利用ArcGIS标注数据集
一、利用ArcGIS绘制矢量图形
本篇文章以标注黄陂地区建筑物数据集为例,详细介绍了标注数据集的整个过程
1、创建shp文件
找一个合适的路径(注意:路径和所有文件的名称不要出现中文!!!),创建一个文件夹,把后面自己做的所有内容统一放在这个文件夹下。
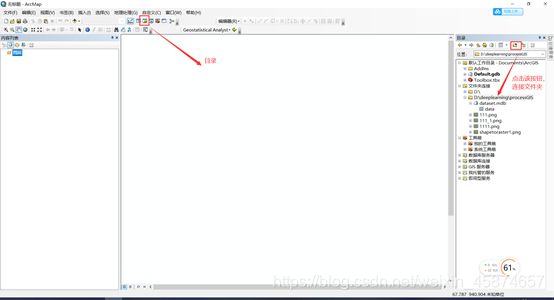
打开ArcGIS,加载影像,影像加载成功后,点击菜单栏中的【目录】。在界面右侧可以看到工作目录,点击右上角【链接到文件夹】,选择自己创建的文件夹。
右键点击连接进来的文件夹,依次选择【新建】–>【个人地理数据库】,修改数据库名称,右击数据库,依次选择【新建】–>【要素类】,在弹出的框中设置要素类的名称,要素类型选择“面要素”,点击【下一步】,直接到【完成】。


2、进行矢量化
在菜单栏的【编辑器】中选择【开始编辑】。选择刚刚创建的shp文件如“HP_ltt”
点击【创建要素】,或者在界面右侧可以看见,点击刚刚创建的shp文件“Hp_ltt”,出现【构造工具】,选择构造工具中的【面】进行绘制。

在矢量化过程中,不包括地块周围的田坎部分,我们只需要对地块的内边界以内的部分进行矢量化。如下图所示:

二、将绘制好的矢量图像导出为png格式
1、矢量转栅格
菜单栏点击【ArcToolbox】,然后依次点击【转换工具】–>【转为栅格】,双击【面转栅格】,(有些ArcGIS没有汉化的同学自己寻找对应工具),点击后如下图所示:
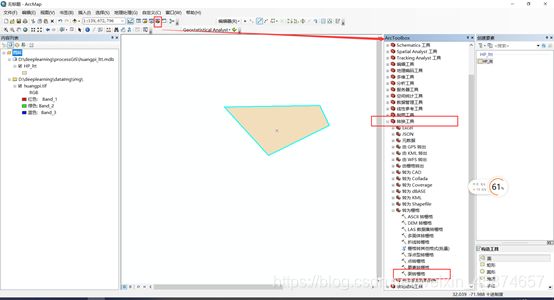
在弹出的框中选择相应的文件和路径,其中,输入文件名设置为“HP_ltt_raster”,路径中不能出现中文。如下图所示。


2、分类并输出png格式
在内容列表中右击“HP_ltt_raster”文件名,依次选择【数据】-【导出数据】,选择路径,下拉【格式】,选择“png”,文件名改为“HP_ltt_png”。点击【保存】,输出之后的图片为黑白的二值图(此时的二值图还不是我们最终想要的二值图,后面还需进一步进行转换),在ArcGIS中打开输出的图片仍然是多分类,这个不用管。如下图所示。



