Python源码学习(二)
内建数据结构
Python中已经预先定义了一些类型,比如int,float,bytes,string,list,dict等。下面我们来看几个有代表性的。
Int
typedef struct {
PyObjct_HEAD
long ob_ival;
}PyIntObject;
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
}
整数在python2里面分为int型和long长整型分开实现。在python3中统一使用了长整型。它非常适合大数据运算,Python中的大整数,也号称是永不溢出的整数,可以轻松计算10的100次方。其底层是通过整数数组来实现大整数的。

这边是他的头,引用计数和类型,这边包含size字段说明整数是变长对象,其中存储的n表示的是整数数组的长度,当n>0时,代表存储的是正数,当n<0时,代表存储的是负数。数组中的元素最大为2的30次方-1
#ifndef NSMALLPOSINTS
#define NSMALLPOSINTS 257
#endif
#ifndef NSMALLNEGINTS
#define NSMALLNEGINTS 5
#endif
#if NSMALLNEGINTS + NSMALLPOSINTS > 0
/* References to small integers are saved in this array so that they
can be shared.
The integers that are saved are those in the range
-NSMALLNEGINTS (inclusive) to NSMALLPOSINTS (not inclusive).
*/
static PyIntObject *small_ints[NSMALLNEGINTS + NSMALLPOSINTS];
#endif
PyIntObject对象也是一个不可变对象,真实的整数值在内存中是不可变的。在python程序中,整数的使用非常广泛,这些整数频繁的生成和销毁,但是在运行时没有影响运行效率。这是因为Python设计了一个整数对象池,运行时的整数对象能通过一定结构联结在一起。
实际编程中,数值比较小的整数,使用会比较频繁,比如range函数的迭代中,for循环中,一般都是从0开始。这样数值比较小的整数,被称为小整数对象,在python中实现了对象池技术,可以看下这个small_ints就是小整数对象的对象池,包含正数257个,负数5个,会在python启动后静态创建一个-5到256的数组,组成小整数对象池,既可以省去申请内存的开销,也不需要初始化对象。所以python代码中,声明两个都等于5的变量,他们指向的是同一块内存区域
Bytes
typedef struct {
PyObject_VAR_HEAD
Py_hash_t ob_shash;
char ob_sval[1];
}
PyTypeObject PyBytes_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"bytes",
PyBytesObject_SIZE,
sizeof(char),
// ...
&bytes_as_number, /* tp_as_number */
&bytes_as_sequence, /* tp_as_sequence */
&bytes_as_mapping, /* tp_as_mapping */
(hashfunc)bytes_hash, /* tp_hash */
// ...
};
通过这个头部,可以看到bytes对象是一个变长对象,而且在初始就给序列分配了一个字节长度,用于在末尾保存\0,来兼容c字符串。通过bytes类型对象的定义,可以看到支持数值操作,序列操作和关联操作。同样的python为了创建效率,维护了一个字符缓冲池,其中只存储单字节对象,也是以空间换时间的优化技术。还有就是,bytes对象的拼接合并操作,可以用+号处理,其实现原理是新建一个长度为两个对象总和的临时对象,再依次将字节序列拷贝到新序列。这也导致一个问题,合并的对象越多,最先合并的对象数据拷贝的次数也越多。可以使用内建的join方法,先计算总长度,然后依次合并,避免重复拷贝。
String
typedef struct {
PyObject_VAR_HAD
long ob_shash; //哈希值
int o_sstate; //是否被intern
char ob_sval[1];
}PyStringObject;
#define PyObject_VAR_HEAD
PyObject_HEAD
Py_ssize_t ob_size;
#define Py_INVALID_SIZE (Py_ssize_t)-1
在Python2中,字符串跟整数一样,也是不可变对象,PyStringObject是字符串对象的实现,不同的是它是一个可变长度的对象,因为声明的每个字符串都不一样。可以看到它的头部中有一个ob_size的变量,它保存的是可变长度内存的大小。ob_sval是一个字符数组,但实际上是作为一个字符指针指向一段内存,这个内存里保存着实际的字符串,结合ob_size的长度,就可以得到这个完整的对象。Ob_shash缓存的是对象的hash值。Ob_sstate用来表示是否被intern(因特er嗯)。Intern机制的目的是复用字符串对象,整个运行期间,只在内存中维护一个字符串的PyStringObject对象,重复声明也只保留一份,这样既可以节省空间,又可以简化string对象的比较,因为只需要判断是否被internd,然后对比引用地址就行了。比如代码中定义的常量,单个的ascii字符或者拉丁字母,还有空字符串。都会标记为internd。
通常情况下,创建两个相同的字符串,是会申请两次内存,创建两个PyStringObject对象的。比较极端的例子就是重复创建了1万个,这样就会浪费大量内存,如果标记了intern,就会返回第一个创建的PyStringObject对象的引用。在实际的应用中,并不是在创建第二个重复对象时就节省内存,而是先创建出对象,然后在维护的字典中查找是否存在,如果存在就减少新创建对象的引用计数为0,让它销毁,新增已存在对象的引用计数+1。因为从字典中查找的时候,必须用创建对象的指针当做键,所以不可避免的要先创建,后销毁,而不是在创建时就判断然后节省内存。
PyTypeObject PyString_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"str",
PyStringObject_SIZE,
sizeof(char),
string_dealloc, /* tp_dealloc */
(printfunc)string_print, /* tp_print */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_compare */
string_repr, /* tp_repr */
&string_as_number, /* tp_as_number */
&string_as_sequence, /* tp_as_sequence */
&string_as_mapping, /* tp_as_mapping */
(hashfunc)string_hash, /* tp_hash */
0, /* tp_call */
string_str, /* tp_str */
//...
