SKlearn学习总结
首先,我想说明下问什么要学习SKlearn:
SKlearn是python的机器学习库,它是基于numpy,pandas,scipy,matplotlib上的,
涵盖了机器学习中数据预处理(很重要),模型选择,数据引入,有监督的回归,分类,无监督的聚类和降维,功能非常全面,是传统机器学习库的首选者.
首先,我们看看它是怎样引入数据集的:

from sklearn.datasets import load_iris
iris = load_iris()
iris.keys()#查看键值,方便对数据集进行处理
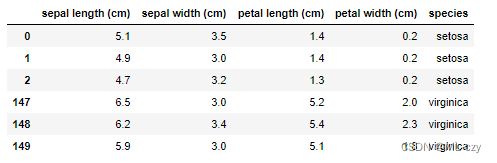
用pandas直观的表示下数据集:
iris_load = pd.DataFrame(iris.data,columns=iris.feature_names)#DataFrame函数合并x和y
iris_load['species'] = iris.target_names[iris.target]#添加一列'species'
核心 API:
可把它不严谨的当成一个模型 (用来回归、分类、聚类、降维),或当成一套流程 (预处理、网格最终)。
本节三大 API 其实都是估计器:
估计器 (estimator) 当然是估计器
预测器 (predictor) 是具有预测功能的估计器
转换器 (transformer) 是具有转换功能的估计器
接下来,我们看看有监督学习中的线性回归:
直接介绍前两个API
from sklearn.linear_model import LinearRegression
import numpy as np
model = LinearRegression()
X = np.array([[1,1],[1,2],[2,2],[2,3]])
y = np.dot(X,np.array([1,2])) + 3
model = LinearRegression().fit(X,y)#--->到这是估计器
model.score(X,y)#返回决定系数,该系数用于观察数据拟合程度
model.predict(np.array([[2,5]]))#输入数据进行预测--->到这是预测器
然后是无监督的Kmeans聚类:
这里继续沿用上面的数据集
from sklearn.cluster import KMeans
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
iris = load_iris()
X_train,X_test,y_train,y_test = train_test_split(iris['data'],
iris['target'],
test_size=0.2)#数据集划分的模版
model = KMeans( n_clusters=3 )#三个簇
X = iris.data[:,0:2]#这里切去前两个特征数据,方便可视化处理
model.fit(X)#训练
idx_pred = model.predict( X_test[:,0:2] )#预测
最后进行可视化处理
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.colors import ListedColormap, LinearSegmentedColormap
model = KMeans(n_clusters=3)
model.fit(X_train[:,0:2])
idx_pred = model.predict(X_test[:,0:2])
#print(idx_pred)
#print(y_test)
cmap_light = ListedColormap(["#FFAAAA",'#AAFFAA','#AAAAFF'])
cmap_bold1 = ListedColormap(["#FFAAAA",'#AAFFAA','#AAAAFF'])
cmap_bold2 = ListedColormap(["#FFAAAA",'#AAFFAA','#AAAAFF'])
centroid = model.cluster_centers_
true_centroid = np.vstack((X_test[y_test == 0,0:2].mean(axis=0),
X_test[y_test == 1,0:2].mean(axis=0),
X_test[y_test == 2,0:2].mean(axis=0)
))
plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
plt.scatter(X_test[:,0],X_test[:,1],c=idx_pred,cmap=cmap_bold1)
plt.scatter(centroid[:,0],centroid[:,1],marker='o',s=200,
edgecolors='k',c=[0,1,2],cmap=cmap_light)
plt.xlabel('Sepal length(cm)')
plt.ylabel('Sepal length(cm)')
plt.title("Predicted Class")
plt.subplot(1,2,2)
plt.scatter(X_test[:,0],X_test[:,1],c=y_test,cmap=cmap_bold2)
plt.scatter(true_centroid[:,0],true_centroid[:,1],marker='o',s=200,
edgecolors='k',c=[2,1,0],cmap=cmap_light)
plt.xlabel('Sepal length(cm)')
plt.ylabel('Sepal width(cm)')
plt.title("True Class")
plt.show()
model.score(X_train[:,0:2],idx_pred)
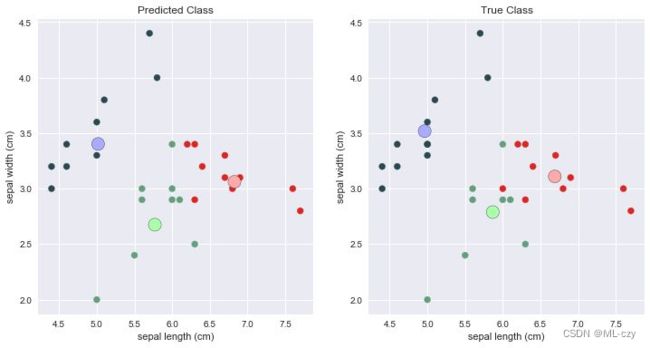
通过上面两个案例,我们知道要对一个数据集进行有监督或者无监督的学习,都离不开fit()和predict()两个函数,那么,就有了如下模板:
from sklearn.XXX import somemodel
model = somemodel()
有监督:
model.fit( X, y )
y_pred = model.predict( X_new )
s = model.score( X_new )
无监督:
model.fit( X )
idx_pred = model.predict( X_new )
s = model.score( X_new )
转换器:
即在fit()后transform()
所以我们在处理那种标签很长的数据集时,可以使用LabelEncoder 和 OrdinalEncoder 都可以将字符转成数字,但是LabelEncoder 的输入是一维,比如 1d ndarray;
OrdinalEncoder 的输入是二维,比如 DataFrame
首先介绍第一种
enc = ["win",'draw','lose','win']
dec = ['draw','draw','win']
from sklearn.preprocessing import LabelEncoder
LE = LabelEncoder()
print(LE.fit(enc))#训练
print(LE.transform(dec))
#print(LE.classes_)#统计数据种类
print(LE.transform(enc))

可以看出,这里把’draw’转换成了0,'win’转换成了2,'lose’转换成了1。
第二种:
from sklearn.preprocessing import OrdinalEncoder
OE = OrdinalEncoder()
enc_DF = pd.DataFrame(enc)
dec_DF = pd.DataFrame(dec)
print( OE.fit(enc_DF) )
print( OE.categories_ )
print( OE.transform(dec_DF) )
OrdinalEncoder(categories='auto', dtype=<class 'numpy.float64'>)
[array(['draw', 'lose', 'win'], dtype=object)]
[[0.]
[0.]
[2.]]
OneHotEncoder
独热编码其实就是把一个整数用向量的形式表现。

转换器 OneHotEncoder 可以接受两种类型的输入:
- 用 LabelEncoder 编码好的一维数组
- DataFrame
from sklearn.preprocessing import OneHotEncoder
OHE = OneHotEncoder()
num = LE.fit_transform(enc)
print(num)
OHE_Y = OHE.fit_transform(num.reshape(-1,1))#做独热编码
OHE_Y.toarray()
[2 0 1 2]
array([[0., 0., 1.],
[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
OneHotEncoder()内部参数
OneHotEncoder(n_values=’auto’, categorical_features=’all’, dtype=
- n_values=’auto’,表示每个特征使用几维的数值由数据集自动推断,即几种类别就使用几位来表示。
- categorical_features = ‘all’,这个参数指定了对哪些特征进行编码,默认对所有类别都进行编码。
- sparse=True 表示编码的格式,默认为 True,即为稀疏的格式,指定 False 则就不用 toarray() 了
- handle_unknown=’error’,其值可以指定为 “error” 或者
“ignore”,即如果碰到未知的类别,是返回一个错误还是忽略它。
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
X = pd.DataFrame([[1,2,3],
[4,5,6],
[10,8,9]],columns=['feature1','feature2','label'])
hotencoder = OneHotEncoder(sparse = False, handle_unknown = "ignore")
hot = hotencoder.fit_transform(X)
print(pd.DataFrame(hot))
0 1 2 3 4 5 6 7 8
0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0
1 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0
2 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0
规范化 (normalize) 或标准化 (standardize) 数值型变量
这里重点强调下特征缩放:
特征缩放是数据处理的一个很重要的方法,具体描述是当多个特征向量中有一个或者多个向量参数范围特别大时,将对我们梯度下降算法有很大干扰,费时费力。这时采用特征缩放对这多个特征向量进行范围标准化,即缩小了特征参数范围,就明显的加快了梯度收敛速度。
#转换之特征缩放:
#MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
X = np.array([0,0.5,1,1.5,2,100])
X_scale = MinMaxScaler().fit_transform(X.reshape(-1,1))
X_scale
#StandScaler
from sklearn.preprocessing import StandardScaler
X_scale = StandardScaler().fit_transform(X.reshape(-1,1))
X_scale
fit() 函数只作用在训练集上,千万不要用在测试集上。
最后介绍sklearn中元估计器,就是很多基估计器组成的估计器.
