SimCSE Simple Contrastive Learning of Sentence Embeddings论文解读
SimCSE: Simple Contrastive Learning of Sentence Embeddings

paper:[2104.08821] SimCSE: Simple Contrastive Learning of Sentence Embeddings (arxiv.org)
code:princeton-nlp/SimCSE: EMNLP’2021: SimCSE: Simple Contrastive Learning of Sentence Embeddings https://arxiv.org/abs/2104.08821 (github.com)
期刊/会议:EMNLP2021
摘要
本文介绍了SimCSE,一个简单的对比学习框架,极大地推进了最先进的句子嵌入。我们首先描述了一种无监督方法,该方法采用一个输入句子,并在一个对比目标中预测自己,仅使用标准dropout作为噪声。这个简单的方法出乎意料地有效,表现与之前有监督的方法相当。我们发现,dropout作为最小的数据增强,删除它会导致模型表示崩溃。然后,我们提出了一种监督方法,通过使用“蕴涵(entailment)”对作为正样本,“矛盾(contradiction)”对作为硬负样本,将来自自然语言推断数据集的标注对合并到我们的对比学习框架中。我们在标准语义文本相似性(STS)任务上评估SimCSE,使用 B E R T b a s e BERT_{base} BERTbase的无监督和有监督模型分别实现了平均76.3%和81.6%的斯皮尔曼相关性(Spearman’s correlation),与之前的最佳结果相比提高了4.2%和2.2%。我们还从理论上和经验上表明,对比学习目标将预训练的嵌入的各向异性空间(anisotropic space)正则化,使其更加均匀,并且当有监督信号可用时,它更好地对齐正样本对。
1、简介
学习通用句子嵌入是自然语言处理中的一个基本问题,其得到了广泛的研究。在这项研究中,我们提出了一个最先进的句子嵌入方法,证明对比目标与预训练语言模型(如BERT或RoBERTa)相结合时可以非常有效。我们提出了SimCSE,一个简单的对比句子嵌入框架,它可以从未标记或标记的数据中产生更好的句子嵌入。
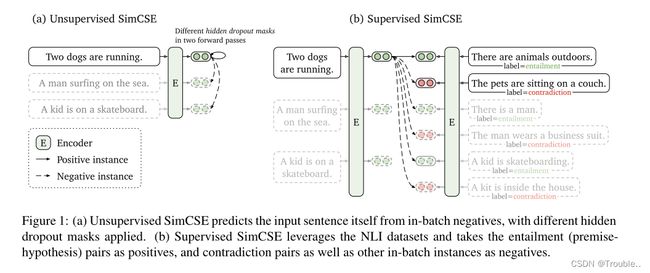
我们的无监督的SimCSE只是预测输入句子本身,只使用dropout 作为噪声(图1(a))。换句话说,我们将相同的句子传递给预训练的编码器两次:通过两次应用标准dropout,我们可以获得两个不同的嵌入作为“正对”。然后我们将同一小批量中的其他句子作为“否定”,模型将在否定中预测积极的句子。虽然它看起来非常简单,但这种方法在预测下一个句子和离散数据增强(例如,单词删除和替换)等训练目标方面表现出色,甚至与以前的监督方法相匹配。通过仔细分析,我们发现dropout作为隐藏表示的最小“数据增强”,而删除它会导致表示崩溃。
我们监督的SimCSE建立在最近成功地使用自然语言推理(NLI)数据集进行句子嵌入的基础上,并在对比学习中纳入了注释句对(图1(b))。与之前的工作不同,我们将其视为3种分类任务(蕴涵、中性和矛盾),我们利用了这样一个事实,即蕴涵对可以自然地用作积极实例。我们还发现,添加相应的矛盾对作为硬否定进一步提高性能。与之前使用相同数据集的方法相比,这种简单的NLI数据集的使用实现了实质性的改进。我们也对比了其他标签句子对数据集,发现NLI数据集对于学习句子嵌入特别有效。
