技术干货|昇思MindSpore NLP模型迁移之LUKE模型——阅读理解任务
LUKE作者提出的模型是在BERT的MLM的基础上使用一种新的预训练任务来训练的。这项任务涉及到预测从维基百科的大型实体注释语料库中检索出来的随机隐藏的单词和实体。作者还提出了一种实体感知的自我注意机制,它是transformer中的自我注意机制的扩展,并在计算注意力分数时考虑了token(单词或实体)的类型。主要贡献有:
1、作者提出了一种新的专门用于处理与实体相关的任务的上下文表示方法LUKE(Language Understanding with Knowledge-based Embeddings)。LUKE利用从维基百科中获得的大量实体注释语料库,预测随机mask的单词和实体。
2、作者提出了一种实体感知的自我注意机制,它是对transformer原有的注意机制的有效扩展,该机制在计算注意力分数时考虑到了标记(单词或实体)的类型。
3、LUKE是以Roberta作为基础的预训练模型,并通过同时优化MLM的目标和我们提出的任务进行模型的预训练。并在5个流行的数据集上获得了最先进的结果。
luke官方源码[1]:
https://github.com/studio-ousia/luke
luke论文(EMNLP2020)[2]:
https://aclanthology.org/2020.emnlp-main.523.pdf
前言
本文环境:
系统:ubuntu18
GPU:3090
MindSpore版本:1.3
数据集:SQuAD1.1(阅读理解任务)
阅读理解任务定义:
机器阅读理解为QA问答技术中的全新领域,允许用户输入非结构化文本以及问题,机器在阅读理解基础上,从文本中寻找答案回答用户问题。
01
数据处理
先参考源码将数据处理为模型需要的Mindrecord文件。

先参考源码使用roberta_tokenizer将文本转化为token,得到word_ids,word_segment_ids等多个字段。其中word_ids部分padding补全需要补1,entity_position_ids实体位置信息需要补-1,其余的字段都为补0。由于源码中是padding长度至256,故这里也参考源码对各个字段进行padding,具体padding代码如下:
import json
from mindspore.mindrecord import FileWriter
SQUAD_MINDRECORD_FILE = "./data/dev_features.mindrecord"
pad = lambda a,i : a[0:i] if len(a) > i else a + [0] * (i-len(a))
pad1 = lambda a,i : a[0:i] if len(a) > i else a + [1] * (i-len(a))
pad_entity = lambda a,i : a[0:i] if len(a) > i else np.append(a,[-1] * (i-len(a)))
#list_dict 为tokenizer之后的token list包含word_ids,word_segment_ids等多个字段
# padding
for slist in list_dict:
slist["entity_attention_mask"] = pad(slist["entity_attention_mask"], 24)
slist["entity_ids"] = pad(slist["entity_attention_mask"], 24)
slist["entity_segment_ids"] = pad(slist["entity_segment_ids"], 24)
slist["word_ids"] = pad1(slist["word_ids"], 256)
slist["word_segment_ids"] = pad(slist["word_segment_ids"], 256)
slist["word_attention_mask"] = pad(slist["word_attention_mask"], 256)
# entity_position padding
entity_size = len(slist["entity_position_ids"])
slist["entity_position_ids"] = np.array(slist["entity_position_ids"])
temp = [[-1]*24 for i in range(24)]
for i in range(24):
if i < entity_size-1:
temp[i]=(pad_entity(slist["entity_position_ids"][i], 24))
slist["entity_position_ids"] =temp
if os.path.exists(SQUAD_MINDRECORD_FILE):
os.remove(SQUAD_MINDRECORD_FILE)
os.remove(SQUAD_MINDRECORD_FILE + ".db")
writer = FileWriter(file_name=SQUAD_MINDRECORD_FILE, shard_num=1)
data_schema = {
"unique_id": {"type": "int32", "shape": [-1]},
"word_ids": {"type": "int32", "shape": [-1]},
"word_segment_ids": {"type": "int32", "shape": [-1]},
"word_attention_mask": {"type": "int32", "shape": [-1]},
"entity_ids": {"type": "int32", "shape": [-1]},
"entity_position_ids": {"type": "int32", "shape": [24,24]},
"entity_segment_ids": {"type": "int32", "shape": [-1]},
"entity_attention_mask": {"type": "int32", "shape": [-1]},
#"start_positions": {"type": "int32", "shape": [-1]},
#"end_positions": {"type": "int32", "shape": [-1]}
}
writer.add_schema(data_schema, "it is a preprocessed squad dataset")
data = []
i = 0
for item in list_dict:
i += 1
sample = {
"unique_id": np.array(item["unique_id"], dtype=np.int32),
"word_ids": np.array(item["word_ids"], dtype=np.int32),
"word_segment_ids": np.array(item["word_segment_ids"], dtype=np.int32),
"word_attention_mask": np.array(item["word_attention_mask"], dtype=np.int32),
"entity_ids": np.array(item["entity_ids"], dtype=np.int32),
