python实现-决策树2-sklearn
sklearn代码
sklearn步骤:
1,实例化 2,通过模型接口训练数据 3,通过模型接口提取需要的信息
主要代码:
from sklearn import tree #导入模块
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(x_train, y_train,) #用训练集数据训练模型
result = clf.score(X_test, y_test) #导入测试集,得结果
sklearn用不纯度Criterion来确定确定最佳节点,可选信息熵或者基尼系数作为Criterion
from sklearn import tree #导入树模块
from sklearn.datasets import load_wine #导入红酒数据
from sklearn.model_selection import train_test_split #划分训练集测试集
wine = load_wine() #下载数据,字典形式
wine.data #标签列
wine.data.shape
wine.target #标签列
import pandas as pd
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
#连接起来,形成表格式
wine.feature_names #特征名
wine.target_names #目标列的类
xtrain,xtest,ytrain,ytest=train_test_split(wine.data,wine.target,test_size=0.3)
#按30%测试集,70%训练集划分数据
xtrain.shape
xtest.shape
clf=tree.DecisionTreeClassifier(criterion='entropy')
#实例化 criterion选择信息增益,默认的是基尼系数
#
#random_state设置了一个随机种子,保证了每次结果输出一致
clf=clf.fit(xtrain,ytrain) #训练模型
score=clf.score(xtest,ytest) #返回预测的准确度
score
import graphviz
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
#特征名转成了中文
dot_data = tree.export_graphviz(clf
,feature_names = feature_name
,class_names=["威士忌","伏特加","琴酒"]
,filled=True
,rounded = True
)
#filled - 是否填充颜色
#rounded - 框的形状
graph = graphviz.Source(dot_data)
graph
#不纯度为0 时,可以选择出叶子节点
clf.feature_importances_
#显示决策树选择的特征,以及其对应的贡献
#没有使用的特征,重要性是0
[*zip(feature_name,clf.feature_importances_)]
#将特征的名字和对应的重要性进行匹配
#根节点 类黄酮 贡献最大
#训练集上的拟合效果
score_train=clf.score(xtrain,ytrain)
score_train
#不能认为过拟合,因为测试集score也不错
剪枝参数1
正确的剪枝是优化的核心
max_depth 限制树的最大深度,建议从3开始测试
min_samples_leaf 限定n,一个节点在分支后的每个子节点都至少有n个训练样本,建议从5开始
min_samples_split 限定n,一个节点至少有n个训练样本,建议从5开始
#重新生成模型,加上剪枝参数
clf=tree.DecisionTreeClassifier(criterion='entropy'
,random_state=30
,splitter='random'
,max_depth=3
# ,min_samples_leaf=10
,min_samples_split=10)
#
clf = clf.fit(xtrain,ytrain) #训练模型
dot_data = tree.export_graphviz(clf
,feature_names = feature_name
,class_names=["威士忌","伏特加","琴酒"]
,filled=True
,rounded = True
)
graph = graphviz.Source(dot_data)
graph
#不纯度为0 时,可以选择出叶子节点
#训练集上的拟合效果
score_train=clf.score(xtrain,ytrain)
score_train
#剪枝后的拟合效果
score=clf.score(xtest,ytest)
score
剪枝参数2
max_features 限制可以使用的特征数量,例如特征900个太多了
min_impurity_decrease 设定一个阈值,信息增益在小于该阈值时,不再进行分支
确定最优的剪枝参数,最优参数不能一个一个的尝试
# 默认的max_depth是1,但是由于分到最后一个可能会导致过拟合的情况出现,因此经常使用几个常见的剪枝参数来预防过拟合。这边就只用了max_depth这个参数
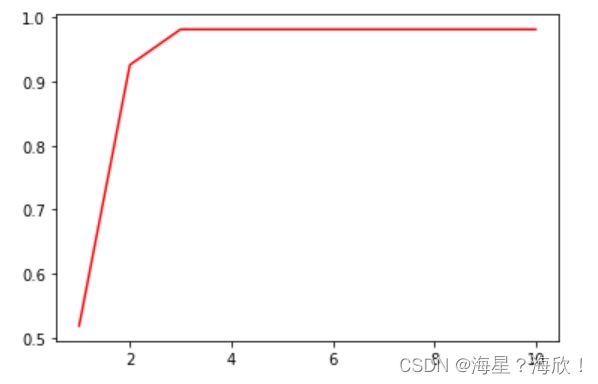
import matplotlib.pyplot as plt
test=[]
for i in range(10):
clf=tree.DecisionTreeClassifier(criterion='entropy'
,max_depth=i+1
,random_state=30)
clf=clf.fit(xtrain,ytrain)
score=clf.score(xtest,ytest)
test.append(score)
plt.plot(range(1,11),test,color='red',label='max_depth')
plt.show()
# 可以看出在3的时候,数据是相对最好的。
目标权重参数
class_weight 给少量的标签更多的权重,让模型更加偏向少数类。 该参数默认None,表示自动给相同的权重
weight_fraction_leaf 对应的剪枝参数
重要属性与接口
属性:模型训练后,能够调用查看模型的各种性质 feature_import sklearn 接口:fit和score apply 和predict
apply返回每个测试样本所在的叶子节点的索引
predict 返回每个测试样本的分类、回归结果
所有接口中要求输入xtest和x_train部分,输入的特征矩阵必须至少至少是一个二维矩阵,不接受一维矩阵!!!!
#apply返回每个测试样本所在的叶子节点的索引
clf.apply(xtest)
#predict 返回每个测试样本的分类、回归结果
clf.predict(xtest)