基于Neo4j的担保社群型态分析挖掘
图技术
利用neo4j、networkx、dgl、python做图分析挖掘
【1】最短路径算法dijkstra
【2】基于networkx的隐性集团关系识别模型
基于Neo4j的担保社群型态分析挖掘
- 图技术
- 一. 前言
-
- 算法步骤
- 算法说明
- 二. 数据说明
- 三. Neo4j介绍
-
- 1. Python、Neo4j交互
- 2. Neo4j入图
- 3. Neo4j图分析
- 四. 图谱型态
- 五. 模型说明
- 六. 模型实例
- 七. 展望
一. 前言
对于担保客户群,如何对担保客群型态进行详细的分析挖掘呢?如图一,怎么获取标签,如何打上标签呢?
担保
担保
担保
企业A
企业B
企业C
| 图一:样例图 |
|---|
采用图技术来计算,可以直接打上三角型标签。
算法步骤
- 担保关联关系数据清洗;
- 利用担保关联关系构建担保图谱;
- 计算担保客户5度全路径;
- 利用louvain进行社区(客群)分团;
- 客群内社区型态分析;
- 担保客户型态汇总。
算法说明
- 模型输入:担保关系数据;
- 模型结果:担保客户图谱型态;
- 模型应用:为每个客户打上型态标签,对于一些异常型态重点关注,防止违规担保,降低风险。
二. 数据说明
demo数据采用python中的faker进行构造,主要生成担保关系数据。
#导入模块包
import warnings
warnings.filterwarnings('ignore')
import random
import pandas as pd
import multiprocessing
import timeit
from faker import Faker
fake = Faker("zh-CN")
import os
#担保关系数据清理
if os.path.isfile('rela_demo.csv'):
os.remove('rela_demo.csv')
#担保客户数据清理
if os.path.isfile('node_demo.csv'):
os.remove('node_data.csv')
#生成担保关系数据
def demo_data_(edge_num):
s = []
for i in range(edge_num):
#担保公司、被担保公司、担保金额、担保时间
s.append([fake.company(), fake.company(), random.random(), fake.date(pattern="%Y-%m-%d", end_datetime=None)])
demo_data = pd.DataFrame(s, columns=['guarantee', 'guarantor', 'money', 'data_date'])
print("-----demo_data describe-----")
print(demo_data.info())
print("-----demo_data head---------")
print(demo_data.head())
return demo_data
#判断DataFrame两列是否相等
def if_same(a, b):
if a==b:
return 1
else:
return 0
#demeo数据处理
def rela_data_(demo_data):
print('原始数据记录数', len(demo_data))
#去除自保
demo_data['bool'] = demo_data.apply(lambda x: if_same(x['guarantor'], x['guarantee']), axis=1)
demo_data = demo_data.loc[demo_data['bool'] != 1]
#去除非空
demo_data = demo_data[(demo_data['guarantor'] != '')&(demo_data['guarantee'] != '')]
#按照日期排序删除重复guarantor、guarantee项
demo_data = demo_data.sort_values(by=['guarantor', 'guarantee', 'data_date'], ascending=False).drop_duplicates(keep='first', subset=['guarantor', 'guarantee']).drop_duplicates().reset_index()
demo_data[['guarantee', 'guarantor', 'money', 'data_date']].to_csv('rela_demo.csv', index = False)
return demo_data[['guarantee', 'guarantor', 'money', 'data_date']]
#节点数据
#节点从关系数据中抽
def node_data_(demo_data):
node_data = pd.concat([demo_data[['guarantor']].rename(columns = {'guarantor':'cust_id'}), demo_data[['guarantee']].rename(columns = {'guarantee':'cust_id'})])[['cust_id']].drop_duplicates().reset_index()
print('节点数目', len(node_data['cust_id'].unique()))
node_data[['cust_id']].to_csv('node_data.csv', index = False)
return node_data[['cust_id']]
if __name__ == '__main__':
#edge_num样本关系条数
demo_data = demo_data_(edge_num=1000)
rela_demo = rela_data_(demo_data)
#node_num样本节点条数
node_data = node_data_(demo_data)
三. Neo4j介绍
1. Python、Neo4j交互
Python作为数据分析常用软件,可以利用python对Neo4j的图分析数据进行处理计算,需要下载一个模块包py2neo。
#连接图数据库
