华为AI认证_NLP
实验一:jieba分词
import jieba
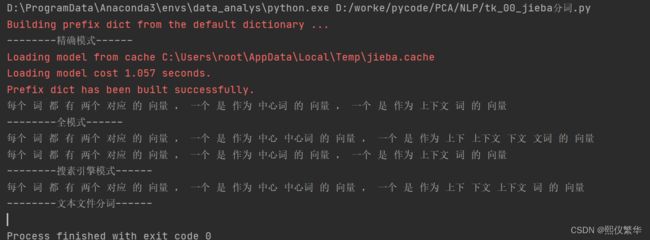
# 精确模式
print("--------精确模式------")
# 分词的语料库
s="每个词都有两个对应的向量,一个是作为中心词的向量,一个是作为上下文词的向量"
cut=jieba.cut(s,cut_all=False,HMM=False)
# print(cut)
print(' '.join(cut))
#全模式
print("--------全模式------")
print(' '.join(jieba.cut(s,cut_all=True)))
print(' '.join(jieba.cut(s,cut_all=False,HMM=True)))
# 搜素引擎模式
print("--------搜素引擎模式------")
print(' '.join(jieba.cut_for_search(s)))
# 文本文件分词
print("--------文本文件分词------")
old_file="./data/华为.txt"
new_file="./data/华为cut.txt"
# 读取数据
with open(old_file,'r') as f:
text=f.read()
# 分词
new_text=jieba.cut(text,cut_all=False)
# 去除标点符号
str_out=' '.join(new_text).replace(',','').replace('。','').replace('?','')
# 数据写入和保存
with open(new_file,'w',encoding='utf-8') as f:
f.write(str_out)运行:
实验二:word2vec
代码:
import jieba
import os
import gensim
from gensim.models import word2vec,Word2Vec
# 定义语料库存放路径和模型保存路径
cut_file = r'data/华为cut.txt'
save_model = r'model/华为.model'
def model_train(train_file,save_model):
'''
模型训练的函数
:param train_file: 数据存放路径
:param save_model: 模型保存路径
:return:
'''
print("Training...........")
# 加载语料库
sentences = word2vec.Text8Corpus(train_file)
# 模型训练,生成词向量
model = Word2Vec(sg=1,vector_size=200,alpha=0.00001,epochs=10000,min_count=2)
# 训练skip-gram模型
model.build_vocab(sentences)
# 保存模型
model.save(save_model)
# 调用模型
if not os.path.exists(save_model):
model_train(cut_file, save_model)
else:
print("模型已存在,不需要再次训练")
# 加载模型
model = Word2Vec.load(save_model)
print(model)
# 输入原始文档中的两个词,计算相似度
y1 = model.wv.similarity('华为','芯片')
print('华为&芯片的相似度:',y1)实验三: 文本分类
3.1 特征提取——词袋法
import jieba
from sklearn.feature_extraction.text import CountVectorizer
jieba_token=jieba.cut #指定分词模式
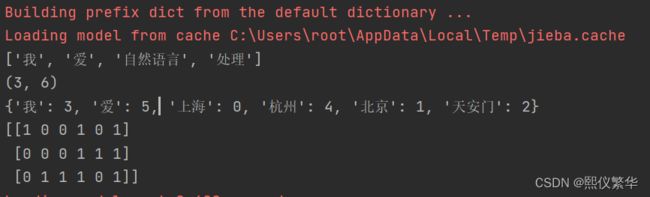
print(list(jieba_token("我爱自然语言处理")))
corpus=['我爱上海','我爱杭州','我爱北京天安门'] #指定文本信息
countVect=CountVectorizer(tokenizer=jieba_token) #初始化CountVectorizer() 实例 并指定分割器
x_train=countVect.fit_transform(corpus) #词向量化
print(x_train.shape)
print(countVect.vocabulary_) #查看词袋模型
print(x_train.toarray()) #转换成列表运行:
3.2 特征提取——TF_IDF
代码:
import jieba
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer
jieba_token=jieba.cut #指定分词模式
corpus=['我爱上海','我爱杭州','我爱北京天安门'] #指定文本信息
# 初始化词袋模型
countVect=CountVectorizer(tokenizer=jieba_token) #初始化CountVectorizer() 实例 并指定分割器
# 初始化tf_idf
tfidfTransf=TfidfTransformer()
# 先转化成词袋矩阵
x_train_count=countVect.fit_transform(corpus) #词向量化
# 在转化成TF-IDF 矩阵
x_train=tfidfTransf.fit_transform(x_train_count)
print(x_train.shape)
# 查看词袋模型
print(countVect.vocabulary_) #查看词袋模型
print(x_train.toarray()) #转换成列表 查看结果运行:
(3, 6)
{'我': 3, '爱': 5, '上海': 0, '杭州': 4, '北京': 1, '天安门': 2}
Loading model cost 1.069 seconds.
