【论文翻译】PLOP: Learning without Forgetting for Continual Semantic Segmentation
论文地址:http://https://arxiv.org/abs/2011.11390
代码地址:GitHub - arthurdouillard/CVPR2021_PLOP: Official code of CVPR 2021's PLOP: Learning without Forgetting for Continual Semantic Segmentation
目录
摘要
1 介绍
2 相关工作
3. PLOP Segmentation Learning Framework
3.1. Continual semantic segmentation framework
3.2. Multi-scale local distillation with Local POD
3.3. Solving background shift with pseudo-labeling
4 实验
4.1. Datasets, Protocols, and Baselines
4.2. Quantitative Evaluation
4.3. New Protocols and Evaluation
4.4. Model Introspection
5 结论
补充资料
A. Appendix
A.1. Further Work
A.2. Algorithm view of Local POD
A.3. Reproducibility
A.4. Additional Experiments
摘要
Deep learning approaches are nowadays ubiquitously used to tackle computer vision tasks such as semantic segmentation, requiring large datasets and substantial computational power. Continual learning for semantic segmentation (CSS) is an emerging trend that consists in updating an old model by sequentially adding new classes. However, continual learning methods are usually prone to catastrophic forgetting. This issue is further aggravated in CSS where, at each step, old classes from previous iterations are collapsed into the background. In this paper, we propose Local POD, a multi-scale pooling distillation scheme that preserves long- and short range spatial relationships at feature level. Furthermore, we design an entropy-based pseudo-labelling of the background w.r.t. classes predicted by the old model to deal with background shift and avoid catastrophic forgetting of the old classes. Our approach, called PLOP, significantly outperforms state-of-the-art methods in existing CSS scenarios, as well as in newly proposed challenging benchmarks1.
如今,深度学习方法普遍用于处理计算机视觉任务,如语义分割,这需要大量数据集和强大的计算能力。语义分割的持续学习(CSS)是一种新兴趋势,它通过顺序添加新类来更新旧模型。然而,持续的学习方法通常容易导致灾难性的遗忘。这个问题在CSS中进一步恶化,在CSS的每一步中,来自先前迭代的旧类都被归为背景。在本文中,我们提出了局部POD,这是一种多尺度池化蒸馏方案,它在特征级别上保持长程和短程空间关系。此外,我们还设计了一个基于熵的伪标签,对旧模型预测的背景等类进行标记,以处理背景偏移,避免对旧类的灾难性遗忘。我们的方法称为PLOP,在现有CSS场景中以及在新提出的具有挑战性的基准中,其性能明显优于最先进的方法。
1 介绍
Semantic segmentation is a fundamental problem of computer vision, that aims at assigning a label to each pixel of an image. In recent years, the introduction of Convolutional Neural Networks (CNNs) has addressed semantic segmentation in a traditional framework, where all classes are known beforehand and learned at once [67, 80, 12]. This setup, however, is quite limited for practical applications. In a more realistic scenario, the model should be able to continuously learn new classes without retraining from scratch. This setup, referred here as Continual Semantic Segmentation (CSS), has emerged very recently for medical applications [56, 57] before being proposed for general segmentation datasets [54, 8].
语义分割是计算机视觉的一个基本问题,其目的是为图像的每个像素指定一个标签。近年来,卷积神经网络(CNN)的引入在传统的框架中解决了语义分割问题,在这种框架中,所有类都是预先知道的,并且可以一次学习[67,80,12]。然而,这种设置在实际应用中非常有限。在更现实的场景中,模型应该能够持续学习新类别,而无需从头开始再训练。这种设置在这里被称为连续语义分割(CSS),最近出现在医学应用中[56,57],之后才被提议用于一般分割数据集[54,8]。
Deep learning approaches that deal with CSS face two main challenges. The first one, inherited from continual learning, is called catastrophic forgetting [61, 23, 68], and points to the fact that neural networks tend to completely and abruptly forget previously learned knowledge when learning new information [38]. Catastrophic forgetting presents a real challenge for continual learning applications based on deep learning methods, especially when storing previously seen data is not allowed for privacy reasons.
处理CSS的深度学习方法面临两大挑战。第一种是从持续学习中延续下来的,被称为灾难性遗忘[61,23,68],它指出了一个事实,即神经网络在学习新信息时往往会完全而突然地忘记先前学习的知识[38]。灾难性遗忘对于基于深度学习方法的持续学习应用程序来说是一个真正的挑战,尤其是当出于隐私原因不允许存储以前看到的数据时。
The second issue, CSS specific, is the semantic shift of the background class. In a traditional semantic segmentation setup, the background contains pixels that don’t belong to any other class. However, in CSS, the background contains pixels that don’t belong to any of the current classes. Thus, for a specific learning step, the background can contain both future classes, not yet seen by the model, as well as old classes. Thus, if nothing is done to distinguish pixels belonging to the real background class from old class pixels, this background shift phenomenon risks exacerbating the catastrophic forgetting even further [8].
第二个问题是特定于CSS的背景类的语义变化。在传统的语义分割设置中,背景包含不属于任何其他类别的像素。但是,在CSS中,背景包含不属于任何当前类的像素。因此,对于特定的学习步骤,背景可以包含模型尚未看到的新类和旧类。因此,如果不采取任何措施将属于真实背景类的像素与旧类像素区分开来,这种背景偏移现象有可能进一步加剧灾难性遗忘[8]。
In this paper, we propose a deep learning strategy to address these two challenges in CSS. Instead of reusing old images, our approach, called PLOP , standing for Pseudolabel and Local POD leverages the old model in two manners, as illustrated on Fig. 1. First, we propose a featurebased multi-scale distillation scheme to alleviate catastrophic forgetting. Second, we employ a confidence-based pseudo-labeling strategy to retrieve old class pixels within the background. For instance, if a current ground truth mask only distinguish pixels from class sofa and background, our approach allows to assign old classes to background pixels, e.g. classes person, dog or background (the semantic class).
在本文中,我们提出了一个深度学习策略来解决CSS中的这两个挑战。我们的方法称为PLOP,它没有重用旧图像,而是代表伪标签和本地POD以两种方式利用旧模型,如图1所示。首先,我们提出了一种基于特征的多尺度蒸馏方案来减小灾难性遗忘。其次,我们采用基于置信度的伪标记策略来检索背景中的旧类像素。例如,如果一个当前的ground truth mask仅将像素与沙发类别和背景区分开来,我们的方法允许将旧类分配给背景像素,例如类person、类dog或类background(语义类)。

Figure 1: Our two-part strategy aims at learning a segmentation network in a continual learning framework, where old class pixels are collapsed into the background at current stage. We generate pseudo labels from old predictions (blue) to deal with the background shift, and retain shortand long-range spatial dependencies by Local POD distillation (red) to prevent catastrophic forgetting. 我们的两部分策略旨在在持续学习框架中学习分割网络,其中旧类像素在当前阶段被压缩到背景中。我们从旧预测(蓝色)生成伪标签以处理背景偏移,并通过局部POD蒸馏(红色)保留短程和长程空间相关性以防止灾难性遗忘。
We thoroughly validate PLOP on several datasets, showcasing significant performance improvements compared to the state-of-the-art methods in existing CSS scenarios. Furthermore, we propose several novel scenarios to further quantify the performances of CSS methods when it comes to long term learning, class presentation order and domain shift. Last but not least, we show that PLOP largely outperforms every CSS approach in these scenarios. To sum it up, our contributions are three-folds:
我们在几个数据集上验证了PLOP,与现有CSS场景中的最新方法相比,显示了显著的性能改进。此外,我们还提出了一些新的场景来进一步量化CSS方法在长期学习、类表示顺序和域转移方面的性能。最后结果显示,在这些场景中,PLOP在很大程度上优于所有CSS方法。总而言之,我们的贡献有三个方面:
• We propose a multi-scale spatial distillation loss to better retain knowledge through the continual learning steps, by preserving long- and short-range spatial relationships, avoiding catastrophic forgetting.
• We introduce a confidence-based pseudo-labeling strategy to identify old classes for the current background pixels and deal with background shift.
• We show that PLOP significantly outperforms state-ofthe-art approaches in existing scenarios and datasets for CSS, as well as in several newly proposed challenging benchmarks.
