NVIDIA支持CUDA的显卡选型简述
**
NVIDIA支持CUDA的显卡选型简述
**
目录
-
- NVIDIA支持CUDA的显卡选型简述
-
- 一、概述
-
- 1、为什么选这三款
- 二、对比
-
- 1、训练--training
-
- CPU与GPU的区别
- 计算精度
- 显存和显存带宽
- 价格
- 2、训练环境的选择
- 3、推理--inference
-
- 吞吐量和时延
- 稳定性
- 4、生产环境的选择
- 三、说明
-
- 1、自我说明
- 2、名词说明
-
- CPU,GPU,TPU,NPU都是什么?
- 3、nVidia显卡架构
- 4、个人愚见
一、概述
参考链接: nvidia官方网站
根据nVidia官方介绍,nVidia出品的支持CUDA的产品有
1、Tesla:用于技术和科学计算
2、Quadro:用于专业可视化
3、NVS:用于商务多屏演示
4、GeForce 和 TITAN:用于游戏娱乐
5、Jetson:用于边缘测AI自主机器
五类产品。
从描述上看,能用于人工智能训练和推理的GPU应该是【Tesla、Quadro、GeForce、TITAN、Jetson】,NVS应该是有多个显示输出接口,以便于商务台式机或笔记本做分屏演示。但是考虑我司的用途,本文档仅对Tesla、GeForce、TITAN等部分系列做对比。
1、为什么选这三款
- 【Tesla】系列产品全部由nVidia原厂设计和生产,产品品质和服务更有保障,而且官方明确定义该类产品适用于数据中心和高性能计算场景,简单的说就是服务器专用系列。从材料和驱动上都对科学计算以及人工智能训练和推理做了相应的优化。
另外,还加入了ECC内存纠错功能,这点是在GeForce系列中没有的。 - 【GeForce】系列本来针对的是个人用户桌面环境的娱乐使用的,就是游戏影音。该系列产品的设计本就不适合高强度、长时间的工作,而且对于程序和驱动方面的优化也只是针对游戏方面的。在其用户使用协议中也申明了,不能安装在服务器上使用,否则将失去维保和支持。
但是很多企业和个人也用该系列的某些产品做人工智能研发,因为相比专业的Tesla卡,同等计算能力的情况下,这个更便宜。
比如我司之前也用过GeForce GTX 1080 Ti 和GeForce GTX 1050 Ti作为研发和生产使用,但是多多少少都出现过问题。就在去年,在客户那里部署的两台生产服务器,每台搭载两张GTX 1080 Ti显卡,其中一台服务器的两张显卡都出现了故障,导致生产停滞,最后不得不联系供应商更换,随后另一台服务的其中一张也出现了故障。这也是我们之前没有查找相关数据以及没有这方面经验导致的。
实践证明,该系列显卡确实不适合服务器那种高强度高负荷的工作环境,但是作为训练或测试环境还是可以选用其作为专业显卡的代替方案的。 - 【TITAN】系列,官方列表把TITAN和GeForce放在了同一个列表中,所以我认为二者的定位应该是差不多的。但是为什么nVidia官方又推荐研究人员、开发人员和创作者使用TITAN RTX呢。我感觉这就像他每一代新产品发布的时候都说“这是世界上最先进的GPU”一样。
我司也是在该卡刚发布的时候(2019年)就采购了一些作为公司的研发生产工具,至于性能如何呢,我也不太清楚了,因为我不是直接使用者。
