挑战更高难度的多目标跟踪,MOT20数据集使用指南
上一期为大家介绍了多目标跟踪任务及其常用的数据集:多目标跟踪(MOT)数据集资源整理分享。其中最新发布的行人数据集MOT20,环境更复杂、人群更密集,任务难度更大。
这一期,给想挑战的朋友,详细介绍一下。
目录指引
1. 数据集简介
2. 数据集详细信息
3. 数据集任务定义及介绍
4. 数据集结构解读
5. 下载链接及可视化脚本
一、数据集简介
发布方:Dynamic Vision and Learning Group at TUM Munich, Germany
发布时间:2020
发布版本:MOT20
背景:相比于此前的多目标跟踪(multi-object tracking)数据集,MOT20关注人群密集的场景,其视频最多可达单帧 246 人。
二、数据集详细信息
1. 数据量及标注情况
数据集共包含 8 个视频片段,分别来自三个不同的场景,4 个视频片段用于训练,4 个视频片段用于测试。每个视频片段均以视频帧的形式提供,8 个视频片段总共包含 13410 帧,其中训练视频 8931 帧,测试视频 4479 帧。


数据集提供每个视频帧上的矩形框标注,其中测试数据的标注不公开。训练数据平均每帧包含 127.04 个行人(pedestrian)矩形框标注,测试数据平均每帧包含 115.52 个行人矩形框标注。

除了行人,数据集还包含其他类型的矩形框标注,如非移动交通工具(non motorized vehicle)等。在评测时仅考虑行人类型的标注,不考虑其他类型。
除了标注信息外,数据集作者在训练数据上训练了一个以 ResNet101 为 backbone 的 Faster R-CNN 作为 baseline,并提供训练和测试数据上逐帧检测行人的结果(注:在竞赛中,如果参赛者要使用基于检测的跟踪方法,只能使用官方提供的检测结果)。
2. 标注类别
数据集的标注包含以下五种标注类别:
● Pedestrian
● Non motorized vehicle
● Static person
● Occluder on the ground
● crowd
3. 可视化
下面是 MOT20-03 的原视频、标注结果、检测结果,平均每帧 130.42 个行人。
MOT20-03-raw(原视频)
MOT20-03(标注结果)
MOT20-03-det(检测结果)
三、数据集任务定义及介绍
多目标跟踪
● 任务定义
在给定的一段视频中识别与跟踪多个目标。(具体介绍可见:多目标跟踪(MOT)数据集资源整理分享)
● 评估
评估过程
在第  帧,ground truth 为
帧,ground truth 为 ![]() ,预测结果 hypothesis 为
,预测结果 hypothesis 为 ![]() ,其中每个
,其中每个  与每个
与每个 ![]() 都属于一个特定的轨迹,即可能已经出现在此前的若干帧中。
都属于一个特定的轨迹,即可能已经出现在此前的若干帧中。
对于 ![]() ,若交并比
,若交并比 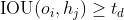 ,则二者可建立关联(relationship),其中
,则二者可建立关联(relationship),其中 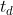 为预设的阈值,在 MOT20 中为
为预设的阈值,在 MOT20 中为 ![]() 。
。
若 ![]() 在第
在第 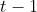 帧匹配(matched),且在第 帧可建立关联,则在第 帧直接进行匹配。
帧匹配(matched),且在第 帧可建立关联,则在第 帧直接进行匹配。
对于剩余未匹配的 ground truth 和 hypothesis,基于建立的关联关系,计算最大二分匹配。
仍未匹配的 ground truth 为 False Negative,仍未匹配的 hypothesis 为 False Positive。
若  与
与  匹配,且此前最近的一次匹配对象为
匹配,且此前最近的一次匹配对象为 ![]() ,则 在第 帧发生一次 identity switch (IDSW)。
,则 在第 帧发生一次 identity switch (IDSW)。
指标
MOT20 竞赛所用的评价指标:
https://motchallenge.net/results/MOT20/

