GPT系列论文精读-GPT1
GPT与BERT、Transformer的关系
Transformer发表在2017年6月,在一年之后GPT出来了,GPT的核心数据把Transformer的解码器拿出来,在大量没有文本的数据集上训练一个语言模型然后获得一个预训练模型,然后再用它在任务上做微调,最终得到每一个任务所要的分类器的。
BERT有小道消息传闻是在GPT出来后两个月,出来了。BERT是把Transformer的编码器拿出来,用来做预训练,结果比GPT好很多。又过了四个月后,GPT2出来了,GPT2是原作者这帮人吸取了前面的教训,收集了一个更大训练集,得到了一个更大的模型,发现GPT2非常适合做zero shoot,用解码器来深入挖掘模型的潜力,但是效果没那么惊艳,于是在一年又3个月之后,GPT3对于GPT2的改进就是数据和模型都大了100倍,暴力出了奇迹,效果非常炸裂。
GPT是由Open AI开发的,BERT是有Google做的,看论文引用数能够看到GPT在学术上的影响力不及BERT,BERT引用量27k,而将GPT,GPT2,GPT3加起来还不到BERT的二分之一。GPT的引用率稍低,不是因为他的创新度或者他的效果不如BERT系列,恰恰相反,是因为Open AI选择去解决更大的问题。所以他在技术上实现更难一些,如果要效果更炸裂一些,必须做到GPT3,但是没有别的团队能够做到如此大的模型,当然也无法取得GPT3这样良好的结果。
OPEN AI这么做,是因为他们公司想做强人工智能,想去解决一个更大的问题,BERT,Transformer来自Google一些独立的研究组,他们一开始想解决的问题其实都比较小,Transformer一开始比较想解决翻译的问题,从一个序列翻译到另一个序列。BERT思想其实也挺实在的,想把计算机视觉种成熟的,先训练一个预训练模型,然后再做微调出任务的结果,这一套方法能够把NLP做好,因为他们能实实在在提升技术的效果。所以在同样模型大小,比如说是一个亿级别的模型大小,BERT的性能是要好于GPT的,就是未来的工作更倾向于BERT,因为我咬咬牙还是能找到足够的机器,能把我的模型跑起来,而且效果不错。如果用GPT3的话,因为模型过于庞大,所以即便是把你卖了你还是跑不起那个实验。
GPT和BERT的区别,BERT用的不是标准的语言模型,它用的是一个带掩码的语言模型,可以理解为它就是完形填空,完形填空就是给一个句子,把中间的一个词挖掉,预测中间的,就是说在预测的时候既能看到它之前的词,又能看到之后词,因此它可以使用Transformer的编码器,因为编码器上可以看到所有的信息。
使用编码器和解码器不是他们两个的主要区别,主要区别在于他们目标函数的选取,GPT用的是一个更难的,就是给前面一段话预测后面一个词,预测未来当然比完形填空要难。就是预测一个开放性结局你预测中间的一个状态难得多。这个也是GPT其实比BERT要差一些的一个原因。那么反过来讲如果这个模型真的能够预测未来的话。那么这个模型比BERT这种通过完型填空模型要强大的多。这也是作者为什么一直不断把模型做大,甚至能做到GPT3这样的模型出来。这也是作者选择了一个更难的技术路线,但有可能它的天花板也就更高了。
Improving Language Understanding by Generative Pre-Traininghttps://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
GPT文章的标题叫做使用通用的预训练来提升语言的理解能力。GPT并没有给自己的文章起标题,所以GPT的名字来自于后面人给他的,GPT三个自己的单次的首字母。而且Open AI的作者在之后对它持续改进,后面有GPT2,GPT3。
Ilya Sutskeve是AlexNet 的二作,然后他去了Open AI担任CTO,所以Open AI很多工作都挂了他的名字,作为最后一个作者。
1.摘要
摘要写的比较简单,前两句话说的是要解决什么问题,说在NLP任务中有很多不一样的任务,虽然我们有很多大量的没有标签的文本数据,但是有标签的数据训练的效果比较好,所以如果我们想要在没有标签的数据集上训练出好的模型比较难。因此作者提出了一个想法,在无标签的数据上训练一个预训练模型,然后在这些有标签的子任务上训练一个微调模型。