from py2neo import Graph, Node, Relationship
def connect_graph():
graph = Graph("http://*.*.*.*:7474", username = "neo4j", password = ' password')
return (graph)
#graph = connect_graph()
2. Neo4j入图
- Neo4j支持多标签入数;
- Neo4j入数最好选用本地文件导入形式;
def create_graph(graph, load_node_path, load_rel_path, load_node_name, load_rel_name, guarantee_edges):
guarantee_edges.to_csv(load_rel_path,encoding = 'utf-8', index = False)
x = guarantee_edges[:]
x1 = pd.DataFrame(x['Guarantor_Id'][:].drop_duplicates())
x1.columns = ['Cust_id']
x2 = pd.DataFrame(x['Guarantee_Id'][:].drop_duplicates())
x2.columns = ['Cust_id']
x3 = x1.merge(x2,left_on = 'Cust_id',right_on = 'Cust_id',how = 'inner')[:]
x1 = x1.append(x3)
x1 = x1.append(x3)
x1 = x1.drop_duplicates(keep = False)[:]
x2 = x2.append(x3)
x2 = x2.append(x3)
x2 = x2.drop_duplicates(keep = False)[:]
x3.insert(loc = 0,column = 'label1',value = 'Cust')
x3.insert(loc = 0,column = 'label2',value = 'Guarantor')
x3.insert(loc = 0,column = 'label3',value = 'Guarantee')
x1.insert(loc = 0,column = 'label1',value = 'Cust')
x1.insert(loc = 0,column = 'label2',value = 'Guarantor')
x1.insert(loc = 0,column = 'label3',value = '')
x2.insert(loc = 0,column = 'label1',value = 'Cust')
x2.insert(loc = 0,column = 'label2',value = '')
x2.insert(loc = 0,column = 'label3',value = 'Guarantee')
x4 = pd.DataFrame(pd.concat([x1, x2, x3]))
x4 = x4.drop_duplicates()
x4.to_csv(load_node_path,encoding = 'utf-8', index = False)
#清除历史关系和节点
graph.run("MATCH p=()-[r:guarantee]->() delete p")
graph.run("MATCH (n:Cust) delete n")
#创建索引
graph.run("CREATE INDEX ON:Cust(Cust_id)")
graph.run("CREATE INDEX ON:Guarantor(Cust_id)")
graph.run("CREATE INDEX ON:Guarantee(Cust_id)")
#导入节点
graph.run("USING PERIODIC COMMIT 1000 LOAD CSV WITH HEADERS FROM 'file://%s' AS line MERGE (p:Cust{Cust_id:line.Cust_id}) ON CREATE SET p.Cust_id=line.Cust_id ON MATCH SET p.Cust_id = line.Cust_id WITH p, [line.label1, line.label2, line.label3] AS sz CALL apoc.create.removeLabels(p, apoc.node.labels(p)) YIELD node as n CALL apoc.create.addLabels(p, sz) YIELD node RETURN count(p)" % load_node_path)
print("%s INFO : 加载%s完毕。" % (time.ctime(), load_node_name))
#导入关系
graph.run("USING PERIODIC COMMIT 1000 LOAD CSV WITH HEADERS FROM 'file://%s' AS line match (s:Cust{Cust_id:line.Guarantor_Id}),(t:Cust{Cust_id:line.Guarantee_Id}) MERGE (s)-[r:guarantee{Money:toFloat(line.Money)}]->(t) ON CREATE SET r.Dt = line.Dt, r.Money = toFloat(line.Money), r.link_strength = 1 ON MATCH SET r.Dt = line.Dt, r.Money = toFloat(line.Money), r.link_strength = 1" % load_rel_path)
print("%s INFO : 加载%s完毕。" % (time.ctime(), load_rel_name))
3. Neo4j图分析
| 序号 | 图计算 |
|---|---|
| 1 | 节点入度 |
| 2 | 节点出度 |
| 3 | 节点的度 |
| 4 | 节点中介度 |
| 5 | 节点中心特征向量值 |
| 6 | 节点的pagerank值 |
| 7 | 节点的5度路径 |
#计算节点的入度
def guarantee_indegree_(graph):
