机器学习算法-决策树原理分析和源代码详解
机器学习算法-决策树原理分析和源代码详解
前言
上一篇文章我们介绍了KNN邻近算法,分析了这个算法的一些优缺点。这一篇,针对KNN无法理解数据内容的缺点,我们来介绍决策树。
源代码地址:决策树源代码地址
决策树理论分析
一、概念解释
决策树是将已有的数据,建立起来一个规则树。
举个例子吧,假如我们要开发一个垃圾邮件识别系统,我们来使用一个树状图来描述一下我们进行判断的过程:
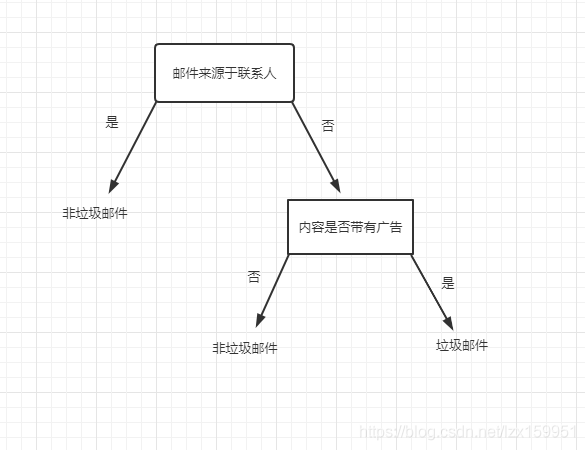
当然,我们判断邮件是否是垃圾邮件的规则有很多,我这里只是随便写了一个,当作一个例子。
当收到邮件时,我们会先看发邮件的是不是自己通讯录里面的人,如果是的话,即判定该邮件不是垃圾邮件。
如果不是联系人发来的邮件,我们需要点进去查看邮件内容进行判断,如果内容带有广告,那么可以判定该邮件是垃圾邮件,否则判定为非垃圾邮件。
这个思考过程我们很容易理解,因为这个过程正是我们从小到大认识、辨别事物的思考过程。
想想小时候你父母如何教你辨认猫狗的,通过不同的特征一步一步进行判定,有一些特征是非常明显的,我们通过该特征一下就能辨别,比如叫声。但是有些特征那个不太明显,比如体型、毛色等。
好了,如果你能理解上面我举得例子,那么,恭喜你,决策树的理论你也就明白了:我们就是从数据集的属性出发,不断地找出辨识度高的属性,来一步一步构建我们的思考过程。
二、信息熵、信息量
上面我们说到,需要不断找出辨识度高的属性,那么,如何进行判定哪个属性的辨识度最高呢,也就是说哪个属性能够更好的区分数据呢?我们首先来了解两个概念熵和信息
一件事情对于某人而言属于哪个类别的不确定性被称为熵
能够消除某人对这件事情的不确定性的叫做信息
我们数据中的属性值,可以理解为信息,它用来帮助我们取判断数据的归属问题,可以解决我们对于数据归属的不确定性。
还是拿动物举例,当我们知道这个动物是狗的话,此时这件事的熵为0。当我们没有获得任何信息,可以认为这个动物属于猫还是属于狗的概率一样,都是50%,此时,熵值最大。随着我们不断获取这个动物的一些属性特征,我们对于判断这个动物属于猫还是属于狗的概率会发生变化。
接下来我们看一下信息熵公式:

P是变量x的概率值。
当我们没有获取任何信息时,可以认为变量x的概率值一样,此时H1的值最大。
当我们获取到了一些信息,变量x的概率值发生了变化,此时H2的值相对上一个H1的值要小
当我们了解了许多信息,已经判断出了X的归属问题,此时Px=1 那么,H3的值为0
三、决策树是实现过程
上面我们介绍了信息熵的概念,这个概念比较抽象,我收集了一些比较容易理解地资料放在文末,大家可以去详细了解一下,不过只要是明白上面我说地,对于这一个算法就够用了。
- 通过计算信息熵,找到辨识度最大地属性
- 划分数据集
- 创建分支节点,创建决策树
- 不断循环1、2、3,,直到属性使用完毕或者数据中只剩下一种类型
这个过程看的是有点抽象,没关系,下面使用代码进行详细解释
决策树源代码解析
一、加载数据
def loadData(dataseturl):
dataset = []
with open(dataseturl) as f:
dataall = f.readlines()
for data in dataall:
dataline = data.strip().split('\t')
dataset.append(dataline)
#age(年龄)、prescript(症状)、astigmatic(是否散光)、tearRate(流泪程度)
labels=['age','prescript','astigmatic','tearRate']#四个属性
return dataset,labels
这里我们使用了《机器学习实战》所给的数据集,是关于推荐隐形眼镜类型的一个数据集。一共有四个属性,代码中注释已经给出每个属性的意义。
二、计算数据的信息熵
def calShannonEnt(dataset):
numEntries = len(dataset)
labelCounts={}
for data in dataset:
classlabel = data[-1]
if(classlabel not in labelCounts.keys()):
labelCounts[classlabel]=0
labelCounts[classlabel]+=1
shannonEnt=0.0
#print("labelCounts",labelCounts)
for key in labelCounts:
p = float(labelCounts[key])/numEntries
shannonEnt-= p*np.log2(p)
#print("shannoEnt:",shannonEnt)
