图像检索|经典论文阅读|快速入门|综述学习
大家好,这里是【来一块葱花饼】,这次带来了图像检索综述的技术学习,欢迎关注,与你分享~
本文主要参考总数论文《Deep Learning for Instance Retrieval: A Survey》(2022年更新过,主要内容来自于2020年)
感兴趣的同学,也可以先看看我的另一篇笔记,对图像检索研究做了一个评估,图像检索|经典方法|快速入门|综述
文章目录
-
- Abstract
- 1 INTRODUCTION
-
- 1.1 Summary of Progress since 2012
- 1.2 Key Challenges
- 2 GENERAL FRAMEWORK OF IIR
- 3 POPULAR BACKBONE DCNN ARCHITECTURES
- 4 RETRIEVAL WITH OFF-THE-SHELF DCNN MODELS
-
- 4.1 Deep Feature Extraction
-
- 4.1.1 Network Feedforward Scheme
- 4.1.2 Deep Feature Selection
- 4.1.3 Feature Fusion Strategies
- 4.2 Feature Embedding and Aggregation
-
- 4.2.1 Matching with Global Features
- 4.2.2 Matching with Local Features
- 4.2.3 Attention Mechanism
- 4.2.4 Hashing Embedding
- 5 RETRIEVAL VIA LEARNING DCNN REPRESENTATIONS
-
- 5.1 Supervised Fine-tuning
-
- 5.1.1 Fine-tuning via Classification Loss
- 5.1.2 Fine-tuning via Pairwise Ranking Loss
- 5.1.3 Discussion
- 5.2 Unsupervised Fine-tuning
-
- 5.2.1 Mining Samples with Manifold Learning
- 5.2.2 Mining Samples by Clustering
- 6 STATE OF THE ART PERFORMANCE
-
- 6.1 Datasets
- 6.2 Evaluation Metrics
- 6.3 Performance Comparison and Analysis
- 7 CONCLUSIONS AND FUTURE DIRECTIONS
Abstract
随着图片数据量的增大,也给数据处理带来了新的挑战,特别是在数据库中搜索类似的内容——基于内容的图像检索(CBIR)——一个长期建立的内容实时检索需要提高效率和准确性的研究领域。
在本综述中,我们回顾了最近基于深度学习算法和技术开发的实例检索工作,以及由深度网络架构类型、深度特征、特征嵌入和聚合方法,以及网络微调策略。最后提出了常用的基准、评价结果、常见的挑战,并提出了很有前途的未来发展方向。
1 INTRODUCTION
基于内容的图像检索(CBIR)是通过分析视觉内容(颜色、纹理、形状、物体等),在图库中搜索相关图像的问题。CBIR一直是计算机视觉和多媒体等领域的长期研究课题。随着图像数据的指数级增长,适当的信息的发展有效地管理如此大的图像集合的系统是至关重要的,而图像搜索是最不可或缺的技术之一。因此,有一个几乎无穷无尽的潜力CBIR的应用,如人/车辆再识别、地标检索、遥感、医学图像搜索、在线产品搜索等。
通常,CBIR方法可以分为两个不同的任务:类别级图像检索(CIR)和实例级图像检索(IIR)。CIR的目标是找到一个任意的图像代表与查询相同的类别(例如,狗,汽车)。相比之下,在IIR任务中,一个特定实例(例如,埃菲尔铁塔,我的邻居的狗)的查询图像是giv的我们的目标是找到包含相同实例的图像,可以在不同的条件下被捕获,如不同的成像距离、视角、背景、光照和天气条件(重新识别同一实例的范例)。本次调查的重点是IIR任务。
