[003]python数据类型一__python_全栈基础
您好!此笔记的文本和代码以网盘形式分享于文末!
因个人能力有限,错误处欢迎大家交流和指正!基础部分内容简单,但多且零散!
一、Python的应用方向及其领域概览(时间仓促,部分举例错误请指正)
| 序号 | 应用方向 | 举例 |
| 1 | 系统编程 | yum apt-get Supervisor等系统工具 |
| 2 | 软件开发工具 | Spinnaker产品快速且持续部署云平台、等 |
| 3 | 软件开发 | zope:Web应用服务器、TKinter 、wxPython、PyQt5功能强大复杂、Kivy移动端跨平台、DevOps |
| 4 | 网络编程 | Twisted高并发、asyncio异步编程、等 |
| 5 | 网络爬虫 | Scrapy、Request、BeautifuSoap、urllib、PySpider、Grab、Cola、等 |
| 6 | WEB开发 | Django-MTV架构、Tornado异步高并发、flask短小精悍、withdeadlines完全主义高效率、等 |
| 7 | 人工智能 | PyTorch、TensorFlow、Theano、Apollo、Spark Mllib、Scikit Learn、Gensim、Pylearn2、Nilearn、Pymc、PyBrain、Fuel、Keras、MxNet等 |
| 8 | 大数据 科学计算 云计算 金融方向 |
NumPy、SciPy数据处理,Mayavi、 matplotlib、pyecharts数据可视化,pandas、Jupyter Notebook数据分析流,Enthought、librarys模块、Spark、Dash、PyODPS、OpenStack、CloudStack、Biopython、sunpy、talib、PyQL、pyfin、vollib、QuantPy、Finance-Python、pynance、tia、BigQuant、easytrader等等 |
| 9 | 系统运维 | psutil、Ipy、dnspython、difflib、pycurl、rrdtool、pyClamad、pexpect、paramiko、fabric、playbook、saltstack等 |
| 10 | 多媒体 | PIL、Piddle、ReportLab图像声音视频动画;pyOpenGL三维场景、RTGraph3D等 |
| 11 | 企业和网站 | odoo、ERP、 CRM、CMDB等 |
| 12 | 自动化测试 | Selenium、requests、Robot Framework、RedwoodHQ、Jasmine、Pytest、unittest、nose、doctest、mock unittest |
| 13 | 信息安全 | Network、Paimei、Capstone、Sulley、Requests、Volatulity、pyew、peepdf、Exomind等等 |
| 14 | 游戏开发 | Panda3D、PyOgre、RenPy、cocos2d、Pygame、Blender、Soya 3D、KlayGE、游戏《文明》《战地2》等 |
| 15 | 硬件编程 | 树莓派、MicroPython、PYNQ、pyMagic等 |
| 16 | 公司与网站 | Instagram图片视频分享、YouTube视频网站、google网络搜索系统、CIA网站、Irobot商业真空吸尘器、NSA加密和智能分析、IronPor邮件服务器、Infoseek公用搜索引擎、Bittorrent P2P文件分享系统、豆瓣、知乎、果壳、Quora、NASA、Dropbox、春雨医生、Reddit、EVE、Digg等等 |
| 二、Python语言发展与特点 | |||||
| Python | 于1991年发布的一种计算机程序设计语言。 | ||||
| Python设计哲学 | “EIBTI”:>>import this; 简单、优雅、明确。 | ||||
| 优点 | 缺点 | 喏!栗子~_~ | |||
| 语言分类 | *面向对象 | 定义 | 采用基于对象(实体)的概念建立模型,模拟客观世界分析、设计、实现软件的办法,面向对象方法的基础实现中也包含面向过程思想; 特性:抽象 封装 继承 多态 |
Python、C++、 JAVA、Ruby |
|
| 1>易维护、易复用、易扩展, 2>有封装、继承、多态性的特性,可设计出低耦合的系统,使系统更加灵活、更加易于维护 |
1>性能比面向过程低 | ||||
| 面向过程 | 定义 | 一种以过程为中心的编程思想,一种基础的顺序的思维方式 特性:模块化、流程化 |
C语言 (查后发现汇编语言属于面向计算机硬件表述) |
||
| 性能比面向对象高,因为类调用需实例化,消耗资源开销大;比如单片机、嵌入式Linux/Unix等一般采用面向过程开发, 性能是最重要的因素 |
相对于面向对象而言不易维护、 不易复用、不易扩展 |
||||