"entity_position_ids": np.array(item["entity_position_ids"], dtype=np.int32),
"entity_segment_ids": np.array(item["entity_segment_ids"], dtype=np.int32),
"entity_attention_mask": np.array(item["entity_attention_mask"], dtype=np.int32),
#"start_positions": np.array(item["start_positions"], dtype=np.int32),
#"end_positions": np.array(item["end_positions"], dtype=np.int32),
}
data.append(sample)
#print(sample)
if i % 10 == 0:
writer.write_raw_data(data)
data = []
if data:
writer.write_raw_data(data)
writer.commit()具体数据样例如下:

02
LUKE模型迁移
主要可以参考官网的API映射的文档进行改写。
链接:https://www.mindspore.cn/docs/migration_guide/zh-CN/r1.5/api_mapping/pytorch_api_mapping.html
2.1 实体嵌入部分
例如Entity_Embedding部分,改写前pytorch源码:
class EntityEmbeddings(nn.Module):
def __init__(self, config: LukeConfig):
super(EntityEmbeddings, self).__init__()
self.config = config
self.entity_embeddings = nn.Embedding(config.entity_vocab_size, config.entity_emb_size, padding_idx=0)
if config.entity_emb_size != config.hidden_size:
self.entity_embedding_dense = nn.Linear(config.entity_emb_size, config.hidden_size, bias=False)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(
self, entity_ids: torch.LongTensor, position_ids: torch.LongTensor, token_type_ids: torch.LongTensor = None
):
if token_type_ids is None:
token_type_ids = torch.zeros_like(entity_ids)
entity_embeddings = self.entity_embeddings(entity_ids)
if self.config.entity_emb_size != self.config.hidden_size:
entity_embeddings = self.entity_embedding_dense(entity_embeddings)
position_embeddings = self.position_embeddings(position_ids.clamp(min=0))
position_embedding_mask = (position_ids != -1).type_as(position_embeddings).unsqueeze(-1)
position_embeddings = position_embeddings * position_embedding_mask
position_embeddings = torch.sum(position_embeddings, dim=-2)
position_embeddings = position_embeddings / position_embedding_mask.sum(dim=-2).clamp(min=1e-7)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = entity_embeddings + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings改写后:
class EntityEmbeddings(nn.Cell):
"""entity embeddings for luke model"""
def __init__(self, config):
super(EntityEmbeddings, self).__init__()
self.entity_emb_size = config.entity_emb_size
self.hidden_size = config.hidden_size
self.entity_embeddings = nn.Embedding(config.entity_vocab_size, config.entity_emb_size, padding_idx=0)
if config.entity_emb_size != config.hidden_size:
self.entity_embedding_dense = nn.Dense(config.entity_emb_size, config.hidden_size, has_bias=False)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
self.layer_norm = nn.LayerNorm([config.hidden_size], epsilon=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.unsqueezee = ops.ExpandDims()
def construct(self, entity_ids, position_ids, token_type_ids=None):
"""EntityEmbeddings for luke"""
if token_type_ids is None:
token_type_ids = ops.zeros_like(entity_ids)
entity_embeddings = self.entity_embeddings(entity_ids)
if self.entity_emb_size != self.hidden_size:
entity_embeddings = self.entity_embedding_dense(entity_embeddings)
entity_position_ids_int = clamp(position_ids)
position_embeddings = self.position_embeddings(entity_position_ids_int)
position_ids = position_ids.astype(mstype.int32)
position_embedding_mask = 1.0 * self.unsqueezee((position_ids != -1), -1)
position_embeddings = position_embeddings * position_embedding_mask