•我们提出了一种多尺度空间蒸馏损失法,通过保持长程和短程空间关系,避免灾难性遗忘,通过持续学习步骤更好地保留知识。
•我们引入了基于置信度的伪标记策略,以识别当前背景像素的旧类,并处理背景偏移。
•我们表明,PLOP在CSS的现有场景和数据集以及一些新提出的具有挑战性的基准中显著优于最先进的方法。
2 相关工作
CSS is a relatively new field where only a few recent papers addressed this specific problem. We thus start this section with a brief overview of the recent advances in semantic segmentation as well as continual learning and follow with a more in-depth discussion of existing approaches to CSS.
CSS是一个相对较新的领域,最近只有几篇论文讨论了这个特定的问题。因此,我们在本节开始时简要概述了语义切分以及持续学习方面的最新进展,随后对CSS的现有方法进行了更深入的讨论。
Semantic Segmentation methods based on Fully Convolutional Networks (FCN) [51, 65] have achieved impressive results on several segmentation benchmarks [20, 15, 84, 6]. These methods improve the segmentation accuracy by incorporating more spatial information or exploiting contextual information specifically. Atrous convolution [13, 53] and encoder-decoder architecture [63, 55, 2] are the most common methods for retaining spatial information. Examples of recent works exploiting contextual information include attention mechanisms [76, 83, 24, 32, 75, 67, 80], and fixed-scale aggregation [82, 13, 12, 79]. More recently, Strip Pooling [30] consists in pooling along the width or height dimensions similarly to POD [18] as a complement to a spatial pyramid pooling [27] to capture both global and local statistics.
语义分割 基于完全卷积网络(FCN)[51,65]的方法在几个分割基准上取得了令人印象深刻的结果[20,15,84,6]。这些方法通过加入更多的空间信息或专门利用上下文信息来提高分割精度。Atrous卷积[13,53]和编解码器架构[63,55,2]是保留空间信息的最常用方法。最近利用上下文信息的作品包括注意机制[76,83,24,32,75,67,80]和固定尺度聚合[82,13,12,79]。最近,Strip Pooling[30]包括沿宽度或高度维度合并,类似于POD[18],作为空间金字塔合并[27]的补充,以捕获全局和局部统计数据。
Continual Learning models generally face the challenge of catastrophic forgetting of the old classes [61, 68, 23]. Several solutions exist to address this problem: for instance, rehearsal learning consists in keeping a limited amount of training data from old classes either as raw images [61, 60, 7, 11], compressed features [26, 35], or generated training data [37, 66, 48]. Other works focus on adaptive architectures that can extend themselves to integrate new classes [74, 45] or dynamically re-arrange coexisting sub-networks [22] each specialized in one specific task [21, 25, 34], or to explicitly correct the classifier drift [73, 81, 3, 4] that happens with continually changing class distributions. Last but not least, distillation-based methods aim at constraining the model as it changes, either directly on the weights [40, 1, 9, 78], the gradients [52, 10], the output probabilities [47, 60, 7, 8], intermediary features [31, 17, 85, 18], or combinations thereof.
持续学习 模型通常面临着旧类灾难性遗忘的挑战[61,68,23]。有几种解决方案可以解决这个问题:例如,排练学习包括将旧课程中有限数量的训练数据保留为原始图像[61,60,7,11]、压缩特征[26,35]或生成的训练数据[37,66,48]。其他工作集中在自适应体系结构上,该体系结构可以扩展自身以集成新的类[74,45],或动态地重新安排共存的子网络[22],每个子网络专门用于一个特定任务[21,25,34],或显式地纠正类分布不断变化时出现的分类器漂移[73,81,3,4]。最后但并非最不重要的一点是,基于蒸馏的方法旨在直接根据权重[40,1,9,78]、梯度[52,10]、输出概率[47,60,7,8]、中间特征[31,17,85,18]或其组合来约束模型的变化。
Continual Semantic segmentation: Despite enormous progress in the two aforementioned areas respectively, segmentation algorithms are mostly used in an offline setting,while continual learning methods generally focus on image classification. Recent works extend existing continual
learning methods [47, 31] for medical applications [56, 57] and general semantic segmentation [54]. The latter considers that the previously learned categories are properly annotated in the images of the new dataset. This is an unrealistic assumption that fails to consider the background shift: pixels labeled as background at the current step are semantically ambiguous, in that they can contain pixels from old classes (including the real semantic background class, which is generally deciphered first) as well as pixels from future classes. To the best of our knowledge, Cermelli et al. [8] are the first to address this background shift problem along with catastrophic forgetting. To do so, they apply two loss terms at the output level. First, they use a knowledge distillation loss to reduce forgetting. However, only constraining the output of the network with a distillation term is not enough to preserve the knowledge of the old classes, leading to too much plasticity and, ultimately, catastrophic forgetting. Second, they propose to modify the traditional cross-entropy loss for background pixels to propagate only the sum probability of old classes throughout the continual learning steps. We argue that this constraint is not strong enough to preserve a high discriminative power w.r.t. the old classes when learning new classes under background shift. On the contrary, in what follows, we introduce our PLOP framework and show how it enables learning without forgetting for CSS.
连续语义分割:尽管在上述两个领域分别取得了巨大进展,但分割算法大多用于离线环境,而连续学习方法通常侧重于图像分类。最近的工作将现有的持续学习方法[47,31]扩展到医学应用[56,57]和一般语义分割[54]。后者认为先前学习的类别在新数据集的图像中得到了正确的注释。这是一个不现实的假设,没有考虑背景偏移:在当前步骤标记为背景的像素是语义上含糊的,因为它们可以包含来自旧类的像素(包括真实语义背景类,通常是先解码的)以及来自未来类的像素。据我们所知,Cermelli等人[8]是第一个解决这一背景变化问题以及灾难性遗忘的人。为此,他们在输出级应用了两个损失项。首先,他们使用知识蒸馏损失来减少遗忘。然而,仅用蒸馏项约束网络的输出不足以保留旧类的知识,导致太多的可塑性,最终导致灾难性的遗忘。其次,他们建议修改背景像素的传统交叉熵损失,以便在连续学习步骤中仅传播旧类的和概率。我们认为,在背景转换下学习新课程时,这种约束不足以保持对旧类的高辨别力w.r.t。相反,在接下来的内容中,我们将介绍我们的PLOP框架,并展示它如何在不忘记CSS的情况下实现学习。
3. PLOP Segmentation Learning Framework
3.1. Continual semantic segmentation framework
CSS aims at learning a model in t = 1...T steps. For each step, we present a dataset Dt that consists in a set of pairs (It,St), where It denotes an input image of size W × H and St the corresponding ground truth segmentation mask. The latter only contains the labels of current classes Ct, and all other labels (e.g. old classes C1:t-1 or future classes Ct+1:T ) are collapsed into the background class cbg. However, the model at step t shall be able to predict all the classes seen over time C1:t. Consequently, we identify two major pitfalls in CSS: the first one, catastrophic forgetting [61, 23], suggests that the network will completely forget the old classes C1:t-1 when learning Ct. Furthermore, catastrophic forgetting is aggravated by the second pitfall,
the background shift: at step t, the pixels labeled as background are indeed ambiguous, as they may contain either old (including the real background class, predicted in C1) or future classes. Fig. 2 (top row) illustrates background shift.
CSS旨在以t=1…t的步骤学习模型。对于每一步,我们提供一个数据集Dt,该数据集Dt由一组对(It,St)组成,其中It它表示大小为W×H的输入图像,St表示相应的ground truth分割掩码。后者仅包含当前类Ct的标签,所有其他标签(例如旧类C1:t-1或新类Ct+1:t)折叠到背景类Cbg中。然而,步骤t的模型应能够预测随时间C1:t出现的所有等级。因此,我们确定了CSS中的两个主要问题:第一个,灾难性遗忘[61,23],表明网络在学习Ct时会完全忘记旧的C1:t-1类。此外,灾难性遗忘因第二个问题——背景偏移而加剧:在步骤t,标记为背景的像素确实是模糊的,因为它们可能包含旧类(包括C1中预测的真实背景类)或未来的类。图2(顶行)显示了背景偏移。

Figure 2: Background shift example in ground truth masks (top row). At step 2 background pixels contain old (person) and future classes (bottle). The model’s target (middle row) is the union of the ground-truth and the pseudo-labels (with transparent filtered uncertain pixels) generated by the previous model. The latter helps the current model predictions (bottom row) to retain information of the old classes (table). ground truth masks中的背景移动示例(顶行)。在步骤2,背景像素包含旧类(person)和新类(bottle)。模型的目标(中间行)是ground-truth和前一个模型生成的伪标签(带有透明过滤的不确定像素)的联合。后者有助于当前模型预测(底行)保留旧类(表)的信息。
Classically, a deep model at step t can be written as the composition of a feature extractor ft(·) and a classifier gt(·). Features can be extracted at any layer l of the former flt(·) , l ∈{1,...L}. We denote![]() the output predicted segmentation mask and Θt the set of learnable parameters for the current network at step t.
the output predicted segmentation mask and Θt the set of learnable parameters for the current network at step t.
