C++易错易忘点总结
目录
- 31.什么是IO多路复用
- 30.linux 预编译头文件
- 29.c++微妙即计时器
- 28. set的find方法
- 27. 用map的insert 方法查看插入结果
- 26. vector resize与reverse
- 25. call once
- 24.static关键字(待补充)
- 23:effective c++
-
- 1.尽量使用const 代替 #define
- 22.常用知识点
- 21.使用void** 作为出参
- 20. move与forward
- 19.字符串分割
- 18.生成随机字符串
- 17.仿函数
- 16. thread中的join()与detach()
- 15.C++ 11 获取UTC时间戳
- 14.set_difference
- 13.标准输入重定向
- 12.结构体用memset进行初始化
- 11.memset 只能按字节进行初始化
- 10.std::move()
- 9.std::forward()
- 8.lock_guard,unique_lock,scoped_lock 与各种锁(待补充)
- 7.composition(组合/复合) aggregation(聚合) association(关联/联系)
- 6.sizeof与数组
- 5.字节对齐(结构体与sizeof)
- 4.sizeof与类
- 3.大小端(经常忘记)
- 2. sizeof与strlen的区别
-
-
- Demo1
- Demo2
-
- 1、c风格字符串记得以‘\0’(或直接写作0)结尾(注意不能是‘0’)
31.什么是IO多路复用
作者:罗志宇
链接:https://www.zhihu.com/question/32163005/answer/55772739
其实“I/O多路复用”这个坑爹翻译可能是这个概念在中文里面如此难理解的原因。所谓的I/O多路复用在英文中其实叫 I/O multiplexing. 如果你搜索multiplexing啥意思,基本上都会出这个图:

于是大部分人都直接联想到"一根网线,多个sock复用" 这个概念,包括上面的几个回答, 其实不管你用多进程还是I/O多路复用, 网线都只有一根好伐。多个Sock复用一根网线这个功能是在内核+驱动层实现的。
重要的事情再说一遍: I/O multiplexing 这里面的 multiplexing 指的其实是在单个线程通过记录跟踪每一个Sock(I/O流)的状态(对应空管塔里面的Fight progress strip槽)来同时管理多个I/O流. 发明它的原因,是尽量多的提高服务器的吞吐能力。 是不是听起来好拗口,看个图就懂了.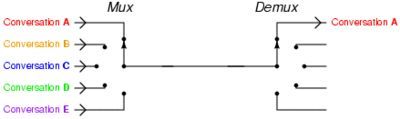
在同一个线程里面, 通过拨开关的方式,来同时传输多个I/O流, (学过EE的人现在可以站出来义正严辞说这个叫“时分复用”了)。
什么,你还没有搞懂“一个请求到来了,nginx使用epoll接收请求的过程是怎样的”, 多看看这个图就了解了。提醒下,ngnix会有很多链接进来, epoll会把他们都监视起来,然后像拨开关一样,谁有数据就拨向谁,然后调用相应的代码处理。
30.linux 预编译头文件
编写一个简单的文件hello.cpp
#include
using namespace std;
int main()
{
cout<<"hello world"<
g++ -o hello_r hello.cpp -H
// 明明只包含了一个头文件,实际却连接了这么多,头文件再多些的话,编译速度肯定会慢,如何解决?使用预编译头文件
. /usr/include/c++/4.8.2/iostream
.. /usr/include/c++/4.8.2/x86_64-redhat-linux/bits/c++config.h
... /usr/include/bits/wordsize.h
... /usr/include/c++/4.8.2/x86_64-redhat-linux/bits/os_defines.h
.... /usr/include/features.h
..... /usr/include/sys/cdefs.h
...... /usr/include/bits/wordsize.h
..... /usr/include/gnu/stubs.h
...... /usr/include/gnu/stubs-64.h
... /usr/include/c++/4.8.2/x86_64-redhat-linux/bits/cpu_defines.h
.. /usr/include/c++/4.8.2/ostream
... /usr/include/c++/4.8.2/ios
.... /usr/include/c++/4.8.2/iosfwd
..... /usr/include/c++/4.8.2/bits/stringfwd.h
...... /usr/include/c++/4.8.2/bits/memoryfwd.h
..... /usr/include/c++/4.8.2/bits/postypes.h
...... /usr/include/c++/4.8.2/cwchar
....... /usr/include/wchar.h
........ /usr/include/stdio.h
........ /usr/lib/gcc/x86_64-redhat-linux/4.8.5/include/stdarg.h
........ /usr/include/bits/wchar.h
......... /usr/include/bits/wordsize.h
........ /usr/lib/gcc/x86_64-redhat-linux/4.8.5/include/stddef.h
........ /usr/include/xlocale.h
.... /usr/include/c++/4.8.2/exception
..... /usr/include/c++/4.8.2/bits/atomic_lockfree_defines.h
.... /usr/include/c++/4.8.2/bits/char_traits.h
..... /usr/include/c++/4.8.2/bits/stl_algobase.h
...... /usr/include/c++/4.8.2/bits/functexcept.h