为了更好地理解SimCSE的强大性能,我们借用了Wang和Isola的分析工具,该工具采用语义相关的正对之间的对齐和整个表示空间的均匀性来衡量学习嵌入的质量。通过实证分析,我们发现我们的无监督SimCSE本质上提高了均匀性,同时避免了通过dropout噪声退化对齐,从而提高了表示的表现力。同样的分析表明,NLI训练信号可以进一步改善正对之间的对齐,并产生更好的句子嵌入。我们还将其与最近的研究结果联系起来,即预训练词嵌入受到各向异性(anisotropy)的影响,并通过频谱视角(spectrum perspective)证明了对比学习目标“扁平化”了句子嵌入空间的奇异值分布,从而提高了均匀性。
我们在七个标准语义文本相似性(STS)任务和七个转化(transfer)任务上对SimCSE进行了综合评估。在STS任务中,我们的无监督和有监督模型使用 B E R T b a s e BERT_{base} BERTbase分别实现了76.3%和81.6%的平均斯皮尔曼相关性,与之前的最佳结果相比提高了4.2%和2.2%。我们在转化(transfer)任务上也取得了有竞争力的表现。最后,我们在文献中发现了一个不连贯的评价问题,并巩固了不同设置的结果,以供将来评价句子嵌入的工作。
2、背景
对比学习的目的是通过将语义上接近的邻居拉到一起并将非邻居分开来学习有效的表示。它假设有一组配对的例子 D = { ( x i , x i + ) } i = 1 m D=\{ (x_i,x_i^+) \}_{i=1}^m D={(xi,xi+)}i=1m,其中 x i x_i xi和 x i + x_i^+ xi+在语义上是相关的。我们遵循Chen等人的对比框架,并采用批内负采样的交叉熵目标函数:设 h i h_i hi和 h i + h_i^+ hi+表示 x i x_i xi和 x i + x_i^+ xi+的表示, ( x i , x i + ) (x_i,x_i^+) (xi,xi+)的训练目标为:
l i = − l o g e s i m ( h i , h i + ) / T ∑ j = 1 N e s i m ( h i , h j + ) / T l_i=-log \frac{e^{sim(h_i,h_i^+)/T}}{\sum_{j=1}^N e^{sim(h_i,h_j^+)/T}} li=−log∑j=1Nesim(hi,hj+)/Tesim(hi,hi+)/T
其中, T T T代表的是温度超参数, s i m ( h 1 , h 2 ) sim(h_1,h_2) sim(h1,h2)是余弦相似度 h 1 T h 2 ∥ h 1 ∥ ⋅ ∥ h 2 ∥ \frac{h_1^T \ h_2}{\parallel h_1 \parallel \cdot \parallel h_2 \parallel} ∥h1∥⋅∥h2∥h1T h2。在这项工作中,我们使用预训练语言模型(如BERT或RoBERTa: h = f θ ( x ) h = f_θ(x) h=fθ(x))对输入句子进行编码,然后使用对比学习目标(公式 1)对所有参数进行微调。
正例:对比学习中一个关键的问题在于怎么去构建 ( x i , x i + ) (x_i,x_i^+) (xi,xi+)对。在视觉表示中,有效的解决方案是对同一图像进行两次随机变换(例如裁剪、翻转、扭曲和旋转)作为 x i x_i xi和 x i + x_i^+ xi+ 。最近在语言表示中也采用了类似的方法,通过应用增强技术,如单词删除、重新排序和替换。然而,由于NLP的离散性,数据扩充在本质上是困难的。正如我们将在§3中看到的,简单地在中间表示上使用标准dropout比这些离散运算方式要好。
在NLP中,类似的对比学习目标已经在不同的背景下进行了探索。在这些情况下, ( x i , x i + ) (x_i,x_i^+) (xi,xi+)是从有监督的数据集中收集的,例如问答对。由于 x i x_i xi和 x i + x_i^+ xi+的性质不同,这些方法总是使用双编码器框架,即对 x i x_i xi和 x i + x_i^+ xi+使用两个独立的编码器 f θ 1 f_{θ_1} fθ1和 f θ 2 f_{θ_2} fθ2。对于句子嵌入,Logeswaran和Lee也使用双编码器方法进行对比学习,将当前句和下句形成为 ( x i , x i + ) (x_i,x_i^+) (xi,xi+)。