x1 = pd.DataFrame(graph.run("call algo.degree.stream('Cust','guarantee',{direction:'incoming'})yield nodeId,score return algo.getNodeById(nodeId).Cust_id as Guarantee_Id,score as guarantee_indegree order by guarantee_indegree desc").data()).drop_duplicates()
x2 = pd.DataFrame(guarantee_edges['Guarantee_Id']).drop_duplicates()[:]
guarantee_indegree = pd.merge(x2, x1, how = 'left', on = ['Guarantee_Id']).drop_duplicates()[:]
if len(guarantee_indegree) == 0:
guarantee_indegree.insert(loc = 0,column = 'name',value = '')
guarantee_indegree.insert(loc = 0,column = 'guarantee_indegree',value = '')
return (guarantee_indegree)
#guarantee_indegree = guarantee_indegree_(graph)
#计算节点的出度
def guarantee_outdegree_(graph):
x1 = pd.DataFrame(graph.run("call algo.degree.stream('Cust','guarantee',{direction:'out'})yield nodeId,score return algo.getNodeById(nodeId).Cust_id as Guarantor_Id,score as guarantee_outdegree order by guarantee_outdegree desc").data()).drop_duplicates()
x2 = pd.DataFrame(guarantee_edges['Guarantor_Id']).drop_duplicates()[:]
guarantee_outdegree = pd.merge(x2, x1, how = 'left', on = ['Guarantor_Id']).drop_duplicates()[:]
if len(guarantee_outdegree) == 0:
guarantee_outdegree.insert(loc = 0,column = 'name',value = '')
guarantee_outdegree.insert(loc = 0,column = 'guarantee_outdegree',value = '')
return (guarantee_outdegree)
#guarantee_outdegree = guarantee_outdegree_(graph)
#计算节点的度
def guarantee_degree_(graph):
x1 = pd.DataFrame(guarantee_edges[['Guarantee_Id','Guarantor_Id']]).drop_duplicates()[:]
x2 = pd.merge(x1, guarantee_indegree, how = 'left', on = ['Guarantee_Id']).drop_duplicates()[:]
guarantee_degrees = pd.merge(x2, guarantee_outdegree, how = 'left', on = ['Guarantor_Id']).drop_duplicates()[:]
if len(guarantee_degrees) == 0:
guarantee_degrees.insert(loc = 0,column = 'name',value = '')
guarantee_degrees.insert(loc = 0,column = 'guarantee_degrees',value = '')
return (guarantee_degrees)
#guarantee_degrees = guarantee_degree_(graph)
#计算节点的中介度
def guarantee_btw_(graph):
guarantee_btw = pd.DataFrame(graph.run("call algo.betweenness.stream('Cust','guarantee',{direction:'outer'}) yield nodeId,centrality return algo.getNodeById(nodeId).Cust_id as name,centrality order by centrality desc").data())
if len(guarantee_btw) == 0:
guarantee_btw.insert(loc = 0,column = 'name',value = '')
guarantee_btw.insert(loc = 0,column = 'centrality',value = '')
return (guarantee_btw)
#guarantee_btw = guarantee_btw_(graph)
#计算节点的中心特征向量值
def guarantee_eigencentrality_(graph):
guarantee_eigencentrality = pd.DataFrame(graph.run("call algo.eigenvector.stream('Cust','guarantee',{normalization:'l2norm', weightProperty:'Money'}) yield nodeId,score return algo.getNodeById(nodeId).Cust_id as name,score as eigenvector order by eigenvector desc").data())
if len(guarantee_eigencentrality) == 0:
guarantee_eigencentrality.insert(loc = 0,column = 'name',value = '')
guarantee_eigencentrality.insert(loc = 0,column = 'eigenvector',value = '')
return (guarantee_eigencentrality)
#guarantee_eigencentrality = guarantee_eigencentrality_(graph)
#计算节点的pagerank值
def guarantee_pagerank_(graph):
sum = pd.DataFrame(graph.run("call algo.pageRank.stream('Cust','guarantee',{iterations:1000,dampingFacter:0.85, weightProperty:'Money'})yield nodeId,score return sum(score) as sum").data())['sum'][0]
guarantee_pagerank = pd.DataFrame(graph.run("call algo.pageRank.stream('Cust','guarantee',{iterations:1000,dampingFacter:0.85, weightProperty:'Money'})yield nodeId,score return algo.getNodeById(nodeId).Cust_id as name,score/%f as pageRank order by pageRank desc" %(sum)).data())
if len(guarantee_pagerank) == 0:
guarantee_pagerank.insert(loc = 0,column = 'name',value = '')
guarantee_pagerank.insert(loc = 0,column = 'pageRank',value = '')
return (guarantee_pagerank)
#guarantee_pagerank = guarantee_pagerank_(graph)
def all_paths_(graph):
all_paths = pd.DataFrame(graph.run("MATCH p = (n:Cust{})-[r:guarantee*..5]->(m) where SIZE(apoc.coll.toSet(NODES(p))) = length(p)+1 RETURN m.Cust_id as id, REDUCE(s=[], x in NODES(p) | s + x.Cust_id) as path, length(p) + 1 as path_len, n.Cust_id as start ").data())
all_paths['path'] = (['->'.join(x) for x in all_paths['path']])
all_paths = all_paths.drop_duplicates()[:]
return (all_paths)
#all_paths = all_paths_(graph)
四. 图谱型态
以圈型为例说明:
- 获取全路径数据;
- 筛选路径长大于2;
- 路径数据与关系数据关联,关联上说明存在圈。
补充:三角型可直接引用algo.triangle
def guarantee_cycle_(all_paths):
x1 = all_paths.drop_duplicates()[:]
x2 = guarantee_edge[['Guarantor_Id','Guarantee_Id']].drop_duplicates()[:]
x2.columns = ['id','start']
x2['cycle_flag'] = 1
x3 = x1.loc[x1['path_len'] > 2].drop_duplicates()[:]
x4 = pd.merge(x3, x2, how = 'left',on = ['id','start']).drop_duplicates()[:]
x5 = x4.loc[x4['cycle_flag'] == 1].drop_duplicates()[:]
x6 = pd.merge(x1, x5, how = 'left',on = ['id','start','path','path_len']).drop_duplicates()[:]
x7 = x6.fillna(0).drop_duplicates()[:]
return (x7)
#三角型态
def triangle_(graph):
x = pd.DataFrame(graph.run("call algo.triangle.stream('Cust','guarantee',{}) yield nodeA, nodeB, nodeC return algo.getNodeById(nodeA).Cust_id as node1, algo.getNodeById(nodeB).Cust_id as node2, algo.getNodeById(nodeC).Cust_id as node3").data())
return (x)
#triangle = triangle_(graph)
五. 模型说明
社群型态,需要对客户分团,然后研究团内的客户型态,比如通过节点数、边数、路长等。
六. 模型实例
模型最终形成一张客户型态宽表
| 客户号 | 社群号 | 路径 | 型态类型 | 社群密度 | pageRank |
|---|---|---|---|---|---|
| A | 1 | A->B->C | 三角 | 1 | * |
型态直接上图说明,分别为:融资、塔、三角、圈
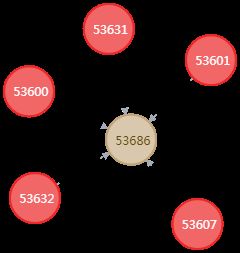
| 图二:融资 |
|---|
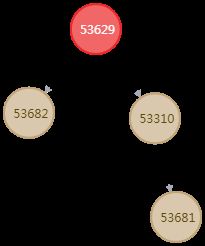
| 图三:塔 |
|---|

| 图四:三角 |
|---|

| 图五:圈 |
|---|
七. 展望
- 社区型态的研究,可以找出高风险型态的客群;
- 读者也可以自己刻画型态。
链接: 基于networkx的隐性集团关系识别模型.