典型地,步骤t的深度模型可以写成特征提取器ft(·)和分类器gt(·)的组合。特征可以在前一个flt(·)的任意层l提取,l∈{1,…L}。我们表示![]() 在步骤t处,输出预测的分段掩码和Θt当前网络的可学习参数集。
在步骤t处,输出预测的分段掩码和Θt当前网络的可学习参数集。
3.2. Multi-scale local distillation with Local POD 具有局部POD的多尺度局部精馏
A common solution to alleviate catastrophic forgetting in continual learning consists of using a distillation loss between the predictions of the old and current models [47]. This distillation loss should constitute a suitable trade-off between too much rigidity (i.e. enforcing too strong constraints, resulting in not being able to learn new classes) and too much plasticity (i.e. enforcing loose constraints, which leads to catastrophic forgetting of the old classes).
缓解持续学习中灾难性遗忘的一种常见解决方案是在旧模型和当前模型的预测之间使用蒸馏损失[47]。这种蒸馏损失应该在太多的刚性(即强制执行太强的约束,导致无法学习新类)和太多的可塑性(即强制执行松散的约束,导致灾难性地忘记旧类)之间进行适当的权衡。
Among existing distillation schemes based on intermediate features [18, 77, 62, 17, 85, 31], POD [18] consists in matching global statistics at different feature levels between the old and current models. Let x denote an embedding tensor of size H × W × C. Extracting a POD embedding Φ consists in concatenating the H×C width-pooled slices and the W × C height-pooled slices of x:
在基于中间特征的现有蒸馏方案中[18,77,62,17,85,31],POD[18]包括在旧模型和当前模型之间的不同特征水平上匹配全局统计数据。设x表示大小为H×W×C的嵌入张量。提取POD嵌入Φ包括连接x的H×C宽度合并切片和W×C高度合并切片: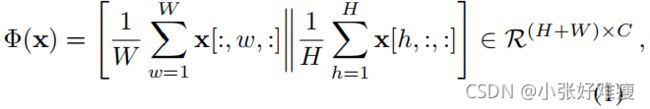
where [·|| ·] denotes concatenation over the channel axis. In our case, this embedding is computed at several layers, for both the old and current model. Then the POD loss consists in minimizing the L2 distance between the two sets of embeddings over the current network parameters Θt:
其中[·|·]表示通道轴上的串联。在我们的例子中,对于旧模型和当前模型,这种嵌入是在几个层上计算的。然后,POD损耗包括在当前网络参数Θt上最小化两组嵌入之间的L2距离:
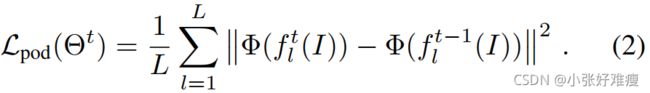
Due to its ability to constraint spatial statistics instead of raw pixel values, this approach yields state-of-the-art results in the context of continual learning for classification. In the frame of CSS, another interest arises: its ability to model long-range dependencies across a whole axis (horizontal or vertical). However, while spatial information is discarded by global pooling in classification, semantic segmentation requires a higher degree of spatial precision. Therefore, modeling statistics across the whole width or height leads to blurring local statistics important for smaller objects.
由于该方法能够约束空间统计信息而不是原始像素值,因此在分类的持续学习环境中,该方法可以产生最先进的结果。在CSS框架中,另一个有趣的问题出现了:它能够跨整个轴(水平或垂直)建模长期依赖关系。然而,尽管分类中的全局池丢弃了空间信息,但语义分割需要更高的空间精度。因此,对整个宽度或高度的统计信息进行建模会导致对较小对象非常重要的局部统计信息变得模糊。

Figure 3: Illustration of local POD. An embedding of size W × H × C is pooled at S scales with POD with a spatialpyramid scheme. Here applying local POD with S = 2 and scales 1 and 1/2 respectively produces 1, and 4 POD embeddings making S × C × (H + W) dimensions total. Local POD的图示。采用空间金字塔方案,在S尺度上用POD合并大小为W×H×C的嵌入。在这里,使用S=2的局部POD和比例1和1/2分别产生1个和4个POD嵌入,使S×C×(H+W)总尺寸。
Hence, a suitable distillation scheme for CSS shall retain both long-range and short-range spatial relationships. Thus, inspired from the multi-scale literature [43, 27], we propose a novel Local POD feature distillation scheme, that consists in computing width and height-pooled slices on multiple regions extracted at different scales![]() , as shown on Fig. 3. For an embedding tensor x of size H × W × C, and at scale 1/2s, the Local POD embedding Ψs(x) at scales is computed as the concatenation of s2 POD embeddings:
, as shown on Fig. 3. For an embedding tensor x of size H × W × C, and at scale 1/2s, the Local POD embedding Ψs(x) at scales is computed as the concatenation of s2 POD embeddings:
因此,CSS的合适蒸馏方案应保持长程和短程空间关系。因此,受多尺度文献[43,27]的启发,我们提出了一种新的局部POD特征提取方案,包括计算在不同尺度![]() 下提取的多个区域上的宽度和高度合并切片,如图3所示。对于尺寸为H×W×C的嵌入张量x,在比例为1/2s时,将比例处的局部POD嵌入ψs(x)计算为s2 POD嵌入的串联:
下提取的多个区域上的宽度和高度合并切片,如图3所示。对于尺寸为H×W×C的嵌入张量x,在比例为1/2s时,将比例处的局部POD嵌入ψs(x)计算为s2 POD嵌入的串联:
where ![]()
![]()
is a sub-region of the embedding tensor x of size W=s × H=s. We then concatenate (along channel axis) the Local POD embeddings Ψs(x) of each scale s to form the final embedding:
其中![]()
![]() 是嵌入张量x的一个子区域,大小为W=s×H=s。然后(沿通道轴)连接每个标度s的局部POD嵌入ψs(x),形成最终嵌入:
是嵌入张量x的一个子区域,大小为W=s×H=s。然后(沿通道轴)连接每个标度s的局部POD嵌入ψs(x),形成最终嵌入:
![]()
We provide in the supplementary materials the complete algorithm of Local POD embedding extraction. We compute Local POD embeddings for several layers of both old and current models. The final Local POD loss is:
我们在补充资料中提供了完整的局部POD嵌入提取算法。我们计算了旧模型和当前模型的几层的局部POD嵌入。最终Local LOD损失为:
Note that while the first scale of Local POD (1=20) is equivalent to POD and models long-range dependencies, which are important for segmentation [70, 33, 58, 30], the subsequent scales ![]() enforce short-range dependencies. This constrains the old and current models to have similar statistics over more local regions. Thus, Local POD allows retaining both long range and short-range spatial relationships, thus alleviating catastrophic forgetting.
enforce short-range dependencies. This constrains the old and current models to have similar statistics over more local regions. Thus, Local POD allows retaining both long range and short-range spatial relationships, thus alleviating catastrophic forgetting.