position_embeddings = ops.reduce_sum(position_embeddings, -2)
position_embeddings = position_embeddings / clamp(ops.reduce_sum(position_embedding_mask, -2), minimum=1e-7)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = entity_embeddings + position_embeddings
embeddings += token_type_embeddings
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
def clamp(x, minimum=0):
mask = x > minimum
x = x * mask + minimum
return x源码中模型的参数为:
LukeConfig {
"architectures": null,
"attention_probs_dropout_prob": 0.1,
"bert_model_name": "roberta-large",
"bos_token_id": 0,
"do_sample": false,
"entity_emb_size": 256,
"entity_vocab_size": 500000,
"eos_token_ids": 0,
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 1024,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 4096,
"is_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-05,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 514,
"model_type": "bert",
"num_attention_heads": 16,
"num_beams": 1,
"num_hidden_layers": 24,
"num_labels": 2,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pad_token_id": 0,
"pruned_heads": {},
"repetition_penalty": 1.0,
"temperature": 1.0,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 1,
"use_bfloat16": false,
"vocab_size": 50265
}2.2实体感知自注意力机制
输入序列为

,其中,输出的序列为,其中输出向量在输入向量转换后加权求和来计算。在该模型中,每个输入和输出都与一个token相关联,一个token可以是一个单词或实体。在一个有个单词和个实体的序列中,设,第i个输出向量计算过程如下:
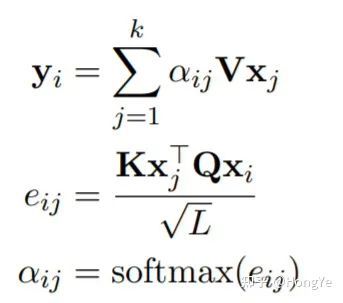
其中
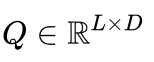
, 分别作为query、key和value矩阵,参数L为注意力头的数目,D为隐藏维度,后文提到该实验L=64,D=1024。
由于LUKE处理两个token的类别,因此论文假设当计算注意力分数(
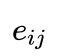
)的时候,使用目标token类别的信息是有益的。在这种思路下,作者通过引入实体感知的查询(query)机制来加强类别信息的提取,该机制对每个可能的token对, 使用不同的查询矩阵。最终注意力分数( )的计算如下:

具体MindSpore实现,如下:
class EntityAwareSelfAttention(nn.Cell):
"""EntityAwareSelfAttention"""
def __init__(self, config):
super(EntityAwareSelfAttention, self).__init__()
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Dense(config.hidden_size, self.all_head_size)
self.key = nn.Dense(config.hidden_size, self.all_head_size)
self.value = nn.Dense(config.hidden_size, self.all_head_size)
self.w2e_query = nn.Dense(config.hidden_size, self.all_head_size)
self.e2w_query = nn.Dense(config.hidden_size, self.all_head_size)
self.e2e_query = nn.Dense(config.hidden_size, self.all_head_size)
# dropout需要 (1 - config.attention_probs_dropout_prob)
self.dropout = nn.Dropout(1 - config.attention_probs_dropout_prob)
self.concat = ops.Concat(1)
self.concat2 = ops.Concat(2)
self.concat3 = ops.Concat(3)
self.sotfmax = ops.Softmax()
self.shape = ops.Shape()
self.reshape = ops.Reshape()
self.transpose = ops.Transpose()
self.softmax = ops.Softmax(axis=-1)
def transpose_for_scores(self, x):
new_x_shape = ops.shape(x)[:-1] + (self.num_attention_heads, self.attention_head_size)
out = self.reshape(x, new_x_shape)
out = self.transpose(out, (0, 2, 1, 3))
return out
def construct(self, word_hidden_states, entity_hidden_states, attention_mask):
"""EntityAwareSelfAttention construct"""
word_size = self.shape(word_hidden_states)[1]
w2w_query_layer = self.transpose_for_scores(self.query(word_hidden_states))
w2e_query_layer = self.transpose_for_scores(self.w2e_query(word_hidden_states))
e2w_query_layer = self.transpose_for_scores(self.e2w_query(entity_hidden_states))
