结构化数据 神经网络
介绍 (Introduction)
As many of us are no doubt aware, the invariable progress made in the field of Computer Vision, has lead to some incredible achievements and broad deployment in fields from healthcare and self-driving cars, to climate study, to name but a few. From state-of-the-art Liquid Nitrogen cooled hardware in the form of Tensor Processing Units (TPU) to increasingly sophisticated, multi-million parameter Deep-Convolutional Networks such as GoogLeNet, AlexNet the capability of such technology continues to break previously unassailable barriers.
众所周知,我们许多人都知道,计算机视觉领域的不断进步已经带来了令人难以置信的成就,并在医疗保健和自动驾驶汽车,气候研究等领域广泛部署。 从采用Tensor处理单元(TPU)形式的最新液氮冷却硬件到日趋复杂,数百万个参数的深层卷积网络(如GoogLeNet) , AlexNet的能力不断突破以前无法克服的障碍。
对抗漏洞 (Adversarial Vulnerability)
Despite these incredible achievements, however, it has been proven that even the most skilful models are not infallible. Multiple research efforts have demonstrated how sensitive these models are to even imperceivably small changes in the input data structure. Initially in the findings of the joint research paper by Google and New York University: ‘Intriguing properties of neural networks, 2014’ the subject of model vulnerability to adversarial examples is now recognised as a subject of such importance that competitions now exist to tackle it:
尽管取得了这些令人难以置信的成就,但事实证明,即使是最熟练的模型也不是绝对可靠的。 多项研究表明,这些模型对输入数据结构中很小的变化甚至多么难以置信。 最初在Google和纽约大学的联合研究论文的发现中: “神经网络的有趣特性,2014年” ,对抗性示例的模型脆弱性这一主题现在被认为是具有如此重要意义的主题,因此现在存在竞争来解决这个问题:
The existence of these errors raises a variety of questions about out-of-sample generalization, and how the use of such examples might be used to abuse deployed systems.
这些错误的存在引发了关于样本外泛化以及如何使用此类示例来滥用已部署系统的各种问题。
神经结构学习 (Neural Structured Learning)
In some applications, these errors might not arise intentionally, moreover, they can arise as a result of human error or simply as a result of input instability. In the mining industry, computer vision has innumerable, highly useful applications, from streaming processing plant conveyor belt imagery in order to predict ore purity for example, to detecting commodity stockpile levels and illegal shipping/mining using satellite imagery.
在某些应用中,这些错误可能不是有意产生的,而且可能是由于人为错误或仅由于输入不稳定而引起的。 在采矿业中,计算机视觉具有无数的,非常有用的应用程序,从流处理厂的传送带图像以预测矿石纯度,到检测商品库存水平和使用卫星图像进行非法运输/采矿,都非常有用。
Quite often we find that such image data is corrupted during collection, as a result of camera misalignment, vibrations or simply very unique out-of-sample examples that can lead to misclassification.
我们经常发现,由于相机未对准,振动或非常独特的样本外示例(可能导致分类错误),此类图像数据在收集过程中被破坏。
In order to overcome examples such as these and generally improve our models against corrupt or perturbed data, we can employ a form of Neural Structured Learning called Adversarial Regularization.
为了克服此类示例并总体上改进针对损坏或受干扰数据的模型,我们可以采用一种 称为 对抗性正则化 的 神经结构学习 形式 。
Neural Structured Learning (NSL) is a relatively new, open-source framework developed by the good folks at TensorFlow for training deep neural networks with structured signals (as opposed to the conventional single sample). NSL implements Neural Graph Learning, in which a neural network is trained using graphs (see image below) which carry information about both a target (node) and neighbouring information in other nodes connected via node edges.