对齐和均匀性(Alignment and uniformity)。最近,Wang和Isola确定了与对比学习相关的两个关键属性-对齐和均匀性-并建议使用它们来衡量表征的质量。给定正对 p p o s p_{pos} ppos的分布,对齐计算成对实例嵌入之间的期望距离(假设表示已经标准化):
ℓ align ≜ E ( x , x + ) ∼ p pos ∥ f ( x ) − f ( x + ) ∥ 2 \ell_{\text {align }} \triangleq \underset{\left(x, x^{+}\right) \sim p_{\text {pos }}}{\mathbb{E}}\left\|f(x)-f\left(x^{+}\right)\right\|^{2} ℓalign ≜(x,x+)∼ppos E f(x)−f(x+) 2
另一方面,均匀性衡量嵌入均匀分布的程度:
ℓ align ≜ E ( x , y ) ∼ p data e − 2 ∥ f ( x ) − f ( y ) ∥ 2 \ell_{\text {align }} \triangleq \underset{ \left(x, y\right) \sim p_{\text {data }}}{\mathbb{E}} e^{-2 \left\|f(x)-f\left(y\right)\right\|^{2}} ℓalign ≜(x,y)∼pdata Ee−2∥f(x)−f(y)∥2
其中 p d a t a p_{data} pdata表示数据分布。这两个指标与对比学习的目标很好地一致:正例应该保持接近,随机实例的嵌入应该分散在超球面上。在下面的小节中,我们还将使用这两个度量来证明我们的方法的内部工作原理。
3、无监督SimCSE
无监督SimCSE的思想非常简单:我们取一组句子 { x i } i = 1 m \{ x_i \}_{i=1}^m {xi}i=1m ,并使用 x i + = x i x_i^+ = x_i xi+=xi。要使这一方法适用于相同的正例对,关键因素是对 x i x_i xi和 x i + x_i^+ xi+使用独立采样的dropout masks。在tranformer的标准训练中,在全连接层上放置了dropout mask以及attention概率(默认p = 0.1)。我们表示 h i z = f θ ( x i , z ) h_i^z = f_θ(x_i, z) hiz=fθ(xi,z),其中 z z z是dropout的随机掩码。我们只需将相同的输入输入到编码器两次,获得两种不同的dropout masks的嵌入 z , z ′ z,z' z,z′,训练SimCSE的目标函数将变成:
l i = − l o g e s i m ( h i z i , h i z i ′ ) / T ∑ j = 1 N e s i m ( h i z i , h j z j ′ ) / T l_i=-log \frac{e^{sim(h_i^{z_i},h_i^{z_i'})/T}}{ \sum_{j=1}^N e^{sim(h_i^{z_i},h_j^{z_j'})/T}} li=−log∑j=1Nesim(hizi,hjzj′)/Tesim(hizi,hizi′)/T
N N N是一个mini-batch中存在的句子数量。 z z z是Transformer中的标准dropout mask,我们没有使用其他的dropout。
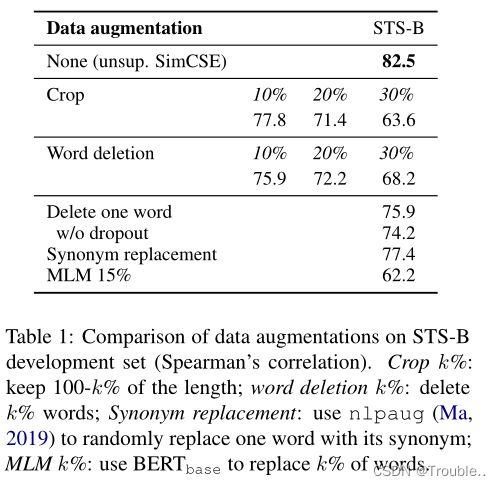
Dropout噪声作为数据增强策略。我们将其视为数据增强的一种最小形式:正对采用完全相同的语句,它们的嵌入仅在dropout mask中有所不同。我们将这种方法与STS-B开发集上的其他训练目标进行比较。表1将我们的方法与常见的数据增强技术(如裁剪、单词删除和替换)进行了比较,可以将其视为 h = f θ ( g ( x ) , z ) h=f_{\theta}(g(x),z) h=fθ(g(x),z), g g g是 x x x上的随机离散算子。我们注意到,即使删除一个单词也会影响性能,而且没有一种离散增强的效果超过dropout噪声。