e2e_query_layer = self.transpose_for_scores(self.e2e_query(entity_hidden_states))
key_layer = self.transpose_for_scores(self.key(self.concat([word_hidden_states, entity_hidden_states])))
w2w_key_layer = key_layer[:, :, :word_size, :]
e2w_key_layer = key_layer[:, :, :word_size, :]
w2e_key_layer = key_layer[:, :, word_size:, :]
e2e_key_layer = key_layer[:, :, word_size:, :]
w2w_attention_scores = ops.matmul(w2w_query_layer, ops.transpose(w2w_key_layer, (0, 1, 3, 2)))
w2e_attention_scores = ops.matmul(w2e_query_layer, ops.transpose(w2e_key_layer, (0, 1, 3, 2)))
e2w_attention_scores = ops.matmul(e2w_query_layer, ops.transpose(e2w_key_layer, (0, 1, 3, 2)))
e2e_attention_scores = ops.matmul(e2e_query_layer, ops.transpose(e2e_key_layer, (0, 1, 3, 2)))
word_attention_scores = self.concat3([w2w_attention_scores, w2e_attention_scores])
entity_attention_scores = self.concat3([e2w_attention_scores, e2e_attention_scores])
attention_scores = self.concat2([word_attention_scores, entity_attention_scores])
attention_scores = attention_scores / np.sqrt(self.attention_head_size)
attention_scores = attention_scores + attention_mask
attention_probs = self.softmax(attention_scores)
attention_probs = self.dropout(attention_probs)
value_layer = self.transpose_for_scores(
self.value(self.concat([word_hidden_states, entity_hidden_states]))
)
context_layer = ops.matmul(attention_probs, value_layer)
context_layer = ops.transpose(context_layer, (0, 2, 1, 3))
new_context_layer_shape = ops.shape(context_layer)[:-2] + (self.all_head_size,)
context_layer = self.reshape(context_layer, new_context_layer_shape)
return context_layer[:, :word_size, :], context_layer[:, word_size:, :]需要注意的是MindSpore中的dropout与pytorch的dropout不一样。
例如pytorch中dropout的入参为0.1,则MindSpore的dropout入参应为0.9。
03
权重迁移pytorch->MindSpore
由于官网已经提供了微调好的权重信息,所以我们尝试直接转换权重进行预测。
我们先要知道模型权重名称以及形状等,需要pytorch与MindSpore模型一一对应。
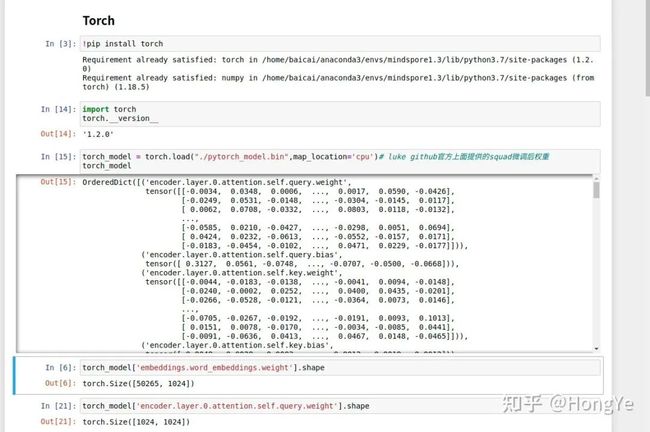
然后在输出MindSpore模型:
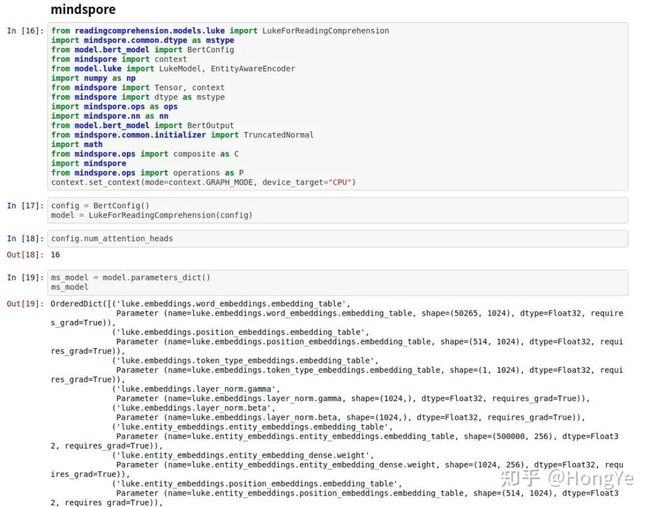
最后写权重转换函数:
## torch2ms
import os
import collections
from mindspore import log as logger
from mindspore.common.tensor import Tensor
from mindspore.common.initializer import initializer
from mindspore import save_checkpoint
from mindspore import Parameter
def build_params_map(layer_num=24):
"""
build params map from torch's LUKE to mindspore's LUKE
map=> key:value,torch_name:ms_name
键:torch权重名称,值:mindspore权重名称
:return:
"""
weight_map = collections.OrderedDict({
'embeddings.word_embeddings.weight': "luke.embeddings.word_embeddings.embedding_table",
'embeddings.position_embeddings.weight': "luke.embeddings.position_embeddings.embedding_table",
'embeddings.token_type_embeddings.weight': "luke.embeddings.token_type_embeddings.embedding_table",
'embeddings.LayerNorm.weight': 'luke.embeddings.layer_norm.gamma',
'embeddings.LayerNorm.bias': 'luke.embeddings.layer_norm.beta',
'entity_embeddings.entity_embeddings.weight':'luke.entity_embeddings.entity_embeddings.embedding_table',
'entity_embeddings.entity_embedding_dense.weight':'luke.entity_embeddings.entity_embedding_dense.weight',
'entity_embeddings.position_embeddings.weight':'luke.entity_embeddings.position_embeddings.embedding_table',
'entity_embeddings.token_type_embeddings.weight':'luke.entity_embeddings.token_type_embeddings.embedding_table',
'entity_embeddings.LayerNorm.weight':'luke.entity_embeddings.layer_norm.gamma',