神经结构学习(NSL) 是TensorFlow的优秀人员开发的一种相对较新的开源框架,用于用结构化信号(与传统的单个样本相反)来训练深度神经网络。 NSL实现了“ 神经图学习” ,其中使用图 (参见下图)训练神经网络,该图携带有关目标(节点)的信息以及通过节点边缘连接的其他节点中的邻近信息。
In doing so, this allows the trained model to simultaneously exploit both labelled and unlabelled data through:
这样一来,经过训练的模型就可以通过以下方式同时利用标记和未标记的数据:
- Training the model on labelled data (standard procedure in any supervised learning problem); 在标签数据上训练模型(任何监督学习问题中的标准程序);
- Biasing the network to learn similar hidden representations for neighbouring nodes on a graph (with respect to the input data labels) 偏向网络以了解图上相邻节点的相似隐藏表示(相对于输入数据标签)
Consistent with point two, we can observe in the above expression both the minimisation of the empirical loss i.e. the supervised loss, and the neighbour loss. In the above example, this is computed as the dot product of the computed weight vector within a target hidden layer, and the distance measure (i.e. L1, L2 distance) between the input, X, and the same input with some degree of noise added to it:
与第二点一致,我们可以在上面的表达式中观察到经验损失(即监督损失)和邻居损失的最小化。 在上面的示例中,这被计算为目标隐藏层内计算出的权重矢量与输入X和同一输入之间的距离测度(即L1,L2距离)的点积,并添加了一定程度的噪声对此:
Adversarial examples are typically created by computing the gradient of the output with respect to the input, x_i, and then maximizing the loss. For example, where you have a model that classifies Chihuahuas and muffins, and you wish to create adversarial examples, you would input a 128 x 128 pixel Chihuahua image into your network, compute the gradient of the loss w.r.t. the input (a 128 x 128 tensor), then add the negative gradient (perturbation) to your image until the network classifies the image as a muffin. By training on these generated images again with the correct label, the network becomes more robust to noise/perturbation.
通常通过计算输出相对于输入x_i的梯度,然后最大化损耗来创建对抗性示例。 例如,如果您有一个模型将奇瓦瓦狗和松饼分类,并且希望创建对抗性示例,则可以将128 x 128像素的奇瓦瓦狗图像输入到您的网络中,计算输入的损失梯度(128 x 128张量),然后向图像添加负梯度(摄动),直到网络将图像分类为松饼。 通过再次使用正确的标签对这些生成的图像进行训练,网络对噪声/摄动变得更加健壮。
为什么要使用NSL? (Why use NSL?)
Higher accuracy: the structured signal(s) among samples can provide information that is not always available in feature inputs.
更高的精度 :样本之间的结构化信号可以提供在功能输入中并不总是可用的信息。
Greater Robustness: models trained with adversarial examples are demonstrably more robust against adversarial perturbations designed for misleading a model’s prediction or classification.
更高的鲁棒性 :用对抗性示例训练的模型对于针对误导模型的预测或分类而设计的对抗性扰动显然更鲁棒 。
Less labelled data required: NSL enables neural networks to harness both labelled and unlabelled data, forcing the network to learn similar hidden representations for “neighbouring samples” that may or may not have labels.
所需标签数据更少 :NSL使神经网络能够利用标签数据和未标签数据,从而迫使网络学习可能带有或不带有标签的“相邻样本”的类似隐藏表示。
对抗规则化 (Adversarial Regularisation)
What can we do if do not have such explicit structures as inputs?
如果没有诸如输入之类的显式结构怎么办?
What is particularly useful about TensorFlows Neural Structured Learning library is the provision of methods that enable users to dynamically construct induced adversarial examples as implicit structures from raw input data, through adversarial perturbation. This generalisation of NSL is known as Adversarial Regularisation, where adversarial examples are constructed to intentionally confuse the model during training, resulting in models that are robust against small input perturbations.
TensorFlows神经结构学习库特别有用的是提供了一些方法,这些方法使用户能够通过对抗性扰动从原始输入数据中动态地将诱导性对抗性示例构造为隐式结构。 NSL的这种概括称为“ 对抗性正规化”,在此过程中构造了对抗性示例以在训练过程中有意混淆该模型,从而使模型可以抵抗较小的输入扰动。
对抗性正规化实践 (Adversarial Regularisation In Practice)
In the following example, we are going to compare the performance of a baseline image classification model (specifically, a Convolutional Neural Network), against a variant that utilises adversarial regularisation. Unfortunately, we cannot demonstrate the use of AR on any of the aforementioned mining data, as this is proprietary.