四、数据集文件结构解读
1. 目录结构
dataset_root├── test # 测试数据│ ├── MOT20-04 # MOT20-04: 视频文件夹,存放一个视频的所有信息│ │ ├── det # Faster R-CNN 检测结果│ │ │ └── det.txt # Faster R-CNN 检测结果,每行一个行人矩形框检测结果│ │ ├── img1 # 媒体文件│ │ │ ├── 000001.jpg # 视频逐帧图片,图片名字为 6 位数字│ │ │ ├── 000002.jpg│ │ │ └── ...│ │ └── seqinfo.ini # 视频信息,包含时长、帧率、宽度、高度等│ ├── MOT20-06│ │ └── ...│ ├── MOT20-07│ │ └── ...│ └── MOT20-08│ └── ...└── train # 训练数据├── MOT20-01 # MOT20-01: 视频文件夹,存放一个视频的所有信息│ ├── det # Faster R-CNN 检测结果│ │ └── det.txt # Faster R-CNN 检测结果,每行一个行人矩形框检测结果│ ├── gt # 标注信息│ │ └── gt.txt # 标注信息,每行一个矩形框标注│ ├── img1 # 媒体文件│ │ ├── 000001.jpg # 视频逐帧图片,图片名字为 6 位数字│ │ ├── 000002.jpg│ │ └── ...│ └── seqinfo.ini # 视频信息,包含时长、帧率、宽度、高度等├── MOT20-02│ └── ...├── MOT20-03│ └── ...└── MOT20-05└── ...
2. 元信息格式
● seqinfo.ini 文件内容如下:
[Sequence]name=MOT20-01imDir=img1frameRate=25seqLength=429imWidth=1920imHeight=1080imExt=.jpg
3. 标注格式
● gt.txt 标注格式如下:
1,1,199,813,140,268,1,1,0.836432,1,201,812,140,268,1,1,0.840153,1,203,812,140,268,1,1,0.840154,1,206,812,140,268,1,1,0.840155,1,208,812,140,268,1,1,0.84015
每行包含九个字段,用逗号分隔,含义如下:
frame number:帧号
identity number:物体编号,同一物体在整个视频片段中具有唯一的编号
x_min:2D 矩形框左上角横坐标
y_min:2D 矩形框左上角纵坐标
width:2D 矩形框宽度
height:2D 矩形框高度
flag:当前标注在评估中是否被考虑,若 flag = 1,则考虑当前标注,若 flag = 0,则忽略。
category:标注物体类别 ID,数据集中出现的 ID 及对应类别包括:
1: Pedestrian
6: Non motorized vehicle
7: Static person
11: Occluder on the ground
13: crowd
visibility:物体可见程度,取值在 0~1 之间,有些物体会被遮挡,取值越低,遮挡越严重。
● det.txt 标注格式如下:
1,-1,757,692,96,209,1,-1,-1,-11,-1,667,682,100,222,1,-1,-1,-11,-1,343,818,127,258,1,-1,-1,-11,-1,806,524,71,172,1,-1,-1,-11,-1,196,814,141,265,1,-1,-1,-1
每行包含十个字段,用逗号分隔,前六个主要字段含义如下:
frame number:帧号
此字段恒为 -1
x_min:2D 矩形框左上角横坐标
y_min:2D 矩形框左上角纵坐标
width:2D 矩形框宽度
height:2D 矩形框高度
五、下载链接及可视化脚本
OpenDataHub平台已经上架了MOT20数据集,为大家提供了完整的数据集信息、流畅的下载速度、可视化脚本、快来体验吧!
1. MOT20数据集资源
https://opendatalab.com/70
2. MOT20数据集可视化
import argparse
import json
import os
import cv2
from itertools import count
from tqdm import tqdm
parse = argparse.ArgumentParser(description="Visualize MOT20 dataset of standard format")
parse.add_argument("--input_path", type=str, help="path of standard format dataset")
parse.add_argument("--output_path", type=str, help="path of output")
parse.add_argument("--fps", type=int, default=25, help="frames per second")
args = parse.parse_args()
def visualize_sub_dataset(sub_dataset_name, media, labels, ann_source):
for i, sequence in tqdm(enumerate(media), total=len(media), desc=f"{sub_dataset_name}-{ann_source}"):
visualize_sequence(sub_dataset_name, i, sequence, labels, ann_source)
def visualize_sequence(sub_dataset_name, seq_id, sequence, labels, ann_source):
frames = []
colors = ((243, 129, 129), (252, 227, 138), (234, 255, 208), (149, 225, 211))
color_id_gen = count()
instance2color = {}
for media_path in sequence:
media_label = labels[media_path]
frame = cv2.imread(os.path.join(args.input_path, media_path))
if "ground_truth" in media_label and "box2d" in media_label["ground_truth"]:
for bbox in media_label["ground_truth"]["box2d"]:
if bbox["attributes"]["source"] == ann_source:
x, y, w, h = list(map(int, bbox["bounding_box"]))
instance_id = bbox.get("instance_id", "0")
if instance_id not in instance2color:
instance2color[instance_id] = colors[next(color_id_gen) % len(colors)]
cv2.rectangle(frame, (x, y), (x + w, y + h), instance2color[instance_id])
frames.append(frame)
video_path = os.path.join(args.output_path, f"{sub_dataset_name}-{seq_id}-{ann_source}.mp4")
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video = cv2.VideoWriter(video_path, fourcc, args.fps, (frames[0].shape[1], frames[0].shape[0]))
for frame in frames:
video.write(frame)
def main():
if not os.path.isdir(args.output_path):
os.makedirs(args.output_path)
elif os.listdir(args.output_path):
raise OSError(f"Directory is not empty: '{args.output_path}'")
annotated_sub_datasets = ["train"]
with open(os.path.join(args.input_path, "dataset_info.json"), "r", encoding="utf8") as f:
dataset_info = json.load(f)
for sub_dataset_name, sub_dataset in dataset_info["data"].items():
media = sub_dataset["media"]
with open(os.path.join(args.input_path, sub_dataset["label"]), "r", encoding="utf8") as f:
labels = json.load(f)
labels = {ann["media"]: ann for ann in labels[sub_dataset_name]}
if sub_dataset_name in annotated_sub_datasets:
visualize_sub_dataset(sub_dataset_name, media, labels, "gt")
visualize_sub_dataset(sub_dataset_name, media, labels, "det")
if __name__ == "__main__":
main()参考资料:
[1]Dendorfer, P., Rezatofighi, H., Milan, A., Shi, J., Cremers, D., Reid, I., Roth, S., Schindler, K. & Leal-Taixé, L. MOT20: A benchmark for multi object tracking in crowded scenes. arXiv:2003.09003[cs], 2020., (arXiv: 2003.09003).
[2]https://motchallenge.net/data/MOT20/
更多数据集上架动态、更全面的数据集内容解读、最牛大佬在线答疑、最活跃的同行圈子……欢迎添加微信opendatalab_yunying 加入OpenDataLab官方交流群。