....... /usr/include/c++/4.8.2/bits/exception_defines.h
...... /usr/include/c++/4.8.2/bits/cpp_type_traits.h
...... /usr/include/c++/4.8.2/ext/type_traits.h
...... /usr/include/c++/4.8.2/ext/numeric_traits.h
...... /usr/include/c++/4.8.2/bits/stl_pair.h
....... /usr/include/c++/4.8.2/bits/move.h
........ /usr/include/c++/4.8.2/bits/concept_check.h
...... /usr/include/c++/4.8.2/bits/stl_iterator_base_types.h
...... /usr/include/c++/4.8.2/bits/stl_iterator_base_funcs.h
....... /usr/include/c++/4.8.2/debug/debug.h
...... /usr/include/c++/4.8.2/bits/stl_iterator.h
..... /usr/include/c++/4.8.2/cwchar
...... /usr/include/wchar.h
.... /usr/include/c++/4.8.2/bits/localefwd.h
..... /usr/include/c++/4.8.2/x86_64-redhat-linux/bits/c++locale.h
...... /usr/include/c++/4.8.2/clocale
....... /usr/include/locale.h
........ /usr/lib/gcc/x86_64-redhat-linux/4.8.5/include/stddef.h
........ /usr/include/bits/locale.h
..... /usr/include/c++/4.8.2/cctype
...... /usr/include/ctype.h
....... /usr/include/bits/types.h
........ /usr/include/bits/wordsize.h
........ /usr/include/bits/typesizes.h
....... /usr/include/endian.h
........ /usr/include/bits/endian.h
........ /usr/include/bits/byteswap.h
......... /usr/include/bits/wordsize.h
......... /usr/include/bits/byteswap-16.h
.... /usr/include/c++/4.8.2/bits/ios_base.h
..... /usr/include/c++/4.8.2/ext/atomicity.h
...... /usr/include/c++/4.8.2/x86_64-redhat-linux/bits/gthr.h
....... /usr/include/c++/4.8.2/x86_64-redhat-linux/bits/gthr-default.h
........ /usr/include/pthread.h
......... /usr/include/sched.h
.......... /usr/lib/gcc/x86_64-redhat-linux/4.8.5/include/stddef.h
.......... /usr/include/time.h
.......... /usr/include/bits/sched.h
......... /usr/include/time.h
.......... /usr/lib/gcc/x86_64-redhat-linux/4.8.5/include/stddef.h
.......... /usr/include/bits/time.h
........... /usr/include/bits/timex.h
......... /usr/include/bits/pthreadtypes.h
.......... /usr/include/bits/wordsize.h
......... /usr/include/bits/setjmp.h
.......... /usr/include/bits/wordsize.h
......... /usr/include/bits/wordsize.h
...... /usr/include/c++/4.8.2/x86_64-redhat-linux/bits/atomic_word.h
..... /usr/include/c++/4.8.2/bits/locale_classes.h
...... /usr/include/c++/4.8.2/string
....... /usr/include/c++/4.8.2/bits/allocator.h
........ /usr/include/c++/4.8.2/x86_64-redhat-linux/bits/c++allocator.h
......... /usr/include/c++/4.8.2/ext/new_allocator.h
.......... /usr/include/c++/4.8.2/new
....... /usr/include/c++/4.8.2/bits/ostream_insert.h
........ /usr/include/c++/4.8.2/bits/cxxabi_forced.h
....... /usr/include/c++/4.8.2/bits/stl_function.h
........ /usr/include/c++/4.8.2/backward/binders.h
....... /usr/include/c++/4.8.2/bits/range_access.h
....... /usr/include/c++/4.8.2/bits/basic_string.h
....... /usr/include/c++/4.8.2/bits/basic_string.tcc