在下面的示例中,我们将比较基准图像分类模型(特别是卷积神经网络)与采用对抗正则化的变体的性能。 不幸的是,由于这是专有的,因此我们无法证明在上述任何挖掘数据上使用AR。
We will instead perform this analysis for two models trained on a renowned image classification dataset — Beans. We will compare the results of the baseline model, versus one trained on adversarial examples in order to fully comprehend the effect that adversarial regularisation has on the ability and performance of each model.
相反,我们将对在著名的图像分类数据集Beans上训练的两个模型执行此分析。 我们将比较基准模型的结果和一个经过对抗性例子训练的模型的结果,以便全面理解对抗性正则化对每个模型的能力和性能的影响。
The Colab notebook containing the code used in this article can be found here. An excellent tutorial, where the inspiration for this article and where some of the code originated from, can be found on the TensorFlow NSL page.
包含本文使用的代码的Colab笔记本可在此处找到。 可以在TensorFlow NSL页面上找到一个出色的教程,该教程是本文的灵感来源以及其中的一些代码。
Before we get started, we must first install TensorFlow’s Neural Structured Learning package:
在开始之前,我们必须首先安装TensorFlow的神经结构学习包:
!pip install neural_structured_learning进口货 (Imports)
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import keras_preprocessing
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_datasets.public_api as tfdsfrom tensorflow.keras import models
from keras_preprocessing import image
from keras_preprocessing.image import ImageDataGenerator加载和检查图像数据 (Load & Inspect Image Data)
TensorFlow hosts a number of renowned datasets within its TensorFlow Datasets collection.
TensorFlow在其TensorFlow Datasets集合中托管了许多著名的数据集 。
We can load the Beans dataset that we want to train our model on using the tfds.load() method, which performs two operations:
我们可以使用tfds.load()方法加载要在其上训练模型的Beans数据集,该方法执行两个操作:
Downloads the dataset and save it as
tfrecordfiles.下载数据集并将其另存为
tfrecord文件。Loads the
tfrecordfiles and returns an instance oftf.data.Dataset加载
tfrecord文件并返回tf.data.Dataset的实例
# load dataset
dataset = 'beans' #@paramdataset = tfds.load(dataset, shuffle_files=True)
train, test = dataset['train'], dataset['test']IMAGE_INPUT_NAME = 'image'
LABEL_INPUT_NAME = 'label'Prior to performing any image scaling or image augmentation/perturbation, we can inspect a sample of the images within the dataset to gain an understanding of the various structures and compositions that a Convolutional layer might pick up as a feature(s), and to understand the differences between the various classes within the dataset:
在执行任何图像缩放或图像增强/摄动之前,我们可以检查数据集中的图像样本,以了解卷积层可能会拾取的各种结构和构图,并了解数据集中各个类之间的差异:
# Get random batch
raw_images = train.take(10)# Tensor to np format
raw_images = [item['image'] for item in
raw_images.as_numpy_iterator()]# Plot batch
fig = plt.gcf()
fig.set_size_inches(10, 10)
for i, img in enumerate(raw_images):
sp = plt.subplot(2, 5, i+1)
sp.axis('Off')
plt.imshow(img)plt.show()By default, the tf.data.Dataset object contains a dict of tf.Tensors. We can iterate over the batch of images (the tf.data.Dataset key values) by calling .as_numpy_iterator() on our raw_images within our list comprehension. This method returns a generator which converts the batch elements of the dataset from a tf.Tensorto np.array format. We can then plot the resulting batch of images:
默认情况下, tf.data.Dataset对象包含tf.Tensor的dict 。 我们可以通过在列表理解范围内对raw_images调用.as_numpy_iterator()来迭代图像批处理(tf.data.Dataset键值)。 此方法返回一个生成器,该生成器将数据集的批处理元素从tf.Tensor为np.array格式。 然后,我们可以绘制生成的图像批次:
前处理 (Preprocessing)
We perform a simple scaling operation on our image data to map the inputs to a float tensor between 0 and 1 (the Beans dataset is a collection of 500 x 500 x 3 images). Helpfully, TDFS datasets store feature attributes as Dictionaries:
我们对图像数据执行简单的缩放操作,以将输入映射到0到1之间的浮点张量(Beans数据集是500 x 500 x 3图像的集合)。 有用的是,TDFS数据集将要素属性存储为字典:
FeaturesDict({
'image': Image(shape=(500, 500, 3), dtype=tf.uint8),
'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=3),
})As a result, we can access the individual images and their labels and perform these preprocessing ops in-place with the .map() attribute of our train and test tf.Dataset instances:
结果,我们可以访问单个图像及其标签,并使用我们的训练和测试tf.Dataset实例的.map()属性就地执行这些预处理操作:
def normalize(features):
"""Scale images to within 0-1 bound based on max image size."""