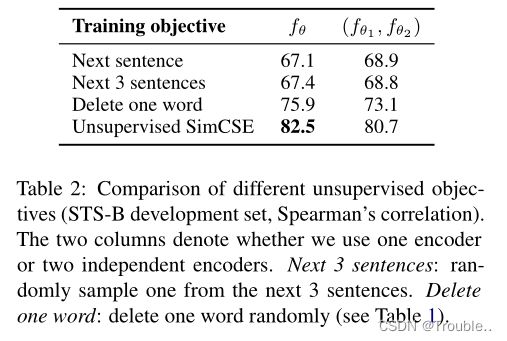
我们还将这种自我预测训练目标与Logeswaran和Lee中使用的下一句作为目标进行比较(NSP),采用一个编码器或两个独立编码器。如表2所示,我们发现SimCSE的性能比下句目标要好得多(在STSB上是82.5 vs 67.4),使用一个编码器而不是两个编码器在我们的方法中有显著差异。
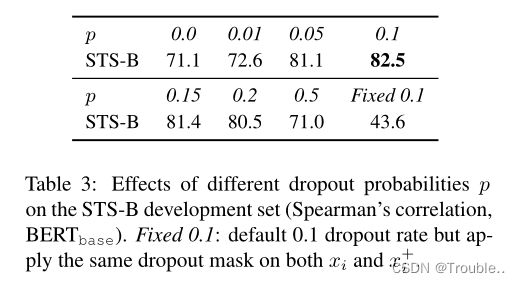
为什么它能起作用:为了进一步理解dropout noise在无监督SimCSE中的作用,我们在表3中尝试了不同的dropout比率,并观察到所有变量的性能都低于transformer的默认dropout概率p = 0.1。我们发现了两个特别有趣的极端情况:“无dropout”(p = 0)和“fixed 0.1”(使用默认dropout p = 0.1,但对其使用相同的dropout掩码)。在这两种情况下,结果的嵌入是完全相同的,这将导致显著的性能下降。在训练过程中,我们每10步对这些模型进行一次检查点,并在图2中可视化对齐和一致性度量,以及一个简单的数据增强模型“删除一个单词”。如图所示,从预训练的检查点开始,所有模型都大大提高了一致性。然而,这两个特殊变体的对齐也急剧下降,而我们的无监督SimCSE由于使用了dropout噪声而保持了稳定的对齐。它还证明了从预先训练好的检查点开始是至关重要的,因为它提供了良好的初始对齐。最后,“删除一个词”改善了对齐,但在均匀度指标上获得了较小的增益,最终性能低于无监督SimCSE。

4、监督SimCSE
我们已经证明,添加dropout噪声能够保持正例 ( x , x + ) p p o s (x, x^+) ~ p_{pos} (x,x+) ppos的良好对齐。在本节中,我们研究是否可以利用监督数据集来提供更好的训练信号,以改善我们的方法的对齐。之前的工作Conneau , Reimers和Gurevych等人已经证明了监督自然语言推理(NLI)数据集通过预测两个句子之间的关系是蕴涵、中性还是矛盾(entailment, neutral, contradiction),可以有效地学习句子嵌入。
标签数据的选择。我们首先探索哪些监督数据集特别适合构建正对 ( x i , x i + ) (x_i, x_i^+) (xi,xi+)。我们用大量带有句子对示例的数据集进行了实验,包括1)QQP4: Quora问题对;2) Flickr30k:每张图像都有5个人工编写的标题,我们认为同一图像的任意两个标题为正对;3) ParaNMT:大规模反译释义数据集;最后4)NLI数据集:SNLI和MNLI。

我们使用不同的数据集按照公式1进行训练对比学习模型,并在表4中对比各种数据集的结果。为了进行公平的比较,我们还使用相同数量的训练组进行实验。在所有选项中,使用来自NLI (SNLI + MNLI)数据集的蕴涵对性能最好。我们认为这是合理的,因为NLI数据集由高质量和众包对组成。此外,人工标注人员应该根据前提手动编写假设,使两个句子的词汇重叠较少。例如,我们发现隐含对(SNLI + MNLI)的词汇重叠(F1在两词袋之间测量)为39%,而QQP和ParaNMT的词汇重叠分别为60%和55%。
矛盾是绝对的负样本。最后,我们进一步利用NLI数据集的优势,将其矛盾对作为绝对的负样本。在NLI数据集中,给定一个前提,标注者需要手动编写一个绝对为真(蕴涵)的句子,一个可能为真(中性)的句子,以及一个绝对为假(矛盾)的句子。因此,对于每个前提及其蕴涵假设,都有一个伴随的矛盾假设(参见图1的例子)。