这么来看的话,那我感觉用最新的RTX 3090,性价比应该是更高的。因为RTX 3090采用了最新的Ampere架构,CUDA核心和显存带宽远比RTX TITAN高出近1倍,计算精度性能这方面没找到相关的数据,但是根据这个架构,这个配置,也不可能低到哪里去。最重要的是,官方给的价格,RTX 3090比RTX TITAN便宜了1000美刀,京东上的价格,二者也相差3-5k。

- 【Quadro】系列,为什么不选它呢,因为老黄准备把这个系列取消了,变成RTX A系列。这个系列的显卡定义是专业图形工作站使用的,简单的说就是绘图,制作,设计等到这类的专业性很强的场景使用的,比如我们熟悉的Adobe全家桶,3DMAX,CAD等这类的软件,而且该类显卡的驱动还在某些专业软件上做过针对性的优化。
虽然它的性能也很不错了,但是根据设计,它的应用场景同样不适合服务器这种7*24h的高负荷且需要足够的稳定性的场景。而且和GeForce差不多性能的情况下,价格却比GeForce贵出去很多。所以我认为用它来做深度学习训练,有些不太合适。 - 【Jetson】系列,这个东西被设计成基于arm架构的AI运算模块,功耗很低,10W-30W左右,所以更适合运用在边缘计算场景下。比如我司也有一些产品就搭载了Jetson AGX Xavier,在生产环境中我感觉表现还是很不错的了。
二、对比
要从众多类型、型号中选出适合公司应用场景的产品,说老实话,还是不那么容易的,因为这个要结合很多实际生产情况而定,比如,是用在训练还是推理上,是做研发测试还是生产环境上,是主要考虑稳定性还是考虑价格等等的因素。
根据我司的实际情况,有两个场景需要用到nVidia GPU资源,一个是『训练』,就是在公司的研发测试上,另一个是『推理』,就是在客户方的生产环境部署。
参考链接:知乎 | 深度学习训练和推理有何不同
1、训练–training
训练,就好比我们在学校中学习某个知识或者某项技能一样。人工智能需要完成某项工作,也要接受教育。
没有训练,就不可能会有推理。这很容易讲通,因为我们人类大多时候就是这样获取和使用知识的。正如我们不需要一直围着老师、满架的书架或名牌院校转也能阅读莎士比亚的十四行诗一样,推理并不需要其训练方案中的所有基础设施就能做得很好。
CPU与GPU的区别
在这篇 “为什么深度学习和神经网络需要GPU? - 知乎” 文章中描述了CPU和GPU的设计区别,基本上解释了为什么在进行深度学习相关业务的时候需要用到GPU,主要是因为它快,快得飞起。
有一个例子我感觉很形象:将CPU比作几个教授,GPU比作很多小学生。当需要进行复杂运算,比如解方程,计算高级函数等等这种操作很显然教授比小学生更出色,当需要进行的计算是简单且大量的四则运算的时候,一个或者几个教授显然比不过成百上千的小学生。而深度神经网络的模型训练就是这种大量的并行的矩阵乘法类似的四则运算,GPU的计算核心和CPU根本就是量级上的差距,而且GPU也更擅长做这类型的计算。
计算精度
根据不同的深度学习应用场景,又有各种浮点运算精度的区别,比如“单精度,双精度,半精度,混合精度”等等。我司主要业务是针对图像分类,特征识别等(用词可能不太专业),这并非是计算精度要求十分严格的科学计算,如航空航天,医学,核能等领域,所以在“图像识别”这类模型训练中一般采用的是单精度或半精度,或者混合精度。
这些各种精度的运算有什么区别,可以参考 知乎 | 单精度、双精度、多精度和混合精度计算的区别是什么?