在过去的二十年里,在图像表示方面取得了惊人的进展,这主要包括特征工程和深度学习这两个重要时期。在功能中在工程时代,该领域主要由各种里程碑式的手工图像表示所主导,如SIFT和视觉文字袋(BoW)。深度学习时代在2012年被重新点燃被称为“AlexNet”(DCNN)的“AlexNet”在ImageNet分类竞赛中以突破性的降低分类错误率获得第一名。从那时起,SIFT如局部描述符的主导作用已经被数据驱动的深度神经网络(DNNs)所取代,它可以直接学习具有多个抽象层次的强大的特征表示从数据。
鉴于这一快速发展的时期,本文的目标是提供在IIR最近的成就的一个全面的调查。与现有的对传统形象的优秀调查相比较检索,如表1所示,我们在本文中的重点是回顾基于深度学习的IIR方法,特别是在检索精度和效率的问题上。
1.1 Summary of Progress since 2012
四个网络级和特征级的视角,构成了本次调查的基础:
Improvements in Network Architectures
Deep Feature Extraction
Feature Embedding and Aggregation
Network Fine-tuning for Learning Representations
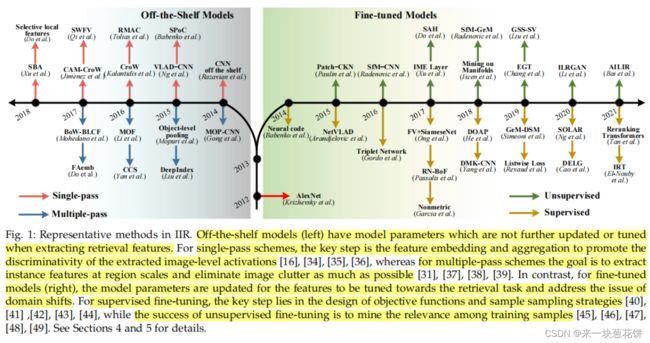
1.2 Key Challenges
虽然在实现准确性和效率方面取得了重大进展,但这两个相互竞争的目标仍然面临挑战。
2 GENERAL FRAMEWORK OF IIR
我们在图2中总结了一个基于深度学习的IIR的一般框架,包括四个主要阶段。
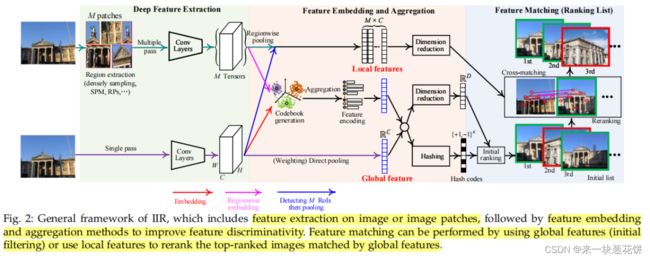
Network feedforward scheme
Deep feature extraction
Feature embedding and aggregation
Feature matching
IIR的前四个阶段(从输入数据到输出排名列表)依赖于使用dcnn作为主干架构。
3 POPULAR BACKBONE DCNN ARCHITECTURES
对于IIR,有四种网络模型作为特征提取的基础:AlexNet、VGG、谷歌LeNet和ResNet。
4 RETRIEVAL WITH OFF-THE-SHELF DCNN MODELS
(现成的深度学习模型)
这种方法有局限性,最基本的是在任务之间存在模型转移或域转移挑战,这意味着经过分类训练的模型,我们必须提取出非常适合于图像检索的特征。特别是,只要特征保持在分类边界内,分类决策是可以成功的这些模型可能显示出足够的检索能力,因为特征匹配本身比分类更重要。本节将调查已制定的战略提高特征表示的质量,特别是基于特征提取/融合和特征嵌入/聚合。
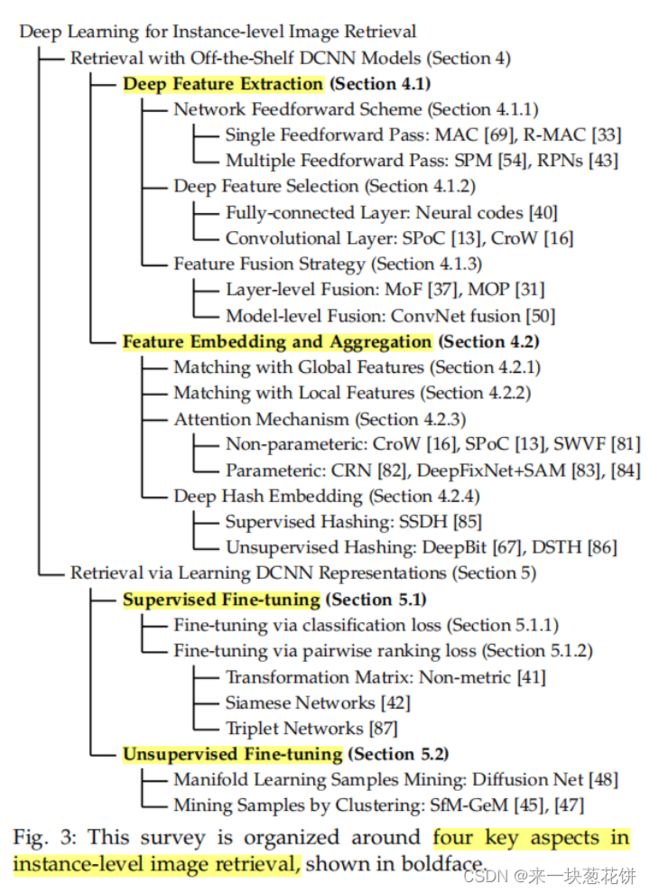
4.1 Deep Feature Extraction
特征提取的主要问题是从非dcnn中提取检索特征的机制,主要涉及三个方面:网络前馈方案、特征选择和特征融合。
4.1.1 Network Feedforward Scheme

网络前馈方案关注于如何将图像输入一个DCNN,其中包括单通和多通。
单前馈传递方法( Single Feedforward Pass Methods)。将整个图像提取出来,并将其输入到一个现成的模型中,以提取特征。该方法相对有效,因为输入图像只被输入一次。这些方法中,全连接层和最后一个卷积层都可以作为特征提取器。
多通前馈传递方法( Multiple Feedforward Pass Methods)。单通方案相比,多通方法更耗时,因为会生成几个补丁,然后被聚合到网络中。这些表示通常由两个阶段产生:补丁检测和补丁描述。使用滑动窗口或空间金字塔获得多尺度图像补丁中间模型(SPM),如图4所示。例如,Zheng等人使用SPM对图像进行分割,并提取特征,从而实现全局的集成l、区域、本地的上下文信息