...... /usr/include/c++/4.8.2/bits/locale_classes.tcc
.... /usr/include/c++/4.8.2/streambuf
..... /usr/include/c++/4.8.2/bits/streambuf.tcc
.... /usr/include/c++/4.8.2/bits/basic_ios.h
..... /usr/include/c++/4.8.2/bits/locale_facets.h
...... /usr/include/c++/4.8.2/cwctype
....... /usr/include/wctype.h
........ /usr/include/wchar.h
...... /usr/include/c++/4.8.2/cctype
...... /usr/include/c++/4.8.2/x86_64-redhat-linux/bits/ctype_base.h
...... /usr/include/c++/4.8.2/bits/streambuf_iterator.h
...... /usr/include/c++/4.8.2/x86_64-redhat-linux/bits/ctype_inline.h
...... /usr/include/c++/4.8.2/bits/locale_facets.tcc
..... /usr/include/c++/4.8.2/bits/basic_ios.tcc
... /usr/include/c++/4.8.2/bits/ostream.tcc
.. /usr/include/c++/4.8.2/istream
... /usr/include/c++/4.8.2/bits/istream.tcc
Multiple include guards may be useful for:
/usr/include/bits/byteswap-16.h
/usr/include/bits/byteswap.h
/usr/include/bits/endian.h
/usr/include/bits/locale.h
/usr/include/bits/sched.h
/usr/include/bits/time.h
/usr/include/bits/typesizes.h
/usr/include/c++/4.8.2/clocale
/usr/include/c++/4.8.2/cwctype
/usr/include/c++/4.8.2/x86_64-redhat-linux/bits/ctype_base.h
/usr/include/c++/4.8.2/x86_64-redhat-linux/bits/ctype_inline.h
/usr/include/gnu/stubs-64.h
/usr/include/gnu/stubs.h
使用预编译头文件。写一个文件如: head.h
//head.h
#include
[root@HikvisionOS test]# cat head.h
#include
29.c++微妙即计时器
#include
#include
#include
// "busy sleep" while suggesting that other threads run
// for a small amount of time
void little_sleep(std::chrono::microseconds us)
{
auto start = std::chrono::high_resolution_clock::now();
auto end = start + us;
do {
std::this_thread::yield();
} while (std::chrono::high_resolution_clock::now() < end);
}
int main()
{
auto start = std::chrono::high_resolution_clock::now();
little_sleep(std::chrono::microseconds(100));
auto elapsed = std::chrono::high_resolution_clock::now() - start;
std::cout << "waited for "
<< std::chrono::duration_cast(elapsed).count()
<< " microseconds\n";
return 0;
}
28. set的find方法
1.set的find方法返回的是常量迭代器,不能对set的内容进行修改,要想修改需要先去掉其常量属性 const_cast
2.向set中插入元素时,如果元素已经存在,就不会插入了(不会替换为最新,对于自定义类型要特别注意)
#if 1
struct CT
{
int a;
std::set b;
bool operator == (const CT& other) const;
bool operator < (const CT& other) const;
};
bool CT::operator==(const CT& other) const{
return this->a == other.a;
}
bool CT::operator<(const CT& other) const{
return this->a < other.a;
}
int main()
{
CT t = {1,{"11"}};
set st;
st.insert({1,{"11"}});
st.insert({2,{"22"}});
//set返回的是常量迭代器,不支持修改
auto iter = st.find(t);
if(iter!=st.end())
{
//去掉常量属性才能进行修改
auto &mod = const_cast(*iter);
mod.b.insert("44");
mod.b.erase("22");
mod.b.erase("22");
}
return 0;
}
27. 用map的insert 方法查看插入结果
#if 1
//map插入返回值
// 1.键值相同重复插入,会失败
// 2.插入返回迭代器的first指向插入的数据,second指向插入的结果
int main()
