轻量型神经网络 shufflenet V1和shufflenet V2
1.shufflenet V1
ShuffleNet是旷视科技(Face++)提出的一种计算高效的CNN模型,其和MobileNet和SqueezeNet等一样主要是想应用在移动端 所以,ShuffleNet的设计目标也是如何利用有限的计算资源来达到最好的模型精度,这需要很好地在速度和精度之间做平衡。 在mobilenet v1中的核心操作是引入了深度可分离卷积,即通过对feature map的每个channel维度进行分组,分组数等于通道数, 然后通过1*1的卷积快进行通道之间信息的融合,防止通道信息无法进行交流。大的卷积核可以起到增大感受野的作用和在卷积操作的过程中代替池化层进行下采样。 而在shufflenet中的核心操作则是pointwise group convolution和channel shuffle,这在保持精度的同时大大降低了模型的计算量。其中group convolution和mobilenet中的depthwise convolution 类似,不过group convolution是认为的将feature map分成一定的group,然后再进行卷积,为防止通道信息的割裂,卷积完成之后进行channel shuffle,这也是shufflenet网络名称的由来。

其中channel shuffle的代码如下:
def channel_shuffle(x, groups):
# type: (torch.Tensor, int) -> torch.Tensor
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x如图b,c为shufflenet的基本模块,b模块不进行下采样,c模块进行下采样,通过b,c模块的堆叠便可得到shufflenet的结构。
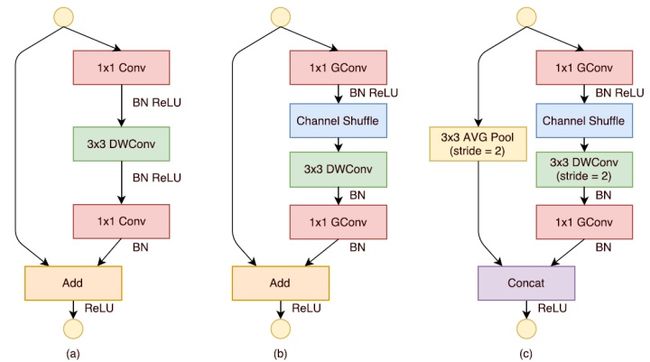
shufflenet v1基本模块
基于上面改进的ShuffleNet基本单元,设计的ShuffleNet模型如表1所示。可以看到开始使用的普通的3x3的卷积和max pool层。然后是三个阶段,每个阶段都是重复堆积了几个ShuffleNet的基本单元。对于每个阶段,第一个基本单元采用的是stride=2,这样特征图width和height各降低一半,而通道数增加一倍。后面的基本单元都是stride=1,特征图和通道数都保持不变。对于基本单元来说,其中瓶颈层,就是3x3卷积层的通道数为输出通道数的1/4,这和残差单元的设计理念是一样的。不过有个细节是,对于stride=2的基本单元,由于原输入会贡献一部分最终输出的通道数,那么在计算1/4时到底使用最终的通道数,还是仅仅未concat之前的通道数。文章没有说清楚,但是个人认为应该是后者吧。其中g控制了group convolution中的分组数,分组越多,在相同计算资源下,可以使用更多的通道数,所以g越大时,采用了更多的卷积核。

shufflenet v1网络结构图
2.shufflenet V2
shufflenet v2在v1的基础上通过大量的实验提出了四条设计轻量神经网络的准则:
(a)1x1卷积进行平衡输入和输出的通道大小;
(b)group convolution要谨慎使用,注意分组数;
(c)避免网络的碎片化;
网络碎片化会降低模型的额并行度 一些网络如Inception,它们倾向于采用“多路”结构,即存在一个block中很多不同的小卷积或者pooling, 这很容易造成网络碎片化,减低模型的并行度,相应速度会慢.
(d)减少元素级运算,
对于元素级(element-wise operators)比如ReLU和Add,虽然它们的FLOPs较小,但是却需要较大的MAC(memory access cost, MAC)。 实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话,速度有20%的提升。
在ShuffleNetv1的模块中,大量使用了1x1组卷积,这违背了b原则, 另外v1采用了类似ResNet中的瓶颈层(bottleneck layer), 输入和输出通道数不同,这违背了a原则。同时使用过多的组,也违背了c原则。 skip connection中存在大量的元素级Add运算,这违背了d原则。
根据前面的四条准则提出了shufflenet v2,为了改善v1的缺陷,v2版本在非下采样模块中引入了一种新的运算:channel split。具体来说,在开始时先将输入特征图在通道维度分成两个分支, 在论文和代码中的体现则是将特征图在channel维度上平均分成两部分.