| 语言种类 | *动态语言 | 定义 | 在运行期间才去做数据类型检查的语言、 不用给任何变量指定数据类型 |
Python、Ruby、 Vbscript、Javascript、Object-C、PHP |
|
| 不需要写多种数据类型的代码,代码相对简洁、方便阅读 | 不方便调试 代码命名也容易混淆 |
||||
| 静态语言 | 定义 | 数据类型是在编译其间检查的、 写程序时要声明所有变量的数据类型 |
C/C++、Java、 Delphi、Go |
||
| 方便调试,代码相对规范 | 代码含很多数据类型,不够简洁 | ||||
| 数据类型 | *强类型 | 定义 | 一旦变量被指定数据类型,若不强制类型转换,则数据类型永远不变 | Python、Java、C/C++ | |
| 类型安全、但是程序可靠, 调试简单,变量更加规范 |
学习成本大开发效率比较低下,代码设计必须考虑存储问题, | ||||
| 弱类型 | 定义 | 数据类型可被忽略,一个变量可赋不同数据类型的值 | JavaScript 、VBScript、PHP | ||
| 学习简单,语言表达简单易懂, 代码更优雅,开发周期更短, 更加偏向逻辑设计 |
类型不安全,变量混乱, 运行效率低下 |
||||
| 转译器种类 | 特点 | 在运行程序的时候才逐行解释翻译,然后执行的语言 | JavaScript、Python、Erlang、PHP、Perl、Ruby、 java.exe 解释器 | ||
| *解释器 | 良好的平台兼容、灵活修改代码不用停机快速部署 | 每次运行都需解释 性能偏低 |
|||
| 特点 | 将源代码编译成机器码,之后才能执行的语言 | C、C++、 Pascal、Object-C、 javac.exe 编译器 |
|||
| 编译器 | 程序执行效率高 可以脱离语言环境独立运行 |
开发效率低,不能跨平台; 修改需重新编译,大工程编译时间长 |
|||
| 小结 | Python是动态强数据类型且解释型执行的面向对象的高级语言 | ||||
| python优缺点 | 1>入门简单,适合阅读; 2>摒弃指针,语法简洁, 可复杂编程且开发效率高; 3>开源代码,可移植性强; 4>可扩展性好,对速度和算法可以部分程序用C/C++编写; 5>可嵌入性好,可将python嵌入到C/C++程序中,胶水语言特性; 6>强大丰富的库和第三方库, 降低开发周期,避免重复造轮子; 7>强制缩进,代码规范; |
1>运行速度稍慢; 2>代码不能加密; 3>由于GIL(全局解释器锁) 线程不能很好利用多CPU 4>架构或框架选择太多,是优势但对初选者不友好; |
人生苦短 我用Python! |
||
| Py解释器 | CPython | 官方版本的解释器,C语言开发,使用最广泛;不支持JIT执行速度不如pypy | |||
| PyPy | 采用JI技术,实现动态编译为机器码,提高执行速度,无法支持官方API,无法使用大部分第三方库 | ||||
| Jython | 运行在Java平台的python解释器,将Python代码翻译成JAVA字节码执行 | ||||
| IronPython | 运行在微软.Net平台上的Python解释器,把Python代码编译成.Net的字节码执行 | ||||
| Ipython | 基于CPython之上的一个交互式解释器 | ||||
| 版本发展 非完全向下兼容 |
2.X | 3.X | |||
| print语句:print Hello world! | print函数:print("hello world!") | ||||
| 输入函数 | input_raw()、raw_input() | input() | |||
| 编码 | 默认编码ascii:中文需首行添加: #-*- encoding:utf-8 -*- |
默认编码utf-8 | |||
| 字符串 | unicode类型表示字符串序列, str类型表示字节序列 |
str类型表示字符串序列, byte类型表示字节序列 |
|||
| True和False | Python2 两个全局变量可更改 | 修正了变量,让True或False不可变 | |||
| nonlocal | 无法在嵌套函数中声明非全局变量 | 使用nonlocal方法实现 | |||
| xrange | 有 | 无,完全range()方法 | |||
| long类型 | 有 | 无,仅有int一种整型 | |||
| 异常 | except exc, var | except exc as var | |||
| 命名改变 | _winreg | winreg | |||
| 命名改变 | ConfigParser | configparser | |||
| 命名改变 | copy_reg | copyreg | |||
| 命名改变 | Queue | queue | |||
| 命名改变 | SocketServer | socketserver | |||