在NLP中没有像ImageNet那么大规模标好的那种数据,这导致在NLP在深度学习的进展比较慢,直到BERT和GPT之后才打开了局面。先训练好预训练模型,然后再做微调,我们使用的是没有标签的文本,然后再GPT系列后面的文章才开始做Zero Shoot,如果说计算机视觉在前几年引领计算机视觉的潮流,后面的创新来自于自然语言处理。而且这些创新也在反馈回计算机视觉里面,比如MLE,就是把BERT用回到计算机视觉上。
当然在自然语言处理界,使用没有标号的数据不是第一次了,比如说十几年前很火的WordToVector,这个词嵌入模型就是用的大量的没有标号的文本,但这里是说跟之前工作的一个区别是,他们是在微调的时候构造与你任务相关的输入,从而使得我们只要很少的改变模型的架构就行了。这是因为文本和图像不一样,他的任务更加多样性一些,有些任务说是对词做些标注,有些任务需要对句子进行判断,有的句子是说我需要一对句子或者三个句子做推理,还有一些应用是说我要生成一个句子,所以导致每个任务都需要有自己的模型,我们最早的词嵌入只是做一个词上面的一个学习,然后你后面的模型还是要构造。
之前的工作需要把模型做一些改变,来适应各个任务,但是这个地方我们只要改变输入的形式就行了,而不需要改变模型,读BERT就知道怎么做了,但是GPT是在BERT之前的出现的,所以它的提出是有新意的,最后从实验结果可以看到,在12个任务上有9个任务能够超过当时的最好的成绩,所以看上去是稍微落于BERT,因为BERT它在10几个任务都超越前面,所以这也说明了为什么BERT出来之后比GPT更有影响力,因为他的效果更好些,但是从创新度来讲,GPT要在BERT之上,因为它毕竟是前面的工作,BERT在很多时候他的思路也是一样的。
2.导言
接下来我们看下导言,导言的第一句话,讲的是我们之前提到的问题,就是怎么样更好的利用无标签的文本,作者提到当时最成功的模型该是词嵌入模型。第二段是在使用无标签的文本时,遇到的一些困难。讲了两个困难,第一个困难是不知道怎样来优化目标函数,就是给你一堆文本,不知道你的损失函数长什么样子,当时有很多选择,比如说你有语言模型,有机器翻译,或者文本的一致性。但没发现某一个特别好,就是一个目标函数在一些任务上比较好,另一个目标函数在另外一些问题上比较好。就是看你的目标函数和你的子任务上,它的相关度有多高。第二个难点是怎么把你学到的这些文本的表示传递到你下游的子任务上。这是因为NLP里面下游的子任务差别比较大,没有一个简单统一的有效的方式,使得一种表示能够一致的迁移到所有的子任务上面。
GPT这篇文章提出了一个半监督的方法,在没有标号的文本上训练一个比较大的语言模型,然后在子任务上进行微调。当然我们现在对这一套比较熟悉,但是有意思的是说你回到当年,作者用的是半监督学习,半监督学习在机器学习界很火,他的核心说我有一些有标签的数据,但我还有大量的相似的但没有标签的数据,怎么把这些没标签的数据用过来,就是半监督学习想学的东西。在没标签的数据上预训练好之后,然后再在有标签的数据上做微调。半监督学习里面还有很多别的算法,但是现在我们把GPT这套方法和BERT之后所有的工作也用到的类似方法。不叫半监督学习而是叫自监督学习。就是同一个方法在不同的作者的论文中将它归类为不一样的算法。
下一段是他讲的模型,可以看到它主要有亮点,第一个是说模型是基于Transformer这个架构的,这篇文章发表在Transformer的后一年,而当时在选择用Transformer还是RNN不是那么显而易见,所以作者解释了一下大概的原因,他说跟RNN这种模型相比,发现Transformer在做迁移学习的时候,它学到的那些feature更加的稳健一些,作者觉得可能是因为Transformer里面有更结构化的记忆。能够处理更长的信息,从而能够抽取更好的句子层面和段层面的这些语义信息了。第二个技术要点是在做迁移的时候,用的是一个与任务相关的输入,我们在之后会看到它到底长什么样子。最后一段讲的是实验结果。
3.相关工作
相关工作就不仔细讲了。主要就是就讲了一下在NLP里面半监督是什么回事,讲的是无监督的预训练模型,还有是说我在训练的时候,使用多个目标函数会怎么样,GPT模型在没有标号的数据上怎么训练出来,以及怎么在子任务上运用有标签的数据进行微调。