'entity_embeddings.LayerNorm.bias':'luke.entity_embeddings.layer_norm.beta',
'qa_outputs.weight':'qa_outputs.weight',
'qa_outputs.bias':'qa_outputs.bias',
# 'pooler.dense.weight':'pooler.weight',
# 'pooler.dense.bias':'pooler.bias'
})
# add attention layers
for i in range(layer_num):
weight_map[f'encoder.layer.{i}.attention.self.query.weight'] = \
f'luke.encoder.layer.{i}.attention.self_attention.query.weight'
weight_map[f'encoder.layer.{i}.attention.self.query.bias']= \
f'luke.encoder.layer.{i}.attention.self_attention.query.bias'
weight_map[f'encoder.layer.{i}.attention.self.key.weight']= \
f'luke.encoder.layer.{i}.attention.self_attention.key.weight'
weight_map[f'encoder.layer.{i}.attention.self.key.bias']= \
f'luke.encoder.layer.{i}.attention.self_attention.key.bias'
weight_map[f'encoder.layer.{i}.attention.self.value.weight']= \
f'luke.encoder.layer.{i}.attention.self_attention.value.weight'
weight_map[f'encoder.layer.{i}.attention.self.value.bias']= \
f'luke.encoder.layer.{i}.attention.self_attention.value.bias'
weight_map[f'encoder.layer.{i}.attention.self.w2e_query.weight']= \
f'luke.encoder.layer.{i}.attention.self_attention.w2e_query.weight'
weight_map[f'encoder.layer.{i}.attention.self.w2e_query.bias']= \
f'luke.encoder.layer.{i}.attention.self_attention.w2e_query.bias'
weight_map[f'encoder.layer.{i}.attention.self.e2w_query.weight']= \
f'luke.encoder.layer.{i}.attention.self_attention.e2w_query.weight'
weight_map[f'encoder.layer.{i}.attention.self.e2w_query.bias']= \
f'luke.encoder.layer.{i}.attention.self_attention.e2w_query.bias'
weight_map[f'encoder.layer.{i}.attention.self.e2e_query.weight']= \
f'luke.encoder.layer.{i}.attention.self_attention.e2e_query.weight'
weight_map[f'encoder.layer.{i}.attention.self.e2e_query.bias']= \
f'luke.encoder.layer.{i}.attention.self_attention.e2e_query.bias'
weight_map[f'encoder.layer.{i}.attention.output.dense.weight']= \
f'luke.encoder.layer.{i}.attention.output.dense.weight'
weight_map[f'encoder.layer.{i}.attention.output.dense.bias'] = \
f'luke.encoder.layer.{i}.attention.output.dense.bias'
weight_map[f'encoder.layer.{i}.attention.output.LayerNorm.weight'] = \
f'luke.encoder.layer.{i}.attention.output.layernorm.gamma'
weight_map[f'encoder.layer.{i}.attention.output.LayerNorm.bias'] = \
f'luke.encoder.layer.{i}.attention.output.layernorm.beta'
weight_map[f'encoder.layer.{i}.intermediate.dense.weight'] = \
f'luke.encoder.layer.{i}.intermediate.weight'
weight_map[f'encoder.layer.{i}.intermediate.dense.bias'] = \
f'luke.encoder.layer.{i}.intermediate.bias'
weight_map[f'encoder.layer.{i}.output.dense.weight'] = \
f'luke.encoder.layer.{i}.output.dense.weight'
weight_map[f'encoder.layer.{i}.output.dense.bias'] = \
f'luke.encoder.layer.{i}.output.dense.bias'
weight_map[f'encoder.layer.{i}.output.LayerNorm.weight'] = \
f'luke.encoder.layer.{i}.output.layernorm.gamma'
weight_map[f'encoder.layer.{i}.output.LayerNorm.bias'] = \
f'luke.encoder.layer.{i}.output.layernorm.beta'
# add pooler
# weight_map.update(
# {
# 'pooled_fc.w_0': 'ernie.ernie.dense.weight',
# 'pooled_fc.b_0': 'ernie.ernie.dense.bias',
# 'cls_out_w': 'ernie.dense_1.weight',
# 'cls_out_b': 'ernie.dense_1.bias'
# }
# )
return weight_map
def _update_param(param, new_param):
"""Updates param's data from new_param's data."""