| 命名改变 | repr | reprlib | |||
| 三、Python关键字和变量命名 | |||||
| 1、关键字概览 | |||||
| 1>内置常量关键字 | |||||
| FALSE | 布尔类型常量, 判断检测属性为假 |
TRUE | 布尔类型常量, 判断检测属性为真 |
None | NoneType数据类型特殊的常量,无值 与任何其他的数据类型比较永远返回False |
| __debug__ | 一个bool类型的常量 | Ellipsis | ellipsis类型的常量 它和…是等价的 |
NotImplemented | 是NotImplementedType类型的常量, 可赋值但不应该这样操作 |
| 2>逻辑与 或 非 | |||||
| not | 逻辑非 | and | 逻辑与 | or | 逻辑或 |
| 3>判断 与 循环 | |||||
| if | 条件判断 | elif | 条件判断,其他情况 | else | 条件判断的结束 |
| for | 与in连用构成循环遍历 | in | 与from连用构成遍历 | is | is判断,常用于id、type、value |
| while | 条件判断-循环语句, 注意条件防止死循环 |
break | 直接跳出整个循环 | continue | 跳出当前循环 |
| 4>函数 | |||||
| def | 用于定义方法 | lambda | 表达式方式定义一个匿名函数,起到函数速写的作用 | pass | 空语句保证程序结构完整性, 占位后续再完善 |
| return | 函数返回值 | yield | 返回一个生成器(iterable)对象 | ||
| 5>异常处理 | |||||
| try | 异常处理, try存放要执行的语句 |
except | except捕获异常,与try连用 | finally | 必然执行finally语句的代码块 |
| raise | 触发异常,后面代码不会再执行, 可以主动引发异常 |
assert | 断言,其返回值为假,就会触发异常 | ||
| 6>导入模块 包 | |||||
| import | 引入外部包 | from | 引用模块 | ||
| 7>重命名 | |||||
| as | 与with连用 | ||||
| 8>变量 | |||||
| global | 定义全局变量 | nonlocal | 用于标识外部作用域的变量 | ||
| 9>类 | |||||
| class | 声明类 | ||||
| 10>删除 | |||||
| del | 删除变量 | ||||
| 11>上下文管理 | |||||
| with | 与as连用,和异常处理 | ||||
| 12>python3.7新增 | |||||
| async | 声明函数为异步函数 | await | 一个协程里可以启动另外一个协程,并等待它完成返回结果 | ||
| 2、变量命名(变量是计算机语言中能储存计算结果或能表示值的抽象概念,简言之就是 数据的别名(标识符),方便记忆和使用) | |||||
| 命名规则 | 列子 | ||||
| 1>必须由数字,字母,下划线任意组合,且不能数字开头; | |||||
| 2>不能是python中的关键字; | 喏,就是上面的哪些关键字喽! | ||||
| 3>不能是中文,变量名不要太冗长 | |||||
| 4>永远不要使用字母‘l’(小写的L),‘O’(大写的O),或者‘I’(大写的i)作为单字符变量名。 在有些字体里,这些字符无法和数字0和1区分,如果想用‘l’,用‘L’代替。 |
|||||
| 5>全局变量名:python中约定俗成常量名字母全大写,单词之间用_分割 | COLOR_WRITE | ||||
| 6>变量名具有可描述性:不要起名为无意义难以解读的变量名 | auigfiusdjvkjlsgfu,这就是无意义的命名 | ||||
| 7>普通变量:小写字母,单词之间用_分割 | this_is_a_var | ||||
| 8>实例变量:以_开头,其他和普通变量一样 | _instance_var | ||||
| 9>私有实例变量:以__开头(2个下划线),其他和普通变量一样 | __private_var | ||||
| 10>专有变量:__开头,__结尾,一般为python的自有变量,不要以这种方式命名 | __class__ | ||||
| 11>类名: 使用驼峰命名规则,单词首字母大写 | ConfigUtil | ||||
| 12>模块和包名:简短全小写字母,可以使用_下划线,但不建议使用; C/C++编写的扩展模块,需要一个下划线前缀 |
ad_stats.py 、_socket | ||||
| 12>普通函数名:函数名应该小写,想提高可读性可使用下划线分割 | get_name() | ||||
| 13>私有函数(外部访问会报错):以__开头(2个下划线),其他和普通函数一样 | __get_name() | ||||
