文名称:f-GAIL: Learning f-Divergence for Generative Adversarial Imitation Learning
论文链接:https://www.aminer.cn/pub/5f7fdd328de39f0828397b9a?conf=neurips2020
简介:模仿学习(IL)旨在从专家演示中学习一项政策,以最大程度地减少学习者与专家行为之间的差异。 已经提出了各种模仿学习算法,它们具有不同的预定差异以量化差异。 这自然会引起以下问题:给定一组专家论证,哪种分歧可以以更高的数据效率更准确地恢复专家策略? 在这项工作中,我们提出了f-GAIL,这是一种新的生成式对抗模仿学习(GAIL)模型,该模型会自动从f-分歧家庭中学习差异措施以及能够产生类似专家行为的政策。 与具有各种预定义偏差度量的IL基线相比,f-GAIL在六项基于物理的控制任务中学习了更好的策略,并具有更高的数据效率。

根据主题分类查看更多论文,扫码进入NeurIPS2020会议专题,最前沿的研究方向和最全面的论文数据等你来~
扫码了解更多NeurIPS2020会议信息

添加“小脉”微信,留言“NeurIPS”,即可加入【NeurIPS会议交流群】,与更多论文作者学习交流!
