redis/redission实现分布式锁
分布式锁使得并行变为串行执行,实际上于我们的高并发相违背
1.redis实现分布式锁
重点:
- 占锁,设置超时时间为原子操作
- 上锁的 key 值为 UUID,防止删错锁
- 对于超时操作,有一专门一个线程来监视,watchDog进行锁续命(使用一条线程每10秒执行一次,如果锁还没有释放则自动续期锁的过期时间 )
public Map> getIndexCategoryMapDispersedLock() {
// 占锁,谁占到谁就查询
ValueOperations ops = stringRedisTemplate.opsForValue();
// 为了避免占锁后突然程序断电或停止等导致死锁,需要给锁加上过期时间,占锁和加锁必须保持原子性
String uuid = UUID.randomUUID().toString();
Boolean lock = ops.setIfAbsent("lock", uuid,60, TimeUnit.SECONDS);
if(lock){
// 执行业务,业务中再次查询缓存数据并缓存数据
Map> data = this.getCategoryFromDb();
String value = ops.get("lock");
// 比如设置的过期时间为10s,而程序执行时间为30s,程序还没有执行完毕就释放锁了,导致其他线程拿到锁也执行业务,执行后又释放其他线程的锁,这样就导致释放锁乱套了,为了解决这种释放其他线程的锁的情况,我们加锁时设置uuid,释放锁时比对值,值如果一样则释放,并且比对值和释放锁必须保持原子性,这种使用lua脚本保持原子性
// 还存在问题过期时间小于业务执行时间,需要续期过期时间,这个技术由分布式redission解决
String script = "if redis.call(\"get\",KEYS[1]) == ARGV[1] then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
stringRedisTemplate.execute(new DefaultRedisScript(script,Long.class),Arrays.asList("lock"),value);
return data;
}else {
try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
//重新抢锁
this.getIndexCategoryMapLocalLock();
}
return null;
}
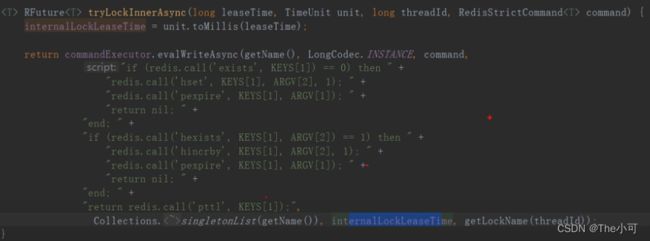
2.redission 实现分布式锁

核心源码: 超过默认设置时间(30s) / 3,根据主线程ID判断是否持有锁,持有就续命
-
引入redission jar 包
org.redisson redisson 3.13.4 -
注入 Bean (RedissonClient)
// redission通过redissonClient对象使用 // 如果是多个redis集群,可以配置 @Bean(destroyMethod = "shutdown") public RedissonClient redisson(){ Config config = new Config(); // 创建单例模式的配置 config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword("xudaze200129"); return Redisson.create(config); } -
加锁逻辑
@Autowired private RedissonClient redissonClient; public Map
Redission 实现读写锁
-
读+读 没有任何影响
-
写+读 读请求在写请求没有执行完毕的情况下会处于阻塞状态,等写完毕之后才会拿到最新请求
-
写+写 会依次排队,没拿到锁的请求后阻塞
-
读+写 会等读请求读完毕之后,写请求才会执行