| 14>常用缩写:function --> fn、text --> txt、object --> obj 、count --> cnt 、number --> num等 | |||||
| 15>一个前导下划线:表示非公有; 一个后缀下划线:避免关键字冲突;两个前导下划线:当命名一个类属性引起名称冲突时使用。两个前导和后缀下划线:“魔”(有特殊用途)对象或者属性,不要创造这样的名字,只是使用它们! | |||||
| 3、注释规范和其他规范(注释需简洁准确,避免冗长无用注释;注释是为方便自己和他人快速阅读并理解代码功能使用) | |||||
| pycharm可以配置pylint来检查代码规范 | 栗子 | ||||
| 1>块注释:块注释适用于跟随它们的某些(或全部)代码,并缩进到与代码相同的级别; 块注释的每一行开头使用一个#和一个空格(除非块注释内部缩进文本)。 块注释内部的段落通过只有一个#的空行分隔 |
|||||
| 2>行内注释: #(解释逻辑为主)推荐有节制的使用行内注释; 行内注释和代码至少要有两个空格分隔,注释由#和一个空格开始。 |
x = x + 1 # Compensate for border | ||||
| 3>文档字符串:'''被注释内容''' """被注释内容"""(解释功能为主); 要为所有的公共模块,函数,类以及方法编写文档说明; 非公共的方法没有必要,但应该在def那一行之后描述方法具体作用的注释 |
|||||
| 4>与代码相矛盾的注释比没有注释还糟,当代码更改时,优先更新对应的注释! | |||||
| 5>注释应该是完整的句子,它的第一个单词应该大写,除非它是以小写字母开头的标识符 | |||||
| 6>注释在句尾结束的时候应该使用两个空格。 | |||||
| 7>缩进:每一级缩进使用4个空格。续行应该与其包裹元素对齐,要么使用圆括号、方括 号和花括号内的隐式行连接来垂直对齐,要么使用挂行缩进对齐 |
|||||
| 8>行的最大长度:所有行限制的最大字符数为79; 没有结构化限制的大块文本(文档字符或者注释),每行的最大字符数限制在72。 |
|||||
| 9>空行:顶层函数和类的定义,前后用两个空行隔开。类里的方法定义用一个空行隔开。 | |||||
| 10>Imports 导入: 在分开的行,推荐使用绝对路径导入;导入顺序依次为:标准库导入、相关第三方库导入、本地应用/库特定导入、应该在每一组导入之间加入空行。 | from subprocess import Popen, PIPE | ||||
| 11>建议程序编写结束后加一个回车空行 | |||||
| 四、Pycharm的快捷键与相关配置简介 | ||||||
| 1、常用快捷键 | ||||||
| Ctrl + / | 注释(取消注释)选择的行 | Alt + Shift + C | 快速查看最近对项目的更改 | F8 | 跳过(Debugging) | |
| Ctrl + Shift + / | 块注释 | Alt + Insert | 自动生成代码 | F7 | 进入(Debugging) | |
| Ctrl + Alt + L | 格式化代码 | Ctrl + O | 重新方法 | Shift + F8 | 退出(Debugging) | |
| Ctrl + Alt + I | 自动缩进行 | Ctrl + Alt + O | 优化导入 | Alt + F9 | 运行游标(Debugging) | |
| Alt + Enter | 优化代码,提示信息实现自动导包 | Tab / Shift + Tab | 缩进/不缩进当前行 | Alt + F8 | 验证表达式(Debugging) | |
| Ctrl + Shift + F | 高级查找 | Ctrl+V/Shift+Insert | 从剪贴板粘贴 | Ctrl + F8 | 断点开关(Debugging) | |
| Alt + Shift + Q | 更新代码到远程服务器 | Ctrl + Shift + V | 从最近的缓冲区粘贴 | Ctrl + Shift + F8 | 查看断点(Debugging) | |
| Ctrl + N | 查找所有的类的名称 | Alt + Shift + F10 | 运行模式配置(Running) | Ctrl + N | 跳转到类(Navigation) | |
| Ctrl + P | 光标位于方法调用的括号内,弹出一个有效参数列表 | Alt + Shift + F9 | 调试模式配置(Running) | Ctrl + Shift + B | 跳转到类型声明(Navigation) | |
| Ctrl + Shift + J | 快捷键将两行合并为一行,并删除不必要的空格以符合代码样式 | Shift + F10 | 运行(Running) | Ctrl + U | 跳转到父方法、父类(Navigation) | |
