basic_vsr 代码介绍
文章目录
-
-
- 1. basic_vsr使用的一些模块介绍:
- 2. basic_vsr网络结构
- 3网络参数打印
- 4. basic_vsr的数据预处理操作
- 5. basic_vsr 推理结果:
-
本文参考basic_vsr code : github code
1. basic_vsr使用的一些模块介绍:
# 1)一个光流预测的网络,预测相邻两帧的 flow
class SPyNet(nn.Module):
# 2)将图像和feature warp到另一帧的视角
def flow_warp(x,
flow,
interpolation='bilinear',
padding_mode='zeros',
align_corners=True)
# 3)链接若干个(30个)ResidualBlockNoBN子网络形成一个比较大的网络
# 用于帧间的前向,后向信息传播
class ResidualBlocksWithInputConv(nn.Module):
class ResidualBlockNoBN(nn.Module):
"""Residual block without BN.
It has a style of:
::
---Conv-ReLU-Conv-+-
|________________|
"""
# 4)PixelShuffle模块,一个用于超分的比较常见的模块
class PixelShuffle(nn.Module):
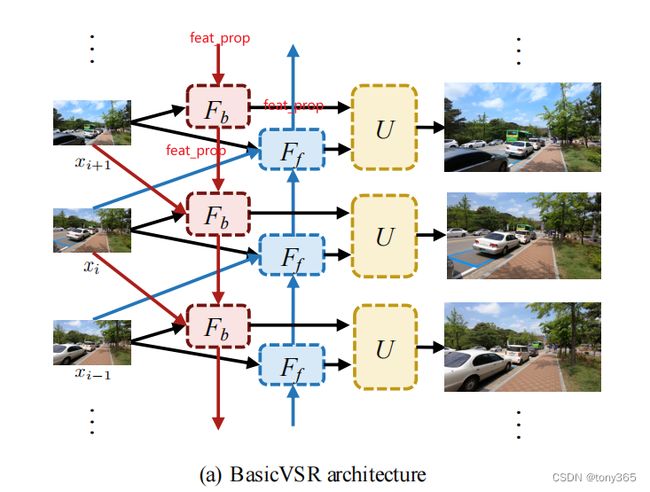
2. basic_vsr网络结构
结合代码和图片一起分析
下图中Fb和Ff 在代码中是backward-time propgation 和 forkward-time propgation
然后后向传递中 feat_prop 和 x(i+1) cat后,进入backward_resblocks网络,输出的feature
向前一帧图像传递,也向U传递,U主要包括 fusion ,conv, upscale 操作。
def forward(self, lrs):
"""Forward function for BasicVSR.
Args:
lrs (Tensor): Input LR sequence with shape (n, t, c, h, w).
Returns:
Tensor: Output HR sequence with shape (n, t, c, 4h, 4w).(if scale_factor=4)
"""
n, t, c, h, w = lrs.size()
assert h >= 64 and w >= 64, (
'The height and width of inputs should be at least 64, '
f'but got {h} and {w}.')