return shannonEnt
计算信息熵公式上面咱们已经给出了,这里是以数据的所属分类作为计算事件,分类数量占比作为P概率值。
三、根据某一特征,划分数据集
#根据某一特征,划分数据集
def splitDataset(dataset,axis,value):#axis 属性的位置 value 返回数据属性值为value
retDataSet = []
for featVec in dataset:
if featVec[axis]==value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
# print("划分数据集:",retDataSet)
return retDataSet
axis 表示属性的位置,value表示属性值。这里就是按照某一属性的值对数据进行划分,就好像我们假设已经知道某一属性值,来显示满足这个属性值的数据。
四、选择最好的属性
def chooseBestFeatureToSplit(dataset):
numFeatures = len(dataset[0])-1 #计算特征数
baseEntropy = calShannonEnt(dataset)#计算信息熵
bestFeature = -1
bestInfoGain = 0
for i in range(numFeatures):#不断循环属性
featList = [example[i] for example in dataset]#获取数据集的第i个特征
uniqueVals = set(featList)#属性i的属性值有哪些
#print("uniqueVals",uniqueVals)
newEntropy = 0.0
for value in uniqueVals:#
subDataSet = splitDataset(dataset,i,value)#按照属性i和属性i的值value进行数据划分
#print("subDataSet",subDataSet)
prob = len(subDataSet)/float(len(dataset))
#print("calShannonEnt(subDataSet):",calShannonEnt(subDataSet))
newEntropy +=prob*calShannonEnt(subDataSet) #计算划分过数据集的信息熵
infoGain = baseEntropy-newEntropy#计算信息增益,也就是信息熵的变换量
#print("infogain",infoGain)
if(infoGain>bestInfoGain):
bestInfoGain = infoGain
bestFeature=i
# print("输出最好的属性",bestFeature)
return bestFeature
前面我们也有提到,如何判断哪个属性是分辨度最高的属性,就是通过计算信息熵来决定的,通过直到哪个属性 的取值,可以使此时数据的信息熵值最小,那么,这个属性就是最好的属性。
五、投票统一
def majorityCnt(classList):
classCount={ }
#这个是个非常常用得手段,用于统计各个值得个数
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
else:
classCount[vote]+=1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
在我们构建决策树的时候,会出现属性值全部使用完毕,但是此时数据集中的数据分类不统一,此时使用这个投票方法,将此时数据归类于类别数量最多的类别里。比如最后我剩下五组数据,其中三组类别为1,两组类别为2,那么,就将这五组数据归属于1类中。
六、构建决策树
def createTree(dataset,labels):#数据集和标签列表
classList =[example[-1] for example in dataset]#数据所属类得值
if classList.count(classList[0])==len(classList):#条件1:classList只剩下一种值
return classList[0]
if len(dataset[0])==1:#条件2:数据dataset中属性已使用完毕,但没有分配完毕
return majorityCnt(classList)#取数量多的作为分类
bestFeat = chooseBestFeatureToSplit(dataset)#选择最好的分类点,即香农熵值最小的
#print("bestFeat:",bestFeat)
labels2 = labels.copy()#复制一分labels值,防止原数据被修改。