Prefix dict has been built successfully.
[[0.76749457 0. 0. 0.45329466 0. 0.45329466]
[0. 0. 0. 0.45329466 0.76749457 0.45329466]
[0. 0.6088451 0.6088451 0.35959372 0. 0.35959372]]
实验四 文本特征选择
4.1 卡方检验
import jieba
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_selection import SelectKBest,chi2
docs = [
'我爱自然语言处理',
'我恨自然语言处理',
'我很喜欢这本书',
'我很讨厌这本书',
'我喜欢使用python语言',
] # 待进行处理的文本
labels = [0,1,0,1,0]
countVec = CountVectorizer(tokenizer=jieba.cut) # 初始化词袋模型
x_train = countVec.fit_transform(docs)
chi2Select = SelectKBest(chi2,k=10)
chi2Select.fit(x_train,labels)
score = pd.DataFrame(
list(zip(countVec.get_feature_names(),chi2Select.scores_,chi2Select.pvalues_)),
columns= ['word','score','pval']
)
print(score.sort_values('score',ascending=True))运行:
word score pval
6 我 0.000000 1.000000
3 处理 0.083333 0.772830
4 很 0.083333 0.772830
7 本书 0.083333 0.772830
9 自然语言 0.083333 0.772830
12 这 0.083333 0.772830
0 python 0.666667 0.414216
1 使用 0.666667 0.414216
8 爱 0.666667 0.414216
11 语言 0.666667 0.414216
2 喜欢 1.333333 0.248213
5 恨 1.500000 0.220671
10 讨厌 1.500000 0.220671实验五 朴素贝叶斯文本分类
import jieba
import pandas as pd
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import classification_report,accuracy_score
# 加载数据
train = pd.read_csv('./data/chnsenticorp/train.tsv',sep="\t")
test = pd.read_csv('./data/chnsenticorp/test.tsv',sep='\t')
labels = {0:'垃圾邮件',1:'正常邮件'}
# 将特征和目标值分开
x_train,y_train = train.text_a.values,train.label.values
x_test,y_test = test.text_a.values,test.label.values
print(x_train)
# 定义分类器
class NB_Classifier():
def __init__(self):
# 朴素贝叶斯分类器
self.model = MultinomialNB(alpha=1.0) # alpha=1.0 是拉普拉斯平滑系数
# 初始化TF-IDF
self.processor = TfidfVectorizer(tokenizer=jieba.cut)
# 训练模型
def fit(self,x_train,y_train):
# 利用tf-idf进行特征提取
x_train_fea = self.processor.fit_transform(x_train)
# 利用朴素贝叶斯进行模型训练
self.model.fit(x_train_fea,y_train)
# 获取准确率
train_accuracy = self.model.score(x_train_fea,y_train)
print("训练集的准确率:{}".format(round(train_accuracy,2)))