显存和显存带宽
还有一个十分重要的参数就是显卡的显存、位宽、显存频率(显存带宽=显存频率x显存位宽/8)。显存就跟主存(内存)差不多,显存带宽就是显存与GPU交换数据的速率。本博文中即将进行对比的几个型号的显卡内存从8GB到40GB不等,显存带宽也由192GB/s到1555GB/s不等。这是个啥概念呢,比如我们的内存,一般大小是8GB到16GB,DDR4的理论带宽是50GB/s到136GB/s左右。
显存越大,就代表等待GPU运算核心处理的数据越多,显存带宽越大,就代表GPU运算核心单位时间内可以拿到数据的能力越大(理论上拿到的数据越多),数据交换越顺畅。
因为在训练中,有大量的素材、中间参数、运算结果等需要存储在显存中,以及运算核心和显存之间在进行着大量的数据交换,所以这个参数也成为深度学习模型训练选择显卡的重要参数了。
价格
俗话说:一分钱一分货。要想获得好的体验,好的效果,那必然是要投入足够的成本的,但是无论是个人还是企业,在研发或者生产过程中都必须要考虑成本(家里有矿的除外),这就需要我们在性能和价格上做好衡量,选择性价比相对最优的方案。
nVidia除了Tesla系列的产品是自己生产加工的(大家称为“公版”)之外,其他系列如GeForce(另外的系列有没有代加工不清楚)都有很多加工厂商。所以根据不同厂商的生产条件如板卡设计,用料等情况的不同,价格和质量都有一些差距。
2、训练环境的选择
综上所述,我认为我们在研发测试的训练(推理)场景下可以选择性能较优,价格相对温和的GeForce或TITAN系列的GPU,如TITAN RTX,GeForce RTX 3090、3080Ti等。
根据nVidia官方给出的数据,我整理了一份表格,可以作为参照。(数据不全,有的是因为官方没给出来,可能定位不一样,给出的参考数据有限。)
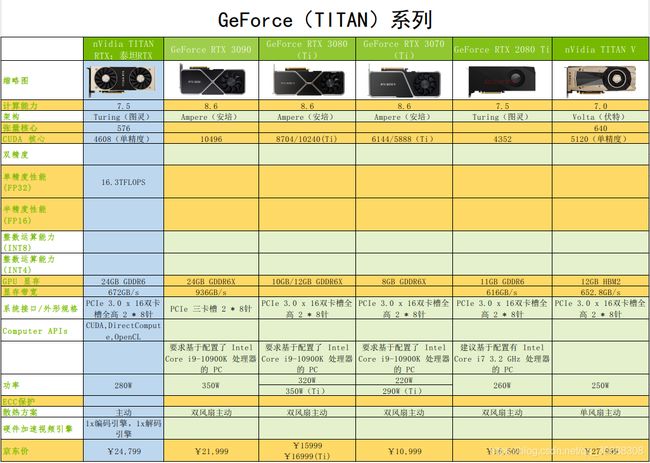
在选择『训练』用卡的时候,我们主要注意“张量核心、CUDA核心、精度性能、显存、显存带宽、价格(这个价格比较粗糙,只看了京东上较便宜的一家)”这几个参数。
我司之前购买的TITAN RTX性价比还是比较高的,但是当时为啥没买RTX 3090呢,因为那时候3090还没出,买不到。。。如果后期还有采购需求,我会建议考虑GeForce RTX 3090。
3、推理–inference
推理其实就是将我们研发测试环境训练好的模型部署到生产环境中去进行应用,训练有一个反向传播的过程,因为要不断的调整权重和参数,以达到最好的效果,但是推理则没有反向传播,所以在对硬件的要求上,应该是要低一些的。