形式上,我们将 ( x i , x i + ) (x_i, x_i^+) (xi,xi+)扩展到 ( x i , x i + , x i − ) (x_i, x_i^+, x_i^-) (xi,xi+,xi−),其中 x i x_i xi是前提, x i + x_i^+ xi+和 x i − x_i^- xi−是蕴涵假设和矛盾假设。训练目标函数 l i l_i li定义为( N N N 为mini-batch size):
− l o g e s i m ( h i , h i + ) / T ∑ j = 1 N ( e s i m ( h i , h j + ) / T + e s i m ( h i , h j + ) / T ) -log \frac{e^{sim(h_i,h_i^+)/T}}{\sum_{j=1}^N (e^{sim(h_i,h_j^+)/T}+e^{sim(h_i,h_j^+)/T})} −log∑j=1N(esim(hi,hj+)/T+esim(hi,hj+)/T)esim(hi,hi+)/T
如表4所示,添加绝对负样本可以进一步提高性能(84.9→86.2),这是我们最终的监督SimCSE。我们还尝试添加ANLI数据集或将其与我们的无监督SimCSE方法相结合,但没有发现有意义的改进。我们还考虑了有监督的SimCSE中的双编码器框架,它会影响性能(86.2→84.2)。
5、与各向异性的连接(Connection to Anisotropy)
最近的工作确定了语言表示中的各向异性问题,即学习嵌入在向量空间中占据一个狭窄的锥,这严重限制了它们的表达能力。Gao等人证明了使用绑定输入/输出嵌入训练的语言模型会导致各向异性的词嵌入,Ethayarajh在预训练的上下文表示中进一步观察到了这一点。Wang等人表明,语言模型中词嵌入矩阵的奇异值急剧衰减:除了少数占主导地位的奇异值外,其他所有奇异值都接近于零。
缓解这一问题的一个简单方法是后处理,要么消除主导的主成分(dominant principal components),或将嵌入映射到各向同性分布(anisotropic distribution)。另一个常见的解决方案是在训练期间添加正则化。在这项工作中,我们从理论上和经验上表明,对比目标也可以缓解各向异性问题。
各向异性问题自然与均匀性有关,两者都强调嵌入应该在空间中均匀分布。直观地说,优化对比学习目标可以改善均匀性(或缓解各向异性问题),因为目标会将负实例分开。在这里,我们采用单光谱视角——这是一种常见的做法在分析词嵌入中,结果表明,对比目标可以“压扁(flatten)”句子嵌入的奇异值分布,使表示更加各向同性。
根据Wang和Isola的研究,当负实例数接近无穷大时(假设 f ( x ) f(x) f(x)是归一化的),对比学习目标(Eq. 1)的渐近性可以用下式表示:
− 1 τ E ( x , x + ) ∼ p p o s [ f ( x ) ⊤ f ( x + ) ] + E x ∼ p data [ log E x − ∼ p data [ e f ( x ) ⊤ f ( x − ) / τ ] ] -\frac{1}{\tau} \underset{\left(x, x^{+}\right) \sim p_{\mathrm{pos}}}{\mathbb{E}}\left[f(x)^{\top} f\left(x^{+}\right)\right] +\underset{x \sim p_{\text {data }}}{\mathbb{E}}\left[\log \underset{x^{-} \sim p_{\text {data }}}{\mathbb{E}}\left[e^{f(x)^{\top} f\left(x^{-}\right) / \tau}\right]\right] −τ1(x,x+)∼pposE[f(x)⊤f(x+)]+x∼pdata E[logx−∼pdata E[ef(x)⊤f(x−)/τ]]
