RPN遇到的坑
RPN的作用在于较为准确的选择前300个推荐框,前2篇论(RCNN,Fast-RCNN)用的是Selective Search方法, 贪婪地合并基于低层次特征的像素,产生2000个推荐框,效率低。本文主要讲解RPN网络层及其损失函数,遇到过的坑和疑惑的地方在这里记录一下,便于今后回顾。涉及到的内容过多,请参考:
Faster-RCNN论文地址
1、RPN模型
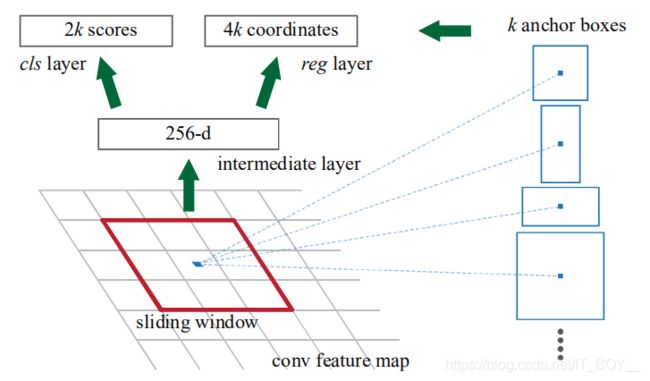
要点1:在每个滑动窗口的中心(经过3x3卷积得到的点,该卷积层不改变feature map的大小,只是将周围的信息融合到中心点上,该中心点的可视野为3x3大小的VGG/ZF特征)预测9种不同尺度大小的锚框(anchors)。这里用的是ZF的feature map 是256-d,而VGG的feature map 是512-d。
vgg_kernel = 512 #如何实现anysize input
f_map_tile = Input(shape=(None,None,512)) #out: 1x1x512
convolution_3x3 = Conv2D(
filters=512, #vgg 512, zf 256
kernel_size=(3, 3),
padding='same',
activation='relu',
name="3x3"
)(f_map_tile) #out: 1x1x512
output_deltas = Conv2D(
filters= 4 * k,
kernel_size=(1, 1), #1x1卷积的作用?
activation="linear",
kernel_initializer="uniform",
name="deltas1"
)(convolution_3x3) #out: 1x1x36
output_scores = Conv2D(
filters=2 * k, #能否换成1*k?
kernel_size=(1, 1),
activation="softmax",
kernel_initializer="uniform",
name="scores1"
)(convolution_3x3) #out: 1x1x18
model = Model(inputs=[feature_map_tile], outputs=[output_scores, output_deltas])
要点2:论文一个框有2种分类(前景和背景),用了2个编码,使用softmax激活函数,而我这里用sigmoid激活函数,0代表背景,1代表前景。这里有一个两难的选择,是将整个feature map放入,还是只放入1x1的feature map。这里要提一下,VGG是有5层池化层,故32倍下采样。
1、如果放入整个feature map的话,那么预测的是WHK个锚框,在这些锚框中,很多是无关锚框(既不是IOU>0.7的锚框,又不是<0.3的锚框),这些无关锚框也要喂入网络,但是不参与损失计算。更麻烦的是,我无法控制前景和背景的比例及数量,通过调节IOU阈值来控制不是正确的方法,若要实现any size image 输入,那么就不能批量训练了,得一张一张feature map喂。
2、如果只喂一部分feature map的话,我就很方便了,我只需选择好前景和背景,然后将前景和背景按1:1的比例喂入网络即可,这样一个batch可以实现喂入多张图像。我用VGG16得到下采样32倍的feature map,这已经算是高级特征了,由feature map 的特征点产生9个锚框(这9个锚框得保证不能都存在前景和背景框,所以IOU阈值控制很重要),喂数据的时候,锚框和特征点要对应起来。这样做的话,3x3的卷积层就没啥作用了,因为1x1的feature map用3x3卷积核卷积的结果还是自己的信息。通过实验,这个效果还行,缺点也是有的,因为32倍下采样了,小物体信息很容易丢失,小物体很难框到。
2、Loss

这里就不翻译了,还是原滋原味的好。
- i : the index of an anchor in a mini-batch
- pi : the predicted probability of anchor i being an object.
- p∗: the ground-truth label,1 if the anchor is positive, and is 0 if the anchor is negative.
- ti: a vector representing the 4 parameterized coordinates of the predicted bounding box, the predicted bounding box associated with a positive anchor
- t∗: the ground-truth box associated with a
positive anchor
要点3:分类损失很简单,使用分类交叉(categorical_crossentropy)作为损失函数即可。这里主要探讨一下回归损失。看下图,回归网络的输出不是坐标值,而是相对于锚框(anchors)的偏移值,用偏移值更利于网络的收敛,当回归损失趋近0时,意味着预测坐标趋近于真实坐标。

x: predicted box
xa: anchor box
x∗: ground truth box
原文:Variables x, xa, and x∗ are for the predicted box, anchor box, and ground-truth box respectively (likewise for y, w, h).
![]()
下图的x=![]()

测试
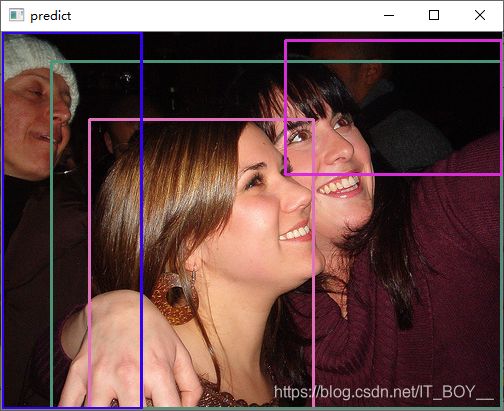
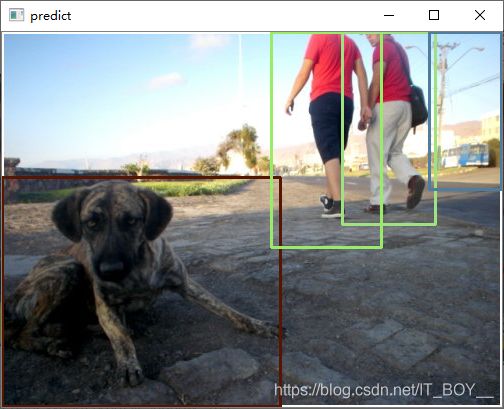
总共会预测大约300个框,我将最好的几个框挑出来显示,效果如下:

总结
只看论文,不去复现,很难理解论文精髓和缺陷,需要两者结合才有更好的效果,矩阵运算很重要,不会操作矩阵,编程寸步难行。最新的实例分割(Parsing-rcnn),目标跟踪(SiamRPN++)等算法都引用了RPN,RPN在faster-rcnn中首次提出,也使得faster-rcnn成为了当时最好的目标检测算法之一,但是yolo从V2版本就赶超了faster-rcnn,yoloV2提到锚框思想,但最终没有采纳,用了另一种方式替代了它。目前yolo已经发展到V4了,成了工业上默认的目标检测算法,可见技术迭代之快。
如有需要,可参考代码:
https://github.com/justDoIt1314/RPN