举个不太恰当的栗子,我们在学习的时候要到学校去,要在教室,要有课本,要住宿舍等等,学校教室课本宿舍等这些都是硬件条件,但是我们考试或者毕业之后在解题的时候是不需要这些硬件条件的,这就是训练到推理的过程。
所以推理的向前传播可以不同于训练,目的是为了更快,比如推理中会删掉一些增强处理、做蒸馏、用加速库等。
吞吐量和时延
模型训练的时候侧重计算精度,而推理的时候更注重实时性和速度,也就是模型运行的性能。衡量推理整体性能最简单的办法就是吞吐量,也就是运行某个模型时,每秒钟能够处理的图片数量。平均每张图的用时长度就是时延。一般来说,常用的时延单位是毫秒(ms)。
芯片的算力性能常用TOPS衡量,即为在深度学习领域的每秒基础算子操作数。如果将芯片的标称算力作为硬件的衡量标准,那么吞吐量则是软硬件一体化作用的结果,和数据结构、模型结构甚至批量处理的批次大小都有很高的相关性。一般来说,对于同样类型和大小的数据,参数量越少的模型,处理的绝对速度就越快,吞吐量就越大。
nVidia官方给出了Tesla系列部分型号的推理性能数据,参考:NVIDIA 数据中心深度学习产品性能
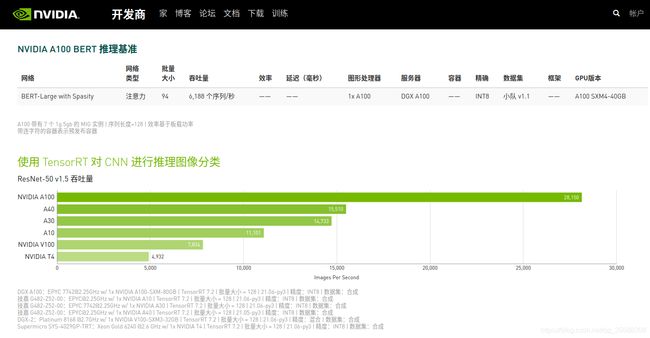

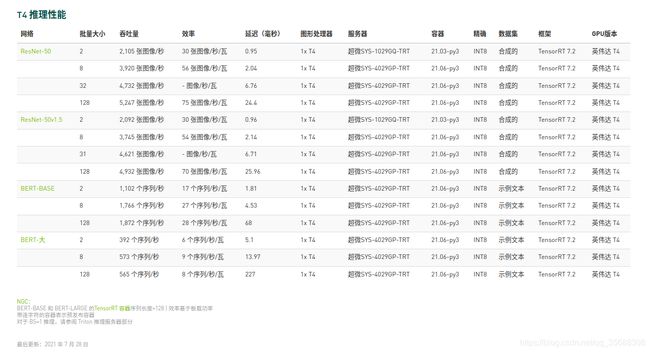
稳定性
在生产环境中,除了考虑性能之外,更重要的也要考虑稳定性。因为严格的讲,服务器是7*24h不间断工作的,所以用于服务器环境的GPU也应该具有可靠的稳定性,这点Tesla显然比GeForce或者TITAN表现要好得多。因为根据实践经验,之前在生产环境中使用的GeForce GTX 1080 Ti已经坏了三个了,所以在新的部署环境中,我们选择了Tesla T4这个型号的GPU。
4、生产环境的选择
同样,我根据nVidia官方给出的数据,对Tesla部分型号的显卡进行了数据统计。
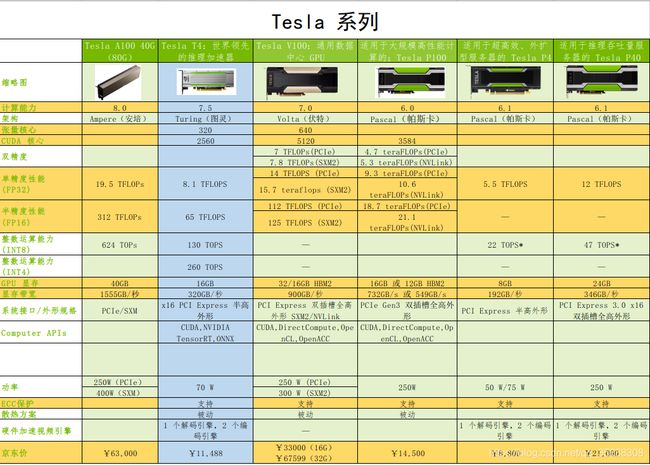
由此可见,我们选择的Tesla T4这个类型的算力卡性价比也还不错,或者也可以考虑P100和P40这两个类型的产品。但是从价格上看,我个人更偏向于T4。
三、说明
1、自我说明
本人对于深度学习、神经网络,以及GPU硬件都不是很了解,只是在这一年多的接触中耳濡目染,“偷听”到一些名词,然后结合网上找的资料,写出来这篇“自以为是”的博文,所以,如果有不对的地方,欢迎读者批评指正,我本人也会继续学习,希望能自我修正。
2、名词说明
关于深度学习的一些名词解释,这个链接进行了描述:深度学习名词解释
CPU,GPU,TPU,NPU都是什么?