features[IMAGE_INPUT_NAME] = tf.cast(
features[IMAGE_INPUT_NAME],
dtype=tf.float32) / 500.0)
return featuresdef examples_to_tuples(features):
return features[IMAGE_INPUT_NAME], features[LABEL_INPUT_NAME]def examples_to_dict(image, label):
return {IMAGE_INPUT_NAME: image, LABEL_INPUT_NAME: label}# Define train set, preprocess. (Note: inputs shuffled on load)
train_dataset = train.map(normalize)
.batch(28)
.map(examples_to_tuples)test_dataset = test.map(normalize)
.batch(28)
.map(examples_to_tuples)The function examples_to_dict will be explained shortly.
稍后将说明函数examples_to_dict 。
基准模型 (Baseline Model)
We then build a simple, baseline convolution neural network model, and fit it to our image data:
然后,我们建立一个简单的基线卷积神经网络模型,并将其拟合到我们的图像数据中:
def conv_nn_model(img_input_shape: tuple) -> tf.keras.Model():
"""Simple Conv2D Neural Network.
Args:
img_input_shape: An (mxnxo) tuple defining the input image
shape.
Returns:
model: An instance of tf.keras.Model.
"""
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu',
input_shape=input_shape),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
# Note to adjust output layer for number of classes
tf.keras.layers.Dense(3, activation='softmax')])
return model# Beans dataset img dims (pixel x pixel x bytes)
input_shape = (500, 500, 3)# Establish baseline
baseline_model = conv_nn_model(input_shape)
baseline_model.summary()baseline_model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])baseline_history = baseline_model.fit(
train_dataset,
epochs=5)results = baseline_model.evaluate(test_dataset)
print(f'Baseline Accuracy: {results[1]}')3/3 [==============================] - 0s 72ms/step - loss: 0.1047 - acc: 0.8934
Baseline Accuracy: 0.8934375We can see that our baseline model has performed well on the test dataset, achieving 89% accuracy.
我们可以看到我们的基线模型在测试数据集上表现良好,达到了89%的准确性。
对抗正则化模型 (Adversarial Regularization Model)
We will now examine how this model performs against a test set that includes adversarially perturbed examples, and pitch it against a model trained on a dataset that includes said examples. We proceed by first creating another convolutional NN model, only this time we will incorporate adversarial training into its training objective.
现在,我们将针对包含对抗性示例的测试集检查该模型的性能,并将其与在包含所述示例的数据集上训练的模型进行比较。 我们首先创建另一个卷积神经网络模型,只是这次我们将对抗性训练纳入其训练目标。
Next, using TensorFlow’s NSL framework, we define a config object with NSL’s helper function, nsl.configs.make_adv_reg_config :
接下来,使用TensorFlow的NSL框架,使用NSL的辅助函数nsl.configs.make_adv_reg_config定义一个配置对象:
#@title ADV Regularization Config# Create new CNN model instance
base_adv_model = build_base_model(input_shape)# Create AR config object
adv_reg_config = nsl.configs.make_adv_reg_config(
multiplier=0.2,
adv_step_size=0.2,
adv_grad_norm='infinity')# Model wrapper
adv_reg_model = nsl.keras.AdversarialRegularization(
base_adv_model,
label_keys=[LABEL_INPUT_NAME],
adv_config=adv_config)We can note that this function requires us to set a number of Hyperparameters. Some of these do not require explicit values, others require our input:
我们可以注意到,此函数要求我们设置一些超参数。 其中一些不需要显式的值,其他一些则需要我们的输入:
multiplier: The weight of the adversarial loss relative to the labelled loss during training, w.r.t our AR model’s objective function. We apply 0.2 as the regularization weight.multiplier:在训练过程中对抗损失相对于标记损失的权重,带有我们的AR模型的目标函数。 我们将0.2作为正则化权重。adv_step_size: The degree/magnitude of adversarial perturbation to be applied during training.adv_step_size:训练期间要应用的对抗性扰动的程度/大小。adv_grad_norm: The Tensor norm (L1 or L2) to normalize the gradient i.e A measure of the magnitude of the adversarial perturbation. Defaults to L2.adv_grad_norm:将梯度标准化的张量范数(L1或L2),即对抗性扰动幅度的度量。 默认为L2。
We can then wrap our newly created model using the nsl.keras.AdversarialRegularization function, which will add the adversarial regularization we configured earlier with our adv_reg_configobject to the training objective (the loss function to be minimised) of our base model.