请注意,虽然Local POD的第一个尺度(1=20)相当于POD,并对长期相关性进行建模,这对细分非常重要[70、33、58、30],但随后的尺度![]() 强制执行短期相关性。这限制了旧模型和当前模型在更多的局部区域具有相似的统计数据。因此,Local POD允许保留长程和短程空间关系,从而减轻灾难性遗忘。
强制执行短期相关性。这限制了旧模型和当前模型在更多的局部区域具有相似的统计数据。因此,Local POD允许保留长程和短程空间关系,从而减轻灾难性遗忘。
3.3. Solving background shift with pseudo-labeling 用伪标记法解决背景偏移问题
As described above, the pixels labelled as background at step t can belong to either old (including the semantic background class) or future classes. Thus, treating them as background would result in aggravating catastrophic forgetting. Rather, we address background shift with a pseudolabeling strategy for background pixels. Pseudo-labeling [44] is commonly used in domain adaptation for semantic segmentation [69, 46, 86, 64], where a model is trained on the union of real labels of a source dataset and pseudo labels assigned to an unlabeled target dataset. In our case, we use predictions of the old model for background pixels as clues regarding their real class, most notably if they belong to any of the old classes, as illustrated on Fig. 2 (middle row). Formally, let![]() the cardinality of the current classes excluding the background class. Let
the cardinality of the current classes excluding the background class. Let![]() denote the predictions of the current model (which include the real background class, all the old classes as well as the current ones). We define S~t ∈
denote the predictions of the current model (which include the real background class, all the old classes as well as the current ones). We define S~t ∈![]() the target as step t, computed using the one-hot ground-truth segmentation map
the target as step t, computed using the one-hot ground-truth segmentation map ![]() at step t as well as pseudo-labels extracted using the old model predictions
at step t as well as pseudo-labels extracted using the old model predictions ![]() as follows:
as follows:
如上所述,在步骤t被标记为背景的像素可以属于旧类(包括语义背景类)或新类。因此,将它们作为背景会导致灾难性遗忘的加重。相反,我们使用背景像素的伪标记策略来处理背景偏移。伪标签[44]通常用于语义分段的域适配[69、46、86、64],其中模型根据源数据集的真实标签和分配给未标记目标数据集的伪标签的并集进行训练。在我们的例子中,我们使用背景像素的旧模型预测作为关于其真实类别的线索,最显著的是如果它们属于任何旧类别,如图2(中间行)所示。形式上,让![]() 表示当前类(不包括后台类)的基数。让
表示当前类(不包括后台类)的基数。让![]() 表示当前模型的预测(包括真实背景类、所有旧类以及当前类)。我们定义了S~t∈
表示当前模型的预测(包括真实背景类、所有旧类以及当前类)。我们定义了S~t∈![]() 将目标作为步骤t,使用步骤t中的one-hot ground-truth分割图
将目标作为步骤t,使用步骤t中的one-hot ground-truth分割图![]() 以及使用旧模型预测
以及使用旧模型预测![]() 提取的伪标签进行计算,如下所示:
提取的伪标签进行计算,如下所示:
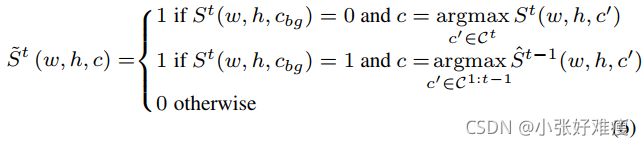
In other words, in the case of non-background pixels we copy the ground truth label. Otherwise, we use the class predicted by the old model ![]() . This pseudolabel strategy allows to assign each pixel labelled as background his real semantic label if this pixel belongs to any of the old classes. However pseudo-labeling all background pixels can be unproductive, e.g. on uncertain pixels where the old model is likely to fail. Therefore we only retain pseudo-labels where the old model is “confident” enough. Eq. 6 can be modified to take into account this uncertainty:
. This pseudolabel strategy allows to assign each pixel labelled as background his real semantic label if this pixel belongs to any of the old classes. However pseudo-labeling all background pixels can be unproductive, e.g. on uncertain pixels where the old model is likely to fail. Therefore we only retain pseudo-labels where the old model is “confident” enough. Eq. 6 can be modified to take into account this uncertainty:
换句话说,在非背景像素的情况下,我们复制ground truth标签。否则,我们使用旧模型![]() 预测的类别。这种伪标签策略允许将标记为背景的每个像素指定为其真正的语义标签(如果该像素属于任何旧类)。然而,伪标记所有背景像素可能是无效的,例如,在旧模型可能失败的不确定像素上。因此,我们只保留旧模型足够“自信”的伪标签。考虑到这种不确定性,可以修改等式6:
预测的类别。这种伪标签策略允许将标记为背景的每个像素指定为其真正的语义标签(如果该像素属于任何旧类)。然而,伪标记所有背景像素可能是无效的,例如,在旧模型可能失败的不确定像素上。因此,我们只保留旧模型足够“自信”的伪标签。考虑到这种不确定性,可以修改等式6:
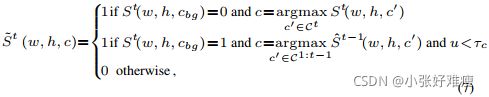
where u represents the uncertainty of pixel (w,h) and τc is a class-specific threshold. Thus, we discard all the pixels for which the old model is uncertain (u ≥ τc) in Eq. 7 and decrement the normalization factor W H by one. We use entropy as the uncertainty measurement u. Specifically, before learning task t, we compute the median entropy for the old model over all pixels of Dt predicted as c for all the previous classes c ∈ C1:t-1, which provides in thresholds τc ∈ C1:t-1, as proposed in [64]. The cross-entropy loss with pseudo-labeling of the old classes can be written as:
其中u表示像素(w,h)的不确定性,τc是特定于类别的阈值。因此,我们丢弃旧模型不确定的所有像素(u≥ τc)并将归一化因子W H减小1。我们使用熵作为测量不确定度u。具体地说,在学习任务t之前,我们计算旧模型的中值熵,该熵覆盖所有先前类c预测为c的Dt的所有像素∈ C1:t-1,提供阈值τc∈ C1:t-1,如[64]所述。旧类的伪标记交叉熵损失可以写成:
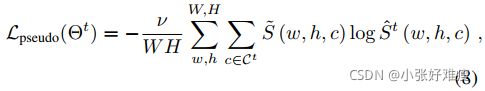
where ν is the ratio of accepted old classes pixels over the total number of such pixels. This ponderation allows to adaptively weight the importance of the pseudo-labeling within the total loss. We call PLOP (standing for Pseudolabeling and LOcal Pod) the proposed approach, that uses both Local POD to avoid catastrophic forgetting, and our uncertainty-based pseudo-labeling to address background shift. To sum it up, the total loss in PLOP is:
其中,ν是可接受的旧类像素与此类像素总数的比率。这种思考允许在总损失中自适应地加权伪标记的重要性。我们将PLOP(代表伪标记和局部Pod)称为所提出的方法,该方法既使用局部Pod避免灾难性遗忘,也使用基于不确定性的伪标记解决背景偏移。综上所述,PLOP的总损失为:
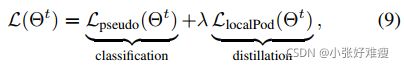
with λ an hyperparameter. λ是一个超参数。
4 实验
4.1. Datasets, Protocols, and Baselines
To ensure fair comparisons with state-of-the-art approaches, we follow the experimental setup of [8] for datasets, protocol, metrics, and baseline implementations.
为了确保与最先进的方法进行公平的比较,我们遵循[8]中关于数据集、协议、度量和基线实现的实验设置。
Datasets: we evaluate PLOP on 3 segmentation datasets: Pascal-VOC 2012 [20] (20 classes), ADE20k [84] (150 classes) and CityScapes [15] (19 classes from 21 different cities). Full details are in the supplementary materials.
数据集:我们在3个细分数据集上评估PLOP:Pascal VOC 2012[20](20类)、ADE20k[84](150类)和城市景观[15](来自21个不同城市的19类)。详细情况见补充材料。
CSS protocols: [8] describes two different CSS settings: Disjoint and Overlapped. In both, only the current classes are labeled vs. a background class Ct. However, in the former, images of task t only contain pixels C1:t-1∪Ct (old and current), while, in the latter, pixels can belong to any classes C1:t-1∪Ct∪Ct+1:T (old, current, and future). Thus, the Overlapped setting is the most challenging and realistic, as in a real setting there isn’t any oracle method to exclude future classes from the background. Therefore, in our experiments, we focus on Overlapped CSS but more results for Disjoint CSS can be found in the supplementary materials. While the training images are only labeled for the current classes, the testing images are labeled for all seen classes. We evaluate several CSS protocols for each dataset, e.g. on VOC 19-1, 15-5, and 15-1 respectively consists in learning 19 then 1 class (T = 2 steps), 15 then 5 classes (2 steps), and 15 classes followed by five times 1 class (6 steps). The last setting is the most challenging due to its higher number of steps. Similarly, on ADE 100-50 means 100 followed by 50 classes (2 steps), 100-10 means 100 followed by 5 times 10 classes (6 steps), and so on.