- 中央处理器(CPU),是电子计算机的主要设备之一,电脑中的核心配件。其功能主要是解释计算机指令以及处理计算机软件中的数据。CPU是计算机中负责读取指令,对指令译码并执行指令的核心部件。中央处理器主要包括两个部分,即控制器、运算器,其中还包括高速及实现它们缓冲处理器之间联系的数据、控制的总线。电子计算机三大核心部件就是CPU、内部存储器、输入/输出设备。中央处理器的功效主要为处理指令、执行操作、控制时间、处理数据。
- 图形处理器(英语:Graphics Processing Unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
- TPU(Tensor Processing Unit)即张量处理单元,是一款为机器学习而定制的芯片,经过了专门深度机器学习方面的训练,它有更高效能(每瓦计算能力)。
- 嵌入式神经网络处理器(NPU)采用“数据驱动并行计算”的架构,特别擅长处理视频、图像类的海量多媒体数据。NPU处理器专门为物联网人工智能而设计,用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。
原文链接:https://blog.csdn.net/qq_44159782/article/details/117416930
3、nVidia显卡架构
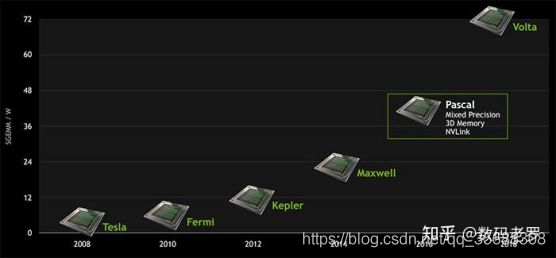
从图上可以看到,nVidia显卡架构是“Tesla(特斯拉)→Fermi(费米) → Kepler(开普勒) → Maxwell(麦克斯韦) → Pascal(帕斯卡) → Volta(伏特) → Turing(图灵) → Amper(安培)[图上没有,因为这个是最新的架构]”这么个路线,都是一些为科学做过突出贡献的历史名人。。。按照这种发展方向,预计不久的将来可能会发布“爱因斯坦”架构。
- Tesla(特斯拉): 市面已经没有相关显卡
- Fermi(费米):GeForce 400, 500, 600, GT-630
- Kepler(开普勒):Tesla K40/K80, GeForce 700, GT-730
- Maxwell(麦克斯韦尔): Tesla/Quadro M series GeForce 900, GTX-970
- Pascal(帕斯卡): Tesla p100,GTX 1080, GTX 1070, GTX 1060
- Votal(伏打): Tesla V100, GTX 1180
- Turing(图灵): T4,GTX 1660 Ti, RTX 2060
- Ampere(安培): A100
原文链接:NVIDIA显卡及架构介绍
Tesla(特斯拉)本来是第一代架构,现在发展为数据中心专用GPU型号代名词了。
另外,因为nVidia将产品分类化,有些设计也在慢慢改变,比如专门用于计算的,大家也称之为“计算卡、算力卡”,这种显卡严格意义上已经不能称之为显卡了,因为它已经将图形输出这部分砍掉了,连个显示器接口都没有了,比如Tesla系列。
4、个人愚见
为什么挖矿大多选用的是GeForce这类的游戏卡呢,个人认为是矿场对于显卡的需求体量还是比较大的,而且是追求算力性能的,在控制成本的前提下,选择算力性能较优的游戏卡,是最好的方案。即使是挖着挖着坏了个把子显卡,换了就是了。而且锻炼个一两年,翻个新就卖二手矿卡,还能赚点。
如果选择Tesla这种专业显卡来挖矿,一个是投入成本高,另一个也不好卖二手的啊,因为用户没那么多。
所以,有的朋友可能需要购买GeForce这类型的显卡,不管是作为深度学习训练还是个人娱乐使用的时候,都要找可靠的渠道购买,最好不要贪便宜,因为保不准就买到了二手矿卡。
我严重怀疑我司之前用的出现故障的GeForce GTX 1080 Ti就是翻新卡,因为更换的时候我看到板子背面有大面积像油一样的东西,后来刷到抖音上电子维修的博主,发现这玩意儿就是焊接用的助焊剂(焊油之类的东西),显然是被修过的。。。
最后,还有一些不错的文章,有兴趣的读者可以参考阅读。
1、深度学习选什么显卡性价比最高?
2、深度学习中GPU和显存分析