然后,我们可以使用nsl.keras.AdversarialRegularization函数包装新创建的模型,该函数会将先前使用adv_reg_config对象配置的对抗性正则化添加到基本模型的训练目标(将损失函数最小化)中。
An important point to note at this stage is that our model expects its input to be a dictionary mapping of feature names to feature values. One can see that when we instantiate our adversarial model, we must pass in label_keys as a parameter. The enables our model to distinguish between input data and target data. Here, we can use our examples_to_dict function and map it to our training and test datasets:
在此阶段需要注意的重要一点是,我们的模型期望其输入是特征名称到特征值的字典映射 。 可以看到,当我们实例化对抗模型时,我们必须传递label_keys作为参数。 这使我们的模型能够区分输入数据和目标数据 。 在这里,我们可以使用examples_to_dict函数并将其映射到我们的训练和测试数据集:
train_set_for_adv_model = train_dataset.map(convert_to_dictionaries)
test_set_for_adv_model = test_dataset.map(convert_to_dictionaries)we then compile, fit and evaluate our adversarially regularised model as normal:
然后,我们像往常一样编译,拟合和评估我们的对抗正则化模型:
4/4 [==============================] - 0s 76ms/step - loss: 0.1015 - sparse_categorical_crossentropy: 0.1858 - sparse_categorical_accuracy: 0.8656 - scaled_adversarial_loss: 0.1057 accuracy: 0.911625Similarly, our adversarially regularised model generalises well to our test dataset, achieving similar accuracy (0.91%) to that of our baseline_model.
同样,我们的对抗式正则化模型可以很好地推广到我们的测试数据集,达到与baseline_model相似的准确性(0.91%)。
针对平均扰动数据的评估 (Evaluation Against Adverarially Perturbed Data)
Now for the interesting part.
现在开始有趣的部分。
In much the same way that one would evaluate a trained model’s ability on a test set, we shall perform the same operation on our two models. In this instance, however, we will compare our two models; the baseline CNN, and the variant that has been trained on adversarially-perturbed input data against a test dataset containing adversarially perturbed examples.
就像在测试集上评估训练模型的能力一样,我们将在两个模型上执行相同的操作。 但是,在这种情况下,我们将比较两个模型。 基线CNN,以及已针对包含对抗性示例的测试数据集在对抗性输入数据上进行过训练的变体。
In order to generate the aforementioned examples, we must first create a reference model, whose configuration (losses, metrics and calibrated/learned weights) will be used to generate perturbed examples. To do so, we once again wrap our performance baseline model with the nsl.keras.AdversarialRegularization function and compile it. Note that we do not fit this model to our dataset — we want to retain the same learned weights as our base model):
为了生成上述示例,我们必须首先创建一个参考模型,该模型的配置(损耗,度量和校准/学习的权重)将用于生成受干扰的示例。 为此,我们再次使用nsl.keras.AdversarialRegularization函数包装性能基准模型并对其进行编译。 请注意,我们并未将此模型适合我们的数据集-我们希望保留与基本模型相同的学习权重 ):
reference_model = nsl.keras.AdversarialRegularization(
baseline_model,
label_keys=[LABEL_INPUT_NAME],
adv_config=adv_reg_config)reference_model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])If at this point you are like me and like to understand the logic behind these things, you can find the source code containing the adversarial regularization class here.