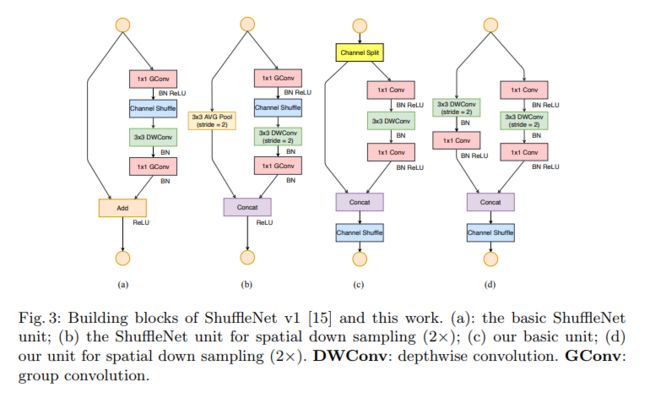
shufflenet v2基本模块图
shufflenet v2的pytorch实现代码如下:
#本来这个代码是要用在目标检测中的,之后和FPN级联所以输出了三个feature map,懒得修改了,一样能看
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
from nanodet.model.module.activation import act_layers
model_urls = {
'shufflenetv2_0.5x': 'https://download.pytorch.org/models/shufflenetv2_x0.5-f707e7126e.pth',
'shufflenetv2_1.0x': 'https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth',
'shufflenetv2_1.5x': None,
'shufflenetv2_2.0x': None,
}
def channel_shuffle(x, groups):
# type: (torch.Tensor, int) -> torch.Tensor
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
class ShuffleV2Block(nn.Module):
def __init__(self, inp, oup, stride, activation='ReLU'):
super(ShuffleV2Block, self).__init__()
if not (1 <= stride <= 3):
raise ValueError('illegal stride value')
self.stride = stride
branch_features = oup // 2
assert (self.stride != 1) or (inp == branch_features << 1)
if self.stride > 1:
self.branch1 = nn.Sequential(
self.depthwise_conv(inp, inp, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(inp),
nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
act_layers(activation),
)
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(inp if (self.stride > 1) else branch_features,
branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
act_layers(activation),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
act_layers(activation),
)
@staticmethod
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
class ShuffleNetV2(nn.Module):
def __init__(self,
model_size='1.5x',
out_stages=(2, 3, 4),
with_last_conv=False,
kernal_size=3,
activation='ReLU'):
super(ShuffleNetV2, self).__init__()
print('model size is ', model_size)
self.stage_repeats = [4, 8, 4]
self.model_size = model_size
self.out_stages = out_stages
self.with_last_conv = with_last_conv
self.kernal_size = kernal_size
self.activation = activation
if model_size == '0.5x':
self._stage_out_channels = [24, 48, 96, 192, 1024]
elif model_size == '1.0x':
self._stage_out_channels = [24, 116, 232, 464, 1024]
elif model_size == '1.5x':
self._stage_out_channels = [24, 176, 352, 704, 1024]
elif model_size == '2.0x':
self._stage_out_channels = [24, 244, 488, 976, 2048]
else:
raise NotImplementedError
# building first layer
input_channels = 3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, 3, 2, 1, bias=False),
nn.BatchNorm2d(output_channels),
act_layers(activation),
)
input_channels = output_channels#24
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
stage_names = ['stage{}'.format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(
stage_names, self.stage_repeats, self._stage_out_channels[1:]):
seq = [ShuffleV2Block(input_channels, output_channels, 2, activation=activation)]
for i in range(repeats - 1):
seq.append(ShuffleV2Block(output_channels, output_channels, 1, activation=activation))
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
output_channels = self._stage_out_channels[-1]
if self.with_last_conv:
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(output_channels),
act_layers(activation),
)
self.stage4.add_module('conv5', self.conv5)
self._initialize_weights()
def forward(self, x):
x = self.conv1(x)
x = self.maxpool(x)
output = []
for i in range(2, 5):
stage = getattr(self, 'stage{}'.format(i))
x = stage(x)
if i in self.out_stages:#[2,3,4]
output.append(x)
return tuple(output)
def _initialize_weights(self, pretrain=True):
print('init weights...')
for name, m in self.named_modules():
if isinstance(m, nn.Conv2d):
if 'first' in name:
nn.init.normal_(m.weight, 0, 0.01)
else:
nn.init.normal_(m.weight, 0, 1.0 / m.weight.shape[1])
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
if m.bias is not None:
nn.init.constant_(m.bias, 0.0001)
nn.init.constant_(m.running_mean, 0)
elif isinstance(m, nn.BatchNorm1d):
nn.init.constant_(m.weight, 1)
if m.bias is not None:
nn.init.constant_(m.bias, 0.0001)
nn.init.constant_(m.running_mean, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if pretrain:
url = model_urls['shufflenetv2_{}'.format(self.model_size)]
if url is not None:
pretrained_state_dict = model_zoo.load_url(url)
print('=> loading pretrained model {}'.format(url))
self.load_state_dict(pretrained_state_dict, strict=False)
if __name__ == "__main__":
model = ShuffleNetV2(model_size='1.0x', )
print(model)
test_data = torch.rand(5, 3, 320, 320)
test_outputs = model(test_data)
for out in test_outputs:
print(out.size())
reference:
1.https://zhuanlan.zhihu.com/p/32304419
2.https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1707.01083.pdf
3.https://zhuanlan.zhihu.com/p/48261931
4.https://arxiv.org/abs/1807.11164