};
这里可以看下string类型的类型对象,PyString_Tpye,这里tp_as_number,tp_as_sequence,tp_as_mapping,代表着string类型支持数值操作,序列操作和映射操作。
在python3之后,str对象内部改用Unicode表示。程序的核心逻辑统一用unicode,在输入和输出层进行字符序列的的编码解码。
List
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item; //ob_item是只想元素列表的指针
Py_ssize_t allocated;
} PyListObject;
这个PyListObject是list列表的底层结构,可以看到,在python的列表中,实际存放的元素都是PyObject*指针。List不仅是一个变长对象,还是一个可变对象。Allocated维护的是当前列表可容纳元素的数量,也就是申请内存的大小。头部的ob_size记录的是已容纳的元素数量,就是list中装入元素的个数。List内部维护的是一个动态数组,在尾部操作增删元素可以不挪动其他元素。
当新数组长度大于底层数组长度的时候,数组需要扩容。扩容时会申请一块新的内存,把旧数组中的元素逐一转移到新数组中,回收旧数组。而当新数组长度小于底层数组长度一半的时候,还会进行缩容,缩容操作与扩容类似,也需要申请新的空间,抛弃旧的空间。
List的倒数下标-1,-2使用非常方便,python内部在处理倒数下标时,会自动加上长度,就会转换为普通下标。
跟int和string一样,list也有缓冲池,不过它是把要销毁的PyListObject对象放进缓冲池,留作未来使用,而且对象中的PyObject指针都已经删除,引用清零,内存也归还了系统。
Dict
typedef struct {
PyObject_HEAD
Py_ssize_t ma_used; //当前保存键值对个数
unit64_t ma_version_tag; //版本号
PyDictKeysObject *ma_keys; //哈希表
PyObject **ma_values; //值对象组成的数组
} PyDictObject;
字典是python中的核心数据结构,也是计算机科学中最常用且最重要的数据结构之一。字典内部使用哈希表实现,为了优化内存,python把哈希表分为哈希索引和键值对两个数组来实现,因为为了控制哈希冲突,python只使用哈希表中不超过2/3的条目,所以至少有1/3是浪费的;这样用一个数组承担哈希表的角色,存储条目的下标,以此在键值对数组中索引,就可以节省掉键值对数组接近1/3的内存,(还要减去引用新数组的内存),总体来说,dict越大,节约的内存越多。
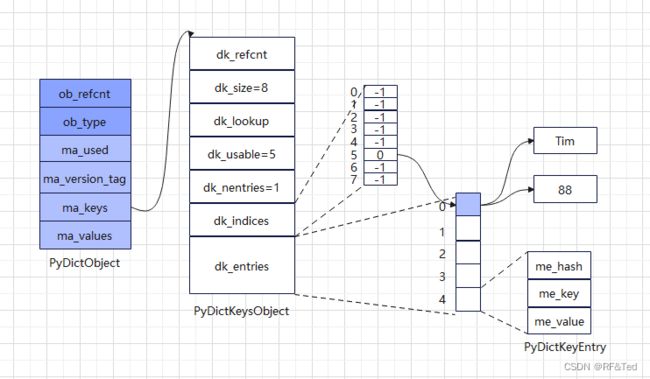
在一个PyDictObject对象生存变化过程中,它其中的键值对会在不同状态中转换,分别是Unused,Active,和Dummy。Unused表示Key和Value都是null,Acitve表示key和value都不能为null,Dummy就是伪删除,伪删除主要用在发生散列冲突,二次寻址的时候,需要从一个位置出发依次的查找其他可用位置,但是如果这条链上某个元素删除了,后面的位置就推算不出来了,所以要用Dummy标记伪删除,告诉算法,后面可能还有链条,以此来保证后面冲突探测链条的连续性。
字典的实现同样也使用了缓冲池,其本质与PyListObject中使用的缓冲池机制是一样的。在销毁时接收对象放入缓冲池,留待下一次使用
除此之外
Python中常用的数据结构有 列表list,元组tuple(塔剖)和字典和集合
Python给我们提供了一些有特殊用途的结构,可以直接拿来用
-字典:
在字典中,提供了有可以记住键的插入顺序的,增加缺省值的,还有只读的字典。
–collections.OrderedDict可以记住键的插入顺序
–collections.defaultdict为缺失的键返回默认值
–collections.ChainMap将多个字典分组到一个映射中,可进行增删改查
–types.MappingProxyType创建一个只读的词典
-列表和元组:
列表是以动态数组实现的,可以包含任意数据类型。元组tuple创建后不能修改
但是如果想要使用约束类型的数组结构,就可以array.array,它只能存储单一数据类型。
-集合:python的集合由dict数据类型支持,他们具有相同的性能特征。所有可散列的对象都可以存储在集合中。也同样提供了不可变集合和多重集合,多重结合相当于背包结构,可以重复和计数,满足特定需求,除此之外,还可以使用逻辑符号对两个集合进行运算,求交集,并集,差集,判断子集和超集。