{
map mcache;
auto iter = mcache.insert(pair(1,"a"));
if(iter.second){
cout <<"insert success "<first<<","<<(iter.first)->second << endl;//1,a
}
auto iter1 = mcache.insert({1,"a"});
if(iter1.second){
cout <<"insert success "<
26. vector resize与reverse
resize : resizes the container so that ti contains n elements. 改变容器的大小,让容器中包好n个元素
reverse: requests that the vector capacity be at least enough to contain n elements. 改变容器的容量,容器的实际大小并不会改变
25. call once
int test_once()
{
static std::once_flag flag;
std::call_once(flag, []() {
cout << " call me" <
24.static关键字(待补充)
23:effective c++
1.尽量使用const 代替 #define
原因: define 定义的变量名会在编译时被替换掉,如果编译出错,不方便定位错误
22.常用知识点
auto 关键字- for-each 循环
- 右值及移动构造函数 + std::forward + std::move + stl 容器新增的 emplace_back() 方法
- std::thread 库、std::chrono 库
- 智能指针系列(std::shared_ptr/std::unique_ptr/std::weak_ptr),智能指针的实现原理一定要知道,最好是自己实现过
- 线程库 std::thread + 线程同步技术库 std::mutex/std::condition_variable/std::lock_guard 等
- Lamda 表达式(Java 中现在也常常考察 Lamda 表达式的作用)
- std::bind/std::function 库
21.使用void** 作为出参
#include
20. move与forward
C++11 std::move和std::forward
19.字符串分割
//通过istringstream 进行分割
#include
18.生成随机字符串
std::string character[62]={"a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z"};
std::string GetUUID(int length)
{
length = length < 8 ? 8 : length;
std::string uuid;
int index = 0;
// uniform_int_distribution u(0,61);
// std::default_random_engine engine(time(nullptr));
// sleep(1);//延时:保证两次连续生成的两组随机数不同
std::random_device rd;
std::default_random_engine engine(rd());
std::uniform_int_distribution<unsigned> dis(0, 61);
auto dice = std::bind(dis, engine);
for (int i = 0; i < length; ++i)
{
index = dice() % 62;
uuid += character[index];
}
return uuid;
}
17.仿函数
-
仿函数老是和函数对象 std::function(类模板 std::function 是通用多态函数封装器。 std::function 的实例能存储、复制及调用任何可调用 (Callable) 目标——函数、 lambda 表达式、 bind 表达式或其他函数对象,还有指向成员函数指针和指向数据成员指针)搞混。 std::function
-
仿函数(functor),就是使一个类的使用看上去像一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了。仿函数本质就是类重载了一个operator(),创建一个行为类似函数的对象。
对于重载了()操作符的类,可以实现类似函数调用的过程,所以叫做仿函数,实际上仿函数对象仅仅占用1字节,因为内部没有数据成员,仅仅是一个重载的方法而已。实际上可以通过传递函数指针实现类似的功能,但是为了和STL内部配合使用,他提供了仿函数的特性。
仿函数
16. thread中的join()与detach()
jion()线程合并,detach线程分离,detach后删除了线程对象,那么被detach的线程还能正常工作吗?这个问题好像反复实验了好几次.但是再次想起来还是忘记结论,很困惑. 记住结论: 会!线程对象删除后,被detach的线程还能正常运行
#include
15.C++ 11 获取UTC时间戳
/*
#include
#include
using namespace std;
using namespace std::chrono;
*/
//秒
time_t now = time(nullptr);
cout<<now<<endl;
//默认是纳秒的
std::chrono::system_clock::time_point now1 = std::chrono::system_clock::now();
cout << "timestampx: " << now1.time_since_epoch().count() <<endl;
//获取UTC时间戳(控制精度 为纳秒级 std::chrono::nanoseconds )
std::chrono::time_point<std::chrono::system_clock,std::chrono::nanoseconds> tp = std::chrono::time_point_cast<std::chrono::nanoseconds>(std::chrono::system_clock::now());