def textFit(self,x_test,y_test):
'''
测试模型
:param x_test:
:param y_test:
:return:
'''
x_test_fea = self.processor.transform(x_test) # 提取特征值
y_predict = self.model.predict(x_test_fea) # 获取测试结果
# test_accuracy = self.model.score(x_test_fea,y_test) # 获取测试集的准确率
# print(y_predict)
# print("测试集的准确率:{}".format(round(test_accuracy,2)))
print("预测结果:",y_predict[:10])
print("真实结果:",y_test[:10])
print("测试集预测结果:\n")
print(classification_report(y_test,y_predict,target_names=['0','1']))
def single_pridect(self,text):
'''
使用训练好的模型,预测数据
:param text: 待预测的文本
:return:
'''
text_preprocess = [' '.join(jieba.cut(text))] # 对文本进行分词
text_fea = self.processor.transform(text_preprocess) # 特征提取
predict_idx = self.model.predict(text_fea)[0] # 对数据进行预测,并把第一个结果获取出来 获取到的值是0/1
predict_label = labels[predict_idx] # 根据predict_idx的值从目标值字典中获取对应的键
predict_prob = self.model.predict_proba(text_fea)[0][predict_idx]
return predict_label,predict_prob
# 初始化分类器
nb_classifiter = NB_Classifier()
# 训练模型
nb_classifiter.fit(x_train,y_train)
# 测试模型
nb_classifiter.textFit(x_test,y_test)
# 调用模型预测
(predict_label,predict_prob) = nb_classifiter.single_pridect("外观很漂亮,出人意料的漂亮,做工非常好。")
print((predict_label,predict_prob))
(predict_label,predict_prob) = nb_classifiter.single_pridect("书的内容没什么好说的,主要是纸张,印刷太差了。")
print((predict_label,predict_prob))
D:\ProgramData\Anaconda3\envs\data_analys\python.exe D:/worke/pycode/PCA/NLP/tk_05_朴素贝叶斯分类器.py
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\root\AppData\Local\Temp\jieba.cache
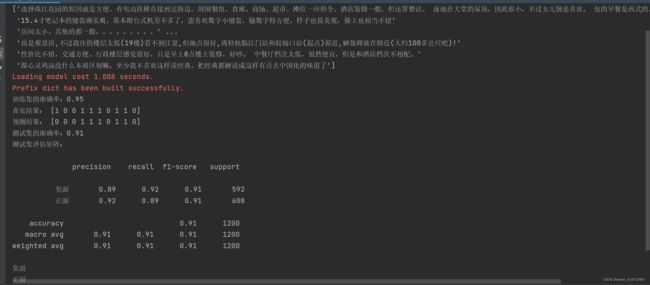
['选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般'
'15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错'
'房间太小。其他的都一般。。。。。。。。。' ...
'虽是观景房,不过我住的楼层太低(19楼)看不到江景,但地点很好,离轻轨临江门站和较场口站(起点)很近,解放碑就在附近(大约100多公尺吧)!'
'性价比不错,交通方便。行政楼层感觉很好,只是早上8点楼上装修,好吵。 中餐厅档次太低,虽然便宜,但是和酒店档次不相配。'
'跟心灵鸡汤没什么本质区别嘛,至少我不喜欢这样读经典,把经典都解读成这样有点去中国化的味道了']
Loading model cost 0.795 seconds.
Prefix dict has been built successfully.