第一个:RandomForestClassifier
RandomForestClassifier 通过控制 n_estimators 超参数来决定基估计器的个数
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
from sklearn import metrics#指标,用于判断一个模型训练的好坏
X_train,X_test,y_train,y_test = train_test_split(iris['data'],
iris['target'],
test_size=0.2)
from sklearn.ensemble import RandomForestClassifier
RF = RandomForestClassifier(n_estimators=4,max_depth=5)
RF.fit(X_train,y_train)
print(RF.n_estimators)
RF.estimators_
print("RF - Accuracy(Train): %.4g"%metrics.accuracy_score(y_train,RF.predict(X_train)))
print("RF - Accuracy(Test):%.4g"%metrics.accuracy_score(y_test,RF.predict(X_test)))
4
RF - Accuracy(Train): 0.975
RF - Accuracy(Test):0.9667
第二个:VotingClassifier
和随机森林由同质分类器「决策树」不同,投票分类器由若干个异质分类器组成
RandomForestClassifier 的基分类器只能是决策树,因此只用通过控制 n_estimators 超参数来决定树的个数,而 VotingClassifier 的基分类器要实实在在的输入其本身。
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier
from sklearn import metrics
LR = LogisticRegression(solver='lbfgs',multi_class='multinomial')
RF = RandomForestClassifier(n_estimators=5)
GNB = GaussianNB()
Ensemble = VotingClassifier(estimators=[('lr',LR),("rf",RF),("gnb",GNB)],voting='hard')
Ensemble.fit(X_train,y_train)#集成估计器,得到最优
# print(len(Ensemble.estimators_))计算估计器个数
# Ensemble.estimators_
LR.fit(X_train,y_train)
RF.fit(X_train,y_train)
GNB.fit(X_train,y_train)
print("LR - Accuracy: %.4g"%metrics.accuracy_score(y_train,LR.predict(X_train)))
print("RF - Accuracy: %.4g"%metrics.accuracy_score(y_train,RF.predict(X_train)))
print("GNB - Accuracy: %.4g"%metrics.accuracy_score(y_train,GNB.predict(X_train)))
print("Ensemble - Accuracy: %.4g"%metrics.accuracy_score(y_train,Ensemble.predict(X_train)))
print("LR - Accuracy: %.4g"%metrics.accuracy_score(y_test,LR.predict(X_test)))
print("LR - Accuracy: %.4g"%metrics.accuracy_score(y_test,RF.predict(X_test)))
print("LR - Accuracy: %.4g"%metrics.accuracy_score(y_test,GNB.predict(X_test)))
LR - Accuracy: 1
RF - Accuracy: 0.9979
GNB - Accuracy: 0.8351
Ensemble - Accuracy: 0.9993
LR - Accuracy: 0.975
RF - Accuracy: 0.9139
GNB - Accuracy: 0.8083
Ensemble - Accuracy: 0.9528
第三个:MultiOutputClassifier
多输出分类
本次将小于等于 4,4 和 7 之间,大于等于 7 分为三类
from sklearn.multioutput import MultiOutputClassifier
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_digits
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import metrics
digits = load_digits()
X_train,X_test,y_train,y_test = train_test_split(digits['data'],
digits['target'],
test_size=0.2)
y_train_1st = y_train.copy()
y_train_1st[y_train<=4] = 0
y_train_1st[np.logical_and(y_train>4,y_train<7)] = 1#np.logical_and即and条件,都满足了才分到这一类
y_train_1st[y_train>=7] = 2
y_train_multioutput = np.c_[y_train_1st,y_train]#把矩阵按列相加,即左右相加
MO = MultiOutputClassifier(RandomForestClassifier(n_estimators=100))
MO.fit(X_train,y_train_multioutput)
MO.predict(X_test[:5,:])
y_test_1st = y_test.copy()
y_test_1st[y_test<=4] = 0
y_test_1st[np.logical_and(y_test>4,y_test<7)] = 1
y_test_1st[y_test>=7] = 2
y_test_multioutput = np.c_[y_test_1st,y_test]
y_test_multioutput[:5,]
array([[0, 1],
[0, 2],
[0, 0],
[2, 9],
[0, 4]])
第四个:Model Selection 估计器
模型选择 (Model Selction) 在机器学习非常重要,它主要用于评估模型表现,常见的 Model Selection 估计器有以下几个:
cross_validate: 评估交叉验证的表现。
learning_curve: 建立学习曲线。
GridSearchCV: 用交叉验证从网格中一组超参数搜索出最佳超参数。
RandomizedSearchCV: 用交叉验证从一组随机超参数搜索出最佳超参数。
下面使用最后两种方法来进行模型选择
from time import time
from scipy.stats import randint
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
X,y = digits.data,digits.target
RF = RandomForestClassifier(n_estimators=20)
#Randomized Search
param_dist = {"max_depth":[3,5],
"max_features":[1,11],
'min_samples_split':randint(2,11),
"criterion":["gini","entropy"]}
n_iter_search = 20
random_search = RandomizedSearchCV(RF,param_distributions=param_dist,n_iter=n_iter_search,cv=5)
start = time()
random_search.fit(X,y)
print("RandomizedSearchCV took %.2f seconds for %d candidates"
"parameter settings."%((time()-start),n_iter_search))
print(random_search.best_params_)
print(random_search.best_score_)
#Grid Search
param_grid = {"max_depth":[3,5],
"max_features":[1,3,10],
'min_samples_split':randint(2,3,10),
"criterion":["gini","entropy"]}
grid_search = GridSearchCV(RF,param_grid=param_grid,cv=5)
start = time()
grid_search.fit(X,y)
print("\nGridSearchCV took %.2f seconds for %d candidate parameter settings."