| Ctrl + Shift + V | 快捷键选择并将最近的剪贴板内容插入到文本中 | Shift + F9 | 调试(Running) | Alt + Up/Down | 跳转到上一个、下一个方法(Navigation) | |
| Shift + F6 | 重命名(Refactoring) | Alt + Delete | 安全删除(Refactoring) | F2 / Shift + F2 | 下一条、前一条高亮的错误(Navigation) | |
| 待补充 | ||||||
| Ctrl+空格 | 代码提示功能 | Ctrl+F4 | 关闭当前文档 | |||
| 3、配置信息简介 | ||||||
| 导入和导出配置 | file>export settings、file>import settings | |||||
| 显示“行号”与“空白字符” | > Appearance -> 勾选“Show line numbers”、“Show whitespaces”、“Show method separators” | |||||
| 颜色与字体 | > Colors & Fonts -> Scheme name -> 选择"monokai"“Darcul | |||||
| 字体大小 | > Colors & Fonts -> Font -> Size -> 设置为“14 | |||||
| 设置缩进符为制表符“Tab | File -> Default Settings -> Code Style -> General -> 勾选“Use tab character -> Python -> 勾选“Use tab character” |
|||||
| 去掉默认折叠 | > Code Folding -> Collapse by default -> 全部去掉勾选 | |||||
| 文件默认编码 | File Encodings> IDE Encoding: UTF-8;Project Encoding: UTF-8; | |||||
| 代码自动整理设置 | File -> Settings -> appearance | |||||
| 代码提示功能 | Main menu -> code -> Completion -> Basic -> 设置为“Alt+/” Main menu -> code -> Completion -> SmartType -> 设置为“Alt+Shift+/” |
|||||
| 待补充 | ||||||
| 五、python数据类型一 | ||||||
| 1、计算机基础知识简介 | ||||||
| CPU | 相当于人的大脑,用于计算 | |||||
| 内存 | 储存数据,4G,8G,16G,32G,成本高,断电数据即消失。 | |||||
| 硬盘 | 固态硬盘、机械硬盘,储存数据,应该长久保持数据,重要文件等断电数据不消失 | |||||
| 操作系统 | windows、Ubuntu、Centos、Gentoo、FreeBSD、MAC OS | |||||
| 应用程序 | word、excel、pycharm等等 | |||||
| 编码 | 机器码 | 电脑的传输,存储都是01010101 | ||||
| ASCII码 | 只能表示256种可能,太少 | |||||
| 万国码 unicode | 来解决全球化文字问题32位表示一个字符。 | |||||
| Unicode 升级 | utf-8 | 最少用一个字节,8位表示一个英文或字符即一个字节表示一个字符 | ||||
| 欧洲文字用16位去表示 两个字节 表示一个字符 | ||||||
| 中文用24 位去表示 三个字节 表示一个字符 | ||||||
| utf-16 | 一个字符最少用16位去表示 | |||||
| utf-32 | 一个字符最少用32位去表示 | |||||
| gbk | 中国发明的,一个中文用两个字节 16位去表示,只能用于中文和ascii码中的文字,英文字母1个字节 | |||||
| python3中 32位 4个字节 表示1个字符 | ||||||
| 单位换算 | ||||||
| 1bit 8bit = 1bytes | 8位 = 1字节bytes | |||||
| 1byte 1024byte = 1KB | ||||||
| 1KB 1024kb = 1MB | ||||||
| 1MB 1024MB = 1GB | ||||||
| 1GB 1024GB = 1TB | ||||||
| 进制转换 | 不详细描述(略) | |||||
| 二进制 | 八进制 | 十六进制 | ||||
| 十进制 | ||||||
| 二进制 | ||||||
| 八进制 | ||||||
| 十六进制 | ||||||
| 2、Python的数据类型 | ||||||
| 先介绍几个概念 | ||||||
| <1 | 不可变数据类型 | 当该数据类型的对应变量的值发生了改变,那么它对应的内存地址也发生改变 | ||||