CSS协议:[8]描述了两种不同的CSS设置:不相交和重叠。在这两种情况下,与背景类Ct相比,只有当前类被标记。然而,在前者中,任务t的图像仅包含像素C1:t-1∪Ct(旧的和当前的),而在后者中,像素可以属于任何类别C1:t-1∪计算机断层扫描∪Ct+1:T(旧的、当前的和未来的)。因此,重叠设置是最具挑战性和现实性的,因为在实际设置中,没有任何oracle方法将将来的类从后台排除。因此,在我们的实验中,我们专注于重叠CSS,但在补充材料中可以找到更多关于不相交CSS的结果。虽然训练图像仅针对当前类进行标记,但测试图像针对所有可见类进行标记。我们评估了每个数据集的几个CSS协议,例如,在VOC 19-1、15-5和15-1上,分别包括学习19个然后1个类(T=2个步骤)、15个然后5个类(2个步骤)和15个类,然后再学习5次1个类(6个步骤)。最后一个设置是最具挑战性的,因为其步骤较多。同样,在ADE上,100-50表示100后面跟着50个类(2个步骤),100-10表示100后面跟着5乘以10个类(6个步骤),依此类推。
Metrics: we compare the different models using traditional mean Intersection over Union (mIoU). Specifically, we compute mIoU after the last step T for the initial classes C1, for the incremented classes C2:T , and for all classes C1:T (all). These metrics respectively reflect the robustness
to catastrophic forgetting (the model rigidity), the capacity to learn new classes (plasticity), as well as its overall performance (trade-of between both). We also introduce a novel avg metric (short for average), which measures the average of mIoU scores measured step after step, integrating performance over the whole continual learning process.
指标:我们使用传统的联合平均交集(mIoU)来比较不同的模型。具体来说,我们在最后一步T之后计算初始类C1、递增类C2:T和所有类C1:T(all)的mIoU。这些指标分别反映了鲁棒性
对于灾难性遗忘(模型刚性)、学习新课程的能力(可塑性)以及其整体表现(两者之间的权衡)。我们还引入了一种新的平均值指标(avg metric,简称average),它一步一步地测量mIoU分数的平均值,将整个持续学习过程中的绩效综合起来。
Baselines: We benchmark our model against the latest stateof-the-arts CSS methods ILT [54] and MiB [8]. We also evaluate general continual models based on weight constraints (EWC [40]) and knowledge distillation (LwF-MC [60]). More baselines are available in the supplementary materials. All models, ours included, don’t use rehearsal learning [61, 60, 11] where a limited quantity of previous tasks data can be rehearsed. Finally, we also compare with a reference model learned in a traditional semantic segmentation setting (“Joint model” without continual learning), which may constitute an upper bound for CSS methods.
基线:我们根据最新的CSS方法ILT[54]和MiB[8]对我们的模型进行基准测试。我们还评估了基于权重约束(EWC[40])和知识提取(LwF MC[60])的一般连续模型。补充材料中提供了更多基线。包括我们在内的所有模型都不使用预演学习[61,60,11],在这种学习中,可以预演数量有限的先前任务数据。最后,我们还将其与在传统语义切分设置中学习的参考模型(“联合模型”,无需持续学习)进行比较,这可能构成CSS方法的上限。
Implementation Details: As in [8], we use a DeeplabV3 [14] architecture with a ResNet-101 [28] backbone pretrained on ImageNet [16] for all experiments. Full details are provided in the supplementary materials.
实现细节:如[8]中所述,我们在所有实验中使用了一个DeeplabV3[14]体系结构,该体系结构在ImageNet[16]上预训练了一个ResNet-101[28]主干网。补充材料中提供了全部细节。
4.2. Quantitative Evaluation
First, we compare PLOP with state-of-the-art methods.
首先,我们将PLOP与最先进的方法进行比较。
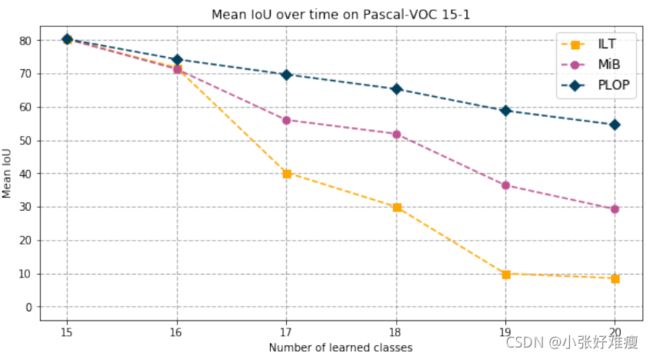
Pascal VOC 2012: Table 1 shows quantitative experiments on VOC 19-1, 15-5, and 15-1. PLOP outperforms its closest contender, MiB [8] on all evaluated settings by a significant margin. On 19-1, the forgetting of old classes (1- 19) is reduced by 4.39 percentage points ( p.p) while performance on new classes is greatly improved (+13.76 p.p). On 15-5, our model is on par with our re-implementation of MiB, and surpasses the original paper scores [8] by 1 p.p. On the most challenging 15-1 setting, general continual models (EWC and LwF-MC) and ILT all have very low mIoU. While MiB shows significant improvements, PLOP still outperforms it by a wide margin: +86% on all classes, +90% on old classes, and +56% on new classes. Also, the joint model mIoU is 77:40%, thus PLOP narrows the gap compared to state-of-the-art approaches on every CSS scenario. The average mIoU is also improved by +24% compared to MiB, indicating that each CSS step benefits from the improvements related to our method. This is echoed by Fig. 4, which shows that while mIoU for both ILT and MiB deteriorates after only a handful of steps, PLOP ’s mIoU remains very high throughout, indicating improved resilience to catastrophic forgetting and background shift.
Pascal VOC 2012:表1显示了VOC 19-1、15-5和15-1的定量实验。PLOP在所有经过评估的设置上都比其最接近的竞争者MiB[8]表现出色。在19-1节课上,对旧类(1-19)的遗忘率降低了4.39个百分点,而对新类的遗忘率大大提高(+13.76 )。在15到5,我们的模型与我们重新实施MiB,并超过原来的纸分数[8]1分。在最具挑战性的15-1设置,一般连续模型(EWC和LWF MC)和ILT都有非常低的MIOU。虽然MiB显示出显著的改进,但PLOP仍然比它有很大的优势:所有类+86%,旧类+90%,新类+56%。此外,联合模型mIoU为77:40%,因此PLOP缩小了与每个CSS场景的最新方法相比的差距。与MiB相比,平均mIoU也提高了+24%,这表明每个CSS步骤都受益于与我们的方法相关的改进。这与图4相呼应,图4显示,虽然ILT和MiB的mIoU在仅仅几个步骤后都会恶化,但PLOP的mIoU在整个过程中仍然很高,这表明对灾难性遗忘和背景变化的恢复力有所提高。

ADE20k: Table 2 shows experiments on ADE 100-50, 100-10, and 50-50. This dataset is notoriously hard, as the joint model baseline mIoU is only 38.90%. ILT has poor performance in all three scenarios. PLOP shows comparable performance with MiB on the short setting 100-50 (only 2 tasks), improves by 1.09 p.p on the medium setting 50-50 (3 tasks), and significantly outperforms MiB with a wider margin of 2.35 p.p on the long setting 100-10 (6 tasks). In addition to being better on all settings, PLOP showcased an increased performance gain on longer CSS (e.g. 100- 10) scenarios, due to increased robustness to catastrophic forgetting and background shift. To further validate this robustness, we propose harder novel CSS scenarios.
