课程向:深度学习与人类语言处理 ——李宏毅,2020 (P6)
传统的语音辨识系统: Hidden Markov Model (HMM) 隐马尔科夫模型
李宏毅老师2020新课深度学习与人类语言处理课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
视频链接地址:
https://www.bilibili.com/video/BV1RE411g7rQ
课件ppt已上传至资源,可免费下载使用
前言
上两篇我们讲的都是神经网络在语音辨识中的使用(LAS、CTC、RNA、RNN-T、Neural Transducer、MoCha),而即使是如今大多数的语音辨识系统还是使用传统的 Hidden Markov Model 隐马尔科夫模型。让我们看看至少10年前还没有deep learning的时候,人们是怎样解决语音辨识的。
I P(Y|X)
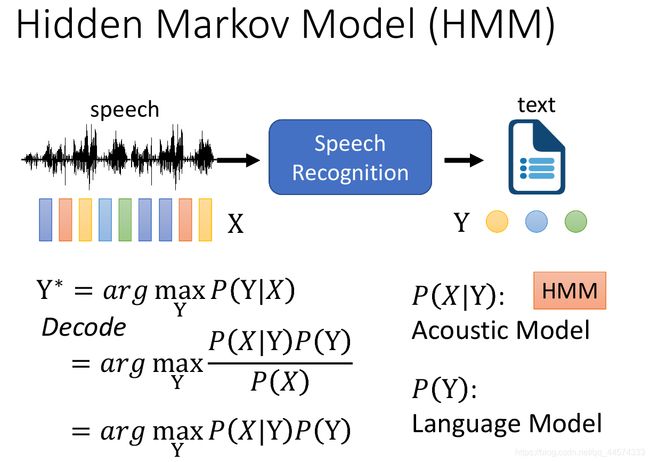
参考上图,我们可以看到语音辨识是输入vector X ,产生 token Y。过去把这个问题当成统计问题,给一段X产生Y的几率,只需穷举所有可能Y,得到 P(Y|X) 的概率最大就是我们语音辨识的结果Y。那我们可能穷举所有可能的Y吗,Y是所有可能的token sequence,这样的sequence太多了。
我们把看到X,找哪一个Y的几率最大的这件事叫做Decode解码。
但根据贝叶斯定理,我们可以把P(Y|X)
- P(Y|X) = P(X|Y) P(Y) / P(X)
而其中P(X)是无关的故可省略。故我们只需要找一个Y使得argmax P(X|Y) P(Y) 最大
其中 P(X|Y) 叫做 Acousitc Model 声学特征模型
P(Y) 叫做 Language Model 语言模型
而Acoustic Model过去常用的就是HMM ,Language Model之后会讲到。
II Hidden Markov Model (HMM) 隐马尔科夫模型

1 S (state)
为找到上面最大化p(X|Y),HMM将Y细化为了S state
之前我们讲过很多各式各样的token(参见P3,Grapheme 字母汉字,Phoneme 音素,Morpheme 词根、缀,Word 词),但这些单位对HMM来说都太大了,HMM的输入并不是token sequence,而是把token sequence 转成 state sequence
也就把 P(X|Y) 转成了 P(X|S),S是state sequence。
而state sequence是什么呢?S是人为定义的,比Phoneme(发音的基本单位)还要小。
举例,请参见上图,假如我们有一段”what do you think“的语音段,我们会先根据Lexicon查表找出这段英文的Phoneme,接下来每一个Phoneme都会受到前后的内容影响,比如说这句中的do有wu的音,you也有wu的音,但同样的wu两者发音是不一样的,他们会受到前后Phoneme的影响,所以我们会用Tri-phone来细化,注意Tri-phone不是指三个phoneme连在一起,而是将现在的phoneme加上前后的phoneme,是把原来的一个phoneme切的更细。接下来,还有更小的单位,就是HMM所用到的S(state),我们通常假设每一个Tri-phoneme是由三个或五个state所构成(自己决定一个Tri-phoneme由多少个state组成,通常是三个或五个)。
2 S->X

在我们有了S后,我们该怎样构造数据,由S产生acoustic feature的X呢?
举例,假设我们有一段声音讯号X(长度为6),S 有 a b c
我们会先进入第一个state a里面,由a产生一些vector如X1、X2,接下来b产生一些vector,最后c。这便是由S产生X的过程,但要算**P(X|S)**的概率的话,我们还需要知道两种概率
- Transition Probability :从某一个state跳到另一个state的几率,如上图由黄色球跳到蓝色球的几率
- Emission Probability:给一个state,它产生某一个acoustic feature的几率有多大,如上图由黄色球生成紫色或红色vector的几率
3 Transition Probability & Emission Probability