如果此时您像我一样并且喜欢了解这些东西背后的逻辑,则可以在此处找到包含对抗性正则化类的源代码 。
We then store our two models; the baseline and the adversarially regularized variant in a dictionary, and subsequently loop over each batch of our test dataset (evaluation in batches is a requirement of the AdversarialRegularization model).
然后,我们存储两个模型; 基准和对抗式正则化变体在字典中,然后循环遍历我们的测试数据集的每批(按批评估是AdversarialRegularization模型的要求)。
With the .perturb_on_batch() method of our newly wrapped reference_model, we can generate adversarially perturbed batches consistent with our adv_reg_config object, and evaluate the performance of our two models on them:
使用我们新包装的reference_model的.perturb_on_batch()方法,我们可以生成与adv_reg_config对象一致的对抗性干扰的批次,并在它们上评估我们两个模型的性能:
labels, y_preds = [], []# Generate perturbed batches,
for batch in test_set_for_adv_model:
perturbed_batch = reference_model.perturb_on_batch(batch)
perturbed_batch[IMAGE_INPUT_NAME] = tf.clip_by_value(
perturbed_batch[IMAGE_INPUT_NAME], 0.0, 1.0)
# drop label from batch
y = perturbed_batch.pop(LABEL_INPUT_NAME)
y_preds.append({})
for name, model in models_to_eval.items():
y_pred = model(perturbed_batch)
metrics[name](y, y_pred)
predictions[-1][name] = tf.argmax(y_pred, axis=-1).numpy()for name, metric in metrics.items():
print(f'{name} model accuracy: {metric.result().numpy()}')>> base model accuracy: 0.2201466 adv-regularized model accuracy: 0.8203125结果 (Results)
The effectiveness of adversarial learning on improving model robustness is immediately apparent by the dramatic reduction in our baseline model’s performance on adversarially perturbed data, vs that of the adv_reg_model.
与基准线adv_reg_model相比,基准线模型在对抗性扰动数据上的性能急剧下降,可以立即看出对抗性学习在提高模型鲁棒性方面的有效性。
Performance on our baseline model has dropped 69% vs our adversarially regularised model, which realised only a 14% drop in performance.
与我们的对抗性正则化模型(仅实现性能下降14%)相比,我们的基准模型的性能下降了69% 。
With Kera’s Layers API, we can examine the effect of adversarially perturbed data on our baseline model by visualising the convolutional layers to understand what features are extracted both prior and after perturbation:
借助Kera的Layers API,我们可以通过可视化卷积层以了解在扰动之前和之后提取了哪些特征来检查对抗性扰动数据对基线模型的影响:
摄动之前 (Before perturbation)
# Random img & conv layer idxs
IDX_IMAGE_1=2
IDX_IMAGE_2=5
IDX_IMAGE_3=10
CONVOLUTION_NUMBER = 10# Get baseline_model layers
layer_outputs = [layer.output for layer in baseline_model.layers]
activation_model = tf.keras.models.Model(
inputs =baseline_model.input,
outputs = layer_outputs)# Plot img at specified conv
f, axarr = plt.subplots(3,2, figsize=(8, 8))
for x in range(0, 2):
f1 = activation_model.predict(test_images[IDX_IMAGE_1].reshape(
1, 500, 500, 3))[x]
axarr[0,x].imshow(f1[0, : , :, CONVOLUTION_NUMBER],cmap='inferno')
axarr[0,x].grid(False)
f2 = activation_model.predict(test_images[IDX_IMAGE_2].reshape(
1,500, 500, 3))[x]
axarr[1,x].imshow(f2[0, : , :, CONVOLUTION_NUMBER],cmap='inferno')
axarr[1,x].grid(False)
f3 = activation_model.predict(test_images[IDX_IMAGE_3].reshape(
1, 500, 500, 3))[x]
axarr[2,x].imshow(f3[0, : , :, CONVOLUTION_NUMBER],cmap='inferno')
axarr[2,x].grid(False)We can observe in the image above, that our baseline model appears to have identified the relevant distinguishing features that define each class: angular leaf rust, healthy and bean spot, made visible by the distinct colour gradients.