%(time()-start,len(grid_search.cv_results_['params'])))
print(grid_search.best_params_)
print(grid_search.best_score_)
第五个:Pipeline 估计器
Pipeline 估计器又叫流水线,把各种估计器串联 (Pipeline) 或并联 (FeatureUnion) 的方式组成一条龙服务
有点类似于深度学习中的Sequential容器,把各种网络层都放到这个容器中,在训练过程中直接调用即可.
下面用一个简单例子来说明如果用 Pipeline 来做「先填补缺失值-再标准化」这两步的。先生成含缺失值 NaN 的数据 X。
import numpy as np
X = np.array([[1,2,3,4,5,np.NaN],
[5,4,3,2,1,np.NaN]])
X = np.transpose(X)#转置
X
array([[ 1., 2., 3., 4., 5., nan],
[ 5., 4., 3., 2., 1., nan]])
然后使用处理缺失值的转换器 SimpleImputer
做规划化的转换器 MinMaxScaler
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
#使用Pipeline容器
pipe = Pipeline([
('impute',SimpleImputer(missing_values=np.nan,strategy='mean')),
('normalize',MinMaxScaler())
])
#分开使用
X_proc = pipe.fit_transform(X)
X_proc
X_impute = SimpleImputer(missing_values=np.nan,strategy='mean').fit_transform(X)
X_impute
X_normalize = MinMaxScaler().fit_transform(X_impute)
X_normalize
结果是一样的,但是用了容器之后,代码看上去更加美观.
接下来建立一个流水线 full_pipe,它并联着两个流水线
categorical_pipe 处理分类型变量
-
DataFrameSelector 用来获取
-
SimpleImputer 用出现最多的值来填充 None
-
OneHotEncoder 来编码返回非稀疏矩阵
numeric_pipe 处理数值型变量
- DataFrameSelector 用来获取
- SimpleImputer 用均值来填充 NaN
- normalize 来规范化数值
import pandas as pd
d ={"IQ":['high','avg','avg','low','high','avg','high',None],
'temper':['good',None,'good','bad','good','bad',None,'bad'],
'income':[50,40,30,20,10,9,np.NaN,12],
'height':[1.68,1.83,1.77,np.NaN,1.9,1.65,1.88,1.75]}#写好数据
# X = pd.DataFrame(d)
# X
from sklearn.pipeline import Pipeline
from sklearn.pipeline import FeatureUnion
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.base import BaseEstimator,TransformerMixin
class DataFrameSelector(BaseEstimator,TransformerMixin):#将DataFrame转换为ndarray,需要构建class
def __init__(self,attribute_names):
self.attribute_names = attribute_names
def fit(self,X,y=None):
return self
def transform(self,X):
return X[self.attribute_names].values
categorical_features = ['IQ','temper']
numeric_features = ['income','height']
categorical_pipe = Pipeline([
('select',DataFrameSelector(categorical_features)),
('impute',SimpleImputer(missing_values=None,strategy='most_frequent')),
('one_hot_encode',OneHotEncoder(sparse=False))])
numeric_pipe = Pipeline([
('select',DataFrameSelector(numeric_features)),
('impute',SimpleImputer(missing_values=np.nan,strategy='mean')),
('normalize',MinMaxScaler())])
full_pipe = FeatureUnion(transformer_list=[
('numeric_pipe',numeric_pipe),
('categorical_pipe',categorical_pipe)
])
X_proc = full_pipe.fit_transform(X)
print(X_proc)
借鉴博客: 链接