ADE20k:表2显示了ADE 100-50、100-10和50-50的实验。该数据集是出了名的硬,因为联合模型型基线mIoU仅为38.90%。ILT在所有三种情况下的性能都很差。PLOP在短设置100-50(仅2项任务)上的性能与MiB相当,在中等设置50-50(3项任务)上的性能提高了1.09,在长设置100-10(6项任务)上的性能显著优于MiB,更大的幅度为2.35。除了在所有设置上都有更好的表现外,PLOP还展示了在较长CSS(例如100-10)场景下的性能提升,这是因为它增强了对灾难性遗忘和背景移动的鲁棒性。为了进一步验证这种稳健性,我们提出了更为新颖的CSS场景。
4.3. New Protocols and Evaluation
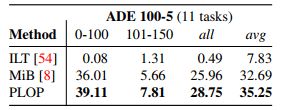
Longer Continual Learning: We argue that CSS experiments should push towards more steps [72, 50, 18, 7] to quantify the robustness of approaches w.r.t. catastrophic forgetting and background shift. We introduce two novel and much more challenging settings with 11 tasks, almost twice as many as the previous longest setting. We report results for VOC 10-1 in Table 3 (10 classes followed by 10 times 1 class) and ADE 100-5 in Table 4 (100 classes followed by 10 times 5 classes). The second previous State-ofthe-Art method, ILT, has a very low mIoU (< 6 on VOC 10- 1 and practically null on ADE 100-5). Furthermore, the gap between PLOP and MiB is even wider compared with previous benchmarks (e.g. ×3.6 mIoU on VOC for mIoU of base classes 1-10), which confirms the superiority of PLOP when dealing with long continual processes.
更长时间的持续学习:我们认为CSS实验应该推进更多步骤[72,50,18,7],以量化灾难性遗忘和背景变化方法的稳健性。我们引入了两种新颖且更具挑战性的设置,共有11项任务,几乎是之前最长设置的两倍。我们在表3中报告了VOC 10-1的结果(10个等级后接10倍1个等级),在表4中报告了ADE 100-5的结果(100个等级后接10倍5个等级)。第二种最先进的方法,ILT,具有非常低的mIoU(VOC 10-1上小于6,ADE 100-5上几乎为零)。此外,与以前的基准相比,PLOP和MiB之间的差距更大(例如,对于基类1-10的mIoU,VOC上的×360万),这证实了PLOP在处理长时间连续过程时的优越性。
Stability w.r.t. class ordering: We already showed that existing continual learning methods may be prone to instability. It has already been shown in related contexts [39] that class ordering can have a large impact on performance. However, in real-world settings, the optimal class order can never be known beforehand: thus, the performance of an ideal CSS method should be as class order-invariant as possible. In all experiments done so far, this class order has been kept constant, as defined in [8]. We report results in Fig. 5 under the form of boxplots obtained by applying 20 random permutations of the class order on VOC 15-1. We report in Fig. 5 (from left to right) the mIoU for the old, new classes, all classes, and average over CSS steps. In all cases, PLOP surpasses MiB in term of avg mIoU. Furthermore, the standard deviation (e.g. 10% vs 5% on all) is always significantly lower, showing the excellent stability of PLOP compared with existing approaches.
稳定性等类排序:我们已经表明,现有的持续学习方法可能容易出现不稳定性。相关上下文[39]已经表明,类排序对性能有很大影响。然而,在现实环境中,最佳的类顺序永远不可能事先知道:因此,理想CSS方法的性能应该尽可能保持类顺序不变。在迄今为止所做的所有实验中,该类顺序一直保持不变,如[8]中所定义。我们以箱线图的形式报告了图5中的结果,箱线图是通过在VOC 15-1上应用20个类顺序的随机排列获得的。我们在图5(从左到右)中报告了旧类、新类、所有类的mIoU,以及CSS步骤的平均值。在所有情况下,PLOP在平均mIoU方面均优于MiB。此外,标准偏差(例如10%对5%)总是显著较低,表明PLOP与现有方法相比具有极好的稳定性。

Domain Shift: The previous experimental setups mainly assess the capacity of CSS methods to integrate new classes, i.e. to deal with catastrophic forgetting and background shift at a semantic level. However, a domain shift can also happen in CSS scenarios. Thus, we propose a novel benchmark on Cityscapes to quantify robustness to domain shift, in which all 19 classes will be known from the start and, instead of adding new classes, each step brings a novel domain (e.g. a new city), similarly to the NI setting of [49] for image classification. Table 5 compares the performance of ILT, MiB, and PLOP on CityScapes 11-5, 11-1, and 1- 1, making 3, 11 and 21 steps of 11 + 2 times 5 cities, 11 + 10 times 1 city, and 1 + 20 times 1 city respectively. PLOP performs better by a significant margin in every such scenario compared with ILT and MiB which, in this setting, is equivalent to a simple cross-entropy plus basic knowledge distillation [29]. Our Local POD, however, retains better domain-related information by modeling long and shortrange dependencies at different representation levels.
领域转移:以前的实验设置主要评估CSS方法集成新类的能力,即在语义级别处理灾难性遗忘和背景转移。然而,在CSS场景中也可能发生域转移。因此,我们提出了一个新的城市景观基准,以量化对域转移的鲁棒性,在该基准中,所有19个类从一开始就已知,而不是添加新类,每个步骤都会带来一个新域(例如,一个新城市),类似于图像分类的NI设置[49]。表5比较了ILT、MiB和PLOP在城市景观11-5、11-1和1-1上的性能,分别为11+2乘以5个城市、11+10乘以1个城市和1+20乘以1个城市的3、11和21个步骤。与ILT和MiB相比,PLOP在每种情况下都表现得更好,在这种情况下,ILT和MiB相当于简单的交叉熵加上基本知识提炼[29]。然而,我们的本地POD通过在不同的表示级别上建模长程和短程依赖关系,保留了更好的领域相关信息。
4.4. Model Introspection 模型内省
We compare several distillation and classification losses on VOC 15-1 to stress the importance of the components of PLOP and report results in Table 6. All comparisons are evaluated on a val set made with 20% of the train set, therefore results are slightly different from the main experiments.
我们比较了VOC 15-1的几种蒸馏和分类损失,以强调PLOP成分的重要性,并在表6中报告结果。所有比较都是在20%列车组的val集上进行评估的,因此结果与主要实验略有不同。

Distillation comparisons: Table 6a compares different distillation losses when combined with our pseudo-labeling loss. As such, UNKD introduced in [8] performs better than the Knowledge Distillation (KD) of [29], but not at every step (as indicated by the avg. value), which indicates instability during the training process. POD, proposed in [18], improves the results on the old classes, but not on the new classes (16-20). In fact, due to too much plasticity, POD model likely overfits and predicts nothing but the new classes, hence a lower mIoU. Finally, Local POD leads to superior performance (+20 p.p) w.r.t. all metrics, due to its integration of both long and short-range dependencies. This final row represents our full PLOP strategy.
蒸馏比较:表6a比较了不同的蒸馏损失与伪标记损失。因此,在[8]中引入的UNKD比[29]中的知识提取(KD)性能更好,但不是在每个步骤(如平均值所示),这表明在训练过程中不稳定。[18]中提出的POD改进了旧类的结果,但没有改进新类的结果(16-20)。事实上,由于太多的可塑性,POD模型可能过度拟合,只能预测新的类别,因此mIoU较低。最后,由于本地POD集成了长程和短程依赖性,因此其所有指标都具有优异的性能(+20)。最后一行代表我们的完整PLOP策略。
Classification comparisons: Table 6b compares different classification losses when combined with our Local POD distillation loss. Cross-Entropy (CE) variants perform poorly, especially on new classes. UNCE, introduced in [8], improves by merging the background with old classes, however, it still struggles to correctly model the new classes, whereas our pseudo-labeling propagates more finely information of the old classes, while learning to predict the new ones, dramatically enhancing the performance in both cases. This penultimate row represents our full PLOP strategy. Also notice that the performance for pseudo-labeling is very close to Pseudo-Oracle (where the incorrect pseudo-labels are removed), which may constitute a performance ceiling of our uncertainty measure. A comparison between these two results illustrates the relevance of our entropy-based uncertainty estimate.
