决策树(信息熵、增益率、基尼指数)
目录
前言
一、决策树是什么?
二、实验过程
1.选择数据集中各个决策属性的优先级
1.1信息熵
1.2增益率
1.3基尼指数
2.决策树的构造
2.1创建决策树:
2.2准备数据:
2.3.读取和保存决策树:
2.4绘制决策树:
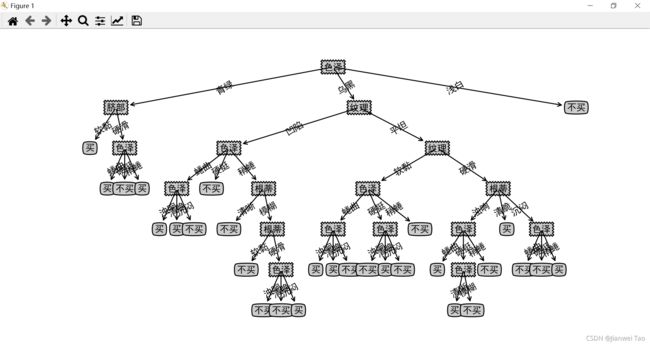
3运行结果:
3.1利用信息熵进行构造
3.2利用增益率进行构造决策树:
3.3利用基尼指数进行构造决策树:
总结
前言
决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
一、决策树是什么?
决策树(decision tree):是一种基本的分类与回归方法,此处主要讨论分类的决策树。
决策树通常有三个步骤:特征选择、决策树的生成、决策树的修剪。
用决策树分类:从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点,此时每个子节点对应着该特征的一个取值,如此递归的对实例进行测试并分配,直到到达叶节点,最后将实例分到叶节点的类中。
例图:

二、实验过程
1.选择数据集中各个决策属性的优先级
一个数据拥有非常多的属性,选择各个属性在决策树节点中的优先级变得尤为重要,决策树学习的关键在于如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点 所包含的样本尽可能属于同一类别,即结点的“纯度 ”(purity)越来越高 。
1.1信息熵
1948年,香农提出了“信息熵”的概念,解决了对信息的量化度量问题。信息熵这个词是C.E.Shannon(香农)从热力学中借用过来的。香农用信息熵的概念来描述信源的不确定度。