三、使用python代码对图像反向并将图像处理为二值图
1、安装pycharm
pycharm百度网盘
提取码:ov2r
2、安装依赖包
可以利用anoconda来管理依赖包,这个大家应该都清楚,安装os、GDAL、numpy(1.16.4)、opencv-python等依赖包
3、运行代码
invertImg.py是对图像进行反相和二值化处理的
import cv2 as cv
import numpy as np
import os
'''
对ArcGIS处理后的图像进行反相并转换为0和255的二值图
可以进行批量处理也可以进行单个图像处理
建议处理整个大的图像之后再进行裁剪
'''
def access_pixels(image_path,outdir,pixel):
# image = cv.imread(image_path,0) #获得灰度图,只有一个通道
image = cv.imread(image_path)
root, name = os.path.splitext(image_path)
imgName = root.split('\\')[-1] + name
out_image_path = os.path.join(outdir, imgName)
height, width, channels = image.shape #得到(高度,宽度,通道)即(253,302,3)
for row in range(height):
for list in range(width):
for c in range(channels):
pv = image[row, list, c]
image[row, list, c] = 255 - pv
cv.imwrite(out_image_path, np.array((image > 0) * 255)) #输出的是0和255的二值图
# print(np.array((image > 0) * 255))
def process_total(image_dir, out_dir, pixel):
'''
image_dir: 需要处理的label文件夹
out_dir: 输出文件夹
pixel: 处理成的像素值
ps: 只能处理2值图~
'''
image_list = os.listdir(image_dir)
for name in image_list:
if name.split('.')[-1] not in ['jpg', 'png', 'tif']:
continue
image_path = os.path.join(image_dir, name)
access_pixels(image_path, out_dir, pixel)
process_total("mask_png","result",256) # mask_png为图像所在的文件夹名称,result为输出图像所在的文件名称
cropImg.py是对图像进行裁剪的
import os
import gdal
import numpy as np
# 读取tif数据集
def readTif(fileName):
dataset = gdal.Open(fileName)
if dataset == None:
print(fileName + "文件无法打开")
return dataset
# 保存tif文件函数
def writeTiff(im_data, im_geotrans, im_proj, path):
if 'int8' in im_data.dtype.name:
datatype = gdal.GDT_Byte
elif 'int16' in im_data.dtype.name:
datatype = gdal.GDT_UInt16
else:
datatype = gdal.GDT_Float32
if len(im_data.shape) == 3:
im_bands, im_height, im_width = im_data.shape
elif len(im_data.shape) == 2:
im_data = np.array([im_data])
im_bands, im_height, im_width = im_data.shape
#创建文件
driver = gdal.GetDriverByName("GTiff")
dataset = driver.Create(path, int(im_width), int(im_height), int(im_bands), datatype)
if(dataset!= None):
dataset.SetGeoTransform(im_geotrans) # 写入仿射变换参数
dataset.SetProjection(im_proj)# 写入投影
for i in range(im_bands):
dataset.GetRasterBand(i + 1).WriteArray(im_data[i])
del dataset
'''
滑动窗口裁剪函数
TifPath 影像路径
SavePath 裁剪后保存目录
CropSize 裁剪尺寸
RepetitionRate 重复率
'''
def TifCrop(TifPath, SavePath, CropSize, RepetitionRate):
dataset_img = readTif(TifPath)
width = dataset_img.RasterXSize
height = dataset_img.RasterYSize
proj = dataset_img.GetProjection()
geotrans = dataset_img.GetGeoTransform()
img = dataset_img.ReadAsArray(0, 0, width, height)#获取数据
# 获取当前文件夹的文件个数len,并以len+1命名即将裁剪得到的图像
new_name = len(os.listdir(SavePath)) + 1
# 裁剪图片,重复率为RepetitionRate
for i in range(int((height - CropSize * RepetitionRate) / (CropSize * (1 - RepetitionRate)))):
for j in range(int((width - CropSize * RepetitionRate) / (CropSize * (1 - RepetitionRate)))):
# 如果图像是单波段
if(len(img.shape) == 2):
cropped = img[int(i * CropSize * (1 - RepetitionRate)) : int(i * CropSize * (1 - RepetitionRate)) + CropSize, int(j * CropSize * (1 - RepetitionRate)) : int(j * CropSize * (1 - RepetitionRate)) + CropSize]
# 如果图像是多波段
else:
cropped = img[:, int(i * CropSize * (1 - RepetitionRate)) : int(i * CropSize * (1 - RepetitionRate)) + CropSize, int(j * CropSize * (1 - RepetitionRate)) : int(j * CropSize * (1 - RepetitionRate)) + CropSize]
# 写图像
writeTiff(cropped, geotrans, proj, SavePath + "/%d.tif"%new_name)# 文件名 + 1
new_name = new_name + 1
# 向前裁剪最后一列
for i in range(int((height-CropSize*RepetitionRate)/(CropSize*(1-RepetitionRate)))):
if(len(img.shape) == 2):
cropped = img[int(i * CropSize * (1 - RepetitionRate)) : int(i * CropSize * (1 - RepetitionRate)) + CropSize, (width - CropSize) : width]
else:
cropped = img[:, int(i * CropSize * (1 - RepetitionRate)) : int(i * CropSize * (1 - RepetitionRate)) + CropSize, (width - CropSize) : width]
# 写图像
writeTiff(cropped, geotrans, proj, SavePath + "/%d.tif"%new_name)
new_name = new_name + 1
# 向前裁剪最后一行
for j in range(int((width - CropSize * RepetitionRate) / (CropSize * (1 - RepetitionRate)))):
if(len(img.shape) == 2):
cropped = img[(height - CropSize) : height, int(j * CropSize * (1 - RepetitionRate)) : int(j * CropSize * (1 - RepetitionRate)) + CropSize]
else:
cropped = img[:, (height - CropSize) : height, int(j * CropSize * (1 - RepetitionRate)) : int(j * CropSize * (1 - RepetitionRate)) + CropSize]
writeTiff(cropped, geotrans, proj, SavePath + "/%d.tif"%new_name)
# 文件名 + 1
new_name = new_name + 1
# 裁剪右下角
if(len(img.shape) == 2):
cropped = img[(height - CropSize) : height, (width - CropSize) : width]
else:
cropped = img[:, (height - CropSize) : height, (width - CropSize) : width]
writeTiff(cropped, geotrans, proj, SavePath + "/%d.tif"%new_name)
new_name = new_name + 1
# 将影像1裁剪为重复率为0.1的256×256的数据集
TifCrop(r"D:\deeplearning\dataImg\img\huangpi.tif", r"D:\deeplearning\dataImg\img\cropImg", 256, 0.0001)
在图像裁剪之前,创建两个文件夹,分别命名为“image”、“label”。图像裁剪分为两个过程,第一是对原始影像进行裁剪,将结果放在名为“image”的文件夹下;第二是对标签进行裁剪,将其结果放在名为“label”的文件夹下。标签就是经过一系列制作之后生成的0和255的二值图像。
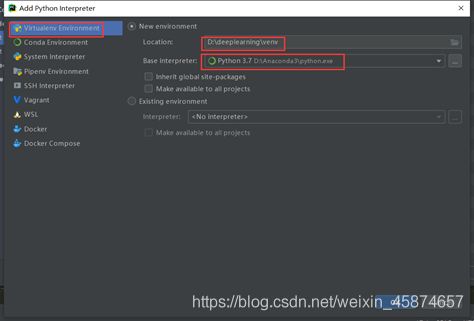
在有pycharm软件的情况下,可直接双击py文件打开,打开文件之后,一般操作是设置pycharm软件中的编译器,也就是Project Interpreter,点击【Add…】,添加自己安装的依赖包的环境下的编译器,我自己添加的是conda环境下的python编译器。切记,编译器和依赖包一定要在同一个环境下,不然运行代码时,会报错,提示找不到相应的模块。如下图所示。

最后所需要的环境配置好之后,就是简单修改代码中文件所在的路径。代码我已经进行了测试,目前没有问题。
感谢观看,祝各位炼丹小伙伴们都能心想事成!