if isinstance(param.data, Tensor) and isinstance(new_param.data, Tensor):
if param.data.dtype != new_param.data.dtype:
logger.error("Failed to combine the net and the parameters for param %s.", param.name)
msg = ("Net parameters {} type({}) different from parameter_dict's({})"
.format(param.name, param.data.dtype, new_param.data.dtype))
raise RuntimeError(msg)
if param.data.shape != new_param.data.shape:
if not _special_process_par(param, new_param):
logger.error("Failed to combine the net and the parameters for param %s.", param.name)
msg = ("Net parameters {} shape({}) different from parameter_dict's({})"
.format(param.name, param.data.shape, new_param.data.shape))
raise RuntimeError(msg)
return
param.set_data(new_param.data)
return
if isinstance(param.data, Tensor) and not isinstance(new_param.data, Tensor):
if param.data.shape != (1,) and param.data.shape != ():
logger.error("Failed to combine the net and the parameters for param %s.", param.name)
msg = ("Net parameters {} shape({}) is not (1,), inconsistent with parameter_dict's(scalar)."
.format(param.name, param.data.shape))
raise RuntimeError(msg)
param.set_data(initializer(new_param.data, param.data.shape, param.data.dtype))
elif isinstance(new_param.data, Tensor) and not isinstance(param.data, Tensor):
logger.error("Failed to combine the net and the parameters for param %s.", param.name)
msg = ("Net parameters {} type({}) different from parameter_dict's({})"
.format(param.name, type(param.data), type(new_param.data)))
raise RuntimeError(msg)
else:
param.set_data(type(param.data)(new_param.data))
def _special_process_par(par, new_par):
"""
Processes the special condition.
Like (12,2048,1,1)->(12,2048), this case is caused by GE 4 dimensions tensor.