4.1.2 Deep Feature Selection
特征选择决定了所提取的特征的接受域,即来自全连接层的全局层和来自卷积层的区域层。
从全连接的图层中提取。选择一个完全连接的层作为全局特征提取器,是很简单的。通过PCA降维和归一化,可以测量图像相似度。该层是完全连接的,每个神经元产生图像级描述符,但这导致了IIR的两个明显的限制:包括不相关的信息,和缺乏局部几何不变性。
从卷积的图层中提取。来自卷积层(通常是最后一层)的特征保留了更多的结构细节,这对于例如检索特别有益。卷积层中的神经元只检测到一个局部区域,这个较小的接受域确保了产生的特征保留了更多的局部结构信息,并且对图像转换更鲁棒。许多图像检索方法都使用卷积层作为特征提取器

4.1.3 Feature Fusion Strategies
融合研究了不同特征的互补性,包括层级和模型级的融合探索。
Layer-level Fusion。考虑到哪层组合的差异和互补性,哪些层组合更有利于融合值得考虑。
Model-level Fusion。可以结合来自不同模型的特征;这种融合更注重模型的互补性,将方法分为模型内和模型间。模型内融合提示具有相似或高度兼容的结构的多个深度模型,而模型间的融合涉及到具有不同结构的模型。
4.2 Feature Embedding and Aggregation
特征嵌入和聚合的主要目的是进一步提高从dcnn中提取的特征的鉴别性,以获得最终的全局和/或局部特征来检索特定的实例。
4.2.1 Matching with Global Features
卷积特征可以解释为局部区域的描述符,因此许多工作利用嵌入方法,包括BoW、VLAD和FV,来编码区域特征向量,然后编码agg将它们(例如,简单地通过和操作)调整为全局描述符。
传统上,基于池化的聚合方法(例如,在图5中)是直接插入到深度网络中,然后从端到端使用整个模型。三种嵌入方法(BoW、VLAD、FV)a最初使用大型预定义词汇表重新训练
4.2.2 Matching with Local Features
局部特征的一个重要方面是检测图像中实例的关键点,然后将检测到的关键点描述为一组局部描述符。IIR整个过程的策略可以分类为检测然后描述和描述然后检测。
使用本地描述符来执行实例检索任务有两个限制。首先,图像的本地描述符是单独和独立地存储的,这是内存密集型的,而不是非常适合于大规模的场景。其次,估计查询图像和数据库图像之间的相似性依赖于所有局部描述符对的交叉匹配,这将导致额外的搜索代价因此,大多数使用本地特性的实例检索系统遵循两个阶段的范例:初始过滤和重新排序,如图2所示。初始滤波器阶段是使用一个全局描述符来选择一组候选匹配图像,从而减少解空间;重新排序阶段是使用局部描述符对排名最高的进行重新排序。
4.2.3 Attention Mechanism
注意机制可以看作是一种特征聚合,其核心思想是突出最相关的特征部分,通过计算注意图来实现。获取方法注意图可以分为非参数图两组和非参数图两类,如图6所示,其中最主要的区别是注意图中的重要性权重是否可学习。
4.2.4 Hashing Embedding
由于其计算和存储效率,哈希算法已被广泛应用于全局和局部描述符。在哈希函数训练过程中,将原始相似图像的哈希码尽可能紧密地嵌入,并将不同图像的哈希码尽可能地分离。
5 RETRIEVAL VIA LEARNING DCNN REPRESENTATIONS
微调方法已被广泛研究,以学习更好的检索特征。DCNNs预先培训,用图像分类的源数据集对类间变异性具有相当的鲁棒性,随后将成对监督信息纳入规则微调网络的排序损失中。经过网络微调后,可以将特性组织为全局或局部来执行检索。
5.1 Supervised Fine-tuning

5.1.1 Fine-tuning via Classification Loss
然后,通过根据交叉熵损失优化DCNN的参数,可以对DCNN进行微调,如图7(a)所示。经过微调的网络在与地标相关的数据集上产生了优越的特征。交叉熵损失可以最小化类内距离,同时最大限度的类间距离。交叉熵损失本质上是使检索特征和gt之间的共同互信息最大化