# check whether the input is an extended sequence
self.check_if_mirror_extended(lrs)
# compute optical flow
flows_forward, flows_backward = self.compute_flow(lrs) # (n, t - 1, 2, h, w)
# backward-time propgation
outputs = []
feat_prop = lrs.new_zeros(n, self.mid_channels, h, w)
for i in range(t - 1, -1, -1):
if i < t - 1: # no warping required for the last timestep
flow = flows_backward[:, i, :, :, :]
feat_prop = flow_warp(feat_prop, flow.permute(0, 2, 3, 1))
feat_prop = torch.cat([lrs[:, i, :, :, :], feat_prop], dim=1) # cat t image and warped t+1 image(default 0)
feat_prop = self.backward_resblocks(feat_prop)
outputs.append(feat_prop)
outputs = outputs[::-1]
# forward-time propagation and upsampling
feat_prop = torch.zeros_like(feat_prop)
for i in range(0, t): # 对于每个图像操作
lr_curr = lrs[:, i, :, :, :]
if i > 0: # no warping required for the first timestep
if flows_forward is not None:
flow = flows_forward[:, i - 1, :, :, :]
else:
flow = flows_backward[:, -i, :, :, :]
feat_prop = flow_warp(feat_prop, flow.permute(0, 2, 3, 1))
feat_prop = torch.cat([lr_curr, feat_prop], dim=1)
feat_prop = self.forward_resblocks(feat_prop)
# 连接每个图像的前向和后向 特征
# upsampling given the backward and forward features
out = torch.cat([outputs[i], feat_prop], dim=1)
out = self.lrelu(self.fusion(out))
out = self.lrelu(self.upsample1(out))
out = self.lrelu(self.upsample2(out))
out = self.lrelu(self.conv_hr(out))
out = self.conv_last(out)
base = self.img_upsample(lr_curr)
out += base
outputs[i] = out
return torch.stack(outputs, dim=1)
3网络参数打印
参考blog
if __name__ == "__main__":
from torch import nn
import torch
from torchviz import make_dot
import tensorwatch as tw
from torchinfo import summary
import netron
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
modelviz = basicVSR().to(device)
# 打印模型的组成
print(modelviz)
summary(modelviz, input_size=(2, 3, 3, 128, 128), col_names=["kernel_size", "output_size", "num_params", "mult_adds"])
# for name, para in modelviz.named_parameters():
# print(name, ' ', para.shape)
# 1. 使用 torchviz 可视化
if 0:
print('**************1. 使用 torchviz 可视化***********')
input = torch.rand(1, 3, 3, 128, 128).to(device)
out = modelviz(input)
print(out.shape)
g = make_dot(out)
g.view() # 直接在当前路径下保存 pdf 并打开
# 2. 保存成pt文件后进行可视化
torch.save(modelviz, "modelviz.pt")
modelData = 'modelviz.pt'
netron.start(modelData)
# 3. 使用tensorwatch可视化
print(tw.model_stats(modelviz, [1, 3, 3, 128, 128]))
tw.draw_model(modelviz, input)
4. basic_vsr的数据预处理操作
对于视频模型来说,网络的输入一般是多帧,因此在处理的时候比 图像类模型 稍显复杂
-
对于视频序列所有的图像进行转换,比如resize
def resize_sequences(sequences,target_size): """resize sequence Args: sequences (Tensor): input sequence with shape (n, t, c, h, w) target_size (tuple): the size of output sequence with shape (H, W) Returns: Tensor: Output sequences with shape (n, t, c, H, W) """ seq_list=[] for sequence in sequences: # n # t img_list=[T.Resize(target_size, interpolation=T.InterpolationMode.BICUBIC)(lq_image) for lq_image in sequence] seq_list.append(torch.stack(img_list)) return torch.stack(seq_list) -
crop 和 翻转
def pair_random_crop_seq(hr_seq,lr_seq,patch_size,scale_factor=4):
"""crop image pair for data augment
Args:
hr (Tensor): hr images with shape (t, c, 4h, 4w).
lr (Tensor): lr images with shape (t, c, h, w).
patch_size (int): the size of cropped image
Returns:
Tensor, Tensor: cropped images(hr,lr)
"""
seq_lenght=lr_seq.size(dim=0)
gt_transformed=torch.empty(seq_lenght,3,patch_size*scale_factor,patch_size*scale_factor)
lq_transformed=torch.empty(seq_lenght,3,patch_size,patch_size)
i,j,h,w=T.RandomCrop.get_params(lr_seq[0],output_size=(patch_size,patch_size))
gt_transformed=T.functional.crop(hr_seq,i*scale_factor,j*scale_factor,h*scale_factor,w*scale_factor)
lq_transformed=T.functional.crop(lr_seq,i,j,h,w)
return gt_transformed,lq_transformed
def pair_random_flip_seq(sequence1,sequence2,p=0.5,horizontal=True,vertical=True):
"""flip image pair for data augment
Args:
sequence1 (Tensor): images with shape (t, c, h, w).
sequence2 (Tensor): images with shape (t, c, h, w).
p (float): probability of the image being flipped.