第一项保持正实例相似,第二项将负实例分开。当 p d a t a p_{data} pdata在有限样本 { x i } i = 1 m \{ x_i \}_{i=1}^m {xi}i=1m上是一致的,且 h i = f ( x i ) h_i = f(x_i) hi=f(xi)时,我们可以用Jensen不等式从第二项推导出如下公式:
E x ∼ p data [ log ∼ p data x − E [ e f ( x ) ⊤ f ( x − ) / τ ] ] = 1 m ∑ i = 1 m log ( 1 m ∑ j = 1 m e h i ⊤ h j / τ ) ≥ 1 τ m 2 ∑ i = 1 m ∑ j = 1 m h i ⊤ h j . \begin{aligned} & \underset{x \sim p_{\text {data }}}{\mathbb{E}}\left[\log \underset{x^{-}}{\mathbb{\sim} p_{\text {data }}} \mathbb{E}\left[e^{\left.f(x)^{\top} f\left(x^{-}\right) / \tau\right]}\right]\right. \\ = & \frac{1}{m} \sum_{i=1}^{m} \log \left(\frac{1}{m} \sum_{j=1}^{m} e^{\mathbf{h}_{i}^{\top} \mathbf{h}_{j} / \tau}\right) \\ \geq & \frac{1}{\tau m^{2}} \sum_{i=1}^{m} \sum_{j=1}^{m} \mathbf{h}_{i}^{\top} \mathbf{h}_{j} . \end{aligned} =≥x∼pdata E[logx−∼pdata E[ef(x)⊤f(x−)/τ]]m1i=1∑mlog(m1j=1∑mehi⊤hj/τ)τm21i=1∑mj=1∑mhi⊤hj.
设 W W W为 { x i } i = 1 m \{x_i\}_{i=1}^m {xi}i=1m对应的句子嵌入矩阵,即 W W W的第 i i i行为 h i h_i hi。优化Eq. 6中的第二项本质上是最小化 W W T WW^T WWT中所有元素总和的上界,即 S u m ( W W T ) = ∑ i = 1 m ∑ j = 1 m h i T h j Sum(WW^T)=\sum_{i=1}^m \sum_{j=1}^m h_i^Th_j Sum(WWT)=∑i=1m∑j=1mhiThj。
由于我们将 h i h_i hi归一化,所以 W W T WW^T WWT对角线上的所有元素都是1,那么 t r ( W W T ) tr(WW^T) tr(WWT)(所有特征值的和)是一个常数。根据Merikoski,如果 W W T WW^T WWT中的所有元素都是正的,根据图G.1大多数时候都是这样,那么 S u m ( W W T ) Sum(WW^T) Sum(WWT)是 W W T WW^T WWT最大特征值的上界。在最小化Eq. 6中的第二项时,我们减少了 W W T WW^T WWT的顶部特征值,并固有地“平坦”了嵌入空间的奇异值。因此,对比学习有望缓解表征退化问题,提高句子嵌入的均匀性。
与Li等人的后处理方法相比,Su等人仅旨在鼓励各向同性表示,对比学习还优化了通过Eq. 6中的第一项对齐正对,这是SimCSE成功的关键。§7给出了定量分析。
6、实验
6.1 评估设置
我们对7个语义文本相似性(STS)任务进行了实验。请注意,我们所有的STS实验都是完全无监督的,并且没有使用STS训练集。即使是有监督的SimCSE,我们也只是指在之前的工作之后,我们采用外部的标签数据集进行训练。我们还评估了7个迁移学习任务,并在附录E中提供了详细的结果。我们与Reimers和Gurevych有相似的观点,句子嵌入的主要目标是聚类语义相似的句子,因此将STS作为主要结果。
