新手友好 ~ kaggle 机器学习课程(Intro to ML)回顾与总结
目录
- kaggle 机器学习课程(Intro to ML)回顾与总结
-
- Kaggle课程是啥?
- Intro to ML内容总结
-
- 基本数据探索
- 解释数据描述
- 选择预测目标
- 选择特征
- 建立模型
- 什么是模型验证?
- 最后
kaggle 机器学习课程(Intro to ML)回顾与总结
前一段时间刚刚学完7个kaggle平台上的课程,个人感觉知识点比较全面,而且有的还有实战代码自己可以带着跑一遍加深理解。趁着还没忘得一干二净之前,做一下回顾复习,顺便分享给需要的机器学习入门的朋友们。再顺便练习一下markdown写法。
如果有其他推荐的学习方法,欢迎留言。求指教!
由于学完每个课程所需时间都不是很长,对于想要快速入门机器学习,数据分析的小伙伴还是挺友好的。觉得理解不足的地方可以另外自己可以再找资料补充。
Kaggle课程是啥?
- 能够快速数据科学入门,对参加kaggle比赛做项目有一定帮助
- 有的课程有实战练习
- 课程大都是由大神级别的科学家提供
- 学完课程可以获得电子证书
- 而且课程免费
Kaggle是由安东尼·高德布卢姆(Anthony Goldbloom)2010年在墨尔本创立的,世界知名的机器学习竞赛平台。Kaggle 官方表示,到目前为止在全世界范围内有超过 85 万的用户。2017年3月谷歌收购了Kaggle。在业界kaggle还算受到了较高的重视。
每学完一个kaggle平台上的课程,都会发行一个电子证书。电子证书大致长这个样子。

虽然具体不太清楚这个证书到底有多大认可度。不过kaggle作为世界上最流行的数据科学竞赛平台之一,个人觉得学习ROI(投资回报率)还算可以。
当然学习kaggle课程只是为了完善个人Profile的第一步。基础可以的人也可以直接通过打比赛来提升。
Intro to ML内容总结
通常机器学习模型来解决问题的步骤大致是这样的:
如果有现成的数据那就省了很多事情,kaggle上面一般都提供了数据,没有数据的话还要从收集数据开始,明确目标(最终通过建立机器学习模型来解决什么样的问题),确立了预测目标之后然后分析数据,对数据进行预处理,建立模型,利用模型对新数据进行预测,最后评估这个模型对新数据预测的好不好。手法很多,整个过程中比较关键的就是特征工程,还有模型调参。这里没有做特别详细的讲解。
最终建立模型是为了解决实际问题的,所以最后还需要把模型部署到实际应用中。
由于这个是入门课程,主要就讲了一下大致步骤,还有基本概念。
具体课程代码参考下面的链接:
https://www.kaggle.com/learn/intro-to-machine-learning
基本数据探索
导入pandas库 使用panda了解数据
import pandas as pd
pandas库中最重要的部分是DataFrame。 DataFrame包含类似表格的数据类型。
例如,查看澳大利亚,墨尔本的home prices数据。
使用以下命令加载和浏览数据:
#将文件路径保存到变量以便于访问
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
#读取数据并将数据存储在名为melbourne_data的DataFrame中
melbourne_data = pd.read_csv(melbourne_file_path)
#打印墨尔本数据中的数据摘要
melbourne_data.describe()
➡
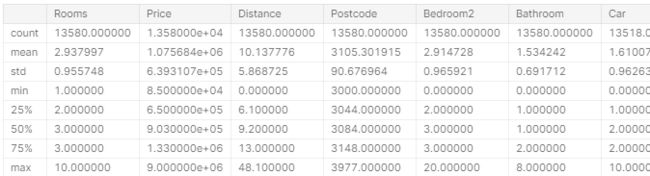
解释数据描述
结果显示原始数据集中每列有8个数字。
count:显示有多少行具有非缺失值。
mean:平均值。
std:标准偏差。它衡量在数值上的分散程度。
min,25%,50%,75%和max:跟字面意思一样。假如从最低值到最高值对每列进行排序。min就是最小值,如果遍历表的四分之一,会发现某个数字大于值的25%,小于值的75%,那么这就是值的25%。50%和75%的定义类似。max是最大值。
数据集包含太多变量,无法很好的理解,甚至无法很好地打印出来。
如何将大量的数据缩减为自己可以理解的数据?