//纳秒
auto tmp0=std::chrono::duration_cast<std::chrono::nanoseconds>(tp.time_since_epoch());
std::time_t timestamp0 = tmp0.count();
cout << "timestamp0: " <<timestamp0 <<endl;
//微妙
auto tmp1=std::chrono::duration_cast<std::chrono::microseconds>(tp.time_since_epoch());
std::time_t timestamp1 = tmp1.count();
cout << "timestamp1: " <<timestamp1 <<endl;
//毫秒
auto tmp2=std::chrono::duration_cast<std::chrono::milliseconds>(tp.time_since_epoch());
std::time_t timestamp2 = tmp2.count();
cout << "timestamp2: " <<timestamp2 <<endl;
//秒
auto tmp3=std::chrono::duration_cast<std::chrono::seconds>(tp.time_since_epoch());
std::time_t timestamp3 = tmp3.count();
cout << "timestamp3: " <<timestamp3 <<endl;
//分钟
auto tmp4=std::chrono::duration_cast<std::chrono::minutes>(tp.time_since_epoch());
std::time_t timestamp4 = tmp4.count();
cout << "timestamp4: " <<timestamp4 <<endl;
//小时
auto tmp5=std::chrono::duration_cast<std::chrono::hours>(tp.time_since_epoch());
std::time_t timestamp5 = tmp5.count();
cout << "timestamp5: " <<timestamp5 <<endl;
==输出==
timestampx: 1596031254748631655
timestamp0: 1596031254748759907
timestamp1: 1596031254748759
timestamp2: 1596031254748
timestamp3: 1596031254
timestamp4: 26600520
timestamp5: 443342
14.set_difference
set_defference只能用来对有序的集合求差集,最好是用在set这类天然有序的容器上
//set_defference只能用来对有序的集合求差集,最好是用在set这类天然有序的容器上
std::vector<string> v1{"1111","mmmm","2222","ffff","tttt","4444"};
std::vector<string> v2{"gggg","hhhh","4444"};
cout<<"v1 = ";
for_each(v1.begin(),v1.end(),[](std::string item){
cout<<item<<" ";
});
cout<<endl;
cout<<"v2 = ";
for_each(v2.begin(),v2.end(),[](std::string item){
cout<<item<<" ";
});
cout<<endl;
std::vector<string> v3;
std::set_difference(v1.begin(),v1.end(),v2.begin(),v2.end(),std::inserter(v3, v3.begin()));
cout<<"[before sort]v3 = ";
for_each(v3.begin(),v3.end(),[](std::string item){
cout<<item<<" ";
});
cout<<endl;
sort(v1.begin(),v1.end());
sort(v2.begin(),v2.end());
v3.clear();
std::set_difference(v1.begin(),v1.end(),v2.begin(),v2.end(),std::inserter(v3, v3.begin()));
cout<<"[after sort]v3 = ";
for_each(v3.begin(),v3.end(),[](std::string item){
cout<<item<<" ";
});
cout<<endl;
------输出
v1 = 1111 mmmm 2222 ffff tttt 4444
v2 = gggg hhhh 4444
[before sort]v3 = 1111 mmmm 2222 ffff tttt 4444
[after sort]v3 = 1111 2222 ffff mmmm tttt
13.标准输入重定向
#include
12.结构体用memset进行初始化
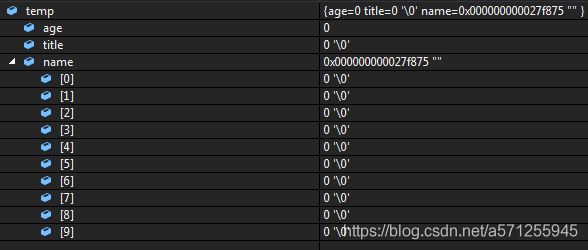
typedef struct Person
{
int age;
char title;
char name[10];
Person(){
memset(this, 0, sizeof(*this));
}
};
int main()
{
Person temp;
cout << "age = " << temp.age << " , title = " << temp.title << " ,name = " << temp.name << endl;
system("pause");
return 0;
}
*可以看到在结构的构造函数总调用 memset(this, 0, sizeof(this)); 可以对整个结构体进行初始
11.memset 只能按字节进行初始化
只能将其用来初始化,而不是将其拿来赋具体的值,因为memset是按照字节来进行初始化的


测试代码1.
