什么是contrastive learning?
阅读更多,欢迎关注公众号:论文收割机(paper_reader)
因为排版问题,很多图片和公式无法直接显示,欢迎关注我们的公众号点击目录来阅读原文。
引言
对比学习最近特别火,为了弄懂这个方向以及需要解决的问题,所以本文将各个领域内比较重要的一些工作拿出来介绍讨论一下。对比学习(Contrastive learning)的主要是与自学习(self-supervised learning)结合起来,从而挖掘数据集本身的一些特性,来帮助模型进行无标签的学习。
计算机视觉
-
SimCLR
对比学习在计算机视觉中的一篇代表作就是Hinton的SimCLR的模型
A Simple Framework for Contrastive Learning of Visual Representations, ICML 2020
这篇文章使用了一个非常简单的框架,将计算机视觉中任务的表现力都提升了不少。模型非常简单,如下图
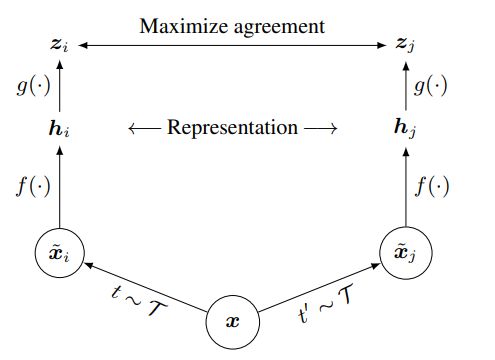
这里面涉及到四个模块:
-
数据增广(data augmentation)$\tau$ (τ)。这个模块将数据进行变化,比如一张图片进行裁剪,颜色变化之类的操作,从而得到新的数据。这个部分是比较重要的,之后我们单独拿出来介绍。
-
数据编码(encoder)f(·)。这个部分就是模型,比如一个深度的神经网络。
-
投影首部(projection header)g(·)。这个部分是为了将两个编码的向量投影到共同的空间中进行对比学习。
-
对比损失函数(contrastive loss)。也就是图中的maximize agreement。
整个对比学习的流程如下,首先对一个样本进行两次数据增广,这样就得到两个本身并不在数据中存在的样本,分别将两个样本通过左边的数据编码和投影头部,就能得到两个向量,z_i, z_j。此时因为这两个新的样本都是从同一个样本中产生出的,所以它们应该具有相似的信息。这时候,通过对比损失函数来最大化这两个向量之间的相似度,从而就可以优化模型。损失函数如下:
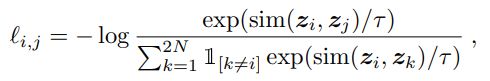
可以看到,我们需要去定义sim函数,也就是相似度函数,一般是余弦相似度。同时,观察分母可以看到这个是把其他样本作为负样本来处理。
数据增广一般是与模型无关的方法, 在图片中有如下的操作

crop,flip,color,rotate等等。这些操作如果都是针对一张图的,那么就是产生一对正样本,否则,就是负样本。通过不同数据增广的组合,实验得到如下的结论
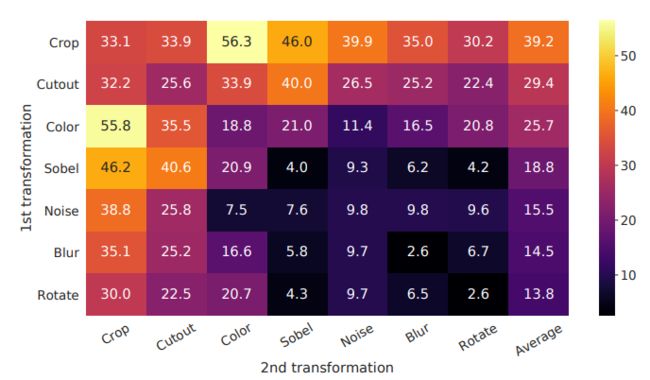
数值代表预测的准确率。可以看到简单的颜色变化以及截块的操作,就能够达到非常好的效果,所以结论就是数据增广的方式越简单,越能够反映样本的特性越好。
-
MoCo
除了Hinton的这篇文章,Kaiming也提出了一个新的计算框架,MOCO
Momentum Contrast for Unsupervised Visual Representation Learning, CVPR 2020
这篇文章的主要思路就是让训练过程中不再需要很大的batch size,也能够很好的产生对比损失,模型核心如下

query和key都是与之前的数据增广相同的样本,不同的是,这里的key是在训练中用字典保存的,这样就可以保存大量的key样本,而每次训练的时候,只需要输入小batch就可以达到比较好的训练效果。伪代码如下:

如果看一下文章中的伪代码,就会发现设计起来是这样子的思路:
-
首先初始化两个相同的模型;
-
拿出一组样本来生成数据增广样本;
-
计算损失函数;
-
将key分支的模型的update与query分支的模型分隔开,然后通过momentum的方式来更新key分支的模型;
-
将目前batch里的样本放到key 字典中 (enqueue/dequeue)
-
重复迭代。
通过这两篇文章,我们比较清楚的知道了对比学习中比较关键点就是在于如何构建augmentation,不同的方式得到的样本对下游任务提供的信息帮助是不同的。除了CV里的对比学习,接下来我们介绍NLP里的对比学习。
自然语言处理
NLP任务中的数据主要是文本数据,文本数据与图片最大的不同就是样本的输入形式就已经是离散的,所以这里面就会导致在数据augmentation的方式上会有所不同。
-
CLEAR
CLEAR: Contrastive Learning for Sentence Representation, arxiv 2020
这是一篇整体上对文书数据如何做augmentation讲的比较全面的对比学习的文章,训练框架基本上与SimCLR相同:
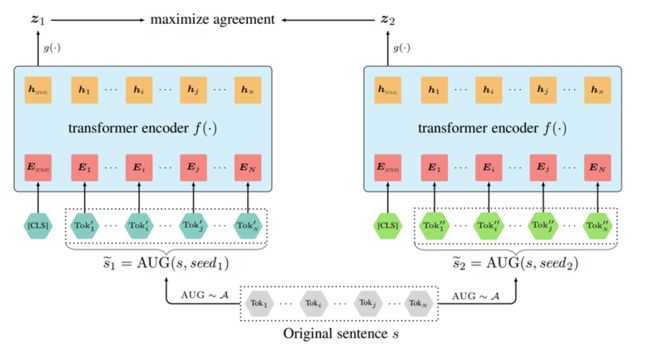
但是在augmentation上,是通过以下的四种方式
-
词语删除;
-
片段删除;
-
次序重排;
-
同义词替换。
这四种方式能够重复的利用已有的数据去生成更多的新的样本,从而完成对比学习的训练。这篇文章在训练上将mask language model (MLM),也就是transformer中常用的训练方式与contrastive learning loss结合起来,构成了一个整体的loss:

这样就能够充分利用好数据进行预训练。
讲到文本数据的augmentation,其实可以研究一下一篇2019年EMNLP的文章:
-
EDA
Wei, Jason, and Kai Zou. "EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks." EMNLP-IJCNLP. 2019.
这篇文章也介绍类似的数据增广的方式,虽然不是在对比学习中使用的,但是其中的设计也是借鉴的。文中提到了以下的数据增广的方式
-
同义词替换(Synonym Replacement)
-
随机插入
-
随机交换
-
随机删除
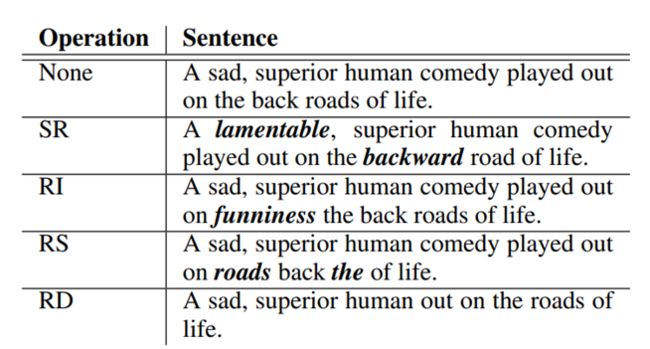