Default: 0.5
horizontal (bool): Store `False` when don't flip horizontal
Default: `True`.
vertical (bool): Store `False` when don't flip vertical
Default: `True`.
Returns:
Tensor, Tensor: cropped images
"""
T_length=sequence1.size(dim=0)
# Random horizontal flipping
hfliped1=sequence1.clone()
hfliped2=sequence2.clone()
if horizontal and random.random() > 0.5:
hfliped1 = T.functional.hflip(sequence1)
hfliped2 = T.functional.hflip(sequence2)
# Random vertical flipping
vfliped1=hfliped1.clone()
vfliped2=hfliped2.clone()
if vertical and random.random() > 0.5:
vfliped1 = T.functional.vflip(hfliped1)
vfliped2 = T.functional.vflip(hfliped2)
return vfliped1,vfliped2
def pair_random_transposeHW_seq(sequence1,sequence2,p=0.5):
"""crop image pair for data augment
Args:
sequence1 (Tensor): images with shape (t, c, h, w).
sequence2 (Tensor): images with shape (t, c, h, w).
p (float): probability of the image being cropped.
Default: 0.5
Returns:
Tensor, Tensor: cropped images
"""
T_length=sequence1.size(dim=0)
transformed1=sequence1.clone()
transformed2=sequence2.clone()
if random.random() > 0.5:
transformed1=torch.transpose(sequence1,2,3)
transformed2=torch.transpose(sequence2,2,3)
return transformed1,transformed2
- dataset class
- train sharp 和 val sharp文件夹里共有 240 + 30 = 270 个图像序列,每个图像序列是100张图像,val_keys=[‘000’, ‘011’, ‘015’, ‘020’]是作为验证集的图像序列,其他作为训练集
- 以训练集为例,从其余264个图像序列中选取 第idx序列。 那么self.gt_seq_paths[idx],self.lq_seq_paths[idx]分别表示高分辨率和低分辨率对应的文件夹
- 视频超分的输入是 t,c,h,w 这里t是num_input_frames=10,从第idx序列中随机选取连续10帧一组做为一个样本,得到gt_sequence,lq_sequence
- 测试的时候不进行transform 裁剪等操作
class REDSDataset(Dataset):
"""REDS dataset for video super resolution.
Args:
gt_dir (str): Path to a gt folder.
lq_dir (str): Path to a lq folder.
patch_size (int): the size of training image
Default: 256
is_test (bool): Store `True` when building test dataset.
Default: `False`.
max_keys (int): clip names(make keys '000' to 'max_keys:03d')
Default: 270(make keys '000' to '270')
"""
def __init__(self, gt_dir, lq_dir,scale_factor=4, patch_size=256, num_input_frames=10, is_test=False,max_keys=270,filename_tmpl='{:08d}.png'):
val_keys=['000', '011', '015', '020']
if is_test:
self.keys = [f'{i:03d}' for i in range(0, max_keys) if f'{i:03d}' in val_keys]
else:
self.keys = [f'{i:03d}' for i in range(0, max_keys) if f'{i:03d}' not in val_keys]
self.gt_dir=gt_dir
self.lq_dir=lq_dir
self.scale_factor=scale_factor
self.patch_size=patch_size
self.num_input_frames=num_input_frames
self.is_test=is_test
self.gt_seq_paths=[os.path.join(self.gt_dir,k) for k in self.keys]
self.lq_seq_paths=[os.path.join(self.lq_dir,k) for k in self.keys]
self.filename_tmpl=filename_tmpl
def transform(self,gt_seq,lq_seq):
gt_transformed,lq_transformed=pair_random_crop_seq(gt_seq,lq_seq,patch_size=self.patch_size)
gt_transformed,lq_transformed=pair_random_flip_seq(gt_transformed,lq_transformed,p=0.5)
gt_transformed,lq_transformed=pair_random_transposeHW_seq(gt_transformed,lq_transformed,p=0.5)
return gt_transformed,lq_transformed
def __len__(self):
return len(self.keys)