训练集的准确率:0.94
预测结果: [1 0 0 1 1 1 0 1 1 0]
真实结果: [1 0 0 1 1 1 0 1 1 0]
测试集预测结果:
precision recall f1-score support
0 0.87 0.88 0.88 592
1 0.88 0.88 0.88 608
accuracy 0.88 1200
macro avg 0.88 0.88 0.88 1200
weighted avg 0.88 0.88 0.88 1200
('正常邮件', 0.8284518713640118)
('垃圾邮件', 0.6876365064367929)
Process finished with exit code 0
实验六 SVM 文本分类
代码:
import jieba
import pandas as pd
from sklearn import svm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_selection import SelectKBest,chi2
from sklearn.metrics import classification_report,accuracy_score
# 加载数据
train = pd.read_csv('data/chnsenticorp/train.tsv',sep='\t')
test = pd.read_csv('data/chnsenticorp/test.tsv',sep='\t')
labels = {0:'正面',1:'负面'}
# 将特征和目标值分开
x_train,y_train = train.text_a.values,train.label.values
x_test,y_test = test.text_a.values,test.label.values
print(x_train)
# 定义分类器,训练,测试函数
class SVN_Classifier():
def __init__(self,use_chi=False):
self.use_chi = use_chi # 是否使用卡方检验
self.model = svm.SVC(C=1.0,kernel='linear',degree=3,gamma='auto') # 初始化分类器
self.process = TfidfVectorizer(tokenizer=jieba.cut)
# 卡方校验特征选择
if use_chi:
self.selector = SelectKBest(chi2,k=10000) # 34814 --》 10000
def fit(self,x_train,y_train):
'''
训练模型
:param x_train:
:param y_train:
:return:
'''
x_train_fea= self.process.fit_transform(x_train)
if self.use_chi: # use_chi == True时,选择做卡方校验
x_train_fea = self.selector.fit_transform(x_train_fea,y_train)
self.model.fit(x_train_fea,y_train)
# 获取准确率
train_accuracy = self.model.score(x_train_fea, y_train)
print("训练集的准确率:{}".format(round(train_accuracy, 2)))
def testFit(self,x_test,y_test):
'''
测试模型
:param x_test:
:param y_test:
:return:
'''
x_test_fea= self.process.transform(x_test)
if self.use_chi: # use_chi == True时,选择做卡方校验
x_test_fea = self.selector.transform(x_test_fea)
y_predict = self.model.predict(x_test_fea)
print("真实结果:",y_test[:10])
print("预测结果:",y_predict[:10])
test_accuracy = accuracy_score(y_test,y_predict) # 获取准确率
print("测试集的准确率:{}".format(round(test_accuracy,2)))
print("测试集评估矩阵:\n")
print(classification_report(y_test,y_predict,target_names=['负面','正面']))
def single_predict(self,text):
'''
预测结果
:param text:
:return:
'''
text_preprocess = [' '.join(jieba.cut(text))] # 对文本进行分词
text_fea = self.process.transform(text_preprocess) # 特征提取
if self.use_chi:
text_fea = self.selector.transform(text_fea)
predict_idx = self.model.predict(text_fea)[0] # 对数据进行预测,并把第一个结果获取出来 获取到的值是0/1
predict_label = labels[predict_idx] # 根据predict_idx的值从目标值字典中获取对应的键
print(predict_label)
# 训练SVN分类器,不使用卡方校验
# svm_classifier = SVN_Classifier()
# svm_classifier.fit(x_train,y_train)
# 训练SVN分类器,使用卡方校验
svm_classifier = SVN_Classifier(use_chi=True)
svm_classifier.fit(x_train,y_train)
#测试模型
svm_classifier.testFit(x_test,y_test)
# 测试
svm_classifier.single_predict("外观很漂亮,出人意料的漂亮,做工非常好。")
svm_classifier.single_predict("书的内容没什么好说的,主要是纸张,印刷太差了。")运行:
实验七 TextCNN
代码:
import jieba
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 加载数据
train=pd.read_csv('data/chnsenticorp/train.tsv',sep='\t')
valid=pd.read_csv('data/chnsenticorp/dev.tsv',sep='\t')
test=pd.read_csv('data/chnsenticorp/test.tsv',sep='\t')
# 特征和目标值分开
x_train,y_train=train.text_a.values,train.label.values
x_valid,y_valid=valid.text_a.values,valid.label.values
x_test,y_test=test.text_a.values,test.label.values
# 构建词汇表
vocab=set() #词汇表
def create_Vocab():
cut_docs=train.text_a.apply(lambda x:jieba.cut(x)).values #分词
for doc in cut_docs:
for word in doc:
# print(word)
if word.strip():
vocab.add(word.strip())
print(vocab)
# 将词汇表写入本地文件
with open('data/vocab.txt','w',encoding='utf-8') as f:
for word in vocab:
f.write(word)
f.write('\n')
# create_Vocab()
# 设置配置变量
class Config():
embedding_dim=300 #词向量维度
max_seq_len=200 # 文章最大词数
vocab_file='data/vocab.txt' #词汇表的路径
# 初始化参数配置
config=Config()
# 定义预处理类 用于将文本分词转转化成id
class Preprocessor():
def __init__(self,config):
self.config=config
#初始化词和id的映射词典 预留0 给padding字符 预留1 给词汇表中未见过词
token2idx={'[PAD]':0,'[UNK]':1} #{word:id}
with open(config.vocab_file,'r',encoding='utf-8') as f:
for index,line in enumerate(f):
token=line.strip()
token2idx[token]=index+2
self.token2idx=token2idx
# print(self.token2idx)
"""
token2idx
{'[PAD]': 0, '[UNK]': 1, '书架上': 2, '情不自禁'
"""
def transform(self,text_list):
"""
文本分词,并将词转换成相应的id,最后不同长度的文本 用padding统一长度(后面补0)
:param test_list:
:return:
"""
# for text in text_list:
# for word in jieba.cut(text):
# inx_list=self.token2idx.get(word.strip(),self.token2idx['[UNk]'])
inx_list=[[self.token2idx.get(word.strip(),self.token2idx['[UNK]']) for word in text] for text in text_list]
# print(inx_list)
"""
[[6063, 24278, 1, 34846, 9732, 2430, 8392, 25183, 2546, 14918, 26979], [6063, 20257, 24278, 1, 34846, 9732, 1, 7489, 5647, 7489]]
"""
idx_padding=pad_sequences(inx_list,self.config.max_seq_len,padding='post')
# print(idx_padding)
return idx_padding
"""
[[ 6063 24278 1 34846 9732 2430 8392 25183 2546 14918 26979 0
......
0 0 0 0 0 0 0 0]
[ 6063 20257 24278 1 34846 9732 1 7489 5647 7489 0 0
......
0 0 0 0 0 0 0 0]]
"""
preprocessor=Preprocessor(config)
idx_padding=preprocessor.transform(["我喜欢使用Python","我也喜欢使用java"])
class TextCNN():
def __init__(self,config):
self.model = None
self.config=config
self.preprocessor=Preprocessor(config)
self.class_name={0:'负面',1:'正面'}
def buid_model(self):
"""
编译模型
:return:
"""
#模型框架搭建
idx_input=tf.keras.layers.Input((self.config.max_seq_len,)) #确定数据的输入
input_embedding=tf.keras.layers.Embedding(len(self.preprocessor.token2idx),
self.config.embedding_dim,
input_length=self.config.max_seq_len,
mask_zero=True
)(idx_input)
convs=[]
for kernel_size in[3,4,5]:
c=tf.keras.layers.Conv1D(128,kernel_size,activation="relu")(input_embedding) #卷积层
c = tf.keras.layers.GlobalMaxPool1D()(c) #池化层 GlobalMaxPool1D
convs.append(c)
fea_cnn=tf.keras.layers.Concatenate()(convs)
fea_dense=tf.keras.layers.Dense(128,activation="relu")(fea_cnn) #全连接层
output=tf.keras.layers.Dense(2,activation="softmax")(fea_dense) #输出层
# 编译模型
model=tf.keras.Model(inputs=idx_input,outputs=output)
model.compile(loss=tf.keras.losses.categorical_crossentropy, #交叉熵损失
optimizer='adam', #优化器
metrics=['accuracy'] #评估规则 准确率
)
model.summary()
self.model=model
def fit(self,x_train,y_train,x_valid=None,y_valid=None,epochs=5,batch_size=128,**kwargs):
"""
训练模型
:param x_train: 训练集的特征值
:param y_train: 训练集的目标值
:param x_valid: 验证集特征值
:param y_valid: 验证集的目标值
:param epochs:迭代次数
:param batch_size:批处理数量
:param kwargs:
:return:
"""
# 编译
self.buid_model()
x_train=self.preprocessor.transform(x_train) #特征提取
if x_valid is not None and y_valid is not None: #验证集不为空时提取特征
x_valid=self.preprocessor.transform(x_valid)
self.model.fit(
x=x_train,
y=y_train,
validation_data=(x_valid,y_valid) if x_valid is not None and y_valid is not None else None,
batch_size=batch_size,
epochs=epochs,
**kwargs
)
textCNN=TextCNN(config)
textCNN.fit(x_train,y_train,x_valid,y_valid,epochs=5)运行:结果在代码段中