Transformer(Attention is All You Need)
Self-Attention和Transformer - machine-learning-noteshttps://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer
1.概述
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建。
1.1Transformer为何优于RNN
RNN的计算限制是顺序的,带来两个问题:
1.时间片 t 的计算依赖 t−1 时刻的计算结果,这样限制了模型的并行能力;
2.顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力
Transoform的提出解决上述问题:
-
首先它使用了Attention机制,将序列中的任意两个位置之间的距离缩小为一个常量;
-
其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
2.Transformer模型架构
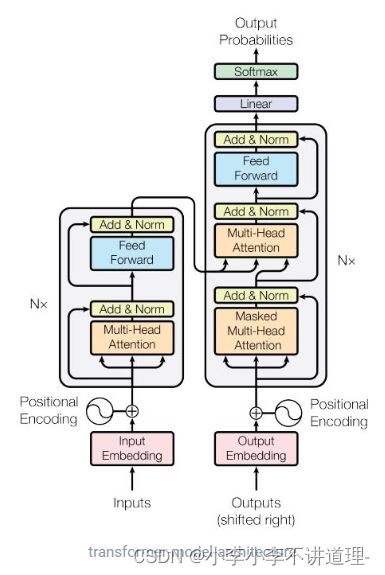
注:编码器和解码器可以是多个,注意左右边的Nx也就是,设置几个编码、解码器
2.1Encoding部分
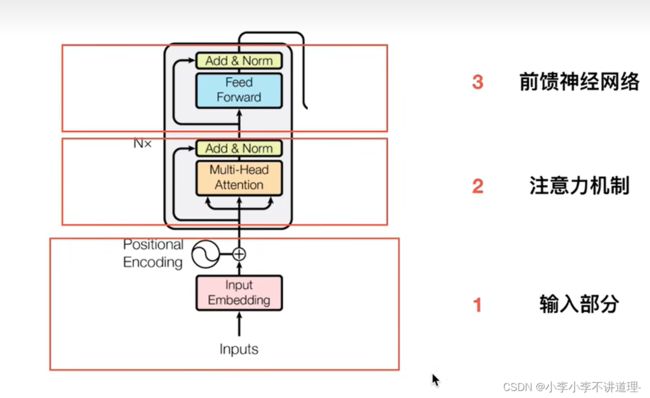
输入部分:Embedding与位置编码
Embedding:对其进行随机初始化(当然也可以选择Pre-trained的结果),但设为Trainable。这样在training过程
中不断地对embeddings进行改进。 即End2End训练方式。
位置编码:想让网络知道这个单词所在句子中的位置是什么,是想让网络做自注意力的时候,不但要知道注意力要聚焦在哪个单词上面,还想要知道单词之间的互相距离有多远。
为什么要知道单词之间的相对位置呢?因为Transformer模型没有用RNN也没有卷积,所以为了让模型能利用序列的顺序,必须输入序列中词的位置。所以我们在Encoder模块和Decoder模块的底部添加了位置编码,这些位置编码和输入的向量的维度相同,所以可以直接相加,从而将位置信息注入。
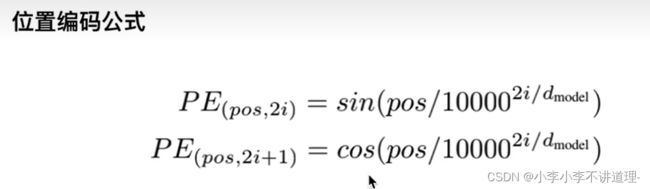
Attention机制

目的是将输入X1转换为另一个向量Z1,两个向量的维度相同
计算步骤:
1.Self-attention

x1和x2输入互相不知道对方的信息,通过W发送信息交换,所有r1,r2各自都有从x1和x2得来的信息。通俗来讲就是输入一个句子内的单词,互相看其他单词对自己的影响力有多少,
Self_attention的计算机制
上述过程中,不同Xi分享了同一个Wq,Wk,Wv,通过该操作,Xi之间发生某种程度上的信息交换。
为什么要有q,k,v向量?
该想法来自于信息检索领域,q是query,k-v是键值对,k是关键词,v是对应的值。
比对query与key的相似性。
最终的公式表示:

此处用矩阵运算是是因为能GPU加速,会更快,参数更少,更节省空间。
Dk:是q或者k的维度,这两者的维度一定是相同的,做点积运算。

multi-headed Attention
为什么需要multi-headed Attention?
让Attention有更丰富的层次,产生不同的z 。


用不同的Wq,Wk,Wv,就能得到不同的q,k,v。multi-headed Attention指用了很多不同的w。
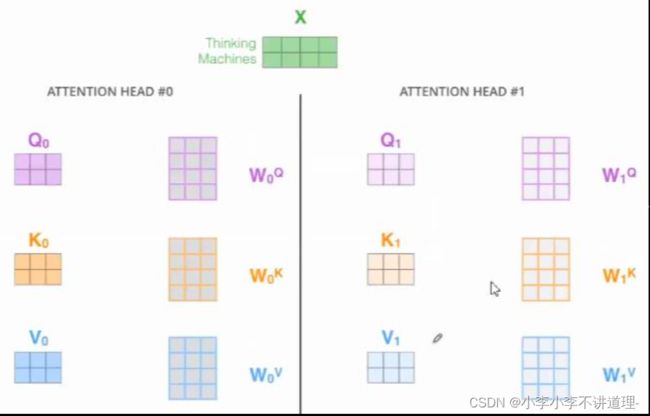
这样做的好处:让Attention有更丰富的层次,产生不同的z 。
注:最后需要将多个z,结合为一个z。

用公式表示:

3.1Decoding部分
Encoding与Decoding三大主要的不同:
-
Decoder SubLayer-1使用的是“Masked” Multi-Headed Attention机制,防止为了模型看到要预测的数据,防止泄露。
- SubLayer-2是一个Encoder-Decoder Multi-head Attention。
- LinearLayer和SoftmaxLayer作用于SubLayer-3的输出后面,来预测对应的word的probabilities 。
Multi-Headed Attention输入端
模型训练阶段:
Decoder的初始输入:训练集的标签Y,并且需要整体右移(Shifted Right)一位。
Shifted Right的原因:T-1时刻需要预测T时刻的输出,所以Decoder的输入需要整体后移一位

3.2Mask
mask表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer模型里面涉及两种mask,分别是 padding mask和sequence mask。 其中,padding mask在所有的scaled dot-product attention 里面都需要用到,而sequence mask只有在Decoder的Self-Attention里面用到。
Padding Mask
什么是padding mask呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的Attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过softmax,这些位置的概率就会接近0! 而我们的padding mask 实际上是一个张量,每个值都是一个Boolean,值为false的地方就是我们要进行处理的地方。
Sequence mask
文章前面也提到,sequence mask是为了使得Decoder不能看见未来的信息。也就是对于一个序列,在time_step为t的时刻,我们的解码输出应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出。因此我们需要想一个办法,把t之后的信息给隐藏起来。 那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
sequence mask的目的是防止Decoder “seeing the future”,就像防止考生偷看考试答案一样。这里mask是一个下三角矩阵,对角线以及对角线左下都是1,其余都是0。下面是个10维度的下三角矩阵:

4.Transforemer总结
-
优点
-
每层计算复杂度比RNN要低。
-
可以进行并行计算。
-
从计算一个序列长度为n的信息要经过的路径长度来看, CNN需要增加卷积层数来扩大视野,RNN需要从1到n逐个进行计算,而Self-attention只需要一步矩阵计算就可以。Self-Attention可以比RNN更好地解决长时依赖问题。当然如果计算量太大,比如序列长度N大于序列维度D这种情况,也可以用窗口限制Self-Attention的计算数量。
-
Self-Attention模型更可解释,Attention结果的分布表明了该模型学习到了一些语法和语义信息。
-
-
缺点:
-
有些RNN轻易可以解决的问题Transformer没做到,比如复制String,或者推理时碰到的sequence长度比训练时更长(因为碰到了没见过的position embedding)
-
理论上:transformers不是computationally universal(图灵完备),而RNN图灵。完备,这种非RNN式的模型是非图灵完备的的,无法单独完成NLP中推理、决策等计算问题(包括使用transformer的bert模型等等)。
-