bestFeatLabel = labels2[bestFeat]
myTree = {bestFeatLabel:{}}#选取获取的最好的属性作为
print("bestFeat:",bestFeat)
# labels.pop(bestFeat)
del(labels2[bestFeat])
featValues = [example[bestFeat] for example in dataset]#获取该属性下的几类值
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels2[:]#剩余属性列表
myTree[bestFeatLabel][value] = createTree(splitDataset(dataset,bestFeat,value),subLabels)
return myTree
这里我们通过字典来进行决策树的构建,形式如下:
{'tearRate': {'reduced': 'no lenses', 'normal': {'astigmatic': {'no': {'age': {'presbyopic': {'prescript': {'hyper': 'soft', 'myope': 'no lenses'}}, 'young': 'soft', 'pre': 'soft'}}, 'yes': {'prescript': {'hyper': {'age': {'presbyopic': 'no lenses', 'young': 'hard', 'pre': 'no lenses'}}, 'myope': 'hard'}}}}}}
这个可能看的有点懵逼,没关系,咱们把它转化成图像看看
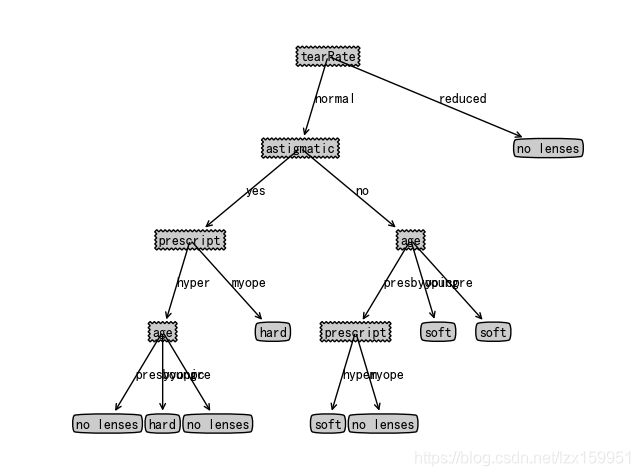
大家可以对照着字典里面的数据结合这个图片来理解一下。
七、决策树的存数和加载
#存储树---以二进制序列化进行存储
def storeTree(inputTree,filename):
fw = open(filename,'wb')
#这里pickle可以稍微详细说一下
pickle.dump(inputTree,fw)#存储
fw.close()
#加载存储的树 以二进制返回加载的序列化值
def grabTree(filename):
fr = open(filename,'rb')
return pickle.load(fr)#加载
这里使用python序列化,将决策树以二进制序列化存储到文件中,注意打开文件要加上‘b’。
八、使用决策树进行分类
def classify(inputTree,featLabels,testVec):
firstStr = list(inputTree.keys())[0]
# print("firststr",firstStr)
# print("featLabels",featLabels)
secondDic = inputTree[firstStr]#获取最外层字典里的值
featIndex = featLabels.index(firstStr)#获取最外层属性值在属性列表中的位置
for key in secondDic.keys():
if testVec[featIndex]==key:
if isinstance(secondDic[key],dict):
classLabel = classify(secondDic[key],featLabels,testVec)
else:
classLabel = secondDic[key]
return classLabel
前面我们已经构造好了我们的决策树,接下来使用我们已经构造好的决策树进行输入数据的分类。
从决策树的字典表达形式上来看,当值为字典形式时,表示里面还存在分类,从树的角度来说,此时这个值的树结点。当值不是字典形式时,表示该值时叶子节点,也就是此时已经完成了分类。
同上递归的形式,结合上面的判断条件,我们可以通过输入数据和已经构造好的决策树,进行数据的分类。
九、画图
上面那个树状图就是使用matplotlib画出来的,由于主要使学习算法,在这里就不再深入解释了,有兴趣的可以自己去琢磨一下。
知识点回味:
一、python中一切皆对象
之前有听说过,但是没有真正理解,直到碰到了这样一个例子:
def test():
test2()
def test2():
test.b=3
test2()
print(test.b)
[out]:3
从代码中,我们有两个方法,一个使test(),另外一个使test2()。不知道大家有没有注意到,test2方法中有一个变量,是test.b 这个变量不是别的,就是test()方法的变量,作用范围属于全局变量.