Ent(D)的值越小,则D的纯度越高
#计算给定数据集的香农熵
def calcShannonEnt(dataSet):
# 返回数据集的行数,样本容量
numEntries = len(dataSet)
# 保存每个标签出现出现次数的字典
labelCounts = {}
#对每组特征向量进行统计
for featVec in dataSet:
#提取标签(label)信息
currentLabel = featVec[-1]
#如果存在标签没有放入统计次数的字典,则将其添加
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
#label计数
labelCounts[currentLabel] += 1
#香农熵赋初值
shannonEnt = 0.0
for key in labelCounts:
#选择该标签的概率
prob = float(labelCounts[key])/numEntries
shannonEnt -=prob * log(prob,2)
return shannonEnt
1.2增益率
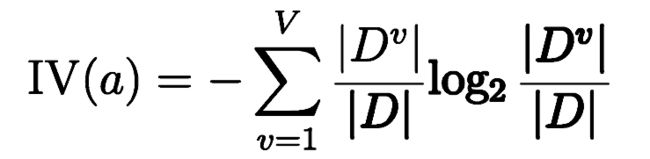
#信息增益率
def chooseBestFeatureToSplit2(dataSet): #使用信息增益率进行划分数据集
numFeatures = len(dataSet[0]) -1 #最后一个位置的特征不算
baseEntropy = calcShannonEnt(dataSet) #计算数据集的总信息熵
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
newEntropyProb = calcShannonEnt1(featList, method='prob') #计算内部信息增益率
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# 通过不同的特征值划分数据子集
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob *calcGini(subDataSet)
newEntropy = newEntropy*newEntropyProb
infoGain = baseEntropy - newEntropy #计算每个信息值的信息增益
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature #返回信息增益的最佳索引1.3基尼指数
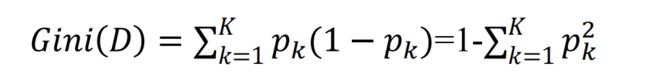
Gini(D)越小,数据集D的纯度越高;
#基尼指数
def calcGini(dataset):
feature = [example[-1] for example in dataset]
uniqueFeat = set(feature)
sumProb =0.0
for feat in uniqueFeat:
prob = feature.count(feat)/len(uniqueFeat)
sumProb += prob*prob
sumProb = 1-sumProb
return sumProb
def chooseBestFeatureToSplit3(dataSet): #使用基尼系数进行划分数据集
numFeatures = len(dataSet[0]) -1 #最后一个位置的特征不算
bestInfoGain = np.Inf
bestFeature = 0.0
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# 通过不同的特征值划分数据子集
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob *calcGini(subDataSet)
infoGain = newEntropy
if(infoGain < bestInfoGain): # 选择最小的基尼系数作为划分依据
bestInfoGain = infoGain
bestFeature = i
return bestFeature #返回决策属性的最佳索引2.决策树的构造
2.1创建决策树:
#创建决策树
def createTree(dataSet,labels):
#取分类标签
classList = [example[-1] for example in dataSet]
#特征可能存在多个属性,需要判断一下,如果类别完全相同则停止继续划分
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList) #遍历完所有特征时返回出现次数最多的类标签
bestFeat = chooseBestFeatureToSplit(dataSet) #选择最优特征
bestFeatLabel = labels[bestFeat] #最优特征的类标签
myTree = {bestFeatLabel:{}} #根据最有特征的标签生成树
#del(labels[bestFeat]) #删除已经使用特征标签
#得到训练集中所有最优特征的属性值
featValues = [example[bestFeat] for example in dataSet]
#去掉重复的属性值
uniqueVals = set(featValues)
#遍历特征,创建决策树
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree#使用决策树的分类函数
def classify(inputTree,featLabels,testVec):
#firstStr = next(iter(inputTree)) #获取决策树结点
firstStr = list(inputTree.keys())[0]
#print(firstStr)
secondDict = inputTree[firstStr] #下一个字典
featIndex = featLabels.index(firstStr) #获取存储选择的最优特征标签的索引
classLabel = -1
for key in secondDict.keys():
if testVec[featIndex] == key:
# 测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else:
classLabel = secondDict[key]
# 标记classLabel为-1当循环过后若仍然为-1,表示未找到该数据对应的节点则我们返回他兄弟节点出现次数最多的类别
if classLabel == -1:
return (getLeafBestCls(inputTree))
else:
return classLabel
#求该节点下所有叶子节点的列表
def getLeafscls(myTree, clsList):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
clsList =getLeafscls(secondDict[key],clsList)
else:
clsList.append(secondDict[key])
return clsList
#返回出现次数最多的类别
def getLeafBestCls(myTree):
clsList = []
resultList = getLeafscls(myTree,clsList)
return max(resultList,key = resultList.count)
2.2准备数据:
准备数据作为决策树的判断构造数据
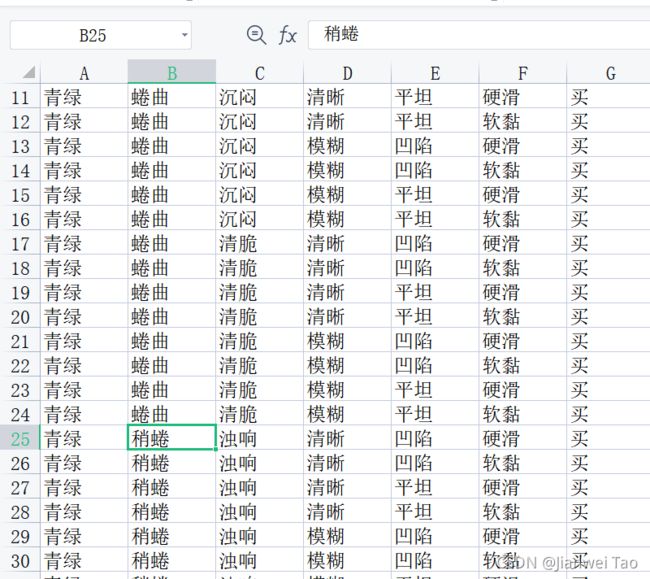
准备测试数据
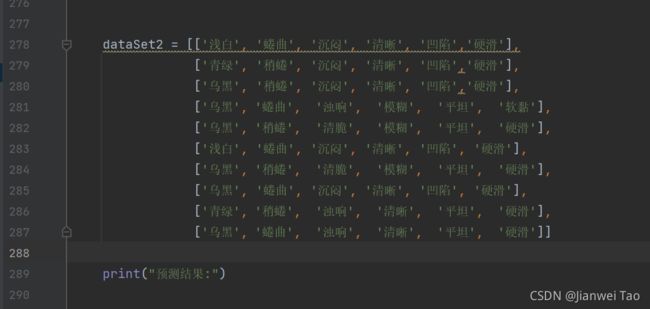
2.3.读取和保存决策树:
myData = pd.read_excel('data.xls',header = None)def storeTree(inputTree, filename):
import pickle
fw = open(filename, 'wb')
pickle.dump(inputTree, fw)
fw.close()
#读取决策树
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr) #决策树字典存储和读取决策树
2.4绘制决策树:
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt): # if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) # this determines the x width of this tree
depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0] # the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) # no ticks
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW;
plotTree.yOff = 1.0;
plotTree(inTree, (0.5, 1.0), '')
plt.show()
def retrieveTree(i):
listOfTrees = [{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
]
return listOfTrees[i]3运行结果:
3.1利用信息熵进行构造

准确率:40%
3.2利用增益率进行构造决策树:
预测结果:
准确率:40%
3.3利用基尼指数进行构造决策树:

预测结果:
准确率:40%
总结
在本次实验中由于数据集是自己编写的,导致了对于决策树的预测结果全是不买,对于信息熵、信息增益率,基尼指数三种划分方式的对数据划分的准确率,也不能作出比较,对于划分方式的优缺比较:
1.信息熵H(p)随概率p变化的曲线
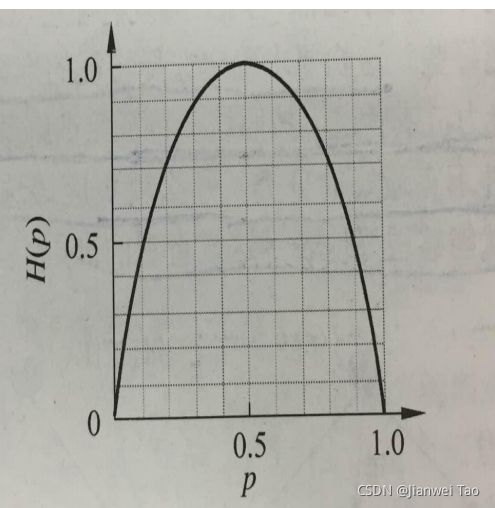
由图可知,当p=0或p=1时,H(p)=0,随机变量完全没有不确定性;
所以信息熵无法处理连续特征,容易过拟合。
2.信息增益对可取值数目较多的属性有所偏好;
3.基尼指数可以结合二叉树的特点,处理连续型特征和做回归。