5.1.2 Fine-tuning via Pairwise Ranking Loss
成对排名损失学习一个最优度量,最小化或最大化对应图像对的距离,以保持它们的相似性。
Fine-tuning with Siamese Networks.simese损失最近被重申为类别级图像检索中的一个非常有效的度量标准,如果仔细执行,其表现将超过许多更复杂的损失
使用三重网络进行微调。三重态网络同时优化相似的对和不同的对。
5.1.3 Discussion
在某些情况下,成对排序损失不能有效地学习样本之间的变化,如果训练集没有正确排序,它的泛化能力仍然较弱。钍因此,成对排序损失需要仔细的样本挖掘和加权策略,以获得信息最丰富的训练对,特别是在考虑小批次时。
hard negative mining strategy通常使用,但最近发展了进一步复杂的mining策略。有文章,计算了所有小批处理上的成对距离矩阵样本选择两个最接近的负对和一个锚正对形成一个三联体进行微调。与其遍历所有可能的二元组或三元组组合,还可以合并r所有阳性样本在一个簇中,另一个阴性样本。
当在细粒度的分类级别检索任务上仔细调整时,交叉熵损失可以匹配甚至超过成对的排名损失。
5.2 Unsupervised Fine-tuning
对图像检索的无监督微调方法是非常必要的,但相关研究较少。对于无监督的微调,有两个方向:1.通过流形学习来挖掘特征之间的相关性;2.通过聚类技术。下面将讨论。
5.2.1 Mining Samples with Manifold Learning
流形学习侧重于捕获流形结构上的内在相关性,以挖掘或推断出启示性,如图9所示。所提取的全局特征之间的初始相似性利用全局或局部特征构造亲和矩阵,然后使用流形学习对其进行重新评估和更新。
捕捉深层特征流形的几何形状是很重要的,通常涉及两步,称为扩散。首先,亲和矩阵(图9)被解释为一个加权的k神经网络图,其中每个向量由一个节点表示,边由两个连接节点的成对亲和度定义。然后,在所有其他因素的情况下重新评估成对的亲和关系元素通过扩散的相似性值通过图

5.2.2 Mining Samples by Clustering
聚类方法用于探索在实例级图像检索中研究过的接近度信息。这些方法背后的基本原理是,样本在一个cluster很可能满足一定程度的相似性。
其中一类进行深度特征聚类的方法是通过kmeans。
knn方法。微调是通过最小化每个查询特征与其k个最近特征的平均值之间的平方距离来执行的。
还有进一步的技术,例如检索,例如使用自动编码器,生成对抗网络(GANs),卷积核网络,和图con体积网络。对于这些方法,他们专注于设计新的无监督框架来实现无监督学习,而不是在f上进行迭代相似度扩散或聚类细化特性空间。
6 STATE OF THE ART PERFORMANCE
6.1 Datasets
UKBench(UKB)由10,200张物体图像组成。该数据集有2550组图像,每组有4张来自不同视点或光照条件下的同一对象的图像s.所有的图像都可以用作查询。
Holidays包括从个人假日专辑中收集的1491张图片。大多数图像都与场景相关。该数据集包括500组相似的图像每个组都有一个查询图像。
Oxford-5k由11张牛津建筑的5062张图像组成。每个建筑都与五个手绘的边界框查询相关联。另一个不连接添加100,000张干扰物图像Oxford-105k。
Paris-6k包括6412张图像,按建筑结构分为12组。图像用相同类型的l进行了标注在牛津使用的标签-5k。最近,在牛津-5k和巴黎-6k中添加了额外的查询和干扰图像,产生了重访牛津(罗克斯福德)和重访巴黎(RParis)数据ets。我们还在硬评估协议下对这些重新访问的数据集进行了部分比较。INSTRE[151]由来自250个不同对象类的28,543张图像组成,其中包括three不相交子集2:INSTRE-S1、INSTRE-S2、INSTRE-M。