//memset只能按字节进行初始化
int* p = (int *)malloc(10 * sizeof(int));
int* p2 = nullptr;
memset(p, 1, 10 * sizeof(int));
//cout << "sizeof(p) = " << sizeof(p) << endl;//8 sizeof(指针)求出的只是指针的大小
//cout << "sizeof(p2) = " << sizeof(p2) << endl;//8 64位程序所以指针占8个字节
//memset(p, 1, sizeof(p));
for (int i = 0; i < 10;i++)
{
printf("地址:0x%x 值:0x%x\n", p + i, *(p + i));
}
/*
地址:0x3ccba0 值:0x1010101
地址:0x3ccba4 值:0x1010101
地址:0x3ccba8 值:0x1010101
地址:0x3ccbac 值:0x1010101
地址:0x3ccbb0 值:0x1010101
地址:0x3ccbb4 值:0x1010101
地址:0x3ccbb8 值:0x1010101
地址:0x3ccbbc 值:0x1010101
地址:0x3ccbc0 值:0x1010101
地址:0x3ccbc4 值:0x1010101
*/
10.std::move()
其实对于 std::move来说,只做了一件事。可以初步的理解为 (不过当然是错误的)
template<typename T>
T&& move(T& val)
{
return static_cast<T&&>(val);
}
move 只是纯粹的将一个左值转化为了一个右值,STL实现基本都已经实现了移动语义,相当于对于 vector::push_back()有两个版本的实现,简单写如下:
template<typename T>
class Vector
{
void push_back(T& lval);
void push_back(T&& rval);
};
而对应的类型 T 也实现了移动拷贝,如下:
class T
{
T(T& other)
{
// copy constructor
}
T(T&& other)
{
// move constructor
}
};
move减少不必要的拷贝,代码有性能提升
原文链接:https://blog.csdn.net/coolwriter/article/details/80970718
9.std::forward()
参考:https://blog.csdn.net/coolwriter/article/details/80970718
当我们将一个右值引用传入函数时,他在实参中有了命名,所以继续往下传或者调用其他函数时,根据C++ 标准的定义,这个参数变成了一个左值。那么他永远不会调用接下来函数的右值版本,这可能在一些情况下造成拷贝。为了解决这个问题 C++ 11引入了完美转发,根据右值判断的推倒,调用forward 传出的值,若原来是一个右值,那么他转出来就是一个右值,否则为一个左值。
这样的处理就完美的转发了原有参数的左右值属性,不会造成一些不必要的拷贝。代码如下:
#include
右值引用类型是独立于值的,一个右值引用参数作为函数的形参,在函数内部再转发该参数的时候它已经变成一个左值,并不是他原来的类型。
如果我们需要一种方法能够按照参数原来的类型转发到另一个函数,这种转发类型称为完美转发。
#include
官方解释:
(1)转发左值为左值或右值,依赖于 T
当 t 是转发引用(作为到无 cv 限定函数模板形参的右值引用的函数实参),此重载将参数以在传递给调用方函数时的值类别转发给另一个函数。
例如,若用于如下的包装器,则模板表现为下方所描述:
template<class T>
void wrapper(T&& arg)
{
// arg 始终是左值