语义文本相似任务:我们评估了7个STS任务:STS 2012 - 2016 ,STS Benchmark和SICKRelatedness。当与以前的工作进行比较时,我们在评估设置中识别了已发表论文中的无效比较模式,包括(a)是否使用额外的回归量,(b) Spearman与Pearson的相关性,以及©结果如何聚合(表B.1)。我们在附录B中讨论了详细的差异,并选择在我们的评估中遵循Reimers和Gurevych的设置(没有额外的回归因子,Spearman的相关性和“全部”聚合)。我们还在表B.2和表B.3中报告了我们对以前工作的重复研究以及我们在不同环境下评估的结果。我们呼吁统一句子嵌入评价的设置,以供未来研究参考。
训练设置:我们从BERT (uncase)或RoBERTa(case)的预训练检查点开始,并将[CLS]表示作为句子嵌入9(参见§6.3不同池化方法的比较)。我们在106个随机抽取的英语维基百科句子上训练无监督SimCSE,并在MNLI和SNLI数据集(314k)的组合上训练有监督SimCSE。更多的训练细节可以在附录A中找到。
6.2 主要的结果
我们将无监督和有监督的SimCSE与以前最先进的STS任务中的句子嵌入方法进行了比较。无监督基线包括平均GloVe嵌入,平均BERT或RoBERTa嵌入,以及BERT-flow和bert-whitening等后处理方法。我们还比较了使用对比目标的几种最近的方法,包括1)IS-BERT ,它最大限度地提高了全局和局部特征之间的一致性;2) DeCLUTR ,将同一文档的不同跨度作为正对;3) CT,将来自两个不同编码器的同一句子的嵌入对齐。其他的方式包括InferSent,Universal Sentence Encoder, SBERT/SRoBERTa。我们提供详细的设置在附件C中。
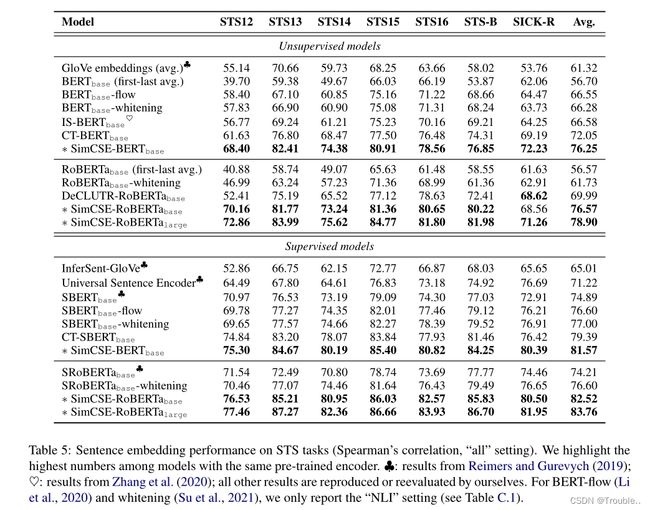
表5显示了7个STS任务的评估结果。SimCSE在有或没有额外的NLI监督的情况下都可以显著改善所有数据集上的结果,大大超过了以前最先进的模型。具体来说,我们的无监督simsse - bertbase将之前的最佳平均斯皮尔曼相关性从72.05%提高到76.25%,甚至可以与有监督基线相媲美。当使用NLI数据集时, S i m C S E − B E R T b a s e SimCSE-BERT_{base} SimCSE−BERTbase进一步将最先进的结果推向81.57%。在RoBERTa编码器上的增益更加明显,我们的监督SimCSE在 R o B E R T a l a r g e RoBERTa_{large} RoBERTalarge上达到83.76%。
在附录E中,我们展示了与现有工作相比,SimCSE也实现了同等或更好的传输任务性能,并且辅助MLM目标可以进一步提高性能。
6.3 消融实验
我们调查了不同的池化方法和硬负样本的影响。本节中报告的所有结果都基于STS-B开发集。我们在附录D中提供了更多的消融研究(归一化、温度和MLM目标)。
池化方式:Reimers和Gurevych、Li等人表明,采用预训练模型的平均嵌入(特别是来自第一层和最后一层)会导致比[CLS]更好的性能。表6显示了无监督和有监督SimCSE中不同池化方法的比较。对于[CLS]表示,原始的BERT实现在其之上附加了一个MLP层。在这里,我们考虑了[CLS]的三种不同设置:1)保持MLP层;2)无MLP层;3)训练时保留MLP,测试时移除。我们发现,对于无监督的SimCSE,只在训练期间使用MLP的[CLS]表示效果最好;对于受监督的SimCSE,不同的池化方法关系不大。默认情况下,我们将[CLS]与MLP (train)用于无监督的SimCSE,将[CLS]与MLP用于有监督的SimCSE。
硬负样本:直观地说,将硬负样本(矛盾的例子)与其他批次负样本区分开来可能是有益的。因此,我们扩展了Eq. 5中定义的训练目标,以纳入不同负面的权重:
− l o g e s i m ( h i , h i + ) / T ∑ j = 1 N ( e s i m ( h i , h j + ) / T + α 1 i j e s i m ( h i , h j + ) / T ) -log \frac{e^{sim(h_i,h_i^+)/T}}{\sum_{j=1}^N (e^{sim(h_i,h_j^+)/T}+\alpha^{1_i^j} e^{sim(h_i,h_j^+)/T})} −log∑j=1N(esim(hi,hj+)/T+α1ijesim(hi,hj+)/T)esim(hi,hi+)/T
1 i j ∈ { 0 , 1 } 1_i^j \in \{ 0,1\} 1ij∈{0,1}是当且仅当 i = j i = j i=j时等于1的指标。我们用不同的α值训练SimCSE,并在STS-B的开发集上评估训练的模型。我们也考虑将中性假设作为硬否定。如表7所示,α = 1表现最好,中性假设不能带来进一步的收益。


7、分析
在本节中,我们将进行进一步的分析,以理解SimCSE的内部工作原理。
一致性和对齐。图3显示了不同句子嵌入模型及其平均STS结果的均匀性和对齐性。一般来说,同时具有更好的对齐性和均匀性的模型可以获得更好的性能,这证实了Wang和Isola的发现。我们还观察到(1)虽然预训练的嵌入具有良好的对齐性,但它们的均匀性很差(即嵌入具有高度的各向异性);(2) BERT-flow、BERT-whitening等后处理方法在改善均匀性的同时,也会导致一致性的退化;(3)无监督SimCSE在保持良好对齐的同时,有效地提高了预训练嵌入的均匀性;(4)在SimCSE中纳入监督数据进一步修正对齐。在附录F中,我们进一步展示了SimCSE可以有效地平坦预训练嵌入的奇异值分布。在附录G中,我们演示了SimCSE在不同的句子对之间提供了更多可区分的余弦相似度。
定性比较。我们使用 S B E R T b a s e SBERT_{base} SBERTbase和 S i m C S E − B E R T b a s e SimCSE-BERT_{base} SimCSE−BERTbase进行了小规模检索实验。我们使用Flickr30k数据集中的150k字幕,以任意一个随机句子作为查询,检索相似句子(基于余弦相似度)。如表8所示的几个例子所示,与SBERT检索的句子相比,SimCSE检索的句子质量更高。

8、相关工作
句子嵌入的早期工作建立在分布假设的基础上,通过预测给定句子的周围句子,表明简单地用n-gram嵌入来增强word2vec 的思想会带来强大的结果。最近(和并发)的几种方法采用了对比目标通过对同一句话或文件采取不同的观点——从数据增强或模型的不同副本。与这些工作相比,SimCSE使用了最简单的思想,从标准dropout中获取同一句话的不同输出,并在STS任务中执行得最好。
有监督的句子嵌入被承诺比无监督的句子嵌入有更强的性能。Conneau等人提出对NLI数据集上的Siamese模型进行微调,该模型进一步扩展到其他编码器或预训练模型。此外,Wieting和Gimpel ;Wieting等人证明双语和反译语料库为学习语义相似性提供了有用的监督。另一个工作重点是正则化嵌入来缓解表征退化问题(如§5所述),并产生了比预训练语言模型的实质性改进。
9、总结
在这项工作中,我们提出了SimCSE,一个简单的对比学习框架,它极大地提高了语义文本相似任务中最先进的句子嵌入。我们提出了一种无监督方法来预测输入句子本身的dropout噪声和一种监督方法利用NLI数据集。通过分析SimCSE与其他基线模型的一致性和一致性,我们进一步证明了我们的方法的内部工作。我们相信,我们的对比目标,特别是无监督的目标,可能在自然语言处理中有更广泛的应用。它为文本输入的数据增强提供了一个新的视角,可以扩展到其他连续表示,并集成到语言模型预训练中。
相关阅读
对比学习(Contrastive Learning):研究进展精要 - 知乎 (zhihu.com) 强烈推荐小白看一下