➡
可以从使用直觉选择一些变量开始。
有很多方法可以选择数据的子集。在这里使用.columns方法打印出数据集的列名称。
此单列存储在Series中,这类似于仅包含一列数据的DataFrame。
melbourne_data.columns
➡
Index(['Suburb', 'Address', 'Rooms', 'Type', 'Price', 'Method', 'SellerG',
'Date', 'Distance', 'Postcode', 'Bedroom2', 'Bathroom', 'Car',
'Landsize', 'BuildingArea', 'YearBuilt', 'CouncilArea', 'Lattitude',
'Longtitude', 'Regionname', 'Propertycount'],
dtype='object')
选择预测目标
选择与销售价格相对应的目标变量。将其保存到名为y的目标变量中。
y = melbourne_data.Price
选择特征
输入到我们的模型中的列(之后用于预测)称为“特征”。有时更少的特征预测结果会更好。
例如在这里,选择下面的列作为用来预测房价的输入特征。
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
按照惯例,称这个数据为X。
X = melbourne_data[melbourne_features]
然后再使用describe(),head()方法来快速查看用于预测房价的数据。
X.describe()
X.head()
此处输出省略。
建立模型
使用scikit-learn库创建模型。
建立和使用模型的步骤:
定义:它将是哪种类型的模型?决策树?还是其他类型的模型?还指定了模型类型的其他一些参数。
拟合:从提供的数据中捕获模式。这是建模的核心。
预测:字面意思
评估:确定模型预测的准确性。
决策树是一种很简单的算法,他的解释性强,也符合人类的直观思维。这是一种基于if-then-else规则的有监督学习算法。
from sklearn.tree import DecisionTreeRegressor
# 定义模型。为random_state指定一个数字,以确保每次运行的结果相同
melbourne_model = DecisionTreeRegressor(random_state=1)
# Fit model 训练模型
melbourne_model.fit(X, y)
DecisionTreeRegressor(criterion='mse', max_depth=None, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=1, splitter='best')
什么是模型验证?
使用模型验证来衡量模型的质量。测量模型质量是迭代改进模型的关键。
总结模型质量有很多指标,此处以平均绝对误差(Mean Absolute Error,MAE)的指标为例。
每个房屋的预测误差为:真实值-预测值
error=actual−predicted
有了模型,就可以计算平均绝对误差。
from sklearn.metrics import mean_absolute_error
predicted_home_prices = melbourne_model.predict(X)
mean_absolute_error(y, predicted_home_prices)
➡
434.71594577146544
补充2个概念:
- overfitting
过度拟合 - 模型在训练集上表现的很好,但在验证或者其他新数据上表现不佳。
- underfitting
模型无法捕获训练数据中的重要区别和模式时,即便在训练集上模型也表现不佳。
我们关心的是根据验证数据估算出的新数据的准确性,因此我们希望找到欠拟合与过度拟合之间的最佳结合点。在下面这张图上,就是我们希望位于(红色)验证曲线的最低点。
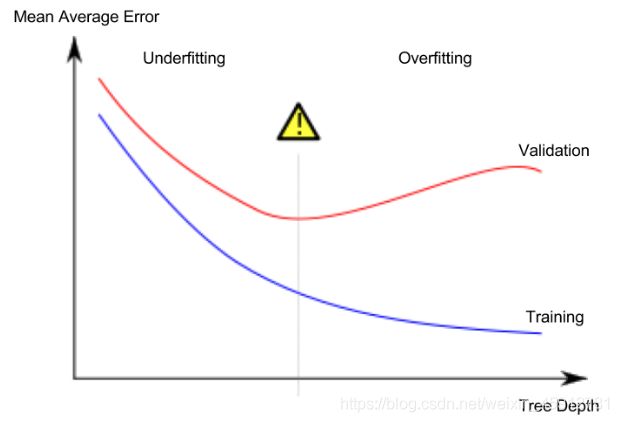
决策树模型:
一棵有很多叶子的深树会过拟合,因为每个预测都是来自仅叶子很少的房屋的历史数据。
但是,只有很少叶子的浅树性能会很差,因为它无法捕获原始数据中尽可能多的差异。
随机森林
随机森林是由很多决策树构成的,不同决策树之间没有关联。进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。与单个决策树相比,它通常具有更好的预测准确性。
最后
在后面的中级机器学习课程(之后总结)里介绍了XGBoost模型等。使用正确的参数进行调整时,模型的性能会更好(但是需要一些技巧才能获得正确的模型参数)。