我们可以在上图中观察到,我们的基线模型似乎已经确定了定义每个类别的相关区别特征:有角的叶锈病,健康的斑点和豆斑,通过不同的颜色渐变可见。
扰动之后 (After perturbation)
Now we can examine what features the baseline model identifies in the perturbed data:
现在,我们可以检查基线模型在扰动数据中识别出的特征:
# Pertubed test data
perturbed_images = []
for batch in test_set_for_adv_model:
perturbed_batch = reference_model.perturb_on_batch(batch)
perturbed_batch[IMAGE_INPUT_NAME] = tf.clip_by_value(
perturbed_batch[IMAGE_INPUT_NAME], 0.0, 1.0)
perturbed_images.append(perturbed_batch)# Get images
pt_img = [item['image'] for item in perturbed_images]IDX_IMAGE_1=0
IDX_IMAGE_2=1
IDX_IMAGE_3=2
CONVOLUTION_NUMBER = 11base_mod_layer_out = [layer.output for layer in baseline_model.layers]base_mod_activ = tf.keras.models.Model(
inputs = baseline_model.input,
outputs = base_mod_layer_out)f1 = base_mod_activ.predict(pt_img[IDX_IMAGE_1].numpy())[x]
f2 = base_mod_activ.predict(pt_img[IDX_IMAGE_2].numpy())[x]
f3 = base_mod_activ.predict(pt_img[IDX_IMAGE_3].numpy())[x]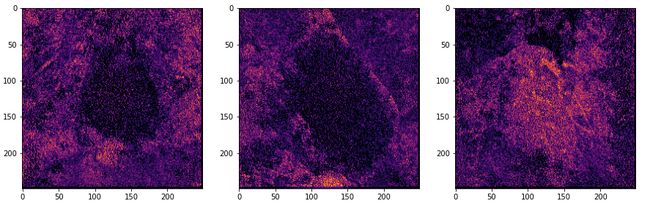
As we can observe in the above representations, the network’s has struggled to represent the raw pixels in each image, and are considerably more abstract as a result of the perturbation. In the image to the far right, it would appear that network managed to successfully retain the features representative of the ‘angular leaf rust’ class, but the basic structure of the leaf is mostly lost. Of course, this is just a single convolutional layer within our untuned network but still serves as a credible demonstration of how a previously skilful model can be unseated as a result of adversarial input data.
正如我们在上述表示中所观察到的,网络一直难以表示每个图像中的原始像素,并且由于扰动而变得更加抽象。 在最右边的图像中,似乎网络成功地保留了代表“角叶锈病”类的特征,但是叶的基本结构大部分丢失了。 当然,这只是我们未调整网络中的单个卷积层,但是仍然可以可靠地证明如何通过对抗性输入数据来取消先前的熟练模型。
结论 (Conclusion)
In this article we examined how we can significantly increase a convolutional neural network model’s robustness and generalisation performance on adversarially perturbed data, using adversarial regularisation. Additionally, we explored:
在本文中,我们研究了如何使用对抗性正则化来显着提高卷积神经网络模型在对抗性扰动数据上的鲁棒性和泛化性能。 此外,我们探索了:
- How to add adversarial regularisation to a Keras model. 如何在Keras模型中添加对抗性正则化。
- How to compare an adversarially regularised model against a baseline performance model. 如何将对抗性正则化模型与基准绩效模型进行比较。
- How to examine the effect of adversarially perturbed data on a conventionally trained model by visualising intermediate layers. 如何通过可视化中间层来检查对抗性数据对常规训练模型的影响。
Please do comment if you find errors or have any constructive criticism/builds.
如果发现错误或有建设性的批评/意见,请发表评论。
Thank you for reading.
感谢您的阅读。
翻译自: https://towardsdatascience.com/neural-structured-learning-adversarial-regularization-378523dace08
结构化数据 神经网络