这两个概率的计算方法请详见《数位语音处理》
Transition Probability,由前一个state跳到下一个state的概率。
Emission Probability,给定一个state,这个state产生某一个acoustic feature的概率。我们之所以可以有Emission Probability,是因为我们假设每一个state产生的声音讯号有一个固定的distribution概率分布,我们会用 GMM (Gaussian Mixture Model) 来表示这个概率分布。
提问:我们为什么还用比Phoneme(人类听识最小单位)还要小的单位state来当作HMM的输入,而不直接用Phoneme呢?
因为我们要假设如果人想要发这个state声音的时候,将这些声音讯号转成vector时,这些vector有一个固定的几率分布,我们会用GMM来表示这个几率分布。这也就是为什么之前,人们不使用类似Word词等当作token,因为同一个word,因上下文(如连读)人们发出这个词的声音讯号是很可能不一样的,不是固定的,也因此无法供HMM使用。
Emission Probability会遇到一个问题,那就是我们的state实在是太多了,Phoneme要转成Tri-phone,再由Tri-phone转成state

而在这些state中,我们的训练资料里可能一些state只出现一两次,这样非常 GMM的概率分布 ,所以过去有一个非常关键的技术,叫做Tied-state,它假设一些state的发音是一样的,让它们共用同样的Gaussian distribution。虽然两个state名字不一样,但它们可以共用同一个GMM。
像这样的技术,经过很多年研究,最终得到了Subspace GMM,之前人们会定义很多规则或通过统计来决定哪些state应该共用,而Subspace GMM 不再讨论哪些state共用,而是将全部的state都共用一个GMM,虽都共用同一个GMM,但不同的state的distribution可以不同,因为加入了一个Gaussian pool 来改变不同state的Gaussian。(2010)10年前这项技术是十分轰动的,而有趣的是,同一年同一个会议ICASSP Hinton发表的将deep learning用在语音辨识上的paper却没受到什么重视,当然也是因为他没有冲 state-of-the-art。
4 Probability P(X|S)

假设我们已经得到了 Transition Probability 和 Emission Probability ,那我们现在可以计算出 P(X|S)的概率了么?还是不能。我们还少了alignment,我们还必须知道每一个acoustic feature 是由哪一个state产生的。通常 输入的state sequence比较短,而输出的acoustic feature sequence 比较长,那我们该怎样对应在一起,这个东西就是alignment。
具体而言,参见上图,假设我们有三个state a b c,那我们该重复几次abc来产生x1 x2 x3 x4 x5 x6。我们可以设定为aabbcc -> x1 x2 x3 x4 x5 x6,当然也可以为 abbbbc -> x1 x2 x3 x4 x5 x6。其中如P(a|a)是由Transition Probability得到,P(x1|a)是由Emission Probability得到。把这些几率全部乘起来,我们就知道P(X|S)。当然alignment不同,算出的几率也不同,也因此我们穷举所有正确的alignment,算出的概率求和,就像上图的h∈align(S)。
III Deep Learning in HMM
将深度学习应用到语音辨识上,最早的想法都是在HMM基础上改进
1 Tandem

用Deep Learning来给我们比较好的acoustic feature,训练一个DNN,输入MFCC,去预测给定MFCC给出state的概率p(a|xi),接下把DNN的输出当成新的acoustic feature,然后同样输给HMM。
2 DNN-HMM Hybrid
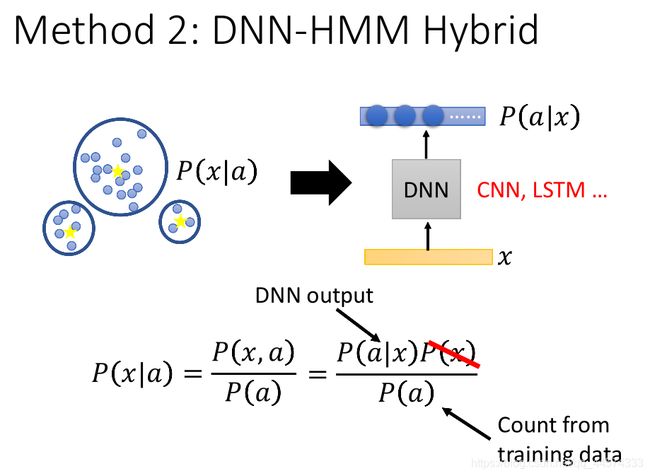
在HMM里面有Gaussian Mixture Model,我们用DNN来取代GMM。原来GMM计算的是给一个state输出acoustic feature vector(x)的概率,而DNN可以训练一个分类器,给一个x输出它是某一个state的几率。看起来这两件事情是相反的,但根据贝叶斯公式,详见上图,我们便可以通过DNN得到GMM的计算结果。

上述都是历史的回顾,下一篇将回到现在的End-to-End技术。