【语义分割】——STDC-Seg快又强 + 细节边缘的监督
paper
code:STDC-Seg
自己修改的code:https://github.com/chenjun2hao/STDC-Seg, 在pytorch1.7.0上测试通过
来自美团
0. 实时语义系列
- AttaNet:strip pooling的进化,快又好
- 实时语义分割DDRNet
1. 简介
前面也介绍了几篇强大的实时语义分割项目或者paper,这里再介绍一个来自美团CVPR2021的项目:STDC-Seg,既然是上了CVPR的,肯定是精度又高,速度上也很能打的。这里先看论文给出的直观对比图。

再附上,我在TX2上实测对比表格:

可以看到,STDC-Seg,AttaNet,DDRNET都能在tx2上做到实时。这里我们直接就着项目的代码进行分析一下。
2. 分析
2.1 网络模型结构

2.1 backbone
这里就不深入了。
2.2 ARM
这里是一个上下文模块,类似pspnet中的ppm模块。只是这里只输出一个尺寸,而且采用了加法进行融合
avg = F.avg_pool2d(feat32, feat32.size()[2:])
avg = self.conv_avg(avg)
avg_up = F.interpolate(avg, (H32, W32), mode='nearest')
feat32_arm = self.arm32(feat32)
feat32_sum = feat32_arm + avg_up
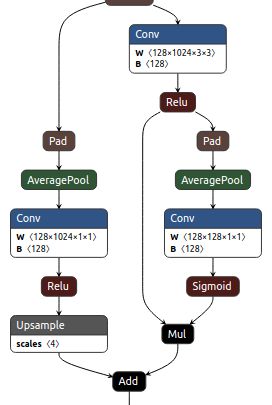
左边是Context info,右边分支是通道info/spatial info
2.3 边缘细节的辅助监督
项目采用边缘细节对语义分割网络进行辅助监督,同时,监督的是:网络前端 1/8的输出,(因为网络前端的细节信息更加丰富),边缘细节的 target 采用 拉普拉斯卷积核和语义label卷积得到。
这里卷积的时候,采用了stride=1,2,4三个不同的参数,然后再做了一个融合。

class DetailAggregateLoss(nn.Module):
def __init__(self, *args, **kwargs):
super(DetailAggregateLoss, self).__init__()
self.laplacian_kernel = torch.tensor(
[-1, -1, -1, -1, 8, -1, -1, -1, -1],
dtype=torch.float32).reshape(1, 1, 3, 3).requires_grad_(False).type(torch.cuda.FloatTensor)
self.fuse_kernel = torch.nn.Parameter(torch.tensor([[6./10], [3./10], [1./10]],
dtype=torch.float32).reshape(1, 3, 1, 1).type(torch.cuda.FloatTensor))
def forward(self, boundary_logits, gtmasks):
# boundary_logits = boundary_logits.unsqueeze(1)
boundary_targets = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, padding=1)
boundary_targets = boundary_targets.clamp(min=0)
boundary_targets[boundary_targets > 0.1] = 1
boundary_targets[boundary_targets <= 0.1] = 0
boundary_targets_x2 = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, stride=2, padding=1)
boundary_targets_x2 = boundary_targets_x2.clamp(min=0)
boundary_targets_x4 = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, stride=4, padding=1)
boundary_targets_x4 = boundary_targets_x4.clamp(min=0)
boundary_targets_x8 = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, stride=8, padding=1)
boundary_targets_x8 = boundary_targets_x8.clamp(min=0)
boundary_targets_x8_up = F.interpolate(boundary_targets_x8, boundary_targets.shape[2:], mode='nearest')
boundary_targets_x4_up = F.interpolate(boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')
boundary_targets_x2_up = F.interpolate(boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')
boundary_targets_x2_up[boundary_targets_x2_up > 0.1] = 1
boundary_targets_x2_up[boundary_targets_x2_up <= 0.1] = 0
boundary_targets_x4_up[boundary_targets_x4_up > 0.1] = 1
boundary_targets_x4_up[boundary_targets_x4_up <= 0.1] = 0
boundary_targets_x8_up[boundary_targets_x8_up > 0.1] = 1
boundary_targets_x8_up[boundary_targets_x8_up <= 0.1] = 0
boudary_targets_pyramids = torch.stack((boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up), dim=1)
boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)
boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids, self.fuse_kernel)
boudary_targets_pyramid[boudary_targets_pyramid > 0.1] = 1
boudary_targets_pyramid[boudary_targets_pyramid <= 0.1] = 0
if boundary_logits.shape[-1] != boundary_targets.shape[-1]:
boundary_logits = F.interpolate(
boundary_logits, boundary_targets.shape[2:], mode='bilinear', align_corners=True)
bce_loss = F.binary_cross_entropy_with_logits(boundary_logits, boudary_targets_pyramid)
dice_loss = dice_loss_func(torch.sigmoid(boundary_logits), boudary_targets_pyramid)
return bce_loss, dice_loss
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
nowd_params += list(module.parameters())
return nowd_params
2.4 边缘的loss
采用的BCELOSS + DICEloss两个loss
3. 总结
- 提出了一个更精简与优秀的网络
- 用边缘loss进行辅助训练,不增加训练时间
- 速度在最优的行列,效果好。