4.架构
主要介绍怎么在没有标签的数据上做预训练,怎么微调。
4.1无标签的预训练
![]()
在没有标号的数据上做预训练,假设我们有一个文本,没有标号的文本里面每个词,里面每个词表示一个ui,那么它整个文本就表示成u1一直到ui,它是有个序列信息,我们不会交换你的顺序,GPT使用一个标准的语言模型的目标函数,来最大化下面这个似然函数,语言模型就是预测第i个词出现的概率,那么第i个词记为ui。
那怎么预测呢?把ui前面的k个词,从ui-1到ui-k,k这个地方是你的窗口大小,或者要做上下文的窗口,也就是说我们每次拿k个连续的词,然后预测这k个词后面那一个词是谁,具体来说他的预测是用一个模型,这个模型加入theta这个地方。给定k个词,以及给你这个模型,那么预测k个词下一个词它的概率,把每一个这样的词i,它的位置从0一直到最后,把全部加起来就得到我们的目标函数,这个地方记为L1,它不是范式里的L1,它就是第一个目标函数,因为他后面还有其他的目标函数,为什么求和是因为取了log的缘故,如果再做指数放回,也就是所以这些词出现的概率相乘,也就是这个文本出现的联合概率。
训练一个模型使它能够最大概率的输出跟我的文本长得一样的一些文章。所以theta是数据的参数,k是超参数,就是窗口的大小,从神经网络的角度来讲,那K就是输入序列的长度,输入的序列越长的话,网络看到的东西就越多,就是它越倾向于在一个比较长的文本里去找里面的关系,K越短的话,当然你的模型相对来说比较简单,只要看比较短的地方就可以了,所以这个地方,如果你想要你的模型很长的话,这个K可能要取几十,几百,甚至上千了。
接着解释这个具体的模型,它用到的模型是Transformer的解码器,Transformer分为编码器和解码器,他们最大的不同是编码器是进来一个序列,它对第i个元素抽取特征的时候,它能够看到序列中所有的元素,但是对解码器来讲,因为有掩码的存在,所以他在对第i个元素抽特征的时候,它只会看到当前元素和它之前的这些元素,他后面那些元素会通过一个掩码,使得在计算注意力机制的时候变成0,所以不看后面的东西,这个地方因为我们用的是标准的语言模型,只能用前面的信息来预测,所以预测第i个词的时候,不会看到这个词的后面这些词是谁,而只能看到前面的,所以这个地方我们只能用Transformer的解码器。
比如要预测u这个词的概率的话,我们把它前面K个拉取出来,记成一个大U,再做一个投影,就是词嵌入的投影。再加上一个位置新的编码,就得到第一层的输入。然后我们要做N层这样的Transformer块,每一层我们把上一次的输出拿进来然后得到输出,因为Transformer块不会改变输入输出的形状。最后拿到最后一个Transformer块的输出,再做一个投影,用SoftMax就会得到它的概率分布。
4.2微调
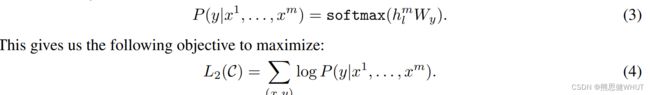
对微调来说是用有标签的数据,具体来说每一次我给你一个长为m的一个词的序列,然后告诉你这个序列它对应的标号是y,也就是每次给定一个序列预测他这个y.具体来说就是每次给x1到xm的数据,来预测y的概率,这里的做法是把整个这个序列放进我们训练好的GPT模型中,然后拿到Transformer块的最后一层的输出,对应的hm这个词的这个输出,然后再乘以一个输出层,再做一个 Softmax,就得到它的概率了。
也就在是微调任务里面,用所有的带标号的这些序列对,然后把这个序列 x1 到 xm 输入进去之后,计算我们真实的那个标号上面的概率,我们要对他做最大化,这是一个非常标准的一个分类目标函数,然后作者说虽然我们在微调的时候,我们只关心这一个分类的精度。但如果把之前的这个语言模型同样放进来,效果也不错,意思是说在做微调的时候有两个目标函数,第一个是给你这些序列,然后预测序列的下一个词。以及给你完整的序列,让你预测序列对应的标号,这两个一起训练效果是最佳的。然后通过一个λ,把这两个目标函数加起来,最后这个东西是可以调的,也是一个超参数了。
![]()