分类比较:表6b将不同的分类损失与本地豆荚蒸馏损失进行了比较。交叉熵(CE)变体表现不佳,尤其是在新类上。[8]中介绍的UNCE通过将背景与旧类合并来改进,但是,它仍然难以正确地建模新类,而我们的伪标记传播旧类的更精细信息,同时学习预测新类,从而显著提高了这两种情况下的性能。倒数第二行代表了我们的全部PLOP策略。还请注意,伪标签的性能非常接近伪Oracle(其中删除了不正确的伪标签),这可能构成我们不确定性度量的性能上限。这两个结果之间的比较说明了我们基于熵的不确定性估计的相关性。
Vizualisation: Fig. 6 shows the predictions for both MiB and PLOP on VOC 15-1 across time. At first, both models output equivalent predictions. However, MiB quickly forgets the previous classes and becomes biased towards new classes. On the other hand, PLOP predictions are much more stable on old classes while learning new classes, thanks to Local POD alleviating catastrophic forgetting by spatially constraining representations, and pseudo-labeling dealing with background shift. Fig. 7 more closely highlights this phenomenon: at first, the ground-truth only contains the class person. At step 5, the class train is introduced. As a result, MiB overfits on train and forgets person. PLOP, instead, manages to avoid forgetting person and predicts decent segmentation for both classes.
可视化:图6显示了VOC 15-1上MiB和PLOP随时间变化的预测。首先,两个模型输出的预测结果相当。然而,MiB很快就忘记了以前的类,并倾向于新类。另一方面,PLOP预测在学习新类的同时在旧类上更加稳定,这要归功于局部POD通过空间约束表示减轻灾难性遗忘,以及处理背景偏移的伪标记。图7更密切地强调了这一现象:首先,基本事实只包含阶级人物。在第5步中,引入了班列。结果,MiB在火车上过度使用,忘记了人。相反,PLOP设法避免忘记person,并预测这两个类都有适当的细分。

5 结论
In this paper, we paved the way for future research on Continual Semantic Segmentation, which is an emerging domain in computer vision. We highlighted two main challenges in Continual Semantic Segmentation (CSS), namely catastrophic forgetting and background shift. To deal with the former, we proposed Local POD, a multi-scale pooling distillation scheme that allows preserving long and shortrange spatial relationships between pixels, leading to a suitable trade off between rigidity and plasticity for CSS and, ultimately, alleviating catastrophic forgetting. The proposed method is general enough to be used in other related distillation settings, where preserving spatial information is a concern. In addition, we introduced a new strategy to address the background shift based on an efficient pseudolabeling method. We validate our PLOP framework, on several existing CSS scenarios involving multiple datasets. In addition, we propose novel experimental scenarios to assess the performance of future CSS approaches in terms of long term learning capacity and stability. We showed that PLOP performs significantly better than all existing baselines in every such CSS benchmark.
在本文中,我们为计算机视觉中的一个新兴领域——连续语义分割的未来研究铺平了道路。我们强调了连续语义分割(CSS)中的两个主要挑战,即灾难性遗忘和背景转移。为了解决前者,我们提出了局部POD,这是一种多尺度的池蒸馏方案,允许保留像素之间的长距离和短距离空间关系,从而在CSS的刚性和可塑性之间进行适当的权衡,并最终缓解灾难性遗忘。所提出的方法具有足够的通用性,可用于其他相关蒸馏装置,其中保存空间信息是一个问题。此外,我们引入了一种基于有效伪标记方法的新策略来解决背景偏移问题。我们在涉及多个数据集的几个现有CSS场景上验证了我们的PLOP框架。此外,我们还提出了新的实验方案,以评估未来CSS方法在长期学习能力和稳定性方面的性能。我们表明,PLOP在每一个这样的CSS基准中都比所有现有的基线表现得好得多。
补充资料
A. Appendix
A.1. Further Work
In our CSS setting, pixels of task T can belong to old C1:t-1, current Ct, and future classes Ct+1:T . In this paper we cover how to better handle old and current classes. Further works should investigate how to exploit the already present future information with Zeroshot [42, 41] as already done in semantic segmentation [36, 5] and explored for continual classification [71, 19].
在我们的CSS设置中,任务T的像素可以属于旧C1:T-1、当前Ct和将来的类Ct+1:T。在本文中,我们将介绍如何更好地处理旧类和当前类。进一步的工作应该研究如何利用Zeroshot[42,41]中已经存在的未来信息,就像语义切分[36,5]中已经做过的那样,并探索连续分类[71,19]。
A.2. Algorithm view of Local POD
In Algo. 1, we summarize the algorithm for the proposed Local POD. The algorithm consists in three functions. First, Distillation, loops over all L layers onto which we apply Local POD. Second, LocalPOD, computes the L2 distance (L.26) between POD embeddings of the current (L.19) and old (L.20) models. It loops over S different scales (L.14) and Φ computes the POD embedding given two features maps subsets (L.19-20) as defined in Eq. 1. || = denotes an in-place concatenation.
在Algo. 1总结了提出的局部POD算法。该算法由三个函数组成。首先,蒸馏,在所有L层上循环,我们在其上应用局部POD。其次,LocalPOD计算当前(L.19)和旧(L.20)模型的POD嵌入之间的L2距离(L.26)。它在S个不同的标度(L.14)上循环,并根据公式1中定义的两个特征映射子集(L.19-20)计算POD嵌入。||=表示就地连接。

A.3. Reproducibility
Datasets: We evaluate our model on three datasets PascalVOC [20], ADE20k [84], and Cityscapes [15]. VOC contains 20 classes, 10,582 training images, and 1,449 testing images. ADE20k has 150 classes, 20,210 training images, and 2,000 testing images. Cityscapes contains 2975 and 500 images for train and test, respectively. Those images represent 19 classes and were taken from 21 different cities. All ablations and hyperparameters tuning were done on a validation subset of the training set made of 20% of the images. For all datasets, we resize the images to 512 × 512, with a center crop. An additional random horizontal flip augmentation is applied at training time.
数据集:我们在三个数据集PascalVOC[20]、ADE20k[84]和Cityscapes[15]上评估我们的模型。VOC包含20个类、10582个训练图像和1449个测试图像。ADE20k拥有150个课程、20210张训练图像和2000张测试图像。城市景观分别包含2975张和500张用于列车和测试的图像。这些图片代表19个班级,来自21个不同的城市。所有消融和超参数调整均在由20%图像组成的训练集的验证子集上进行。对于所有数据集,我们将图像调整为512×512,并进行中心裁剪。在训练时附加随机水平翻转增强。
Implementation details: For all experiments, we use a Deeplab-V3 [14] architecture with a ResNet-101 [28] backbone pretrained on ImageNet [16], as in [8]. For all datasets, we set a maximum threshold for the uncertainty measure of Eq. 7 to τ = 1e - 3. We train our model for 30 and 60 epochs per CSS step on Pascal VOC and ADE, respectively, with an initial learning rate of 1e - 2 for the first CSS step, and 1e-3 for all the following ones. We reduce the learning rate exponentially with a decay rate of 9e - 1. We use SGD optimizer with 9e-1 Nesterov momentum. The Local POD factor λ is set to 1e - 2 and 5e - 4 for intermediate feature maps and logits, respectively. Moreover, we multiply this factor by the adaptive weighting  introduced by [31] that increases the strength of the distillation the further we are into the continual process. For all feature maps, Local POD is applied before ReLU, with squared pixel values, as in [77, 18]. We use 3 scales for Local POD: 1, 1=2, and 1=4, as adding more scales experimentally brought diminishing returns. We use a batch size of 24 distributed on two GPUs. Contrary to many continual models, we don’t have access to any task id in inference, therefore our setting/strategy has to predict a class among the set of all seen classes —a realist setting.
introduced by [31] that increases the strength of the distillation the further we are into the continual process. For all feature maps, Local POD is applied before ReLU, with squared pixel values, as in [77, 18]. We use 3 scales for Local POD: 1, 1=2, and 1=4, as adding more scales experimentally brought diminishing returns. We use a batch size of 24 distributed on two GPUs. Contrary to many continual models, we don’t have access to any task id in inference, therefore our setting/strategy has to predict a class among the set of all seen classes —a realist setting.