在python中,方法属于一种特殊的函数,使用方法名+.+变量名可以定义一个全局变量,好处呢,就是有辨识度,方便使用。
这个知识点出现在决策树的画图treePlotter.py文件中,大家看代码的时候注意一下。
二、可变对象和不可变对象
在python中,strings, tuples, 和 numbers 是不可更改的对象,而 **list,**dict 等则是可以修改的对象。
对于不可变对象,在进行赋值时,会产生一个新的对象。而在作为参数进行传递时,只是将值进行传递,不会影响值得本身。看下面这个例子:
a=1
print("第一个a的内存地址:",id(a))
a=2
print("第二个a的内存地址:",id(a))
def test(a):
a= a+1
print("第三个a的内存地址:",id(a))
test(a)
print("第四个a的内存地址:",id(a))
[out]:
第一个a的内存地址: 140717973873040
第二个a的内存地址: 140717973873072
第三个a的内存地址: 140717973873104
第四个a的内存地址: 140717973873072
id()是返回对象得内存地址,从结果中,我们能够看出,第一个a和第二个a是两个不同的对象,将第二个a作为参数传递时,对数据进行加1操作后,改变后的a有了新的内存地址,说明产生了新的对象,不再是传递过来的第二个a。最后输出的a是a=2的对象,因为test()方法并没有对原数据产生改变。
对于可变对象,进行赋值时,不会产生一个新得对象,会在原来数据上进行修改。在作为参数进行传递时,是真正得将对象进行传递,在方法内部对该对象进行修改,原数据也会被修改。
list1=[1,2,3,4,5]
print("输出原数据和内存地址:",list1,id(list1))
list1[0]=2
print("输出改变后的数据和内存地址",list1,id(list1))
def test(x):
x[0]=3
test(list1)
print("输出参数传递后的数据和内存地址:",list1,id(list1))
[out]:
输出原数据和内存地址: [1, 2, 3, 4, 5] 2223630012872
输出改变后的数据和内存地址 [2, 2, 3, 4, 5] 2223630012872
输出参数传递后的数据和内存地址: [3, 2, 3, 4, 5] 2223630012872
从上述例子中,我们发现这个list对象内存地址始终没有发生改变,说明在赋值或者参数传递过程中,使用的都是一个对象。
三、python的pickle序列化
pickle是python内置的一个序列化操作额工具包。
为什么要使用序列化进行存储?
pickle数据格式使用相对紧凑的二进制表示,能够很好的压缩数据,减小存储空间
其实对于决策树来说,如果你的数据属性不是太多,使用普通的文本形式也能够存储。
序列化操作:
使用dumps()函数,参数你所要序列化的对象
如果要写入文件中,要使用dump(),第一个参数是所要序列化的对象,第二个参数是文件对象
反序列操作:
loads()函数,参数是对象,返回值是经过反序列化转化的对象
load()函数,从文件中加载数据,并进行反序列化操作
参考资料:
- python函数基础
- 什么是信息熵
- pickle反序列化
- 《机器学习实战》
- 百度百科-信息熵
总结:
上面咱们介绍了决策树,通过大体上的介绍,决策树的优点非常明显,我们只需要进行依次决策树的构建,就可以针对不同的输入数据进行分类,计算量和空间占有量要远远小于KNN算法。
但是,有的时候我们希望模型告诉我们一个概率值,也就是一个可信度,并不希望直接告诉我们分类的结果。这个问题,将由下一个算法来解决-朴素贝叶斯。