@ResponseBody @GetMapping("index/read") public String testRead() throws InterruptedException { RReadWriteLock lock = redisson.getReadWriteLock("test-wr-lock"); // 拿到读锁 RLock rLock = lock.readLock(); rLock.lock(); // 业务逻辑 rLock.unlock(); return "读完毕"; }@ResponseBody @GetMapping("index/write") public String testWrite() throws InterruptedException { RReadWriteLock lock = redisson.getReadWriteLock("test-wr-lock"); // 拿到写锁 RLock rLock = lock.writeLock(); rLock.lock(); // 业务逻辑 rLock.unlock(); return "写完毕"; }
redission 信号量(Semaphore)
信号量为存储在redis中的一个数字,当这个数字大于0时,即可以调用acquire()方法增加数量,也可以调用release()方法减少数量,但是当调用release()之后小于0的话方法就会阻塞,直到数字大于0
@ResponseBody
@GetMapping("index/inSemaphore")
public String inSemaphore() throws InterruptedException {
// 进库车位就 -1
RSemaphore semaphore = redisson.getSemaphore("semaphore");
if(semaphore.tryAcquire(2,TimeUnit.SECONDS)){
semaphore.acquire(1);
return "进库";
}
return "车位已满";
}
@ResponseBody
@GetMapping("index/outSemaphore")
public String outSemaphore() throws InterruptedException {
RSemaphore semaphore = redisson.getSemaphore("semaphore");
// 出库车位 +1
semaphore.release(1);
return "出库";
}
redission 闭锁,门闩(CountDownLatch )
比如现在有10个任务,必须要10个任务全部完成才算完成任务,count不等于就等待,用于集齐一批一起执行
/**
* 模拟学校锁门
* 保安锁门
* @return
*/
@ResponseBody
@GetMapping("index/studentlockroom")
public String studentlockroom() throws InterruptedException {
RCountDownLatch room = redisson.getCountDownLatch("room");
// 设置几个班,必须要等5个班的同学都走完之后再锁门
room.trySetCount(5);
room.await();
return "锁门";
}
/**
* 模拟学校锁门
* 班级放假
* @return
*/
@ResponseBody
@GetMapping("index/gogogo/{id}")
public String gogogo(@PathVariable("id")String id) throws InterruptedException {
RCountDownLatch room = redisson.getCountDownLatch("room");
room.countDown();
return id+"班放假了";
}
数据一致性问题
我们使用缓存后如果需要保持数据一致性怎么办 ?
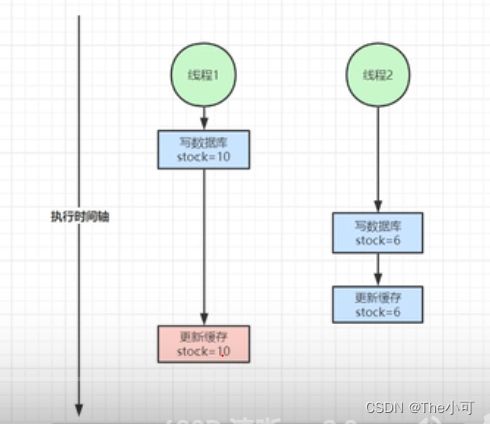
双写模式: 写数据库的同时写缓存,但是可能会出现以下情况
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hRbWoPwa-1662453238528)(C:\Users\HP\Desktop\学习方向\Redis\图片\数据一致性问题.PNG)]
- 如果对某些数据的实时性要求不是很高的话可以设置过期时间,到时间会自动更新缓存,
- 但如果要改动了之后需要立马更新到缓存中的解决办法就是加锁或加读写锁即可解决上面的问题

假设现在有请求ABC同时到达,但由于各种原因导致它们处理数据的速度不一致,请求A到达后处理的最快,已经把数据库更新了并且把缓存删除了。请求B正在写数据库但是还没有写完,这是请求C读取数据的时候发现缓存中没有,就去数据库查询到了请求A修改的数据库,这时候请求B才把数据库写完然后删除缓存,然后请求C更新请求A修改的值到缓存中,导致数据库的值是请求B写的,缓存中的值是请求A写的,数据不一致问题,但这些也只是暂时性的脏读,等到过期时间到了即可一致。如果非要保证数据一致性高的话可用读写锁解决问题。