实现细节:对于所有实验,我们都使用了一个Deeplab-V3[14]体系结构,在ImageNet[16]上预训练了一个ResNet-101[28]主干,如[8]所示。对于所有数据集,我们将等式7的不确定度测量值的最大阈值设置为τ=1e-3。我们分别在Pascal VOC和ADE上对我们的模型进行30和60个阶段的CSS步骤的训练,第一个CSS步骤的初始学习率为1e-2,接下来的所有步骤的初始学习率为1e-3。我们以9e-1的衰减率指数降低学习率。我们使用带有9e-1 Nesterov动量的SGD优化器。对于中间要素图和逻辑图,局部POD因子λ分别设置为1e-2和5e-4。此外,我们将该系数乘以[31]引入的自适应加权,该加权可增加蒸馏的强度,使我们进一步进入连续过程。对于所有特征地图,局部POD应用于ReLU之前,具有平方像素值,如[77,18]所示。我们对本地POD使用3个尺度:1、1=2和1=4,因为添加更多的尺度会带来递减的回报。我们在两个GPU上使用24个批量。与许多连续模型相反,我们在推理中无法访问任何任务id,因此我们的设置/策略必须在所有看到的类集合中预测一个类-现实主义设置。
Classes ordering details: For all quantitative experiments on Pascal-VOC 2012 and ADE20k, the same class ordering was used across all evaluated models. For Pascal-VOC 2012 it corresponds to [1, 2, ..., 20] and ADE20k to [1, 2, ..., 150] as defined in [8]. For continual-domain cityscapes, the order of the domains/cities is the following: aachen, bremen, darmstadt, erfurt, hanover, krefeld, strasbourg, tubingen, weimar, bochum, cologne, dusseldorf, hamburg, jena, monchengladbach, stuttgart, ulm, zurich, frankfurt, lindau, and munster.
类别排序详细信息:对于Pascal VOC 2012和ADE20k的所有定量实验,在所有评估模型中使用相同的类别排序。对于Pascal VOC 2012,它对应于[1,2,…,20],ADE20k对应于[8]中定义的[1,2,…,150]。对于连续域城市景观,域/城市的顺序如下:亚琛、不来梅、达姆施塔特、埃尔福特、汉诺威、克雷菲尔德、斯特拉斯堡、图宾根、魏玛、波鸿、科隆、杜塞尔多夫、汉堡、耶拿、蒙城拉德巴赫、斯图加特、乌尔姆、苏黎世、法兰克福、林道和蒙斯特。
In the main paper we showcased a boxplot featuring 20different class orders for Pascal-VOC 2012 15-1. For the sake of reproducibility, we provide details on these orders:
In the 15-1 setting, we first learn the first fifteen classes, then increment the five remaining classes one by one. Note that the special class background (0) is always learned during the first task.
在15-1设置中,我们首先学习前15个类,然后逐个增加剩余的5个类。请注意,特殊类背景(0)总是在第一个任务中学习的。
Hardware and Code: For each experiment, we used two Titan Xp GPUs with 12 Go of VRAM each. The initial step t = 1 for each setting is common to all models, therefore we re-use the weights trained on this step. All models took less than 2 hours to train on PascalVOC 2012 15-1, and less than 16 hours on ADE20k 100-10. We distributed the batch size equally on both GPUs. All models are implemented in PyTorch [59] and runned with half-precision for efficiency reasons with Nvdia’s APEX library (https://github.com/NVIDIA/apex) using O1 optimization level. Our code base is based on [8]’s code (https://github.com/fcdl94/MiB) that we modified to implement our strategy. It is available at https://github.com/arthurdouillard/CVPR2021 PLOP.
硬件和代码:对于每个实验,我们使用两个Titan Xp GPU,每个GPU有12个VRAM。每个设置的初始步骤t=1对于所有模型都是通用的,因此我们重复使用在该步骤中训练的权重。所有车型在PascalVOC 2012 15-1上的训练时间不到2小时,在ADE20k 100-10上的训练时间不到16小时。我们在两个GPU上平均分配批量大小。所有模型均在PyTorch[59]中实现,出于效率考虑,使用Nvdia的APEX库以半精度运行(https://github.com/NVIDIA/apex)使用O1优化级别。我们的代码库基于[8]的代码(https://github.com/fcdl94/MiB)我们为了实施我们的战略而修改了。可于https://github.com/arthurdouillard/CVPR2021 PLOP。
A.4. Additional Experiments
Model ablation: Table 7 shows the construction of our model component by component on Pascal-VOC 2012 in 15-5 and 15-1. For this experiment, we train our model on 80% of the training set and evaluate on the validation set made of the remaining 20%. We report the mIoU at the final task (“all”) and the average of the mIoU after each task (“avg”). We start with a crude baseline made of solely cross-entropy (CE). Pseudo-labeling by itself increases by a large margin performance (eg. 3.99 to 19.74 for 15-1). Applying Local POD reduces drastically the forgetting leading to a massive gain of performance (eg. 19.74 to 50.41 for 15-1). Finally our adaptive factor ν based on the ratio of accepted pseudo-labels over the number of background pixels further increases our overall results (eg. 50.41 to 52.31 for 15-1). The interest of ν arises when PLOP faces hard images where few pseudo-labels will be created due to an overall high uncertainty. In such a case, current classes will be over-represented, which can in turn lead to strong bias towards new classes (i.e. the model will have a tendency to predict one of the new classes for every pixel). The ν factor therefore decreases the overall classification loss on such images, and empirical results confirm its effectiveness.
模型消融:表7显示了我们在Pascal VOC 2012第15-5页和第15-1页上的模型组件构造。对于这个实验,我们在80%的训练集上训练我们的模型,并在剩下的20%的验证集上进行评估。我们报告最终任务的mIoU(“全部”)和每个任务后的mIoU平均值(“平均值”)。我们从一个仅由交叉熵(CE)构成的粗略基线开始。伪标记本身可以大幅度提高性能(例如,15-1的伪标记从3.99增加到19.74)。应用本地POD可以大大减少遗忘,从而获得巨大的性能提升(例如,15-1的成绩从19.74提高到50.41)。最后,我们基于接受的伪标签与背景像素数之比的自适应因子ν进一步增加了我们的总体结果(例如,对于15-1,从50.41增加到52.31)。当PLOP面对硬图像时,由于整体的高度不确定性,几乎不会创建伪标签,这时就产生了对ν的兴趣。在这种情况下,当前类将被过度表示,这反过来会导致对新类的强烈偏见(即,模型将倾向于预测每个像素的一个新类)。因此,ν因子降低了此类图像的总体分类损失,实证结果证实了其有效性。

Pascal-VOC 2012 Disjoint: In the main paper, we reported results on Pascal-VOC 2012 Overlap. For reasons mentioned previously, Overlap is a more realist setting than Disjoint. Nevertheless, for the sake of comparison, we also provide results in Table 8 in the Disjoint setting. While PLOP has similar performance to MiB in 15-5 (the differences are not significant), it significantly outperforms previous state-of-the-art methods in both 19-1 and 15-1.
Pascal VOC 2012不相交:在主要论文中,我们报告了Pascal VOC 2012重叠的结果。出于前面提到的原因,重叠比不相交更现实。然而,为了进行比较,我们还在表8中提供了不相交设置的结果。虽然PLOP在15-5中的性能与MiB相似(差异不显著),但它在19-1和15-1中的性能明显优于以前最先进的方法。
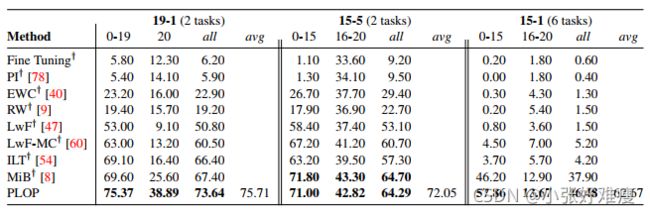
Pascal-VOC 2012 Overlap with more baselines: In Table 9, we report results on Pascal-VOC 2012 Overlap with more baselines. In addition to the models presented in the main paper, we add a naive Fine Tuning, two continual models based on weights constraints (PI [78] and RW [9]), and one continual model based on knowledge distillation (LwF [47]). PLOP surpasses these methods in all CSS scenarios.
Pascal VOC 2012与更多基线重叠:在表9中,我们报告了Pascal VOC 2012与更多基线重叠的结果。除了本文中介绍的模型外,我们还添加了一个简单的微调、两个基于权重约束的连续模型(PI[78]和RW[9])和一个基于知识提取的连续模型(LwF[47])。PLOP在所有CSS场景中都优于这些方法。