| <2 | 可变数据类型 | 当该数据类型的对应变量的值发生了改变,那么它对应的内存地址不发生改变 | ||||
| <3 | 不可哈希 | 改变值的同时却没有改变id,无法由地址定位值的唯一性,因而不可哈希 | ||||
| <4 | 可哈希 | 一个对象能称为 hashable ,必须有个 hash 值,这个值在整个生命周期都不会变化,而且必须可以进行相等比较 | ||||
| 数据类型 | ID测试 | 属性 | ||||
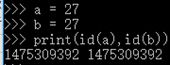
| 1>整型 | int 数字 (64系统) -2**63~2**63-1 |
 |
 |
同值同址, 不同值不同址 |
不可变 可哈希 |
|
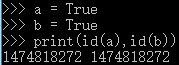
| 2>布尔型 | bool,用于判断 真 1 True 假 0 False |
 |
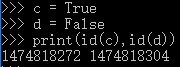 |
同值同址, 不同值不同址 |
不可变 可哈希 |
|
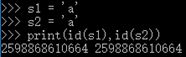
| 3>字符串 | str 字符集合 ‘’ 引号引起来的数据 |
 |
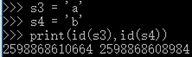 |
同值同址, 不同值不同址 |
不可变 可哈希 |
|
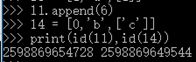
| 4>列表 | list 容器 [ ] 承载多种数据类型 l1 = [2, 0, '567'] |
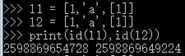 |
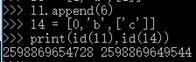 |
同值不同址, 不同值同址 |
可变 不可哈希 |
|
| 5>元组 | tuple 重要数据容器 () 不能增删改的容器 tu1 = ( 'a', '何', 3, “5”) |
 |
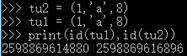 |
元组因为是不可修改的 | 不可变 可哈希 |
|
| 6>字典 | dict 容器 { } 易查询有数据关联 person = {"name": "mr.wu", 'age': 18} |
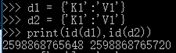 |
 |
同值不同址, 不同值同址 |
可变 不可哈希 |
|
| 7>集合 | set 数据集合 { } 无序的且不重复 set1 = {1,2,'harald',} |
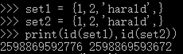 |
 |
集合数据发生改变 但是内存地址没有改变 |
可变 不可哈希 |
|
| 8>frozenset | forzenset() 函数 返回一个冻结的集合 frozenset([,5, 6, 7, 8, 9]) |
frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。 | 不可变 可哈希 |
|||
| 六、Python流程控制语句基础 | |||
| 1、顺序结构:即代码从上到下的执行顺序来执行 | |||
| 2、分支结构:代码执行到某位置而进行判断,来决定继续执行的方向 | |||
| if语句 | 形式 | 简单栗子 | |
| 条件式判断 if 形式 |
if 表达式: 语句块 |
if a>0: print("正数") |
|
| 非此即彼式选择 if-else形式 |
if 表达式: 语句块1 else: 语句块2 |
if a>0: print("正数") else: print("负数") |
|
| elif个数不限制 if-elif-else形式 |
if 表达式1: 语句块1 elif: 语句块2 ... else: 语句块n |
if a>0: print("正数") elif a == 0: print("零") else: print("负数") |
|
| 3、循环结构 | |||
| 形式 | 举例 | ||
| whlie循环 | while 条件式 | while 循环条件: 循环体 |
while i <= 100: num += i i += 1 |
| for循环 | for遍历式 | for x in y: 循环体 |
for i in range(10): print(i) |
| 4、break、pass、continue语句 | |||
| break | 用于跳出最近的一级 for 或 while 循环 | ||
| continue | 表示循环继续执行下一次迭代 | ||
| pass | 语句什么也不做,可以作为控制体占位符 | ||
愿有更多的朋友,在网页笔记结构上分享更逻辑和易读的形式:
链接:https://pan.baidu.com/s/1PaFbYL1sYoUcRj0xgm8W8Q
提取码:(暂缓)