"""
par_shape_len = len(par.data.shape)
new_par_shape_len = len(new_par.data.shape)
delta_len = new_par_shape_len - par_shape_len
delta_i = 0
for delta_i in range(delta_len):
if new_par.data.shape[par_shape_len + delta_i] != 1:
break
if delta_i == delta_len - 1:
new_val = new_par.data.asnumpy()
new_val = new_val.reshape(par.data.shape)
par.set_data(Tensor(new_val, par.data.dtype))
return True
return False
def extract_and_convert(torch_model, ms_model):
"""extract weights and convert to mindspore"""
print('=' * 20 + 'extract weights' + '=' * 20)
state_dict = []
weight_map = build_params_map(layer_num=24)
for weight_name, weight_value in torch_model.items():
if weight_name not in weight_map.keys():
continue
state_dict.append({'name': weight_map[weight_name], 'data': Tensor(weight_value.numpy())})
value = Parameter(Tensor(weight_value.numpy()),name=weight_map[weight_name])
key = ms_model[weight_map[weight_name]]
_update_param(key, value)
print(weight_name, '->', weight_map[weight_name], weight_value.shape)
save_checkpoint(model, os.path.join("./luke-large-qa.ckpt"))
print('=' * 20 + 'extract weights finished' + '=' * 20)
extract_and_convert(torch_model,ms_model)这里名称一定要一一对应。如果后期改动了模型,也需要在检查一下这个转换函数是否能对应。
04
评估测试
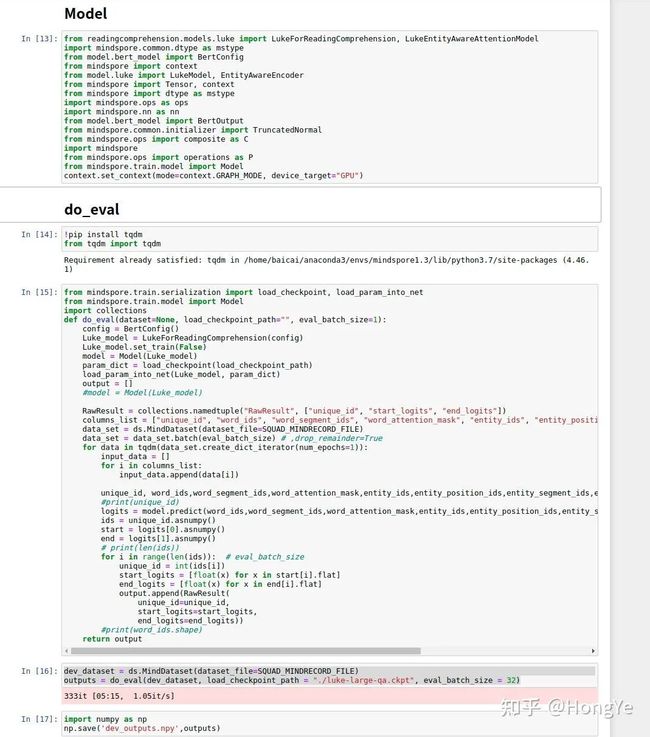
我们将输出后的概率进行后处理,可以得到最终的预测答案。
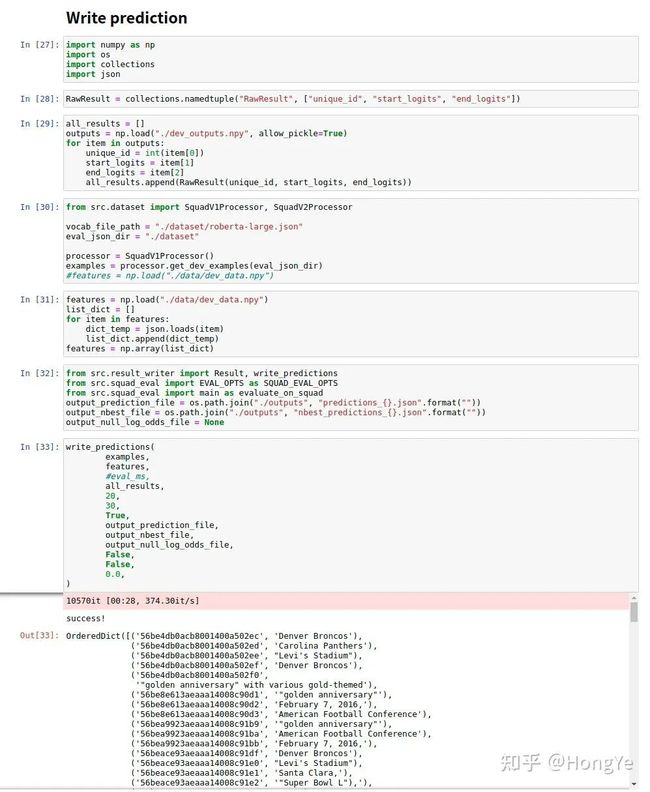
最后将预测值与标准答案进行评估,得到最后的F1分数。
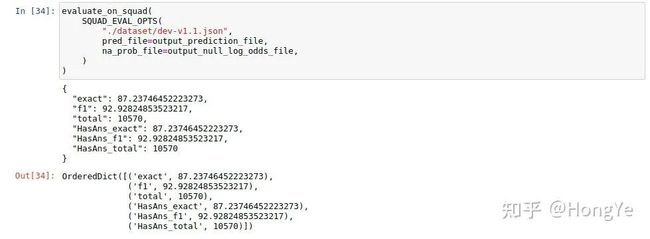
(训练相关等将于后续更新)
参考链接:
[1] luke源码:
https://github.com/studio-ousia/luke
[2] luke论文:
https://aclanthology.org/2020.emnlp-main.523.pdf
[3] 参考文章:
https://zhuanlan.zhihu.com/p/381626609

MindSpore官方资料
GitHub : https://github.com/mindspore-ai/mindspore
Gitee : https : //gitee.com/mindspore/mindspore
官方QQ群 : 871543426