谷歌地标数据集(GLD),由GLDv1和GLD-v2组成。图像的数量GLD-v1中的Es会随着时间的推移而缩小,因为这些图像可能会被删除。GLD-v2具有稳定性的优势,所有图像都有许可许可。GLD-v2由超过500万张图像和超过20万k天的图像组成插入实例标签,使其成为迄今为止最大的实例识别数据集。它被分为三个子集:(i)118k个带有地面真相注释的查询图像,(ii)4.1M个的训练图像203k地标带标签,(iii)101k地标的762k索引图像。通过去除杂波来进一步清理训练集,其中包括一个包含1.6M张81k图像的子集“GLD-v2-clean”陆标
6.2 Evaluation Metrics
平均精度(AP)是指精度-召回率(PR)曲线下的覆盖面积
对所有查询图像的评价均采用平均平均精度(mAP)
N-S分数是UKBench的度量;N-S分数是数据集上前4的精度的平均值。
6.3 Performance Comparison and Analysis

图10总结了从2014年到2020年的6个数据集的性能。早期,dcnn的强大特征提取导致了快速的改进。随后的关键思想是提取实例e区域级特征,减少图像杂波,并采用特征融合、特征聚合等方法提高特征判别性特征嵌入。微调是通过调优特定于学习实例特性的深度网络来提高性能的一个重要策略
对单次前馈通过的评估。可以提高增强特征辨别能力,改善效果。
对多次前馈通过的评估。本文报告了图4中的方法的结果。其中,使用过度密集提取图像补丁在4个数据上性能最高设置,刚性网格具有竞争力(巴黎-6k的mAP为87.2%)。这两种方法用于特征提取时,考虑更多的补丁,甚至背景信息。而不是生成斑块密集、区域建议和空间金字塔建模在图像对象中引入了一定的目的和效率。使用多路s可以更好地维护空间信息化学物质比一次性使用。
对有监督的微调的评估。与现成的模型相比,对深度网络进行微调通常会提高精度,见表3。例如,牛ford-5k使用预tra的结果当使用单边际暹罗损失时,的预期VGG从66.9%提高到81.5%。在巴黎-6k数据集上也可以观察到类似的趋势。对于基于分类的微调,它的性能通过使用强大的dcnn和注意机制等特征增强方法,可以提高规则性。
对无监督的微调的评估。与有监督的微调相比,无监督的微调方法的探索相对较少。无监督微调的困难是挖掘采样没有“真实的标签的相关性。一般来说,无监督的微调方法的性能应该被预期为低于有监督的微调方法。对不同的数据集进行微调可能会产生不同的最终检索性能。
更深的网络由于提取更多的鉴别特征,始终带来更好的精度。
聚合相同的现成DCNN的不同方法会导致检索性能的差异。
高维特征通常捕获更多的语义,并有助于检索。
全局特征维度和区域搜索,更多的背景或无关区域也被提取并用于交叉匹配(即多对多匹配),并对性能产生负面影响。
利用全局特征,在初始过滤步骤后,重新排序进一步提高了检索精度。

7 CONCLUSIONS AND FUTURE DIRECTIONS
在本综述中,我们回顾了深度学习方法的检索分类,确定了里程碑方法,揭示了各种方法之间的联系,使性能比较提出了具有代表性的方法,并讨论了其优点和局限性。很明显,深度学习在IIR方面已经取得了显著的进展,但仍有许多问题尚未解决。下面列出了一些潜在的未来研究方向:
(1)大规模实例检索。虽然IIR领域进展迅速,但大多数SOTA方法都是在实例类别有限的非常小的数据集上进行测试的。
(2)专门化和通用实例检索。当然,人们对地标检索、行人检索等专门的实例检索、车辆检索越来越感兴趣
(3)不变的特征表示。实例检索的主要挑战之一是大的类内可性,包括观点、尺度、光照、天气条件的变化背景杂波等
(4)增量图像检索。一个方向是通过增量学习方法建立一个最新的检索模型来处理新实例的连续流
(5)对抗性健壮性。在图像检索领域,图像检索的对抗性鲁棒性受到的关注非常有限,未来值得更多的关注。
另外,还有一篇很好的综述:SIFT Meets CNN:A Decade Survey of Instance Retrieval–2017年发表
码字不易,都看到这里了不如点个赞哦~
这里是【来一块葱花饼】,你的点赞+收藏+关注,就是我坚持下去的最大动力~