# train sharp 和 val sharp文件夹里共有 240 + 30 = 270 个图像序列,每个图像序列是100张图像,val_keys=['000', '011', '015', '020']是作为验证集的图像序列,其他作为训练集
# 以训练集为例,从其余264个图像序列中选取 第idx序列。 那么self.gt_seq_paths[idx],self.lq_seq_paths[idx]分别表示高分辨率和低分辨率对应的文件夹
# 视频超分的输入是 t,c,h,w 这里t是num_input_frames=10,从第idx序列中随机选取连续10帧一组做为一个样本,得到gt_sequence,lq_sequence
# 测试的时候不进行transform 裁剪等操作
def __getitem__(self,idx):
gt_sequence, lq_sequence = generate_segment_indices(self.gt_seq_paths[idx],self.lq_seq_paths[idx],num_input_frames=self.num_input_frames,filename_tmpl=self.filename_tmpl)
if not self.is_test:
gt_sequence, lq_sequence = self.transform(gt_sequence,lq_sequence)
return gt_sequence,lq_sequence
5. basic_vsr 推理结果:
import os
from pathlib import Path
import numpy as np
import torch
import torchvision.transforms
from torchvision.io import read_image, read_video, write_png
from model import basicVSR
if __name__ == "__main__":
torch.cuda.empty_cache()
with torch.no_grad():
# 0. get input
# img = read_image("assets/1_1.jpg")
# print(img.size)
device = 'cuda'
from_video = 0
if from_video:
video_file = Path('../../../dataset/video_noise/10/10.avi')
frames, _, meta = read_video(str(video_file))
frames = frames.permute([0, 3, 1, 2])
print(type(frames))
print(frames.shape)
print(meta)
input = frames[10:20, ...].float() / 255
t, c, h, w = input.shape
input = torchvision.transforms.Resize([h // 4, w // 4])(input)
print(input.shape)
else:
# 2 input
dir = Path('/home/ww/dataset/REDS/val_sharp_bicubic/X4/012/')
frames = [read_image(os.path.join(dir, f'{i:08d}.png')) for i in range(10)]
input = torch.stack(frames).float() / 255
t, c, h, w = input.shape
print(input.shape)
dir = Path('/home/ww/dataset/REDS/val_sharp/012/')
frames_gt = [read_image(os.path.join(dir, f'{i:08d}.png')) for i in range(10)]
# 1. init model with pretrained weight
model = basicVSR()
### input = (n, t, c, h, w).
# print("Model's state_dict:") # 打印模型的状态字典
# for param_tensor in model.state_dict():
# print(param_tensor, "\t", model.state_dict()[param_tensor].size())
pretrained = 'basicvsr_300000.pth'
pre_pt = torch.load(pretrained)
# for param_tensor in pre_pt:
# print(param_tensor, type(pre_pt[param_tensor]))
# print("********print parameter*************")
# parameter = pre_pt[param_tensor]
# for param_name in parameter:
# print(param_name, parameter[param_name].shape)
model.load_state_dict(pre_pt, strict=False)
model.to(device)
model.eval()
# print(type(model))
# for param_tensor in model.state_dict():
# print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# 2. preprocess
# 3. apply inference
prediction = model(input.unsqueeze(0).cuda()).squeeze(0)
print(prediction.shape)
pred = torch.clamp(prediction.cpu(),0,1) * 255 #.detach().numpy()
pred = pred.byte()
for i in range(len(pred)):
write_png(pred[i], f'd{i:3d}_10.png')
inp = torch.clamp(input.cpu(), 0 , 1)*255 #.detach().numpy()
inp = inp.byte()
for i in range(len(inp)):
write_png(inp[i], f'd{i:3d}input_10.png')
write_png(frames_gt[i], f'd{i:3d}inputH_10.png')
左中右,分别是 模型输出,lr, hr gt
可以看出 1是模型输出比较模糊,2是颜色发生了变化
效果不好, 不知道什么原因