通过这样的几种方式,通过增加了训练的数据量来增强模型的健壮性。
图
相对文本以及图像数据,图数据具有更强的结构性,属于高维的数据。因此也是具有一些特殊的数据增广的方式。
-
GraphCL
Graph Contrastive Learning with Augmentations (GraphCL), NIPS 2020
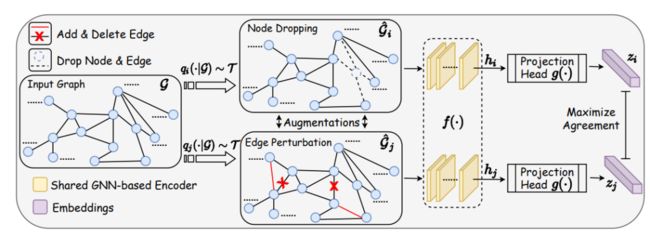
其中从node和edge的角度可以分别做augmentation。比如通过随机删除一些节点,或者对边进行随机的变化(perturbation)。
-
GCC
GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training, KDD 2020

除了GraphCL这种,GCC也提出了可以通过random walk来生成正样本以及负样本。GCC中的一个节点的样本是它周围通过随机游走产生的一个子图。如果两个子图是同一个节点随机游走生成的子图,那么就是一对正样本,否则就是负样本,这样就可以完成对比学习。
推荐系统
基于图的对比学习,也促进了推荐系统领域对于该训练框架的讨论,今年SIGIR2021 上就有一篇SGL的文章,通过将现有的图神经网络协同过滤模型与对比学习结合
Wu, Jiancan, et al. "Self-supervised Graph Learning for Recommendation." arXiv preprint arXiv:2010.10783 (2020).
值得注意的是该文的共同作者也是比较有名的NGCF,LightGCN的作者xiang wang以及xiangnan he。SGL模型在对比学习上的整体框架也是与之前类似的,需要进行数据增广,然后对比学习。当然,推荐系统中的对比学习更类似于图上的对比学习,所以SGL也是对node以及edge进行操作
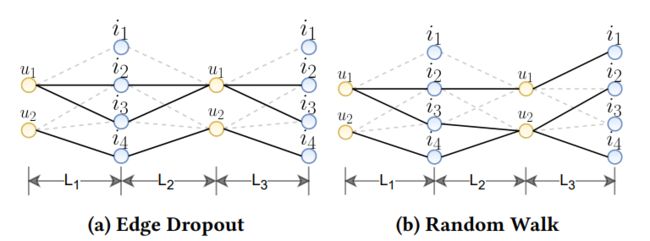
三种不同的augmentation:
-
node drop
-
edge drop
-
random walk
值得注意的是,这里的random walk不再是完全的随机游走,而是强调edge drop的layer-wise的特性。
总结
这篇文章简单梳理了图像,文本,图,以及推荐系统领域里的几个比较典型的使用对比学习来进行训练的模型。目前来看对比学习的核心点还是在于进行数据增广,以及应用对比损失函数来。不过也有一些最新的工作讨论到除了直接对样本进行修改,也可以考虑加drop-out来改变模型输出从而得到新的样本,比如SimCSE:
Gao, Tianyu, Xingcheng Yao, and Danqi Chen. "SimCSE: Simple Contrastive Learning of Sentence Embeddings." arXiv preprint arXiv:2104.08821 (2021).
这篇文章就提出只要在transformer里加一层drop-out mask,就可以进行很好的对比学习。
目前来看,对比学习还是处于蓬勃代发的状态,大家感兴趣的应该都可以参与进来这个方向进行研究。
笔者也在逐步整理了一些对比学习上的文章,可以大家一起学习,可以点击访问链接
https://github.com/ContrastiveSR/Contrastive_Learning_Papers

阅读更多,欢迎关注公众号:论文收割机(paper_reader)
因为排版问题,很多图片和公式无法直接显示,欢迎关注我们的公众号点击目录来阅读原文。
往期文章:
-
WWW'21 | 图神经网络增量学习在事件检测中的应用
-
KDD’20 | 解决会话(session)推荐中图神经网络的信息损失问题
-
序列推荐模型梳理(Sequential Recommendation)