3.主从架构 redis分布式锁失效问题:
3.1 常用分布式集群实现分布式锁
-
redis集群实现分布式锁:A(可用性)P(分区容错性),在主节点加锁成功就代表加锁成功,之后再由主节点同步到从节点
适用: 并发高
-
zookeeper集群实现分布式锁 : C(强一致性) P(分区容错性),在主节点加锁成功,再由主节点同步到从节点,从节点返回加锁成功,即半数以上节点均返回加锁成功才返回结果加锁成功。
适用:强一致性
3.2 解决redis主从切换锁丢失问题
1.Redlock 实现原理:个节点没有关系,每次加锁都同时往所有节点上加锁,必须一半以上节点加锁成功才算加锁成功
4.提高并发效率
基于concurrentHashMap的分段锁机制:
将一个大的库存拆分为多个小的库存段,如将一个 productID : 100,拆分为多个productID_1 : 25,productID_2 : 25,productID_3 : 25,productID_4 : 25
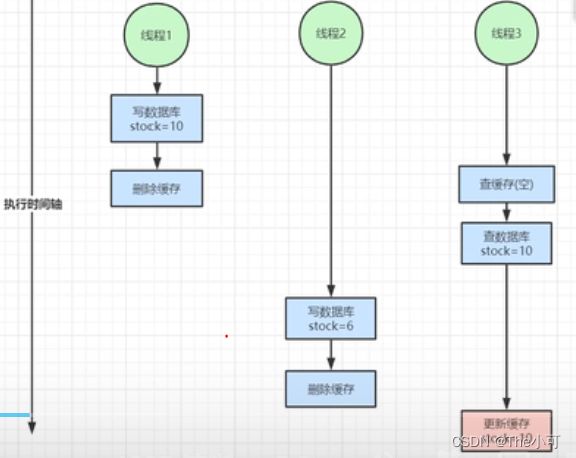
5.双写数据不一致问题:
- 写完数据库后更新
- 写完数据库后删除key,由查的时候更新缓存
6.Redis 为什么快?
- 底层基于 Epoll 和 select 的IO多路复用,NIO
- 单线程没有线程的上下文切换
- 基层数据结构,hash 算法( 全局hash表 )
- set a 111 进行set操作的时候,会判断value是否能转为 int ,若能则以整性编码
- set b 1aa 进行set操作判断不能转为 int 类型,底层用 embstr 编码
Blocking MQ(阻塞队列) = LPUSH + BRPOP
为什么要用redis的数据结构,而不是java?
redis 可跨多个 JVM,分布式数据结构,对所有web应用共享
1.抽奖活动:
1.添加抽奖人 : sadd key value
2.取出全部数据 : smembers key
3.随机取出2个参与人 : srandmember key 2
4.抽1,2,3等奖(取出来的key会删除), spop key 2
2.微信点赞,收藏,标签:
-
点赞 :
sadd like:{消息ID} {用户ID}
-
取消点赞
srem like:{消息ID} {用户ID}
-
检查用户是否点过赞
sismember like:{消息ID} {用户ID}
-
获取点赞的用户列表
smembers like:{消息ID}
-
获取点赞的用户数
scard like:{消息ID}
3.关注模型:
sinter (交集), sunion (并集) ,sdiff(差集)
- 共同关注: sinter me he
- 我关注的人也关注过他 sismember he she
- 我可能认识的人 sdiff he me
4.排行榜:
-
点击新闻增加访问量:
zincrby hotNews:20220829 1 setKey
-
展示当日排行前十
zrevrange hotNews:20220829 0 9 withscores
-
7日搜索榜单计算
zunionstore hotNews:20190822-20220829 7
-
展示7日排行前十
zrevrange hotNews:20220822-20220829 0 9 withscores
5.跳表:
zset :
数据少( < zset-max-ziplist-entries (默认128个) )的时候是 ziplist
多的时候 是 skiplist

-
**查找:**从顶层向下,不断缩小搜索范围。
-
插入:
首先需要判断节点2是否已经存在,若存在则返回
false。否则,随机生成待插入节点的层数。
/** * 生成随机层数[0,maxLevel) * 生成的值越大,概率越小 * * @return */ private int randomLevel() { int level = 0; while (Math.random() < PROBABILITY && level < maxLevel - 1) { ++level; } return level; }- PROBABILITY = 0.5
-
删除: 就是将它的前驱节点指向它的后继节点
O ( log n ) 的删除算法实现基本都是基于双向链表的,但是双向链表需要多维护一个pre指针,或者额外需要一个updates列表来记录前驱节点,增加了复杂度。根据查找算法,理论上是可以在一次查找过程中找到它的前驱节点,并进行删除的。