知道微调长什么样子的情况下。接下来要考虑的是怎么样把 NLP 里面那些很不一样的子任务,表示成一个我们要的形式,就是说表示成一个序列和他一个对应的标号。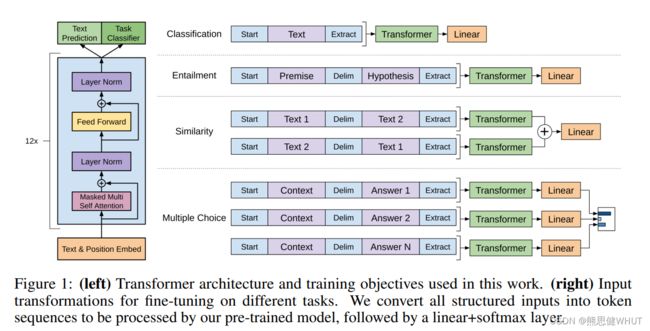
可以直接通过图一了解 NLP 里面四大常见的应用。一类是最常见的分类,就说给我一句话或者一段文本,来判断他对的一个标号,比如说一个用户对一个产品的评价,是正面的还是负面的。这里的做法是,把我要分类的这一段文字,在前面放一个初始的词元,在后面加一个抽取的词元,然后就做成一个序列。序列放进 Transformer 的解码器里面,然后模型对最后一个词抽取的特征,最后放进一个线性层里面。线性层的话,就投影到我要的那个标号的空间,就是说如果我要做10类分类的话,那么你的线性层它的输出大小就是10。在训练的时候,就是对每一个文本和标号对,把文本变成一个这样子的序列,然后标号就放在这个地方参加训练。在预测的时候,当然是只拿到这一个序列信息,然后对他直接做预测就行了,所以这个地方跟之前的语言模型还是有那么一点区别的。因为这个线性层是新加的,这是在微调的时候,重新构造了一个新的线性层,里面的全都可能是随机初始化的,然后他的输出大小跟我的标号的大小是一致的。
第二个任务英文叫做蕴含。就是我给你一段话,然后再问你一个假设,你看一下我前面这段话,有没有蕴含我假设提出来的东西.比如说 a 送给 b 一束玫瑰,假设我的假设是说 a 喜欢 b,那么你就说我前面这段话是支持你这个假设的.如果我说,a 讨厌 b 那么你可以认为,前面这段话是不支持这个假设的.如果我说 a 和 b 是邻居,那么你可以说前面这个假设既不支持,也不反对我这个假设.所以说白了就是一个三类的问题.我给你两段文本,然后让你做一个三分类的问题,他在表达的时候,就是把这两个文本串成一个长的序列,用一个开始符,分隔符和抽取符.这三个词元是一个特殊的记号,必须要跟我的词典里面那些别的词是不一样才行的,不然的话模型就会混淆了。
第三个应用是相似。就是判断两段文字是不是相似,这个应用在 NLP 里面用的也是非常广泛,比如说我一个搜索词,和我一个文档是不是相似的,或者说我两个文档是不是相似,我这样子能来去重。或者说两个问题问的是不是相似来去重。因为相似是一个对称的关系,就说 a 和 b 相似,那么意味着 b 和 a 也是相似的,但是我们在语言模型里面是有个先后的顺序,所以这个地方做两个序列。第一个序列里面,第一段文字放在第二段文字前面,中间还是一样用分割符分开,前面加一个起始符和一个结束符。第二个序列就是把文字1和文字2交换顺序,这是因为他的对称关系,这是因为他的对称关系,序列分别进入我的模型之后,得到最后的这个输出,然后在上面做加号,最后进入线性层。得到我们要的,是相似还是不是相似的一个二分类的问题。
最后是一个多选题。就是我问你一个问题,然后给你几个答案,你在里面选出你觉得正确那个答案。他的做法是如果你有 n 个答案的话,那我们就构造 n 个序列,其中前面的都是你的问题,然后每一个答案作为第二个序列放在这个地方。每一个序列分别进入你的模型,然后用一个线性投影层,他的输出大小是1,这样得到你这个答案,是我这个问题问到的正确答案的一个置信度。对每个答案我都算一个这样子的标量,然后最后做一个 soft max,就知道我对于这个问题,我对每个答案觉得是正确答案的置信度是等于多少了。
可以看到,虽然这些应用上数据类型和大小都不同,但是基本上都可以构造成一个序列,要么就是有一段话要么就是有两段话。如果更复杂一点的话,可以构造出多个序列出来,但是这个地方不管我的输入形式怎么变,输出的构造怎么变,中间这个Transformer模型是不会变的。就是说我预先练好我的Transformer模型之后,我在做下游的任务时候,我都不会对这个模型的结构做改变,这也是GPT跟之前工作的一个大的区别,也就是这篇文章的一个核心点.
5.实验
实验这里注意到这有两点就可以了。第一点是他是在一个叫做BooksCorpus 的一个数据集上训练出来的,这个地方有7,000篇没有被发表的书。第二个说他的模型,用了12层的一个Transformer 的解码器,然后每一层的他的维度是768,所以我们关心的是说,你用一个多大的模型,在一个多大的数据集上训练好的,在结果上他当然比了之前那些算法.他说我们这样子的方法,比前面的人都要好一点.