foo(std::forward<T>(arg)); // 转发为左值或右值,依赖于 T
}
(2) 转发右值为右值并禁止右值的转发为左值
此重载令转发表达式(如函数调用)的结果可行,结果可以是右值或左值,同转发引用参数的原始值类别。
例如,若包装器不仅转发其参数,还在参数上调用成员函数,并转发其结果:
// 转换包装器
template<class T>
void wrapper(T&& arg)
{
foo(forward<decltype(forward<T>(arg).get())>(forward<T>(arg).get()));
}
其中 arg 的类型可以是
struct Arg
{
int i = 1;
int get() && { return i; } // 此重载的调用为右值
int& get() & { return i; } // 此重载的调用为左值
};
试图转发右值为左值,例如通过以左值引用类型 T 实例化形式 (2) ,会产生编译时错误。也就是说要想规则(2)有效,void wrapper(T&& arg)中的&& 不能是 &
8.lock_guard,unique_lock,scoped_lock 与各种锁(待补充)
连接
7.composition(组合/复合) aggregation(聚合) association(关联/联系)
这三者的关系总是搞不清楚,容易忘记,**陈硕**中有一段解释的比较清楚,这里总结记录下.
概括下:
组合 —>实例成员
关联 —> 指针/引用成员
聚合 —> 指针/引用成员 ,但比关联在逻辑上多了一层整体与部分的关系
composition(组合/复合) :在代码上体现为类的成员变量,而且成员变量是实例类型,不是指针或引用类型.这种关系在多线程里不会有什么麻烦,因为对象的x的生命周期由唯一的拥有者owner控制.
association(关联/联系):关联/联系是一种宽泛的关系,表示一个对象a用到了另一个对象b,调用了后者的成员函数.从代码形式上看,a持有b的指针或引用,但b的生命周期不受a单独控制
aggregation(聚合):聚合关系和关联关系从形式上看相同,即a持有b的指针或引用,但b的生命周期不受a单独控制,特殊之处在于a和b在逻辑上有整体和部分的关系
6.sizeof与数组
详细说明见代码中注释
#include
5.字节对齐(结构体与sizeof)
内存对齐:编译器将程序中的每个“数据单元”安排在字的整数倍的地址指向的内存之中
内存对齐的原则:
- 结构体变量的首地址能够被其最宽基本类型成员大小与对齐基数中的较小者所整除;
- 结构体每个成员相对于结构体首地址的偏移量 (offset)都是该成员大小与对齐基数中的较小者的整数倍,如有需要编译器会在成员之间加上填充字节 (internal padding);
- 结构体的总大小为结构体最宽基本类型成员大小与对齐基数中的较小者的整数倍,如有需要编译器会在最末一个成员之后加上填充字节 (trailing padding)
/*
说明:程序是在 64 位编译器下测试的
*/
#include
可以看到以适当的方式排列结构体中的变量确实能减小空间占用,尽量短的类型放在后面,大的类型放在前面
4.sizeof与类
详见代码中的注释
#if 1
#include
3.大小端(经常忘记)

2. sizeof与strlen的区别
Demo1
概括:
sizeof();//计算整个字符数组所占空间的大小
strlen();//计算的是字符串的长度
顺带注意‘0’与‘\0’,0的区别
作为字符串结束符‘\0’和数字0是等价的,而‘0’是0字符不是字符串结束符
#if 1
#include
Demo2
概括:
sizeof求的是空间大小,‘\0’占用空间了自然要算它的大小;
strlen求的是字符串的长度,字符串当然不包含最后的字符串结束符,所以就不算在长度之内了
#if 1
#include
1、c风格字符串记得以‘\0’(或直接写作0)结尾(注意不能是‘0’)
#include