场景文字检测DBnet论文解读
文章目录
- 前言
- 一、简介
- 二、相关工作
-
- 1.基于回归的方法
- 2.基于回归的方法
- 三.Methodology
-
- 1.Differentiable binarization(可微分二值化)
- 2.概率图标签
- 3.损失函数
- 4.推理
- 5.缺点
- 总结
前言
最近接触到了文字检测,学习一下DBnet。
一、简介
DBnet提出了一个可微二值化(DB)模块,该模块可以在分割网络中进行二值化处理。与DB模块一起优化的分割网络可以自适应地设置二值化的阈值,不仅简化了后处理,而且提高了文本检测的性能。
标准的二值化过程是不可微的,作者提出了一个近似二值化函数代替标准二值化,也就是这个DB模块,并且DB模块在推理阶段还可以删除,不影响推理速度。
两个函数图像对比如下:

DBnet的优点如下:
(1)DBnet能检测任意形状文本,并且在各个数据集上取得了好性能。
(2)DBnet执行速度比以前的领先方法快得多,因为DB可以提供一个高度鲁棒的二值化映射,大大简化了后处理。
(3)DB在使用轻量级骨干时工作得非常好,它显著地增强了ResNet-18骨干的检测性能。
(4)由于可以在推断阶段删除DB,而不牺牲性能,因此测试不需要额外的内存/时间成本。
二、相关工作
最近的场景文本检测方法大致可以分为两类:基于回归的方法和基于分割的方法。
1.基于回归的方法
基于回归的方法是一系列直接回归文本实例的边界框的模型。文本框(Liao et al. 2017)修改了基于SSD的锚点和卷积核的尺度(Liu et al. 2016),用于文本检测。TextBoxes++ (Liao, Shi, and Bai 2018)和DMPNet (Liu, and Jin 2017)应用四边形回归检测多面向文本。SSTD (He et al. 2017a)提出了一种用于粗略识别文本区域的注意机制。RRD (Liao et al. 2018)通过使用旋转不变特征进行分类,使用旋转敏感特征进行回归,从而将分类和回归解耦,从而更好地处理多面向和长文本实例。EAST (Zhou et al. 2017)和DeepReg (He et al. 2017b)是无锚方法,它们对多面向文本实例应用像素级回归。SegLink (Shi, Bai, and Belongie 2017)回归段包围框并预测它们的链接,以处理长文本实例。DeRPN (Xie et al. 2019b)提出了一种维度分解区域建议网络来处理场景文本检测中的尺度问题。基于回归的方法通常采用简单的后处理算法(如非最大抑制)。然而,它们中的大多数都不能准确地表示不规则形状(如曲线形状)的边界框。
2.基于回归的方法
基于分割的方法通常结合像素级预测和后处理算法来得到包围盒。(Zhang et al. 2016)通过语义分割和基于mser的算法检测多面向文本。文本边框被用于(Xue, Lu, and Zhan 2018)分割文本实例,蒙版TextSpotter (Lyu et al. 2018a;Liao等人。2019)基于Mask R-CNN的实例分割方式检测任意形状的文本实例。PSENet (Wang et al. 2019a)通过分割具有不同尺度内核的文本实例,提出了递进尺度扩展。(Tian et al. 2019)中提出了像素嵌入,从分割结果中聚类像素。PSENet (Wang et al. 2019a)和SAE (Tian et al. 2019)对分割结果提出了新的后处理算法,导致推断速度较低。相反,DBnet的方法专注于改进分割结果,将二值化过程纳入训练期间,而不损失推理速度。
三.Methodology
DBnet的架构如下:

前面和普通的分割模型类似,都是backbone+fpn及其变种。然后将fpn的各个特征上采样到同一个尺度产生级联特征。利用这个级联特征得到概率图P和阈值图T,P和T经过DB模块得到了近似二值图B。然后对P,T,B进行监督,其中P和B共享监督信息。
1.Differentiable binarization(可微分二值化)

DB模块是DBnet的一个关键,主要创新就是把二值化的过程变成可优化的,提出了自适应二值化。我们先看DB模块的公式:
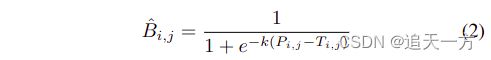
其中Pij和Tij就对应了概率图和阈值图,K是方法系数,论文中设为50。该近似二值化函数与标准二值化函数的行为类似,但具有可微性,因此可以在训练期间随分割网络进行优化。具有自适应阈值的可微分二值化方法不仅可以将文本区域从背景中区分出来,而且可以分离出紧密连接的文本实例(笔者感觉是因为阈值图监督的是突出文本的边界)。
2.概率图标签
一个示例如下:
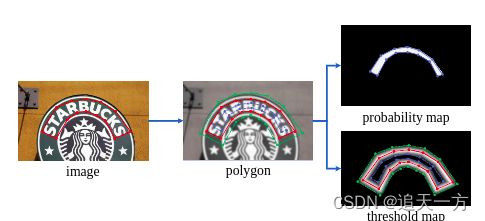
其中红色部分是原来的标注,绿色部分是扩张的标注,蓝色是收缩的。
概率图标签(近似二值图也是)就参照了psenet的kernel的想法,采用Vatti裁减算法收缩文本。将原来的文本G收缩到Gs,这个Gs就是概率图标签,收缩的偏移两D计算如下:

其中A是多边形的面积,L是周长,r是收缩比,论文中是0.4.
通过类似的过程,我们可以为阈值图生成标签。首先,文本多边形G以相同的偏移量D扩张到到Gd。我们将G和Gd之间的间隙作为文本区域的边界,其中阈值图的标签可以通过计算到G中最近的线段的距离来产生。
3.损失函数
损失函数就是三个图损失的加权和。其中概率图和近似二值图采用BCE损失,但是因为正负样本不平衡,所以采样正负样本比例为1:3:

阈值图则采用L1损失:

4.推理
在推断阶段,我们可以使用概率映射或近似二进制映射来生成文本边界框,它们产生的结果几乎相同。为了提高效率,我们使用了概率图,从而可以消除阈值分支。方框形成过程包括三个步骤:
(1)首先将概率图/近似二值图以恒定阈值(0.2)进行二值化处理,得到二值图;
(2)由二值映射得到连通区域(收缩文本区域);
(3)利用偏移D’the Vatti裁剪算法(Vati 1992)对收缩区域进行扩张。
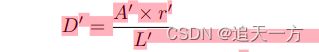
其中A '为收缩多边形的面积;L’是收缩后多边形的周长;R '是收缩比,根据经验设置为1.5。
5.缺点
不能检测文本里的的文本,这是基于分割方法都有的缺点,简单来说就是文本里面还有一个文本,这时是两个文本,但是DBnet只能检测出是一个文本。
总结
感觉DBnet还是很nice的,作者的代码也易读。